Go 程序的性能监控与分析 pprof
你有没有考虑过,你的goroutines是如何被go的runtime系统调度的?是否尝试理解过为什么在程序中增加了并发,但并没有给它带来更好的性能?go执行跟踪程序可以帮助回答这些疑问,还有其他和其有关性能的问题,例如延迟、竞争和较低的并行效率。
该工具是Go 1.5版本加入的,通过度量go语言特定事件的运行时,例如:
创建,启动和终止goroutines
阻塞/非阻塞goroutines(syscalls, channels, locks)
网络 I/O
Syscalls
垃圾回收
Go 开箱就提供了一系列的性能监控 API 以及用于分析的工具, 可以快捷而有效地观察应用各个细节的 CPU 与内存使用概况, 包括生成一些可视化的数据(需要额外安装 Graphviz).
例子 gist 来自之前的 Trie 的实现, Ruby vs Go.
main 函数加上了下面几行:
|
|
这里 os.Create("cpu_profile") 指定生成的数据文件, 然后 pprof.StartCPUProfile 看名字就知道是开始对 CPU 的使用进行监控. 有开始就有结束, 一般直接跟着 defer pprof.StopCPUProfile() 省的后面忘了. 编译执行一次以后会在目录下生成监控数据并记录到 cpu_profile. 接着就可以使用 pprof 来解读分析这些监控生成的数据.
When CPU profiling is enabled, the Go program stops about 100 times per second and records a sample consisting of the program counters on the currently executing goroutine’s stack.
CPU Profiling
|
|
因为是在多核环境, 所以, 取样时间(Total samples) 占比大于 100% 也属于正常的. 交互操作模式提供了一大票的命令, 执行一下 help 就有相应的文档了. 比如输出报告到各种格式(pdf, png, gif), 方块越大个表示消耗越大.

又或者列出 CPU 占比最高的一些(默认十个)运行结点的 top 命令, 也可以加上需要的结点数比如 top15
|
|
- flat: 是指该函数执行耗时, 程序总耗时 570ms,
main.NewNode的 200ms 占了 35.09% - sum: 当前函数与排在它上面的其他函数的 flat 占比总和, 比如
35.09% + 12.28% = 47.37% - cum: 是指该函数加上在该函数调用之前累计的总耗时, 这个看图片格式的话会更清晰一些.
可以看到, 这里最耗 CPU 时间的是 main.NewNode 这个操作.
除此外还有 list 命令可以根据匹配的参数列出指定的函数相关数据, 比如:

Memory Profiling
|
|
类似 CPU 的监控, 要监控内存的分配回收使用情况, 只要调用 pprof.WriteHeapProfile(memProfile)
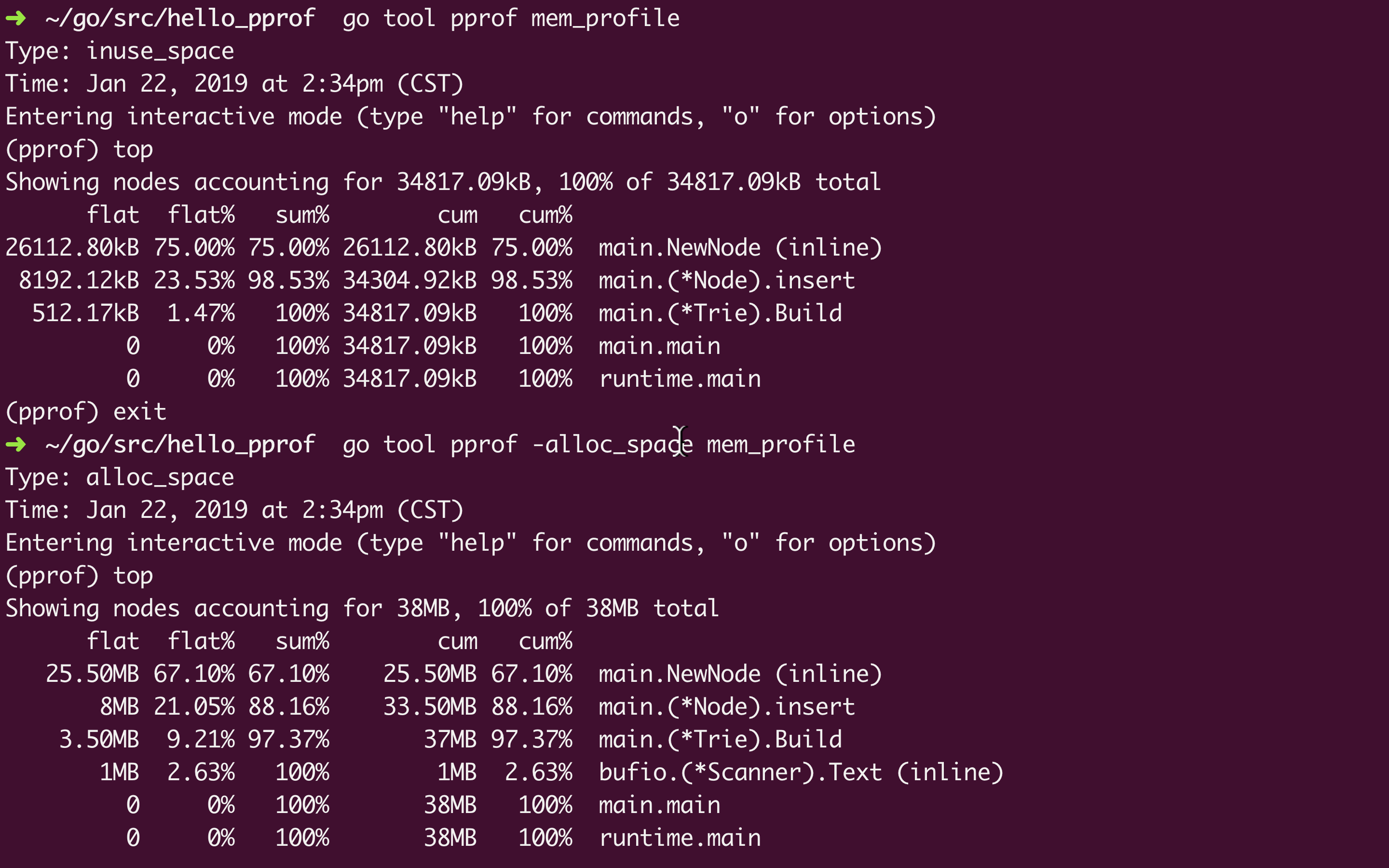
然后是跟上面一样的生成图片:

Type: inuse_space 是监控内存的默认选项, 还可以选 -alloc_space, -inuse_objects, -alloc_objects
inuse_space 是正在使用的内存大小, alloc_space是从头到尾一共分配了的内存大小(包括已经回收了的), 后缀为 _objects 的是相应的对象数
net/http/pprof
对于 http 服务的监控有一些些的不同, 不过 Go 已经对 pprof 做了一些封装在 net/http/pprof
例子 gist 来自从 net/http 入门到 Gin 源码梳理
引入多一行 _ "net/http/pprof", 启用服务以后就可以在路径 /debug/pprof/ 看到相应的监控数据. 类似下面(已经很贴心的把各自的描述信息写在下边了):
用 wrk (brew install wrk) 模拟测试
wrk -c 200 -t 4 -d 3m http://localhost:8080/hello

还是没有前面的那些可视化图形 UI 直观, 不过可以通过 http://localhost:8080/debug/pprof/profile (其他几个指标也差不多, heap, alloc…)生成一个类似前面的 CPU profile 文件监控 30s 内的数据. 然后就可以用 go tool pprof来解读了.
|
|
gin pprof
import _ "net/http/pprof" 实际上是为了执行包 net/http/pprof 中的 init 函数.
|
|
因此, Gin 项目要使用 pprof 的话可以参考这里
Flame Graph 火焰图
go-torch 在 Go 1.11 之前是作为非官方的可视化工具存在的, 它可以为监控数据生成一个类似下面这样的图形界面, 红红火火的, 因而得名. 从 Go 1.11 开始, 火焰图被集成进入 Go 官方的 pprof 库.
go-torch is deprecated, use pprof instead
As of Go 1.11, flamegraph visualizations are available in go tool pprof directly!
|
|
在浏览器打开 http://localhost:8081/ui/flamegraph, 就可以看到下面这样的反过来的火焰图.
长条形的颜色只是为了好看, 颜色的深浅是随机的 = 。= 长度越长代表占用 CPU 时间越长

然后, pprof 命令行的 top 以及 list 正则也可以在这里边完成, 还有 svg 图形.
基于Chrome的图形trace/debug
Trace概览
让我们从一个简单的“Hello,world”示例开始。在本例中,我们使用runtime/trace包将trace数据写入标准错误输出。
package main
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
// create new channel of type int
ch := make(chan int)
// start new anonymous goroutine
go func() {
// send 42 to channel
ch <- 42
}()
// read from channel
<-ch
}这个例子创建了一个无缓冲的channel,初始化一个goroutine,并发送数字42到channel。运行主goroutine时是阻塞的,它会等待另一个goroutines发送一个int数值给channel。
用 go run main.go 2> trace.out 运行这段代码会发送trace数据到trace.out,之后可以用 go tool trace trace.out 读取trace。(该程序是个web app,默认启动127.0.0.1地址的一个随机端口,如果需要修改host可以加参数解决,例如 go tool trace --http=':8080' trace.out,译者加)
Tips: go 1.8之前,你同时需要可执行二进制文件和trace数据来分析trace;用go 1.8之后的版本编译的程序,trace数据已经包含了go tool trace命令所有的信息。
运行该命令后,在浏览器窗口打开该地址,它会提供一些选项。每一个都会打开trace的不同视图,涵盖了程序执行的不同信息。

1 View trace
最复杂、最强大和交互式的可视化显示了整个程序执行的时间轴。这个视图显示了在每个虚拟处理器上运行着什么,以及什么是被阻塞等待运行的。稍后我们将在这篇文章中深入探讨这个视图。注意它只能在chrome上显示。
2 Goroutine analysis
显示了在整个执行过程中,每种类型的goroutines是如何创建的。在选择一种类型之后就可以看到关于这种类型的goroutine的信息。例如,在试图从mutex获取锁、从网络读取、运行等等每个goroutine被阻塞的时间。
3 Network/Sync/Syscall blocking profile
这些图表显示了goroutines在这些资源上所花费的时间。它们非常接近pprof上的内存/cpu分析。这是分析锁竞争的最佳选择。
4 Scheduler latency profiler
为调度器级别的信息提供计时功能,显示调度在哪里最耗费时间。
View Trace
点击“View Trace”链接,你会看到一个界面,里面充满了关于整个程序执行的信息。Tips: 右上角的"?"按钮可以获取快捷方式列表,以帮助跟踪trace。
下面的图片突出了最重要的部分,图片下面是对每个部分的说明描述:

1 Timeline
显示执行的时间,根据跟踪定位的不同,时间单位可能会发生变化。你可以通过使用键盘快捷键(WASD键,就像视频游戏一样)来导航时间轴。
2 Heap
在执行期间显示内存分配,这对于发现内存泄漏非常有用,并检查垃圾回收在每次运行时能够释放多少内存。
3 Goroutines
在每个时间点显示有多少goroutines在运行,有多少是可运行的(等待被调度的)。大量可运行的goroutines可能显示调度竞争,例如,当程序创建过多的goroutines,会导致调度程序繁忙。
4 OS Threads
显示有多少OS线程正在被使用,有多少个被syscalls阻塞。
5 Virtual Processors
每个虚拟处理器显示一行。虚拟处理器的数量由GOMAXPROCS环境变量控制(默认为内核数)。
6 Goroutines and events
显示在每个虚拟处理器上有什么goroutine在运行。连接goroutines的连线代表事件。在示例图片中,我们可以看到goroutine "G1.runtime.main"衍生出了两个不同的goroutines:G6和G5(前者是负责收集trace数据的goroutine,后者是我们使用“go”关键字启动的那个)。每个处理器的第二行可能显示额外的事件,比如syscalls和运行时事件。这还包括goroutine代表运行时所做的一些工作(例如辅助垃圾回收)。下图显示了当选择一个goroutine时得到的信息。

该信息包含:
它的“名称”(Title)
何时开始(Start)
持续时间(Wall Duration)
开始时的栈trace
结束时的栈trace
该goroutine产生的事件
我们可以看到,这个goroutine创造了两个事件:
trace goroutine和在channel上发送42的goroutine。

通过点击一个特定的事件(点击图中的一条连线或者在点击goroutine后选择事件),我们可以看到:
事件开始时的栈信息
事件持续时长
事件包含的goroutine
你可以点击这些goroutines来定位跟踪到它们的trace数据。
阻塞概况
从trace中获得的另一个特殊视图是网络/同步/syscall阻塞概况。阻塞概况显示了一个类似于pprof的内存/cpu概况中的图形视图。不同之处在于,这些概况显示每个goroutine在一个特定资源上花费的阻塞时间,而不是显示每个函数分配了多少内存。下图告诉我们示例代码的“同步阻塞概况”

这告诉我们,我们的主goroutine从一个channel接收花费了12.08微秒。当太多的goroutines在竞争着获取一个资源的锁时,这种类型的图是找到锁竞争的很好的方法。
收集trace
有三种收集trace的方法:
1 使用 runtime/trace包
这个需要调用trace.Start和trace.Stop,已经在我们的示例程序中讲过。
2 使用 -trace=<file>测试标志
用来收集关于被测试代码的trace时比较有用。
3 使用 debug/pprof/tracehandler
这是用来收集运行中的web应用的trace的最好的方法。
跟踪一个web应用
想要从一个运行的web应用收集trace, 你需要添加 /debug/pprof/trace handler。下面的代码示例展示了如何通过简单地导入 net/http/pprof 包为 http.DefaultServerMux 做到这一点。
package main
import (
"net/http"
_
"net/http/pprof"
)
func main() {
http.Handle("/hello", http.HandlerFunc(helloHandler))
http.ListenAndServe("localhost:8181", http.DefaultServeMux)
}
func helloHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("hello world!"))
}为了收集trace,我们需要向endpoint发出请求,例如,curl localhost:8181/debug/pprof/trace?seconds=10 > trace.out 此请求将阻塞10秒钟,trace数据将写入文件trace.out。像这样生成的trace可以像我们以前那样查看:go tool trace trace.out
Tips: 请注意,将pprof handlers暴露给Internet是不建议的。推荐的做法是在不同的只绑定到loopback接口的http.Server暴露这些endpoint。这篇博客(https://mmcloughlin.com/posts/your-pprof-is-showing)讨论该风险,并有代码示例解释如何正确地暴露pprof handler。
在收集trace之前,让我们首先通过wrk来给我们的服务加一些负载:$ wrk -c 100 -t 10 -d 60s http://localhost:8181/hello
这将使用10个线程的100个连接在60秒内发出请求。当wrk正在运行时,我们可以使用 curl localhost:8181/debug/pprof/trace?seconds=5 > trace.out 来收集5s的trace数据。这会产生一个5MB的文件(如果我们能够在我的4核CPU机器上生成更多的负载,它就可以快速增长)。同样,打开trace是由go tool trace命令完成的。当该工具解析文件的整个内容时,这将花费比我们之前的示例花费的时间更长。当它完成时,页面看起来略有不同:
View trace (0s-2.546634537s)
View trace (2.546634537s-5.00392737s) Goroutine analysis
Network blocking profile
Synchronization blocking profile
Syscall blocking profile
Scheduler latency profile
为了保证浏览器渲染呈现所有内容,该工具将trace分为两个连续的部分。更复杂的应用或更长的trace可能需要工具将其分割成更多的部分。点击“View trace(2.546634537-5.00392737)”我们可以看到有很多事情正在发生:
这个特殊的屏幕截图显示了一个GC运行情况,它从1169ms-1170ms开始,在1174ms之后结束。在这段时间里,一个OS线程(PROC 1)运行一个用于GC的goroutine,而其他goroutines则在一些GC阶段中提供辅助(这些步骤显示在goroutine的连线中,并被叫做MARK ASSIST)。在截图的最后,我们可以看到大部分分配的内存都被GC释放了。 另一个特别有用的信息是在“Runnable”状态下的goroutines的数量(在选定的时间内是13):如果这个数字随着时间的推移变得很大,这就意味着我们需要更多的cpu来处理负载。
结论
trace程序是调试并发问题的强大工具。例如,竞争和逻辑冲突。但它并不能解决所有的问题:它并不是用来跟踪哪块代码花费最多CPU时间或分配的最佳工具。go tool pprof 更适用于这些用例。当你想要了解一个耗时程序的行为,并且想知道当每个goroutine不运行时它在做什么,这个工具就会很好地发挥作用。收集trace可能会有一些开销,并且会生成大量的数据用来检查。不幸的是,官方文档是缺失的,因此需要进行一些试验来尝试和理解trace程序所显示的内容。这也是对官方文档和整个社区作出贡献的机会(e.g 博客文章)。
参考
Go execution tracer (design doc)
Using the go tracer to speed fractal rendering
Go tool trace
Your pprof is showing
Go 程序的性能监控与分析 pprof的更多相关文章
- web性能监控与分析
注:原文为:andyguo: <web性能监控与分析> 性能测试需要使用不同的工具,结合系统日志,监控服务器.应用等方面的多项指标.以下阐述监控指标.监控工具.瓶颈分析. 服务端监控指标 ...
- Linux性能监控与分析之--- CPU
Linux性能监控与分析之--- CPU 望月成三人关注 2016.07.25 18:16:12字数 1,576阅读 2,837 CPU性能指标 用户进程使用CPU的比率 系统进程使用CPU的比率 W ...
- MongoDB监控之一:运行状态、性能监控,分析
为什么要监控? 监控及时获得应用的运行状态信息,在问题出现时及时发现. 监控什么? CPU.内存.磁盘I/O.应用程序(MongoDB).进程监控(ps -aux).错误日志监控 1.4.1 Mong ...
- 性能监控 | MAT分析内存泄漏
使用MAT分析内存泄漏(二)八周年重印版 - 知乎 .u-safeAreaInset-top { height: constant(safe-area-inset-top) !important; h ...
- 【性能测试实战:jmeter+k8s+微服务+skywalking+efk】系列之:性能监控、分析、调优等
说明: 本文是基于虚拟机演示的,资源有限 skywalking中拓扑图 kubectl get po -A -owide 测试执行:单场景 查询礼品 jmeter -n -t gift.jmx -l ...
- MongoDB 运行状态、性能监控,分析
这篇文章的目的是让你知道怎么了解你正在运行的Mongdb是否健康.转载自http://tech.lezi.com/archives/290 mongostat详解 启动mongodb监控,通过下面命令 ...
- MongoDB运行状态、性能监控,分析
转载自这位仁兄:地址 mongostat详解 mongostat是mongdb自带的状态检测工具,在命令行下使用.它会间隔固定时间获取mongodb的当前运行状态,并输出.如果你发现数据库突然变慢或者 ...
- mysql存储过程性能监控和分析
公司当前版本的系统大量的使用了存储过程,有些复杂的过程套过程,一个主调用者可能最多调用其它几十个小的业务逻辑和判断,不要说这么做很不合理,在大陆,目前至少30%的证券交易系统代码都是用存储过程写业务逻 ...
- JVM-Java程序性能监控-初级篇
前篇 - 小伙们都知道,java程序的性能监控主要是针对jvm中heap的监控~ 那么在做压力测试时如何对heap.线程等一系列的指标进行的监控的呢? 首先-你若不懂命令,那么就需要了解一套Java程 ...
随机推荐
- Scala 占位符在REPL和Eclipse/IDEA中初始化变量问题
占位符在REPL和Eclipse/IDEA中初始化变量问题: 占位符初始化,如果是局部变量,都会报错!只能在全局变量中使用! REPL: Eclipse: IDEA: 如果是类的属性,却就是对的.
- 02-17 kd树
目录 kd树 一.kd树学习目标 二.kd树引入 三.kd树详解 3.1 构造kd树 3.1.1 示例 3.2 kd树搜索 3.2.1 示例 四.kd树流程 4.1 输入 4.2 输出 4.3 流程 ...
- HashMap底层数据结构详解
一.HashMap底层数据结构 JDK1.7及之前:数组+链表 JDK1.8:数组+链表+红黑树 关于HashMap基本的大家都知道,但是为什么数组的长度必须是2的指数次幂,为什么HashMap的加载 ...
- 浅谈sqlserver的事务锁
锁的概述 一. 为什么要引入锁 多个用户同时对数据库的并发操作时会带来以下数据不一致的问题: 丢失更新 A,B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统 ...
- 1.C&DataStructure引言
使用过C++ <STD> 库的猿友们应该都觉得 C++中那些已经实现好了的数据类型封装使用让人很是舒服; 例如 vector 支持自动扩充数组,支持模板类,任何数据类型都可以 简单的管理, ...
- 《java编程思想》P140-P160(第七章复部+第八章部分)
1.不用修饰符 修饰的方法或类,它们的修饰符是 默认修饰符,即 包访问权限(包内都可以用)(临时记的) 2. final数据: 对于基本类型,final使数值恒定不变,而对于对象引用,final使引用 ...
- 阿里terway源码分析
背景 随着公司业务的发展,底层容器环境也需要在各个区域部署,实现多云架构, 使用各个云厂商提供的CNI插件是k8s多云环境下网络架构的一种高效的解法.我们在阿里云的方案中,便用到了阿里云提供的CNI插 ...
- 【Medium 万赞好文】ViewModel 和 LIveData:模式 + 反模式
原文作者: Jose Alcérreca 原文地址: ViewModels and LiveData: Patterns + AntiPatterns 译者:秉心说 View 和 ViewModel ...
- Cobalt Strike之CHM、LNK、HTA钓鱼
CHM钓鱼 CHM介绍 CHM(Compiled Help Manual)即“已编译的帮助文件”.它是微软新一代的帮助文件格式,利用HTML作源文,把帮助内容以类似数据库的形式编译储存.利用CHM钓鱼 ...
- Windows 7 SP1官方原版ISO系统镜像所有版本下载集合
========================================================================== Windows 7 With SP1 32位简体中 ...