详解svm和smo的出现
SupportVector Machines are learning models used forclassification: which individuals in a population belong where?
支持向量机(SVM)定义:支持向量机是主要用于解决分类问题的学习模型。
感知机
在讲解SVM之前我们先回到1956年达特矛斯会议之后,在会议中确定了我们学科的名字AI的同时,也激起了一片人工智能热,正是在这次浪潮中出现了一个人-罗森布拉特。


他是一位心理医生,在神经感知科学背景下提出了类似现在机器学习模型得--感知机。罗森布拉特声称感知机不仅能识别图像,还能教机器行走,说话和做出表情。受时代的限制,感知机能做的事情还很有限。神经网络的研究经历了十多年的冷冻期。后来,2004年,IEEE Frank Rosenblatt Award成立,他被称为神经网络的创立者。
感知器算法是最古老的分类算法之一,原理比较简单,不过模型的分类泛化能力比较弱,不过感知器模型是SVM、神经网络、深度学习等算法的基础。感知器的思想很简单:在任意空间中,感知器模型寻找的就是一个超平面,能够把所有的二元类别分割开。感知器模型的前提是:数据是线性可分的。

对于m个样本,每个样本n维特征以及一个二元类别输出y,如下:

目标是找到一个超平面
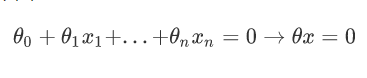
让一个类别的样本满足:θx>0 ;另外一个类别的满足:θx<0感知器模型为:
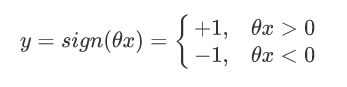
正确分类:yθx>0,错误分类:yθx<0;所以我们可以定义我们的损害函数为:期望使分类错误的所有样本(m条样本)到超平面的距离之和最小。

因为此时分子和分母中都包含了θ值,当分子扩大N倍的时候,分母也会随之扩大,也就是说分子和分母之间存在倍数关系,所以可以固定分子或者分母为1,然后求另一个即分子或者分母的倒数的最小化作为损失函数,简化后的损失函数为(分母为1):
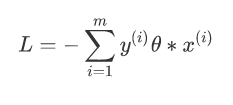
直接使用梯度下降法就可以对损失函数求解,不过由于这里的m是分类错误的样本点集合,不是固定的,所以我们不能使用批量梯度下降法(BGD)求解,只能使用随机梯度下降(SGD)或者小批量梯度下降(MBGD);一般在感知器模型中使用SGD来求解。

知识点
为了后面SVM推理的过程更好理解必须了解的知识点。
距离公式
两点之间得距离A(a1,b1)和B(a2,b2):
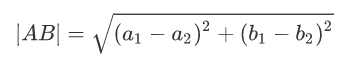
点到直线/平面的距离公式:假定点p(x0,y0),平面方程为f(x,y)=Ax+By+C,那么点p到平面f(x)的距离为:
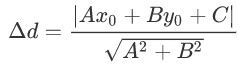
从三维空间扩展到多维空间中,如果存在一个超平面f(X)=θX+b; 那么某一个点X0到这个超平面的距离为:
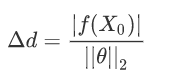
例如扩展到n维空间 :
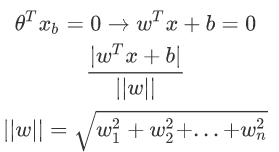
导数
导数:一个函数在某一点的导数描述了这个函数在这一点附近的变化率,也可以认为是函数在某一点的导数就是该函数所代表的曲线在这一点的切线斜率。导数值越大,表示函数在该点处的变化越大。
梯度
梯度:梯度是一个向量,表示某一函数在该点处的方向导数沿着该方向取的最大值,即函数在该点处沿着该方向变化最快,变化率最大(即该梯度向量的模);当函数为一维函数的时候,梯度其实就是导数。
梯度下降法
梯度下降法(Gradient Descent, GD)常用于求解无约束情况下凸函数(ConvexFunction)的极小值,是一种迭代类型的算法,因为凸函数只有一个极值点,故求解出来的极小值点就是函数的最小值点。

梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以梯度下降法也被称为“最速下降法”。梯度下降法中越接近目标值,变量变化越小。计算公式如下:

α被称为步长或者学习率(learning rate),表示自变量x每次迭代变化的大小。当目标函数的函数值变化非常小的时候或者达到最大迭代次数的时候,就结束循环。
由于梯度下降法中负梯度方向作为变量的变化方向,所以有可能导致最终求解的值是局部最优解,所以在使用梯度下降的时候,一般需要进行一些调优策略:
学习率的选择:
学习率过大,表示每次迭代更新的时候变化比较大,有可能会跳过最优解;学习率过小,表示每次迭代更新的时候变化比较小,就会导致迭代速度过慢,很长时间都不能结束;
算法初始参数值的选择:
初始值不同,最终获得的最小值也有可能不同,因为梯度下降法求解的是局部最优解,所以一般情况下,选择多次不同初始值运行算法,并最终返回损失函数最小情况下的结果值;
标准化:
由于样本不同特征的取值范围不同,可能会导致在各个不同参数上迭代速度不同,为了减少特征取值的影响,可以将特征进行标准化操作
批量梯度下降法(Batch Gradient Descent, BGD):使用所有样本在当前点的梯度值来对变量参数进行更新操作。
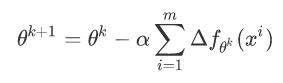
随机梯度下降法(Stochastic Gradient Descent, SGD):在更新变量参数的时候,选取一个样本的梯度值来更新参数。
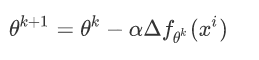
小批量梯度下降法(Mini-batch Gradient Descent, MBGD):集合BGD和SGD的特性,从原始数据中,每次选择n个样本来更新参数值,一般n选择10。
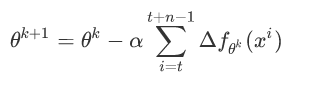
三种梯度下降比较
当样本量为m的时候,每次迭代BGD算法中对于参数值更新一次,SGD算法中对于参数值更新m次,MBGD算法中对于参数值更新m/n次,相对来讲SGD算法的更新速度最快;
SGD算法中对于每个样本都需要更新参数值,当样本值不太正常的时候,就有可能会导致本次的参数更新会产生相反的影响,也就是说SGD算法的结果并不是完全收敛的,而是在收敛结果处波动的;
SGD算法是每个样本都更新一次参数值,所以SGD算法特别适合样本数据量大的情况以及在线机器学习(Online ML)。
拉格朗日乘子法
有约束的最优化问题
最优化问题一般是指对于某一个函数而言,求解在其指定作用域上的全局最小值问题,一般分为以下三种情况(备注:以下几种方式求出来的解都有可能是局部极小值,只有当函数是凸函数的时候,才可以得到全局最小值):
无约束问题:求解方式一般求解方式梯度下降法、牛顿法、坐标轴下降法等;

等式约束条件:求解方式一般为拉格朗日乘子法

不等式约束条件:求解方式一般为KKT条件

拉格朗日乘子法就是当我们的优化函数存在等值约束的情况下的一种最优化求解方式;其中参数α被称为拉格朗日乘子,要求α不等于0

对偶问题
在优化问题中,目标函数f(x)存在多种形式,如果目标函数和约束条件都为变量x的线性函数,则称问题为线性规划;如果目标函数为二次函数,则称最优化问题为二次规划;如果目标函数或者约束条件为非线性函数,则称最优化问题为非线性优化。每个线性规划问题都有一个对应的对偶问题。对偶问题具有以下几个特性:
对偶问题的对偶是原问题;
无论原始问题是否是凸的,对偶问题都是凸优化问题;
对偶问题可以给出原始问题的一个下界;
当满足一定条件的时候,原始问题和对偶问题的解是完美等价的。
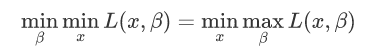
KKT条件
KKT条件是泛拉格朗日乘子法的一种形式;主要应用在当我们的优化函数存在不等值约束的情况下的一种最优化求解方式;KKT条件即满足不等式约束情况下的条件。

可行解必须在约束区域g(x)之内,由图可知可行解x只能在g(x)<0和g(x)=0的区域取得;

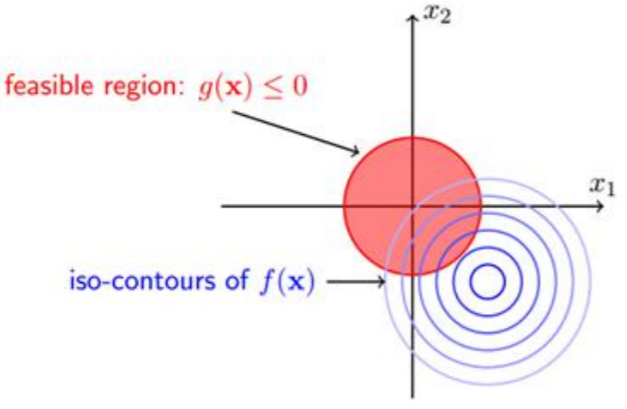
当可行解x在g(x)<0的区域中的时候,此时直接极小化f(x)即可得到;


当可行解x在g(x)=0的区域中的时候,此时直接等价于等式约束问题的求解。

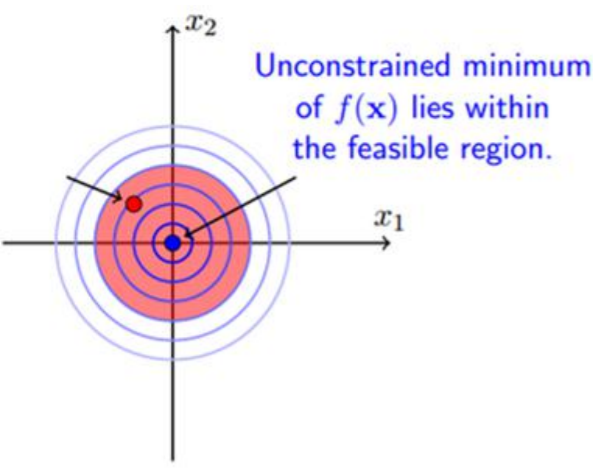
当可行解在约束内部区域的时候,令β=0即可消去约束。
对于参数β的取值而言,在等值约束中,约束函数和目标函数的梯度只要满足平行即可,而在不等式约束中,若β≠0,则说明可行解在约束区域的边界上,这个时候可行解应该尽可能的靠近无约束情况下的解,所以在约束边界上,目标函数的负梯度方向应该远离约束区域朝无约束区域时的解,此时约束函数的梯度方向与目标函数的负梯度方向应相同;从而可以得出β>0。
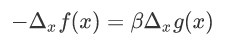
对偶问题的直观理解:最小的里面的那个最大的要比最大的那个里面的最小的大;从而就可以为原问题引入一个下界。

KKT 案例
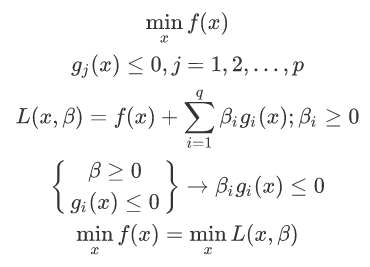
这里利用该KKT条件满足对偶条件:

拉格朗日取得可行解的充要条件;
将不等式约束转换后的一个约束,称为松弛互补条件;
初始的约束条件;
初始的约束条件;
不等式约束需要满足的条件。
SVM
支持向量机(Support Vecor Machine, SVM)本身是一个二元分类算法,是对感知器算法模型的一种扩展,现在的SVM算法支持线性分类和非线性分类的分类应用,并且也能够直接将SVM应用于回归应用中,同时通过OvR或者OvO的方式我们也可以将SVM应用在多元分类领域中。在不考虑集成学习算法,不考虑特定的数据集的时候,在分类算法中SVM可以说是特别优秀的。
思考一下


当面临像上面的分类问题时候我们可以利用感知机轻易的找到一个分界线。
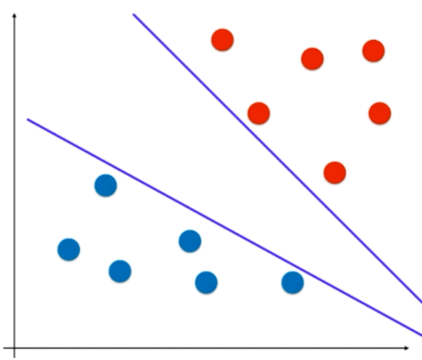

可以对于这些分界线那个更好呢?这便是SVM要解决得问题。
在感知器模型中,我们可以找到多个可以分类的超平面将数据分开,并且优化时希望所有的点都离超平面尽可能的远,但是实际上离超平面足够远的点基本上都是被正确分类的,所以这个是没有意义的;反而比较关心那些离超平面很近的点,这些点比较容易分错。所以说我们只要让离超平面比较近的点尽可能的远离这个超平面,那么我们的模型分类效果应该就会比较不错喽。SVM其实就是这个思想。
首先确定什么是支持向量
就是在支持向量机中,距离超平面最近的且满足一定条件的几个训练样本点被称为支持向量。
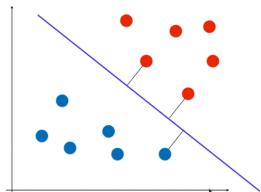

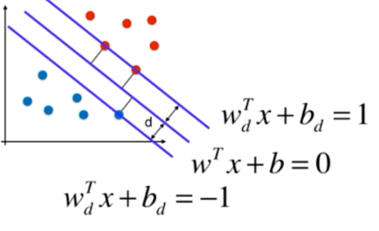
SVM尝试找到一个决策边界,距离两个类别最近的样本最远
线性可分(Linearly Separable):
在数据集中,如果可以找出一个超平面,将两组数据分开,那么这个数据集叫做线性可分数据。
线性不可分(Linear Inseparable):
在数据集中,没法找出一个超平面,能够将两组数据分开,那么这个数据集就叫做线性不可分数据。分割超平面(Separating Hyperplane):将数据集分割开来的直线/平面叫做分割超平面。
间隔(Margin):
数据点到分割超平面的距离称为间隔。
支持向量(Support Vector):
离分割超平面最近的那些点叫做支持向量。
SVM推理
这时候就用到上面介绍的距离公式了:
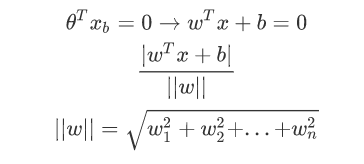

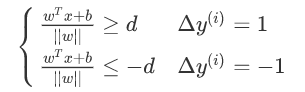
对上式进行化简:
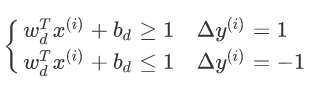

此时的w和b已不是原来的w和b



将两个式子合成一个,也就是约束条件满足:
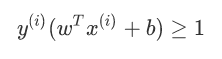
这时候对于任意支持向量x来说:
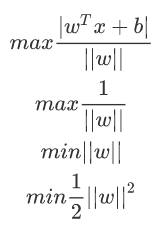
对接下来的函数求最优解,利用梯度下降,求各个特征的偏导:
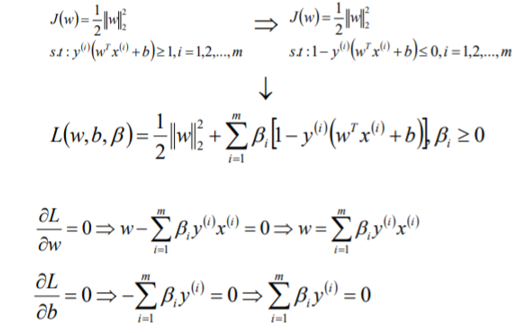

将求解出来得w和b带入优化函数L中,定义优化之后得函数如下:



通过对w、b极小化后,我们最终得到的优化函数只和β有关,所以此时我们可以直接极大化我们的优化函数,得到β的值,从而可以最终得到w和b的值。

也就是求解下面函数:

这里先不求解,先去看看当前模型存在的弱点,并进行改正。
软间隔
线性可分SVM中要求数据必须是线性可分的,才可以找到分类的超平面,但是有的时候线性数据集中存在少量的异常点,由于这些异常点导致了数据集不能够线性划分;直白来讲就是:正常数据本身是线性可分的,但是由于存在异常点数据,导致数据集不能够线性可分;


如果线性数据中存在异常点导致没法直接使用SVM线性分割模型的时候,我们可以通过引入软间隔的概念来解决这个问题;
硬间隔:
可以认为线性划分SVM中的距离度量就是硬间隔,在线性划分SVM中,要求函数距离一定是大于1的,最大化硬间隔条件为:

软间隔:
SVM对于训练集中的每个样本都引入一个松弛因子(ξ),使得函数距离加上松弛因子后的值是大于等于1;这表示相对于硬间隔,对样本到超平面距离的要求放松了:

松弛因子(ξ)越大,表示样本点离超平面越近,如果松弛因子大于1,那么表示允许该样本点分错,所以说加入松弛因子是有成本的,过大的松弛因子可能会导致模型分类错误,所以最终的目标函数就转换成为:
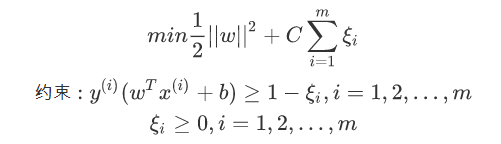
函数中的C>0是惩罚参数,是一个超参数,类似L1/L2 norm的参数;C越大表示对误分类的惩罚越大,C越小表示对误分类的惩罚越小;C值的给定需要调参。
将上面的计算全部用软间隔的模型进行计算....(雷同略过)
最后得出结果:
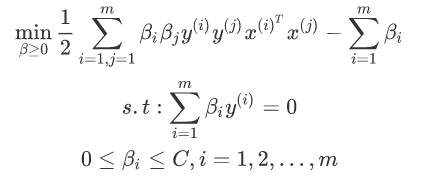
在硬间隔最大化的时候,支持向量比较简单,就是离超平面的函数距离为1的样本点就是支持向量。但是软间隔相当于加了一个宽泛条件,使得满足|wx+b|=1的所有样本均是支持向量。
软间隔模型的优缺点
可以解决线性数据中携带异常点的分类模型构建的问题;
通过引入惩罚项系数(松弛因子),可以增加模型的泛化能力,即鲁棒性;
如果给定的惩罚项系数越小,表示在模型构建的时候,就允许存在越多的分类错误的样本, 也就表示此时模型的准确率会比较低;如果惩罚项系数越大,表示在模型构建的时候,就越不允许存在分类错误的样本,也就表示此时模型的准确率会比较高。
线性不可分问题
在求解之前,先讨论线性可分和不可分
上面推理的过程中不管是线性可分SVM还是加了软间隔得线性可分SVM,都要求数据必须是线性可分的;虽然纯线性可分的SVM模型对于异常数据的预测可能会不太准;但对于线性可分的数据,SVM分类器的效果非常不错。
可在现实中大多数数据是线性不可分的,类似于下面这种情况:


这时候有个解决办法就是升维,回顾一下线性回归中得多项式回归:

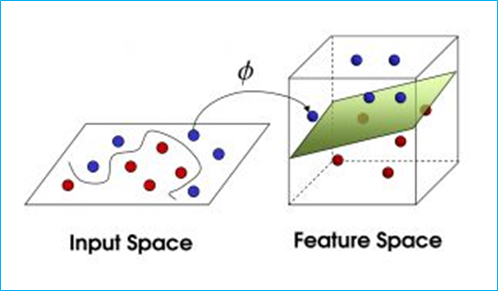

这样一来就可以轻易的将数据给分开了这样一来问题就解决了吗?
似乎是的:拿到非线性数据,就找一个映射,然后一股脑把原来的数据映射到新空间中,再做线性 SVM 即可。不过事实上没有这么简单!
其实刚才的方法稍想一下就会发现有问题:在最初的例子里做了一个二阶多项式的转换,对一个二维空间做映射,选择的新空间是原始空间的所有一阶和二阶的组合,得到了5个维度;如果原始空间是三维,那么我们会得到9维的新空间;如果原始空间是n维,那么我们会得到一个n(n+3)/2维的新空间;这个数目是呈爆炸性增长的,这给计算带来了非常大的困难,而且如果遇到无穷维的情况,就根本无从计算。
核函数
核函数在解决线性不可分问题的时候,采取的方式是:使用低维特征空间上的计算来避免在高维特征空间中向量内积的恐怖计算量;也就是说此时SVM模型可以应用在高维特征空间中数据可线性分割的优点,同时又避免了引入这个高维特征空间恐怖的内积计算量。
假设函数Ф是一个从低维特征空间到高维特征空间的一个映射,那么如果存在函数K(x,z), 对于任意的低维特征向量x和z,都有:

上面得函数就称为核函数。
举个栗子
从最开始的简单例子出发,设两个向量x1=(u1,u2) 和x2=(n1,n2) ,而即是到前面说的五维空间的映射,因此映射过后的内积为:

对于上面得式子,再看一下这个:

可以发现两者之间非常相似,所以我们只要乘上一个相关的系数,就可以让这两个式子的值相等,这样不就将五维空间的一个内积转换为两维空间的内积的运算。
| x1 | 3 | 5 |
|---|---|---|
| x2 | 4 | 2 |

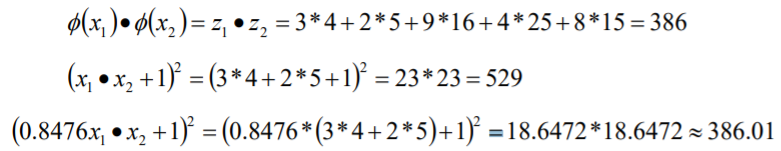

线性核函数(Linear Kernel):

多项式核函数(Polynomial Kernel):其中γ、r、d属于超参,需要调参定义;

高斯核函数(Gaussian Kernel):其中γ属于超参,要求大于0,需要调参定义;

Sigmoid核函数(Sigmoid Kernel):其中γ、r属于超参,需要调参定义;

核函数可以自定义;核函数必须是正定核函数,即Gram矩阵是半正定矩阵;
核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算;
通过核函数,可以将非线性可分的数据转换为线性可分数据;
SMO算法出现得必要

经过加上软间隔和核函数处理后:

详解svm和smo的出现的更多相关文章
- 机器学习,详解SVM软间隔与对偶问题
今天是机器学习专题的第34篇文章,我们继续来聊聊SVM模型. 我们在上一篇文章当中推导了SVM模型在硬间隔的原理以及公式,最后我们消去了所有的变量,只剩下了\(\alpha\).在硬间隔模型当中,样本 ...
- ML-求解 SVM 的SMO 算法
这算是我真正意义上认真去读的第一篇ML论文了, but, 我还是很多地方没有搞懂, 想想, 缓缓吧, 还是先熟练调用API 哈哈 原论文地址: https://www.microsoft.com/en ...
- 详解SVM模型——核函数是怎么回事
大家好,欢迎大家阅读周二机器学习专题,今天的这篇文章依然会讲SVM模型. 也许大家可能已经看腻了SVM模型了,觉得我是不是写不出新花样来,翻来覆去地炒冷饭.实际上也的确没什么新花样了,不出意外的话这是 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- 【机器学习详解】SMO算法剖析(转载)
[机器学习详解]SMO算法剖析 转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51227754 CSDN−勿在浮沙筑高台 本文力 ...
- libsvm的安装,数据格式,常见错误,grid.py参数选择,c-SVC过程,libsvm参数解释,svm训练数据,libsvm的使用详解,SVM核函数的选择
直接conda install libsvm安装的不完整,缺几个.py文件. 第一种安装方法: 下载:http://www.csie.ntu.edu.tw/~cjlin/cgi-bin/libsvm. ...
- EasyPR--开发详解(6)SVM开发详解
在前面的几篇文章中,我们介绍了EasyPR中车牌定位模块的相关内容.本文开始分析车牌定位模块后续步骤的车牌判断模块.车牌判断模块是EasyPR中的基于机器学习模型的一个模块,这个模型就是作者前文中从机 ...
- EasyPR--中文开源车牌识别系统 开发详解(1)
在上篇文档中作者已经简单的介绍了EasyPR,现在在本文档中详细的介绍EasyPR的开发过程. 正如淘宝诞生于一个购买来的LAMP系统,EasyPR也有它诞生的原型,起源于CSDN的taotao123 ...
- EasyPR--开发详解(2)车牌定位
这篇文章是一个系列中的第三篇.前两篇的地址贴下:介绍.详解1.我撰写这系列文章的目的是:1.普及车牌识别中相关的技术与知识点:2.帮助开发者了解EasyPR的实现细节:3.增进沟通. EasyPR的项 ...
随机推荐
- SharePoint js操作原生的New/Edit表单
列表的表单,有个类似的需求:在New需隐藏特定字段,Edit时显示. 默认是New/Edit表单的字段是一样,就算在Content type 是隐藏也是同时影响两个表单. 如何做到仅仅在New时隐 ...
- C语言程序的内存布局
C语言程序的内存布局 一:C语言程序的存储区域 C语言编写的程序经过编绎-链接后,将形成一个统一的文件,它由几个部分组成,在程序运行时又会产生几个其他部分,各个部分代表了不同的存储区域: 1.代码段( ...
- 【spring boot】application.properties官方完整文档
官方地址: https://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/ 进入搜索: Appendice ...
- Matlab与.Net混合编程-多维数组赋值出错的问题
问题描述:Matlab可编译供.net调用的dll.两种不同环境对数据类型的定义相差较大,因此在C#中调用Matlab编译的函数时,首先要将C#中的变量类型转换成与Matlab对应的中转类型.Matl ...
- SYN591-A型 计数器
SYN591-A型 计数器 秒表计数器累计计数器电机测速表使用说明视频链接: http://www.syn029.com/h-pd-248-0_310_44_-1.html 请将此链接复制到浏览 ...
- Spring Boot入门篇(基于Spring Boot 2.0系列)
1:概述: Spring Boot是用来简化Spring应用的初始化开发过程. 2:特性: 创建独立的应用(jar|war形式); 需要用到spring-boot-maven-plugin插件 直接嵌 ...
- shell把文件批量导入mysql
for file in ./tmp_data/* do echo $file mysql -u'root' -p'wangbin' --default-character-set=utf8 -e&qu ...
- 我所理解的Vue——学习心得体会1(Vue对象)
初学Vue,总结如下: 1.首先要区分html的dom和js的dom 2.html的dom是View的范畴,js的dom是Model的范畴. 3.vue这库就是创建了伟大的new Vue()对象,把h ...
- Ubuntu --- lamp环境下安装php扩展和开启apache重写
安装教程参考:http://www.laozuo.org/8303.html 1.安装php扩展(比如安装mbstring) 先搜索相关的包 apt-cache search php7 再安装 apt ...
- Spring 注解编程之模式注解
Spring 框架中有很多可用的注解,其中有一类注解称模式注解(Stereotype Annotations),包括 @Component, @Service,@Controller,@Reposit ...