MySQL的统计信息学习总结
统计信息概念
MySQL统计信息是指数据库通过采样、统计出来的表、索引的相关信息,例如,表的记录数、聚集索引page个数、字段的Cardinality....。MySQL在生成执行计划时,需要根据索引的统计信息进行估算,计算出最低代价(或者说是最小开销)的执行计划.MySQL支持有限的索引统计信息,因存储引擎不同而统计信息收集的方式也不同. MySQL官方关于统计信息的概念介绍几乎等同于无,不过对于已经接触过其它类型数据库的同学而言,理解这个概念应该不在话下。相对于其它数据库而言,MySQL统计信息无法手工删除。MySQL 8.0之前的版本,MySQL是没有直方图的。
统计信息参数
MySQL的InnoDB存储引擎的统计信息参数有7(个别版本有8个之多),如下所示:
MySQL 5.6.41 有8个参数:
mysql> show variables like 'innodb_stats%';
+--------------------------------------+-------------+
| Variable_name | Value |
+--------------------------------------+-------------+
| innodb_stats_auto_recalc | ON |
| innodb_stats_include_delete_marked | OFF |
| innodb_stats_method | nulls_equal |
| innodb_stats_on_metadata | OFF |
| innodb_stats_persistent | ON |
| innodb_stats_persistent_sample_pages | 20 |
| innodb_stats_sample_pages | 8 |
| innodb_stats_transient_sample_pages | 8 |
+--------------------------------------+-------------+
8 rows in set (0.00 sec)
MySQL 8.0.18 有7个参数:
mysql> show variables like 'innodb_stats%';
+--------------------------------------+-------------+
| Variable_name | Value |
+--------------------------------------+-------------+
| innodb_stats_auto_recalc | ON |
| innodb_stats_include_delete_marked | OFF |
| innodb_stats_method | nulls_equal |
| innodb_stats_on_metadata | OFF |
| innodb_stats_persistent | ON |
| innodb_stats_persistent_sample_pages | 20 |
| innodb_stats_transient_sample_pages | 8 |
+--------------------------------------+-------------+
关于这些参数的功能,下面做了一个大概的整理、收集。
|
参数名称 |
参数意义 |
|
innodb_stats_auto_recalc |
是否自动触发更新统计信息。当被修改的数据超过10%时就会触发统计信息重新统计计算 |
|
innodb_stats_include_delete_marked |
控制在重新计算统计信息时是否会考虑删除标记的记录。 |
|
innodb_stats_method |
对null值的统计方法 |
|
innodb_stats_on_metadata |
操作元数据时是否触发更新统计信息 |
|
innodb_stats_persistent |
统计信息是否持久化 |
|
innodb_stats_sample_pages |
不推荐使用,已经被innodb_stats_persistent_sample_pages替换 |
|
innodb_stats_persistent_sample_pages |
持久化抽样page数 |
|
innodb_stats_transient_sample_pages |
瞬时抽样page数 |
参数innodb_stats_auto_recalc
该参数innodb_stats_auto_recalc控制是否自动重新计算统计信息,当表中数据有大于10%被修改时就会重新计算统计信息(注意,由于统计信息重新计算是在后台发生,而且它是异步处理,这个可能存在延时,不会立即触发,具体见下面介绍)。如果关闭了innodb_stats_auto_recalc,需要通过analyze table来保证统计信息的准确性。不管有没有开启全局变量innodb_stats_auto_recalc。即使innodb_stats_auto_recalc=OFF时,当新索引被增加到表中,所有索引的统计信息会被重新计算并且更新到innodb_index_stats表上。
下面验证一下系统变量innodb_stats_auto_recalc=OFF时,创建索引时,会触发该表所有索引重新统计计算。
mysql> set global innodb_stats_auto_recalc=off;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'innodb_stats_auto_recalc%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_stats_auto_recalc | OFF |
+--------------------------+-------+
1 row in set (0.00 sec)
mysql> select * from mysql.innodb_index_stats
-> where database_name='MyDB' and table_name = 'test';
+---------------+------------+-----------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+-----------------+---------------------+--------------+------------+-------------+-----------------------------------+
| MyDB | test | GEN_CLUST_INDEX | 2019-10-28 14:54:48 | n_diff_pfx01 | 2 | 1 | DB_ROW_ID |
| MyDB | test | GEN_CLUST_INDEX | 2019-10-28 14:54:48 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
| MyDB | test | GEN_CLUST_INDEX | 2019-10-28 14:54:48 | size | 1 | NULL | Number of pages in the index |
+---------------+------------+-----------------+---------------------+--------------+------------+-------------+-----------------------------------+
3 rows in set (0.00 sec)
mysql> create index ix_test_name on test(name);
mysql> select * from mysql.innodb_index_stats
-> where database_name='MyDB' and table_name = 'test';
+---------------+------------+-----------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+-----------------+---------------------+--------------+------------+-------------+-----------------------------------+
| MyDB | test | GEN_CLUST_INDEX | 2019-10-28 22:02:07 | n_diff_pfx01 | 2 | 1 | DB_ROW_ID |
| MyDB | test | GEN_CLUST_INDEX | 2019-10-28 22:02:07 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
| MyDB | test | GEN_CLUST_INDEX | 2019-10-28 22:02:07 | size | 1 | NULL | Number of pages in the index |
| MyDB | test | ix_test_name | 2019-10-28 22:02:07 | n_diff_pfx01 | 1 | 1 | name |
| MyDB | test | ix_test_name | 2019-10-28 22:02:07 | n_diff_pfx02 | 2 | 1 | name,DB_ROW_ID |
| MyDB | test | ix_test_name | 2019-10-28 22:02:07 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
| MyDB | test | ix_test_name | 2019-10-28 22:02:07 | size | 1 | NULL | Number of pages in the index |
+---------------+------------+-----------------+---------------------+--------------+------------+-------------+-----------------------------------+
7 rows in set (0.00 sec)
下面是我另外一个测试,全局变量innodb_stats_auto_recalc=ON的情况,修改表的属性STATS_AUTO_RECALC=0,然后新建索引,测试验证发现也会重新计算所有索引的统计信息。
mysql> select * from mysql.innodb_index_stats
-> where database_name='MyDB' and table_name = 'test';
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| MyDB | test | PRIMARY | 2019-10-30 15:49:00 | n_diff_pfx01 | 0 | 1 | id |
| MyDB | test | PRIMARY | 2019-10-30 15:49:00 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
| MyDB | test | PRIMARY | 2019-10-30 15:49:00 | size | 1 | NULL | Number of pages in the index |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
3 rows in set (0.01 sec)
mysql> ALTER TABLE test STATS_AUTO_RECALC=0;
Query OK, 0 rows affected (0.27 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from mysql.innodb_index_stats
-> where database_name='MyDB' and table_name = 'test';
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| MyDB | test | PRIMARY | 2019-10-30 15:49:00 | n_diff_pfx01 | 0 | 1 | id |
| MyDB | test | PRIMARY | 2019-10-30 15:49:00 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
| MyDB | test | PRIMARY | 2019-10-30 15:49:00 | size | 1 | NULL | Number of pages in the index |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
3 rows in set (0.00 sec)
mysql> CREATE INDEX ix_test_name ON test(name);
Query OK, 0 rows affected (1.41 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from mysql.innodb_index_stats
-> where database_name='MyDB' and table_name = 'test';
+---------------+------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
| MyDB | test | PRIMARY | 2019-10-30 15:54:22 | n_diff_pfx01 | 0 | 1 | id |
| MyDB | test | PRIMARY | 2019-10-30 15:54:22 | n_leaf_pages | 1 | NULL | Number of leaf pages in the index |
| MyDB | test | PRIMARY | 2019-10-30 15:54:22 | size | 1 | NULL | Number of pages in the index |
| MyDB | test | ix_test_name | 2019-10-30 15:54:22 | n_diff_pfx01 | 999 | 17 | name |
| MyDB | test | ix_test_name | 2019-10-30 15:54:22 | n_diff_pfx02 | 999 | 17 | name,id |
| MyDB | test | ix_test_name | 2019-10-30 15:54:22 | n_leaf_pages | 17 | NULL | Number of leaf pages in the index |
| MyDB | test | ix_test_name | 2019-10-30 15:54:22 | size | 18 | NULL | Number of pages in the index |
+---------------+------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
7 rows in set (0.00 sec)
mysql>
关于统计信息重新计算延时,官方的介绍如下:
Because of the asynchronous nature of automatic statistics recalculation, which occurs in the background, statistics may not be recalculated instantly after running a DML operation that affects more than 10% of a table, even when innodb_stats_auto_recalc is enabled. Statistics recalculation can be delayed by few seconds in some cases. If up-to-date statistics are required immediately, run ANALYZE TABLE to initiate a synchronous (foreground) recalculation of statistics
参数innodb_stats_include_delete_marked
重新计算统计信息时是否会考虑删除标记的记录.
innodb_stats_include_delete_marked can be enabled to ensure that delete-marked records are included when calculating persistent optimizer statistics.
网上有个关于innodb_stats_include_delete_marked的建议,如下所示,但是限于经验无法对这个建议鉴定真伪,个人觉得还是选择默认关闭,除非有特定场景真有这种需求。
· innodb_stats_include_delete_marked建议设置开启,这样可以针对未提交事务中删除的数据也收集统计信息。
By default, InnoDB reads uncommitted data when calculating statistics. In the case of an uncommitted transaction that deletes rows from a table, delete-marked records are excluded when calculating row estimates and index statistics, which can lead to non-optimal execution plans for other transactions that are operating on the table concurrently using a transaction isolation level other than READ UNCOMMITTED. To avoid this scenario, innodb_stats_include_delete_marked can be enabled to ensure that delete-marked records are included when calculating persistent optimizer statistics.
When innodb_stats_include_delete_marked is enabled, ANALYZE TABLE considers delete-marked records when recalculating statistics.innodb_stats_include_delete_marked is a global setting that affects all InnoDB tables, and it is only applicable to persistent optimizer statistics.innodb_stats_include_delete_marked was introduced in MySQL 5.6.34.
参数innodb_stats_method
Specifies how InnoDB index statistics collection code should treat NULLs. Possible values are NULLS_EQUAL (default), NULLS_UNEQUAL and NULLS_IGNORED
· 当变量设置为nulls_equal时,所有NULL值都被视为相同(即,它们都形成一个 value group)。
· 当变量设置为nulls_unequal时,NULL值不被视为相同。相反,每个NULL value 形成一个单独的 value group,大小为 1。
· 当变量设置为nulls_ignored时,将忽略NULL值。
更多详细信息,参考官方文档“InnoDB and MyISAM Index Statistics Collection”,另外,还有一个系统变量myisam_stats_method控制MyISAM表对Null值的统计方法。
mysql> show variables like 'myisam_stat%';
+---------------------+---------------+
| Variable_name | Value |
+---------------------+---------------+
| myisam_stats_method | nulls_unequal |
+---------------------+---------------+
1 row in set (0.00 sec)
参数innodb_stats_on_metadata
参数innodb_stats_on_metadata在MySQL 5.6.6之前的版本默认开启(默认值为O),每当查询information_schema元数据库里的表时(例如,information_schema.TABLES、information_schema.TABLE_CONSTRAINTS .... )或show table status、SHOW INDEX..这类操作时,Innodb还会随机提取其他数据库每个表索引页的部分数据,从而更新information_schema.STATISTICS表,并返回刚才查询的结果。当你的表很大,且数量很多时,耗费的时间就很长,以致很多经常不访问的数据也会进入Innodb_buffer_pool缓冲池中,造成池污染,关闭这个参数,可以加快对于schema库表访问,同时也可以改善查询执行计划的稳定性(对于Innodb表的访问)。所以从MySQL 5.6.6这个版本开始,此参数默认为OFF。
注意:仅当优化器统计信息配置为非持久性时,此选项才生效。这个参数开启的时候,InnoDB会更新非持久统计信息
官方文档的介绍如下:
innodb_stats_on_metadata
|
Property |
Value |
|
Command-Line Format |
--innodb-stats-on-metadata[={OFF|ON}] |
|
System Variable |
innodb_stats_on_metadata |
|
Scope |
Global |
|
Dynamic |
Yes |
|
Type |
Boolean |
|
Default Value |
OFF |
This option only applies when optimizer statistics are configured to be non-persistent. Optimizer statistics are not persisted to disk when innodb_stats_persistent is disabled or when individual tables are created or altered with STATS_PERSISTENT=0. For more information, see Section 14.8.11.2, “Configuring Non-Persistent Optimizer Statistics Parameters”.
When innodb_stats_on_metadata is enabled, InnoDB updates non-persistent statistics when metadata statements such as SHOW TABLE STATUS or when accessing the INFORMATION_SCHEMA.TABLES or INFORMATION_SCHEMA.STATISTICS tables. (These updates are similar to what happens for ANALYZE TABLE.) When disabled,InnoDB does not update statistics during these operations. Leaving the setting disabled can improve access speed for schemas that have a large number of tables or indexes. It can also improve the stability of execution plans for queries that involve InnoDB tables.
To change the setting, issue the statement SET GLOBAL innodb_stats_on_metadata=mode, where mode is either ON or OFF (or 1 or 0). Changing the setting requires privileges sufficient to set global system variables (see Section 5.1.8.1, “System Variable Privileges”) and immediately affects the operation of all connections
参数innodb_stats_persistent
此参数控制统计信息是否持久化,如果此参数启用,统计信息将会保存到mysql数据库的innodb_table_stats和innodb_index_stats表中。从MySQL 5.6.6开始,MySQL默认使用持久化的统计信息,即默认INNODB_STATS_PERSISTENT=ON。 Persistent optimizer statistics were introduced in MySQL 5.6.2 and were made the default in MySQL 5.6.6。设置此参数之后我们就不需要实时去收集统计信息了,因为实时收集统计信息在高并发下可能会造成一定的性能上影响,并且会导致执行计划有所不同。
另外,我们可以使用表的建表参数(STATS_PERSISTENT,STATS_AUTO_RECALC和STATS_SAMPLE_PAGES子句)来覆盖系统变量设置的值,建表选项可以在CREATE TABLE或ALTER TABLE语句中指定。表上面指定的参数会覆盖全局变量,也就是说优先级要高于全局变量。例子如下:
mysql> ALTER TABLE test STATS_PERSISTENT=1;
Query OK, 0 rows affected (0.15 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE test STATS_AUTO_RECALC=0;
Query OK, 0 rows affected (0.27 sec)
Records: 0 Duplicates: 0 Warnings: 0
持久化统计新存储在mysql.innodb_index_stats和mysql.innodb_table_stats中,这两个表的定义如下:
innodb_table_stats:
|
Column name |
Description |
|
database_name |
数据库名 |
|
table_name |
表名,分区名或者子分区名 |
|
last_update |
统计信息最后一次更新时间戳 |
|
n_rows |
表中数据行数 |
|
clustered_index_size |
聚集索引page个数 |
|
sum_of_other_index_sizes |
非聚集索引page个数 |
innodb_index_stats:
|
Column name |
Description |
|
database_name |
数据库名 |
|
table_name |
表名,分区名或者子分区名 |
|
index_name |
索引名 |
|
last_update |
最后一次更新时间戳 |
|
stat_name |
统计信息名 |
|
stat_value |
统计信息不同值个数 |
|
sample_size |
采样page个数 |
|
stat_description |
描述 |
非持久化(Non-persistent optimizer statistics) 存储在内存里,并在服务器关闭时丢失。某些业务和某些条件下也会定期更新统计数据。 注意,这里保存在内存指保存在哪里呢?
Optimizer statistics are not persisted to disk when innodb_stats_persistent=OFF or when individual tables are created or altered with STATS_PERSISTENT=0. Instead, statistics are stored in memory, and are lost when the server is shut down. Statistics are also updated periodically by certain operations and under certain conditions.
其实这里指保存在内层表(MEMROY TABLE),下面有简单介绍。
参数innodb_stats_persistent_sample_pages
如果参数innodb_stats_persistent设置为ON,该参数表示ANALYZE TABLE更新Cardinality值时每次采样页的数量。默认值为20个页面。innodb_stats_persistent_sample_pages太少会导致统计信息不够准确,太多会导致分析执行太慢。
我们可以在创建表的时候对不同的表指定不同的page数量、是否将统计信息持久化到磁盘上、是否自动收集统计信息,如下所示:
CREATE TABLE `test` (
`id` int(8) NOT NULL auto_increment,
`data` varchar(255),
`date` datetime,
P
PRIMARY KEY (`id`),
I
INDEX `DATE_IX` (`date`)
) ENGINE=InnoDB,
STATS_PERSISTENT=1,
STATS_AUTO_RECALC=1,
STATS_SAMPLE_PAGES=25;
参数innodb_stats_sample_pages
已弃用. 已用innodb_stats_transient_sample_pages 替代。
参数innodb_stats_transient_sample_pages
innodb_stats_transient_sample_pages控制采样pages个数,默认为8。Innodb_stats_transient_sample_pages可以runtime设置
innodb_stats_transient_sample_pages在innodb_stats_persistent=0的时候影响采样。注意点:
1.若值太小,会导致评估不准
2.若果值太大,会导致disk read增加。
3.会生产很不同的执行计划,因为统计信息不同。
还有一个参数information_schema_stats_expiry。这个参数的作用如下:
· 对于INFORMATION_SCHEMA下的STATISTICS表和TABLES表中的信息,8.0中通过缓存的方式,以提高查询的性能。可以通过设置information_schema_stats_expiry参数设置缓存数据的过期时间,默认是86400秒。查询这两张表的数据的时候,首先是到缓存中进行查询,缓存中没有缓存数据,或者缓存数据过期了,查询会从存储引擎中获取最新的数据。如果需要获取最新的数据,可以通过设置information_schema_stats_expiry参数为0或者ANALYZE TABLE操作。
查看统计信息
统计信息分持久化(PERSISTENT)与非持久化统计数据(TRANSIENT),那么它们存储在哪里呢?
· 持久化统计数据
存储在mysql.innodb_index_stats和mysql.innodb_table_stats中
· 非持久化统计数据
MySQL 8.0之前,存储在information_schema.INDEXES和information_schema.TABLES中, 那么MySQL8.0之后放在那里呢? INFORMATION_SCHEMA.TABLES、INFORMATION_SCHEMA.STATISTICS、INNODB_INDEXES。官方文档说非持久化统计信息放在内存中,其实就是内存表(MEMORY Table)中。
我们可以用下面脚本查看持久化统计信息信息,mysql.innodb_index_stats的数据如何看懂,要搞懂stat_name和stat_value的具体含义:
select * from mysql.innodb_index_stats
where table_name = 'test';
select * from mysql.innodb_index_stats
where database_name='MyDB' and table_name = 'test';
stat_name=size时:stat_value表示索引的页的数量(Number of pages in the index)
stat_name=n_leaf_pages时:stat_value表示叶子节点的数量(Number of leaf pages in the index)
stat_name=n_diff_pfxNN时:stat_value表示索引字段上唯一值的数量,此处做一下具体说明:
*n_diff_pfxNN: NN代表数字(例如: 01,02等),当stat_name为n_diff_pfxNN时,stat_value列值显示索引的first column(即索引的最前索引列,从索引定义顺序的第一个列开始)列的唯一值数量,例如: 当NN为01时,stat_value列值就表示索引的第一个列的唯一值数量,当NN为02时,stat_value列值就表示索引的第一和第二个列的组合唯一值数量,以此类推。 此外,在stat_name = n_diff_pfxNN的情况下,stat_description列显示一个以逗号分隔的计算索引统计信息列的列表。
MySQL的直方图
MySQL 8.0推出了直方图(histogram), 直方图数据存放在information_schema.column_statistics这个系统表下,每行记录对应一个字段的直方图,以json格式保存。同时,新增了一个参数histogram_generation_max_mem_size来配置建立直方图内存大小。
直方图是数字数据分布的准确表示。对于RDBMS,直方图是特定列内数据分布的近似值。
mysql> show variables like 'histogram_generation_max_mem_size';
+-----------------------------------+----------+
| Variable_name | Value |
+-----------------------------------+----------+
| histogram_generation_max_mem_size | 20000000 |
+-----------------------------------+----------+
1 row in set (0.01 sec)
mysql>
mysql> desc information_schema.column_statistics;
+-------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-----+---------+-------+
| SCHEMA_NAME | varchar(64) | NO | | NULL | |
| TABLE_NAME | varchar(64) | NO | | NULL | |
| COLUMN_NAME | varchar(64) | NO | | NULL | |
| HISTOGRAM | json | NO | | NULL | |
+-------------+-------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
mysql>
MySQL的直方图有两种,等宽直方图和等高直方图。等宽直方图每个桶(bucket)保存一个值以及这个值累积频率;等高直方图每个桶需要保存不同值的个数,上下限以及累计频率等。MySQL会自动分配用哪种类型的直方图,有时候可以通过设置合适Buckets数量来实现。?
创建删除直方图
直方图数据会自动生成吗? MySQL的直方图比较特殊,不会在创建索引的时候自动生成直方图数据,需要手工执行 ANALYZE TABLE [table] UPDATE HISTOGRAM .... 这样的命令产生表上各列的直方图,默认情况下这些信息会被复制到备库。
ANALYZE TABLE tbl_name UPDATE HISTOGRAM ON col_name [, col_name] WITH N BUCKETS;
ANALYZE TABLE tbl_name DROP HISTOGRAM ON col_name [, col_name];
ANALYZE TABLE test UPDATE HISTOGRAM ON create_date,name WITH 16 BUCKETS;
注意:可指定BUCKETS的值,也可以不指定,它的取值范围为1到1024,如果不指定BUCKETS值的话,默认值是100。
我们测试如下,首先删除所有的直方图数据。然后使用下面SQL生成直方图数据。
ANALYZE TABLE test UPDATE HISTOGRAM ON name;
SELECT SCHEMA_NAME
,TABLE_NAME
,COLUMN_NAME
,HISTOGRAM->>'$."data-type"' AS 'DATA-TYPE'
,HISTOGRAM->>'$."sampling-rate"' AS SAMPLING_RATE
,HISTOGRAM->>'$."last-updated"' AS LAST_UPDATED
,HISTOGRAM->>'$."number-of-buckets-specified"' AS NUM_BUCKETS_SPECIFIED
,JSON_LENGTH(HISTOGRAM->>'$."buckets"') AS 'BUCKET-COUNT'
FROM INFORMATION_SCHEMA.COLUMN_STATISTICS
WHERE TABLE_NAME = 'test';
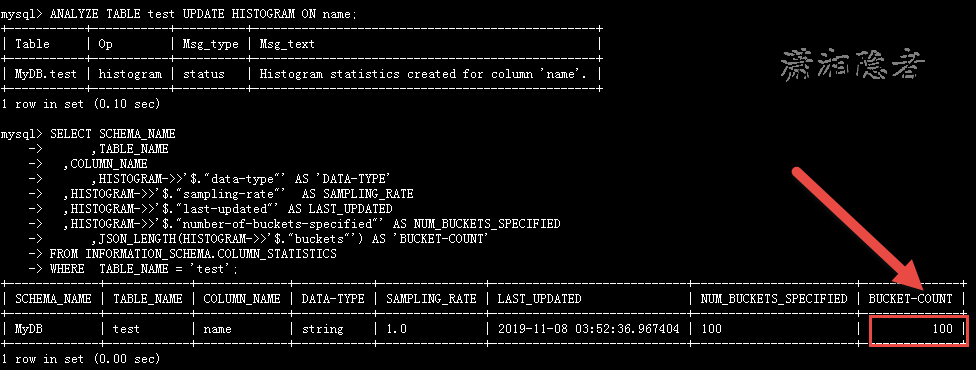
其实不是所有默认的BUCKETS都是100,如下所示,如果我将记录删除,只剩下49条记录,然后创建直方图,你会看到BUCKETS的数量为49,所有这个值还跟表的数据量有关系。如果数据量较大的话,默认是100。
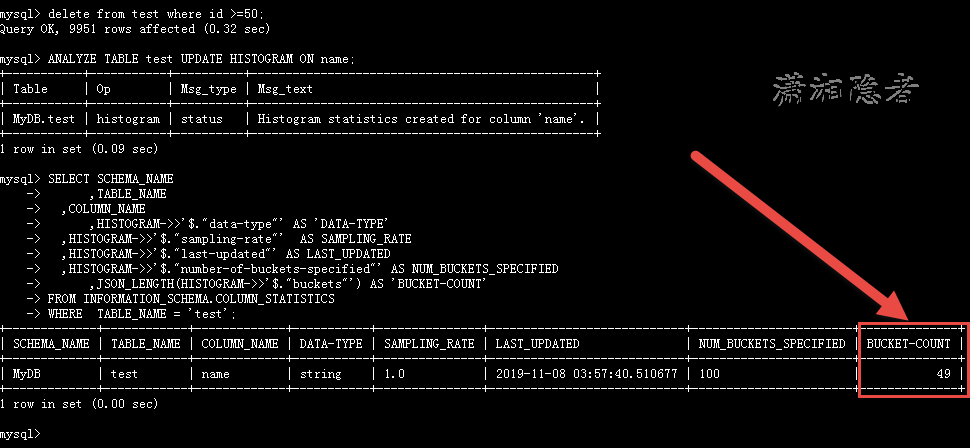
另外,如下测试所示,如果BUCKETS超过1024,就会报“ERROR 1690 (22003): Number of buckets value is out of range in 'ANALYZE TABLE'”
mysql> ANALYZE TABLE test UPDATE HISTOGRAM ON name WITH 1024 BUCKETS;
+-----------+-----------+----------+-------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+-----------+-----------+----------+-------------------------------------------------+
| MyDB.test | histogram | status | Histogram statistics created for column 'name'. |
+-----------+-----------+----------+-------------------------------------------------+
1 row in set (0.13 sec)
mysql> ANALYZE TABLE test UPDATE HISTOGRAM ON name WITH 1025 BUCKETS;
ERROR 1690 (22003): Number of buckets value is out of range in 'ANALYZE TABLE'
mysql>
删除删除直方图
--删除字段上的统计直方图信息
ANALYZE TABLE test DROP HISTOGRAM ON create_date
mysql> ANALYZE TABLE test DROP HISTOGRAM ON name;
+-----------+-----------+----------+-------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+-----------+-----------+----------+-------------------------------------------------+
| MyDB.test | histogram | status | Histogram statistics removed for column 'name'. |
+-----------+-----------+----------+-------------------------------------------------+
1 row in set (0.10 sec)
直方图信息查看
我们知道直方图的数据是以json格式保存的,直接将json格式展示出来,看起来非常不直观。其实有一些SQL可以解决这个问题。
SELECT SCHEMA_NAME, TABLE_NAME, COLUMN_NAME, JSON_PRETTY(HISTOGRAM)
FROM information_schema.column_statistics
WHERE TABLE_NAME='test'\G
SELECT SCHEMA_NAME
,TABLE_NAME
,COLUMN_NAME
,HISTOGRAM->>'$."data-type"' AS 'DATA-TYPE'
,HISTOGRAM->>'$."sampling-rate"' AS SAMPLING_RATE
,HISTOGRAM->>'$."last-updated"' AS LAST_UPDATED
,HISTOGRAM->>'$."histogram-type"' AS HISTOGRAM_TYPE
,HISTOGRAM->>'$."number-of-buckets-specified"' AS NUM_BUCKETS_SPECIFIED
,JSON_LENGTH(HISTOGRAM->>'$."buckets"') AS 'BUCKET-COUNT'
FROM INFORMATION_SCHEMA.COLUMN_STATISTICS
WHERE TABLE_NAME = 'test';
SELECT FROM_BASE64(SUBSTRING_INDEX(v, ':', -1)) value, concat(round(c*100,1),'%') cumulfreq,
CONCAT(round((c - LAG(c, 1, 0) over()) * 100,1), '%') freq
FROM information_schema.column_statistics, JSON_TABLE(histogram->'$.buckets',
'$[*]' COLUMNS(v VARCHAR(60) PATH '$[0]', c double PATH '$[1]')) hist
WHERE schema_name = 'MyDB' and table_name = 'test' and column_name = 'name';
SELECT v value, concat(round(c*100,1),'%') cumulfreq,
CONCAT(round((c - LAG(c, 1, 0) over()) * 100,1), '%') freq
FROM information_schema.column_statistics, JSON_TABLE(histogram->'$.buckets',
'$[*]' COLUMNS(v VARCHAR(60) PATH '$[0]', c double PATH '$[1]')) hist
WHERE schema_name = 'MyDB' and table_name = 'test' and column_name = 'name';
更新统计信息
非持久统计统计信息也会触发自动更新,非持久化统计信息在以下情况会被自动更新,官方文档介绍如下:
Non-persistent optimizer statistics are updated when:
Running ANALYZE TABLE.
Running SHOW TABLE STATUS, SHOW INDEX, or querying the INFORMATION_SCHEMA.TABLES or INFORMATION_SCHEMA.STATISTICS tables with theinnodb_stats_on_metadata option enabled.
The default setting for innodb_stats_on_metadata is OFF. Enabling innodb_stats_on_metadata may reduce access speed for schemas that have a large number of tables or indexes, and reduce stability of execution plans for queries that involve InnoDB tables. innodb_stats_on_metadata is configured globally using a SETstatement.
SET GLOBAL innodb_stats_on_metadata=ON
Note
innodb_stats_on_metadata only applies when optimizer statistics are configured to be non-persistent (when innodb_stats_persistent is disabled).
Starting a mysql client with the --auto-rehash option enabled, which is the default. The auto-rehash option causes all InnoDB tables to be opened, and the open table operations cause statistics to be recalculated.
To improve the start up time of the mysql client and to updating statistics, you can turn off auto-rehash using the --disable-auto-rehash option. The auto-rehashfeature enables automatic name completion of database, table, and column names for interactive users.
A table is first opened.
InnoDB detects that 1 / 16 of table has been modified since the last time statistics were updated.
简单整理如下:
1 执行ANALYZE TABLE
2 innodb_stats_on_metadata=ON情况下,执SHOW TABLE STATUS, SHOW INDEX, 查询 INFORMATION_SCHEMA下的TABLES, STATISTICS
3 启用--auto-rehash功能情况下,使用mysql client登录
4 表第一次被打开
5 距上一次更新统计信息,表1/16的数据被修改
持久统计信息的统计信息更新上面已经有介绍,还有一种方法就是手动更新统计信息,
1、手动更新统计信息,注意执行过程中会加读锁:
ANALYZE TABLE TABLE_NAME;
2、如果更新后统计信息仍不准确,可考虑增加表采样的数据页,两种方式可以修改:
1) 全局变量INNODB_STATS_PERSISTENT_SAMPLE_PAGES,默认为20;
2) 单个表可以指定该表的采样:
ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=100;
经测试,此处STATS_SAMPLE_PAGES的最大值是65535,超出会报错。
mysql> ALTER TABLE test STATS_SAMPLE_PAGES=65535;
Query OK, 0 rows affected (0.12 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE test STATS_SAMPLE_PAGES=65536;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '65536' at line 1
mysql>
参考资料:
https://dev.mysql.com/doc/refman/8.0/en/innodb-persistent-stats.html
https://dev.mysql.com/doc/refman/8.0/en/index-statistics.html
https://dev.mysql.com/doc/refman/8.0/en/innodb-performance-optimizer-statistics.html
https://www.percona.com/blog/2019/10/29/column-histograms-on-percona-server-and-mysql-8-0/ 重点
http://chinaunix.net/uid-31396856-id-5787793.html
https://mysqlserverteam.com/histogram-statistics-in-mysql/
https://mp.weixin.qq.com/s/698g5lm9CWqbU0B_p0nLMw?
MySQL的统计信息学习总结的更多相关文章
- Atitit mysql数据库统计信息
Atitit mysql数据库统计信息 SELECT table_name, table_rows, index_length, data_length, auto_increment, create ...
- MySQL索引统计信息更新相关的参数
MySQL统计信息相关的参数: 1. innodb_stats_on_metadata(是否自动更新统计信息),MySQL 5.7中默认为关闭状态 仅在统计信息配置为非持久化的时候生效. 也就是说在i ...
- mysql收集统计信息
一.手动 执行Analyze table innodb和myisam存储引擎都可以通过执行“Analyze table tablename”来收集表的统计信息,除非执行计划不准确,否则不要轻易执行该 ...
- MySQL 8.0 中统计信息直方图的尝试
直方图是表上某个字段在按照一定百分比和规律采样后的数据分布的一种描述,最重要的作用之一就是根据查询条件,预估符合条件的数据量,为sql执行计划的生成提供重要的依据在MySQL 8.0之前的版本中,My ...
- mysql-5.7 持久化统计信息详解
一.持久化统计信息的意义: 统计信息用于指导mysql生成执行计划,执行计划的准确与否直接影响到SQL的执行效率:如果mysql一重启 之前的统计信息就没有了,那么当SQL语句来临时,那么mysql就 ...
- curl -s 不输出统计信息
curl -s 不输出统计信息 学习了:https://blog.csdn.net/qinyushuang/article/details/44114583
- MySQL统计信息以及执行计划预估方式初探
数据库中的统计信息在不同(精确)程度上描述了表中数据的分布情况,执行计划通过统计信息获取符合查询条件的数据大小(行数),来指导执行计划的生成.在以Oracle和SQLServer为代表的商业数据库,和 ...
- MySQL InnoDB配置统计信息
MySQL InnoDB配置统计信息 1. 配置持久化(Persistent)统计信息参数 1.1 配置自动触发更新统计信息参数 1.2 配置每张表的统计参数 1.3 配置InnoDB优化器统计信息的 ...
- MySQL统计信息简介
作者:王小龙@网易乐得DBA 原文地址: http://mp.weixin.qq.com/s/698g5lm9CWqbU0B_p0nLMw MySQL执行SQL会经过SQL解析和查询优化的过程,解析器 ...
随机推荐
- phpexcel 导出方法
Vendor("PHPExcel.PHPExcel"); Vendor("PHPExcel.PHPExcel.IOFactory"); Vendor(" ...
- Python3行代码之——截图工具
最近工作需要个定时截图的小工具,用Python实现比较急直接上代码 from PIL import ImageGrab im = ImageGrab.grab() im.save(addr,'jpeg ...
- 基于SpringBoot+WebSocket搭建一个简单的多人聊天系统
前言 今天闲来无事,就来了解一下WebSocket协议.来简单了解一下吧. WebSocket是什么 首先了解一下WebSocket是什么?WebSocket是一种在单个TCP连接上进行全双工 ...
- ELK 学习笔记之 elasticsearch elasticsearch.yml配置概述
elasticsearch.yml配置概述: 设置集群名字 cluster.name 定义节点名称 node.name 节点作为master,但是不负责存储数据,只是协调. node.master: ...
- Spring框架学习笔记(4)——SSM整合以及创建Maven自定义模版
Spring+Spring MVC+MyBatis+Maven SSM整合的核心还是Spring+MyBatis的整合,回顾一下MyBatis操作数据库流程,我们是使用一个SQLSessionFact ...
- 创建一个 Laravel 项目
创建一个 Laravel 项目,首先需要安装 Composer ,如果没有安装的参考 https://docs.phpcomposer.com/00-intro.html 一.安装 Laravel 安 ...
- python编程基础之二十七
列表生成式:[exp for iter_var in iterable] 同样也会有字典生成式,集合生成式,没有元组生成式,元组生成式的语法被占用了 字典生成式,集合生成式,就是外面那个括号换成{} ...
- 基于OAuth 2.0的第三方认证 -戈多编程
引用(http://www.cnblogs.com/artech/p/oauth-01.html) OAuth 2.0的角色 获得资源拥有者授权的第三方应用请求受保护的资源采用的不是授权者的凭证,所有 ...
- python程序调用C/C++代码
这篇用来记录在些模拟Canoe生成CAN数据桢工具时遇到的问题, 生成CAN数据桢,主要分为两个关注点: 1.如何从can信号名获取到can信号的ID长度以及信号的起始位,并将信号值按照一定的规则填写 ...
- 写在Python学习前
Python是一门非常有意思的语言,不需要太多的语言基础,就可以实现自己想要的操作.许多非计算机专业的学生都可以利用词云分析.分词.画图等实现自己想要的东西.学习Python和学习其他语言一样,需要耐 ...