PHP中高级面试题 一个高频面试题:怎么保证缓存与数据库的双写一致性?
分布式缓存是现在很多分布式应用中必不可少的组件,但是用到了分布式缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
Cache Aside Pattern
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。
但是问题在于,这个缓存到底会不会被频繁访问到?举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。
实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低,用到缓存才去算缓存。其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。
查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
最初级的缓存不一致问题及解决方案
问题:先修改数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
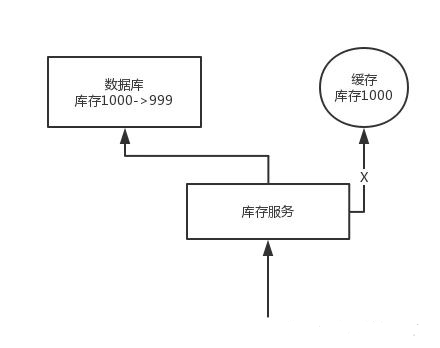
解决思路:先删除缓存,再修改数据库。如果数据库修改失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,则读数据库中旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。
完了,数据库和缓存中的数据不一样了。。。为什么上亿流量高并发场景下,缓存会出现这个问题?只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。
但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个 jvm 内部队列中。读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个 jvm 内部队列中。
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成。
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可。
待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。
如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回;如果请求等待的时间超过一定时长,那么这一次直接从数据库中读取当前的旧值。
高并发的场景下,该解决方案要注意的问题:
1、读请求长时阻塞由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时时间范围内返回。该解决方案,最大的风险点在于说,可能数据更新很频繁,导致队列中积压了大量更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库。
务必通过一些模拟真实的测试,看看更新数据的频率是怎样的。另外一点,因为一个队列中,可能会积压针对多个数据项的更新操作,因此需要根据自己的业务情况进行测试,可能需要部署多个服务,每个服务分摊一些数据的更新操作。如果一个内存队列里居然会挤压 100 个商品的库存修改操作,每隔库存修改操作要耗费 10ms 去完成,那么最后一个商品的读请求,可能等待 10 * 100 = 1000ms = 1s 后,才能得到数据,这个时候就导致读请求的长时阻塞。
一定要做根据实际业务系统的运行情况,去进行一些压力测试,和模拟线上环境,去看看最繁忙的时候,内存队列可能会挤压多少更新操作,可能会导致最后一个更新操作对应的读请求,会 hang 多少时间,如果读请求在 200ms 返回,如果你计算过后,哪怕是最繁忙的时候,积压 10 个更新操作,最多等待 200ms,那还可以的。如果一个内存队列中可能积压的更新操作特别多,那么你就要加机器,让每个机器上部署的服务实例处理更少的数据,那么每个内存队列中积压的更新操作就会越少。
其实根据之前的项目经验,一般来说,数据的写频率是很低的,因此实际上正常来说,在队列中积压的更新操作应该是很少的。像这种针对读高并发、读缓存架构的项目,一般来说写请求是非常少的,每秒的 QPS 能到几百就不错了。实际粗略测算一下如果一秒有 500 的写操作,如果分成 5 个时间片,每 200ms 就 100 个写操作,放到 20 个内存队列中,每个内存队列,可能就积压 5 个写操作。
每个写操作性能测试后,一般是在 20ms 左右就完成,那么针对每个内存队列的数据的读请求,也就最多 hang 一会儿,200ms 以内肯定能返回了。经过刚才简单的测算,我们知道,单机支撑的写 QPS 在几百是没问题的,如果写 QPS 扩大了 10 倍,那么就扩容机器,扩容 10 倍的机器,每个机器 20 个队列。
2、读请求并发量过高这里还必须做好压力测试,确保恰巧碰上上述情况的时候,还有一个风险,就是突然间大量读请求会在几十毫秒的延时 hang 在服务上,看服务能不能扛的住,需要多少机器才能扛住最大的极限情况的峰值。但是因为并不是所有的数据都在同一时间更新,缓存也不会同一时间失效,所以每次可能也就是少数数据的缓存失效了,然后那些数据对应的读请求过来,并发量应该也不会特别大。
3、多服务实例部署的请求路由可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过 Nginx 服务器路由到相同的服务实例上。比如说,对同一个商品的读写请求,全部路由到同一台机器上。可以自己去做服务间的按照某个请求参数的 hash 路由,也可以用 Nginx 的 hash 路由功能等等。
4、热点商品的路由问题,导致请求的倾斜万一某个商品的读写请求特别高,全部打到相同的机器的相同的队列里面去了,可能会造成某台机器的压力过大。就是说,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以其实要根据业务系统去看,如果更新频率不是太高的话,这个问题的影响并不是特别大,但是的确可能某些机器的负载会高一些。
PHP中高级面试题 一个高频面试题:怎么保证缓存与数据库的双写一致性?的更多相关文章
- PHP经典面试题:如何保证缓存与数据库的双写一致性?
只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题? 面试题剖析 一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说 ...
- 面试前必知Redis面试题—缓存雪崩+穿透+缓存与数据库双写一致问题
今天来分享一下Redis几道常见的面试题: 如何解决缓存雪崩? 如何解决缓存穿透? 如何保证缓存与数据库双写时一致的问题? 一.缓存雪崩 1.1什么是缓存雪崩? 回顾一下我们为什么要用缓存(Redis ...
- Redis面试题记录--缓存双写情况下导致数据不一致问题
转载自:https://blog.csdn.net/lzhcoder/article/details/79469123 https://blog.csdn.net/u013374645/article ...
- 备战“金九银十”10道String高频面试题解析
前言 String 是我们实际开发中使用频率非常高的类,Java 可以通过 String 类来创建和操作字符串,使用频率越高的类,我们就越容易忽视它,因为见的多所以熟悉,因为熟悉所以认为它很简单,其实 ...
- Spring经典高频面试题,原来是长这个样子
Spring经典高频面试题,原来是长这个样子 2019年08月23日 15:01:32 博文视点 阅读数 719 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文 ...
- 熟悉这几道 Redis 高频面试题,面试不用愁
1.说说 Redis 都有哪些应用场景? 缓存:这应该是 Redis 最主要的功能了,也是大型网站必备机制,合理地使用缓存不仅可以加 快数据的访问速度,而且能够有效地降低后端数据源的压力. 共享Ses ...
- 从阿里、腾讯的面试真题中总结了这11个Redis高频面试题
前言 现在大家的工作生活基本已经是回归正轨了,最近也是迎来了跳槽面试季,有些人已经拿到了一两个offer了. 这段时间收集了阿里.腾讯.百度.京东.美团.字节跳动等公司的Java面试题,总结了Redi ...
- 一分钟搞定Java高频面试题
一分钟搞定Java高频面试题 一.变量赋值和计算 题目: public static void main(String[] args) { int i = 1; i = i++; int j = i+ ...
- 100道Java高频面试题(阿里面试官整理)
我分享文章的时候,有个读者回复说他去年就关注了我的微信公众号,打算看完我的所有文章,然后去面试,结果我后来很长时间不更新了...所以为了弥补一直等我的娃儿们,给大家的金三银四准备了100道花时间准备的 ...
随机推荐
- Oracle报错注入总结
0x00 前言 在oracle注入时候出现了数据库报错信息,可以优先选择报错注入,使用报错的方式将查询数据的结果带出到错误页面中. 使用报错注入需要使用类似 1=[报错语句],1>[报错语句], ...
- 套壳浏览器与Chrome浏览器之间的差别
之前QQ浏览器一直是我前端调试工具的主力,因为它是一个套壳浏览器,所以它的兼容模式(谷歌Chrome内核)和极速模式(IE浏览器内核)简直是调试兼容性的神器,可以直接切换,不用再反复打开Chrome和 ...
- python编程系列---Pycharm快捷键(更新中....)
以下是我常用到的Pycharm快捷键(还有很多,只是我暂时用的最多的就这些): 在开发过程中,经常使用一些快捷键会大大提高开发效率,不要因为看这多而不用,常用的就那些,用得多就都记住了,脱离鼠标,逼格 ...
- 详解JavaScript调用栈、尾递归和手动优化
调用栈(Call Stack) 调用栈(Call Stack)是一个基本的计算机概念,这里引入一个概念:栈帧. 栈帧是指为一个函数调用单独分配的那部分栈空间. 当运行的程序从当前函数调用另外一个函数时 ...
- python中基本的数据类型
基本数据类型 数据:描述衡量数据的状态 类型:不同的事物需要不同的类型存储 整型 int 定义:年龄,手机号码等是整数的数字 字符串b转化为整型b = '12'print(type(b))b = i ...
- fenby C语言
P1框架 1#include <stdio.h> 2 3int main(){ 4 printf(“C语言我来了”); 5 return 0; 6} P2main()门 P3计 ...
- springboot---发送邮件
1.pom.xml配置 <dependencies> <dependency> <groupId>org.springframework.boot</grou ...
- SpringBoot + Redis 执行lua脚本
1.背景 有时候,我们需要一次性操作多个 Redis 命令,但是 这样的多个操作不具备原子性,而且 Redis 的事务也不够强大,不支持事务的回滚,还无法实现命令之间的逻辑关系计算.所以,一般在开发中 ...
- 正则表达式和python中的re模块
---恢复内容开始--- 常用的正则匹配规则 元字符 量词 字符组 字符集 转义符 贪婪匹配 re模块使用正则表达式 实例引入(是否使用re模块和正则表达式的区别) # 不使用正则表达式 phone_ ...
- Django学习day8——admin后台管理和语言适应
Django最大的优点之一,就是体贴的为你提供了一个基于项目model创建的一个后台管理站点admin.这个界面只给站点管理员使用,并不对大众开放. 1. 创建管理员用户 (django) E:\Dj ...