DataOps系列丨数据的“资产负债表”与“现状”

作者:DataPipeline CEO 陈诚
《跨越鸿沟》的作者Geoffrey Moore曾说“没有数据,运营企业就像一个又聋又瞎的人在高速上开车一样”。数据的价值从未像现在这样被企业重视,IDC预估,到2020年,全世界会有44万亿G数据,每一个世界500强的CEO和独角兽创业公司的创始人都在思考并实践如何能用数据支持、改造、创新业务,以获得新的增长。
尽管越来越多的人认同数据是极为重要的资产,但由于数据全生命周期管理和使用的复杂度,导致过去的数据管理方法论虽然正确且全面,但往往在推进落地的过程中容易陷入高投入慢节奏的怪圈。 投入产出比不清晰,多数项目半途夭折,已经成为多数企业在数据管理方面不可言说的痛,但遗憾的是大多数企业仍然没有找到成熟有效的理念与方法论来组织、推动和指引数据价值的落地。Thomas Redman博士在《哈佛商业评论》推荐的《数据驱动:从最重要的资产中获利》中写到“当数据冒烟的时候,业务就会起火”,形象地点出了数据时效性低、质量差等问题对业务发展的重大影响。 基于上述背景,在这篇文章中我们将讨论DataOps,一种通过文化、流程和工具来帮助大型公司在内部推动数据价值落地,完成数字化业务转型的理念。
一、数据的“资产负债表”
当下,数据量的增长态势已经远远超出了预期,很容易让我们产生一种错觉,仿佛这样就拥有了数据资产。
但我们认为这是对事实的一种简化。单就存储庞大的数据而言,企业就要为此付出大量成本。例如,如果有100PB的数据,存储在亚马逊云服务AWS S3上一年就需要花费2500万美元。如果要让数据发挥价值,那么数据的采集流转、处理计算、质量监测以及提供数据服务的资源成本和人力成本更是会快速上升。 在这种情况下,如果我们制作一个企业的“数据资产负债表”,到底会有多少数据是企业真正的资产?如何才能增加企业的数据资产呢?
问题看似简单,但很少有企业能在深入思考后得出严谨的回答。导致目前在使用数据的过程中存在“多、乱、慢、差”等情况,严重降低和阻碍了数据发挥作用的价值与效率。所以,只有像经营公司一样精细化地经营数据,数据才能从负债变成资产。
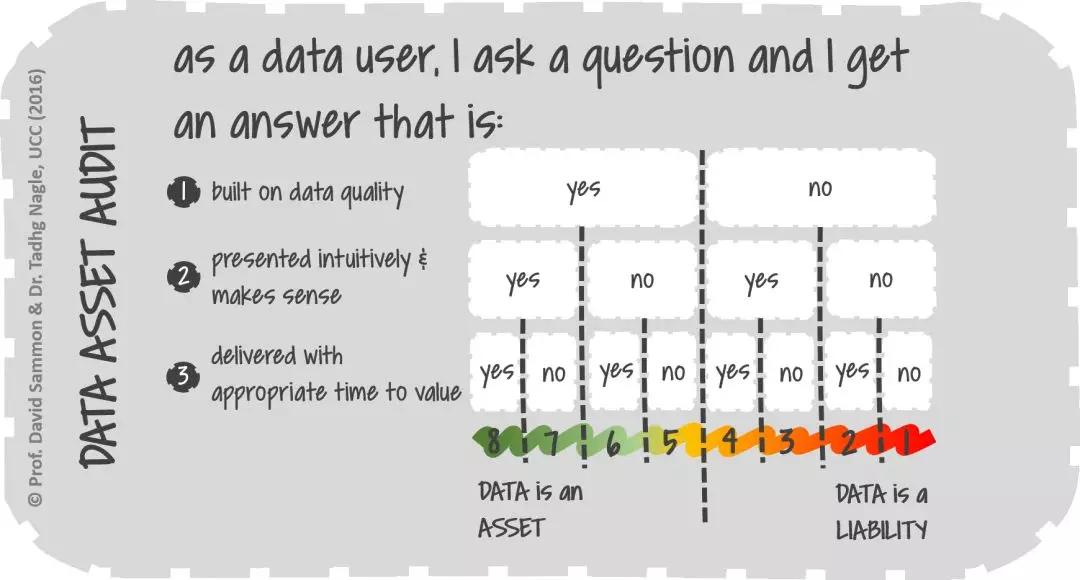
二、当前的数据现状
若想实现精细化运营,就不得不迎接种种难题。当前,拥有几百上千个内外部数据源的组织越来越多,其中包括各种业务、流程、客户数据,结构化、半结构化、非结构化数据。如果再考虑到未来5G和区块链带来的应用级影响,将又会是一种难以言说的痛。 在这种复杂异构的背景下,企业一方面缺少高效整合数据的方法和工具,另一方面更缺失能从这些数据中寻找规律,发掘价值的人才和文化,因此让理解、整合数据变得雪上加霜。而这恰恰是所有数据使用的起点,如果没有成熟高效的应对之道,数据驱动业务将会沦为空谈。

除了数据源数量和类型的不断增多,业务本身也在不断地进化调整,从而导致其产生的数据结构或元数据也随之发生改变,以上种种会引发一系列数据链路的连锁反应。
遗憾的是,很多企业制定元数据架构时通常是静态的,可以理解当下的数据架构和含义,但无法在业务的快速迭代发展中,始终保持与业务语义的一致,以致最后逐渐丧失指导数据分析师理解业务的能力,造成数据分析时统计口径不一致等情况,给企业进行重大决策时造成混乱。
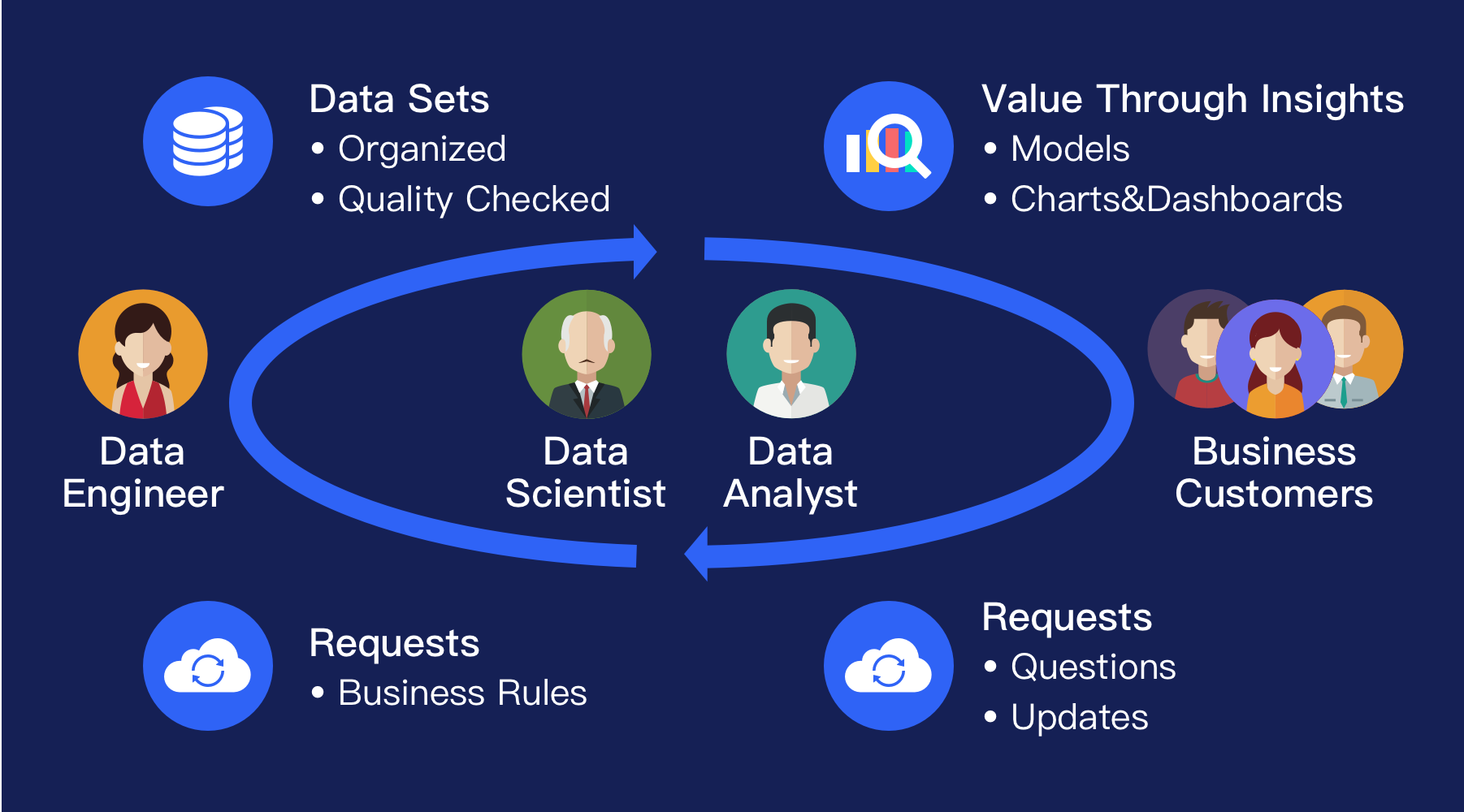
当业务部门希望使用数据来辅助决策或者创造新的商业模式时,通常有两个时效性的要求:一是满足数据需求的速度,二是对于所需数据的延迟性。因为业务创新的关键点在于能否快速满足市场需求,不仅需要用数据快速测算市场规模,更需要在时间窗口打开的时机内提供相应的产品和服务从而占领市场。而这一过程越来越受数据供给速度及时效性的影响,例如银行业的实时风控系统,零售业的实时营销系统,工业界的数字孪生系统,都是业务创新对数据实时性要求非常高的典型。而大多数企业的数据部门在这两点的满足上是捉襟见肘的。

数据被使用只是万里长征的第一步,接下来数据质量差的问题会接踵而至。目前,企业经营者和高管要么不知道数据质量存在问题,要么就是以鸵鸟心态回避和掩盖问题。Gartner的数据质量市场调查显示,糟糕的数据质量平均每年会带来 1500 万美元的损失。尽管所有企业都认同数据质量的重要性,但Gartner认为仍有84%的企业的数据质量处于“不成熟”阶段。损失金钱只是硬币的一面,又有多少公司因为数据质量差,缺乏信任,而错失了创造大量收入的机会呢? 最后,数据安全与隐私也是亟待关注的问题。每年都有许多公司因为数据泄露而蒙受声誉和财务上的双重损失,欧盟已经制定了GDPR的标准和规则,并且对包括Google在内的许多科技巨头开出了数以亿计的罚单,同时我国也在相关法律法规的制定流程中。数据的安全与隐私问题是一个非常关键的点,在安全合规的范围内充分发挥数据价值是DataOps的关键点之一,而这并不仅是技术问题。而是在安全合规的前提下,最大限度赋予组织内部使用数据权限灵活度的问题。
三、现状之下的反思
大多数时候,数据出现问题并不仅仅是数据部门的原因,更多是组织架构及配合的问题。相较于追责某些工具,反而应该思考文化在其中扮演的角色。因此,是时候深入思考这些问题背后的“元问题”了。

我们应该用何种理念和方法来面对这个“元问题”?不妨先从DataOps着手。
接下来DataPipeline将集中讨论「DataOps与企业如何增强数据管理」的问题,本文首先交代了数据管理目前的现状以及DataOps出现的背景。
后面将陆续从「DataOps理念及设计原则」、「DataOps的组织架构与挑战」、「DataOps的技术考量」等角度进行全方位地解读。
DataOps系列丨数据的“资产负债表”与“现状”的更多相关文章
- 智能合约语言 Solidity 教程系列4 - 数据存储位置分析
写在前面 Solidity 是以太坊智能合约编程语言,阅读本文前,你应该对以太坊.智能合约有所了解, 如果你还不了解,建议你先看以太坊是什么 这部分的内容官方英文文档讲的不是很透,因此我在参考Soli ...
- 使用GDAL工具对FY3系列卫星数据进行校正
本文档主要对如何使用GDAL提供的工具对FY3系列卫星数据进行校正处理.FY3系列卫星提供的数据一般是以HDF5格式下发,一个典型的FY3A和FY3B的数据文件名如下: FY3A_MERSI_GBAL ...
- 9.9 翻译系列:数据注解特性之--MaxLength 【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/maxlength-minlength-dataannotations-attribut ...
- 9.3 翻译系列:数据注解特性之Key【EF 6 Code-First 系列】
原文链接:http://www.entityframeworktutorial.net/code-first/key-dataannotations-attribute-in-code-first.a ...
- 9.2 翻译系列:数据注解特性之---Column【EF 6 Code First系列】
原文链接:http://www.entityframeworktutorial.net/code-first/column-dataannotations-attribute-in-code-firs ...
- 9.1 翻译系列:数据注解特性之----Table【EF 6 Code-First 系列】
原文地址:http://www.entityframeworktutorial.net/code-first/table-dataannotations-attribute-in-code-first ...
- 9.8 翻译系列:数据注解特性之--Required 【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/required-attribute-dataannotations-in-code-f ...
- 9.11 翻译系列:数据注解特性之--Timestamp【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/TimeStamp-dataannotations-attribute-in-code- ...
- 9.12 翻译系列:数据注解特性之ConcurrencyCheck【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/concurrencycheck-dataannotations-attribute-i ...
随机推荐
- centOS7.3 6忘记密码/修改root密码
RedHat最近升级了centos linux操作系统,更新为centos7,更新幅度之大,连红帽官方的认证RHCE也进行了升级,认证必须使用rhel7,可见红帽官方对centos7的重视程度. 最新 ...
- python的自定义函数
今天想把上次参考着网上教程写的scrapy爬虫改写成requests和beautifulsoup的普通爬虫,写着写着发现自己对python的自定义函数还不是太熟悉(自己TCL了.........流泪) ...
- 并发编程-concurrent指南-Lock
既然都可以通过synchronized来实现同步访问了,那么为什么还需要提供Lock?这个问题将在下面进行阐述.本文先从synchronized的缺陷讲起,然后再讲述java.util.concurr ...
- 解决Spring的java项目打包后执行出现“无法读取方案文档...“、“原因为 1) 无法找到文档; 2) 无法读取文档; 3) 文档的根元素不是...”问题
问题 一个用Spring建的java项目,在Eclipse或idea中运行正常,为什么打包后运行出现如下错误呢? 2019/07/10/19:04:07 WARN [main] org.springf ...
- iOS 国际化 (国际化文字内容不改变,app名字国际化,一键切换语言)
首先我们要分三个步骤讲解怎么一步步实现app名字国际化.内容国际化.一键切换国际化的: 一.app设置内容或者可以说是app名字或者可以说Info.Plist中的东西国际化 app名字国际化 1. ...
- JVM结构的简单梳理
#cnblogs_post_body img { width: 500px; height: auto; } JVM是什么 JVM的基本特性 JVM的流程结构 1. Java编译(Java Compi ...
- C#中的委托和事件(上篇)
每一个初学C#的程序猿,在刚刚碰到委托和事件的概念时,估计都是望而却步,茫然摸不到头脑的.百度一搜,关于概念介绍的文章大把大把的,当然也不乏深入浅出的好文章.可看完这些文章,大多数新手,估计也只是信心 ...
- Linux命令学习-mkdir命令
Linux中,mkdir命令的全称是make directory,即创建目录的意思. 假设当前处于wintest用户的主目录,路径为 /home/wintest ,存在文件夹testA,进入testA ...
- k8s学习 - 概念 - ReplicationController
k8s学习 - 概念 - ReplicationController 我们有了 pod,那么就需要对 pod 进行控制,就是同一个服务的 podv我需要启动几个?如果需要扩容了,怎么办?这里就有个控制 ...
- 【LightOJ - 1370】Bi-shoe and Phi-shoe
Bi-shoe and Phi-shoe Descriptions: 给出一些数字,对于每个数字找到一个欧拉函数值大于等于这个数的数,求找到的所有数的最小和. Input 输入以整数T(≤100)开始 ...