python爬虫—— 抓取今日头条的街拍的妹子图
AJAX 是一种用于创建快速动态网页的技术。 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
近期在学习获取js动态加载网页的爬虫,决定通过实例加深理解。
1、首先是url的研究(谷歌浏览器的审查功能)
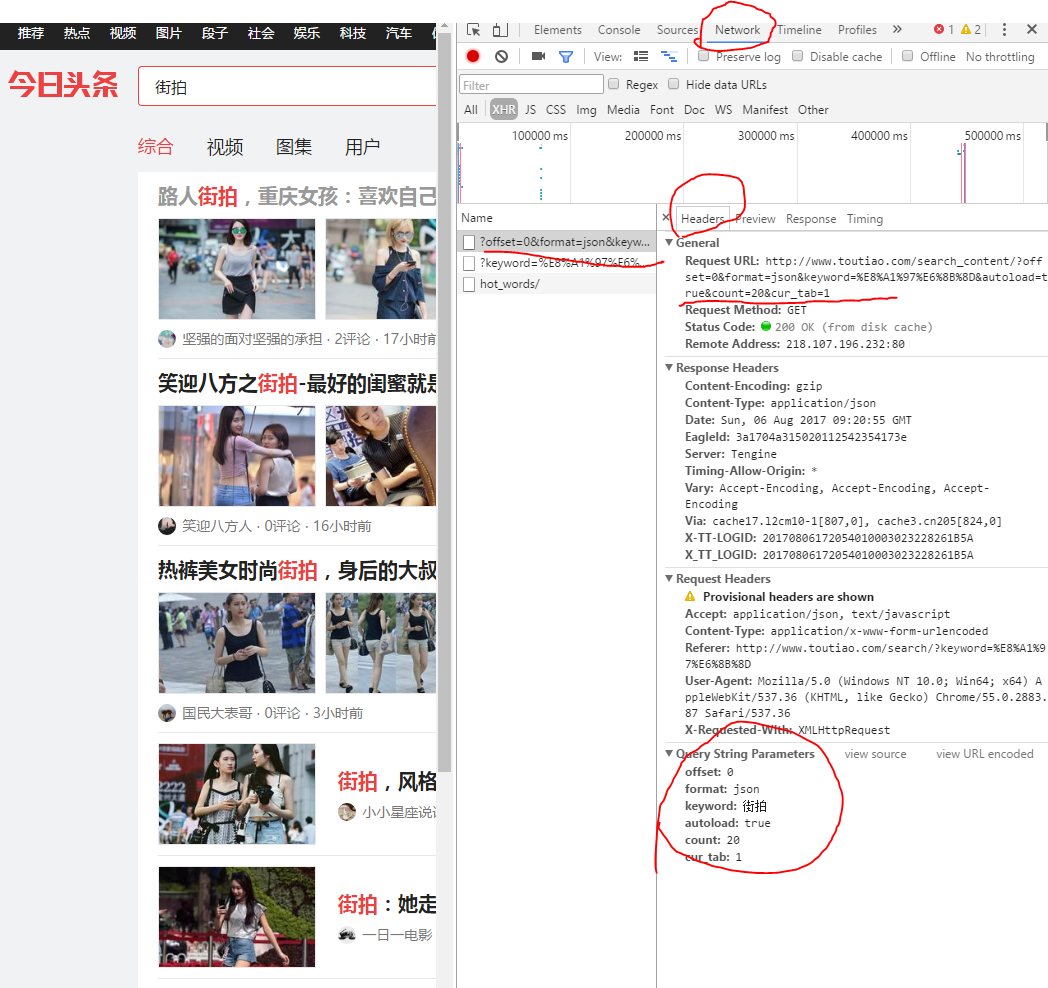
http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1
对应用get方法到url上获取信息。网页对应offset=0 、keyword=%E8%A1%97%E6%8B%8D 是会变的。如果要批量爬取,就得设置循环。
当网页下拉,offset会20、40、60的变化,其实就是每次加载20个内容。
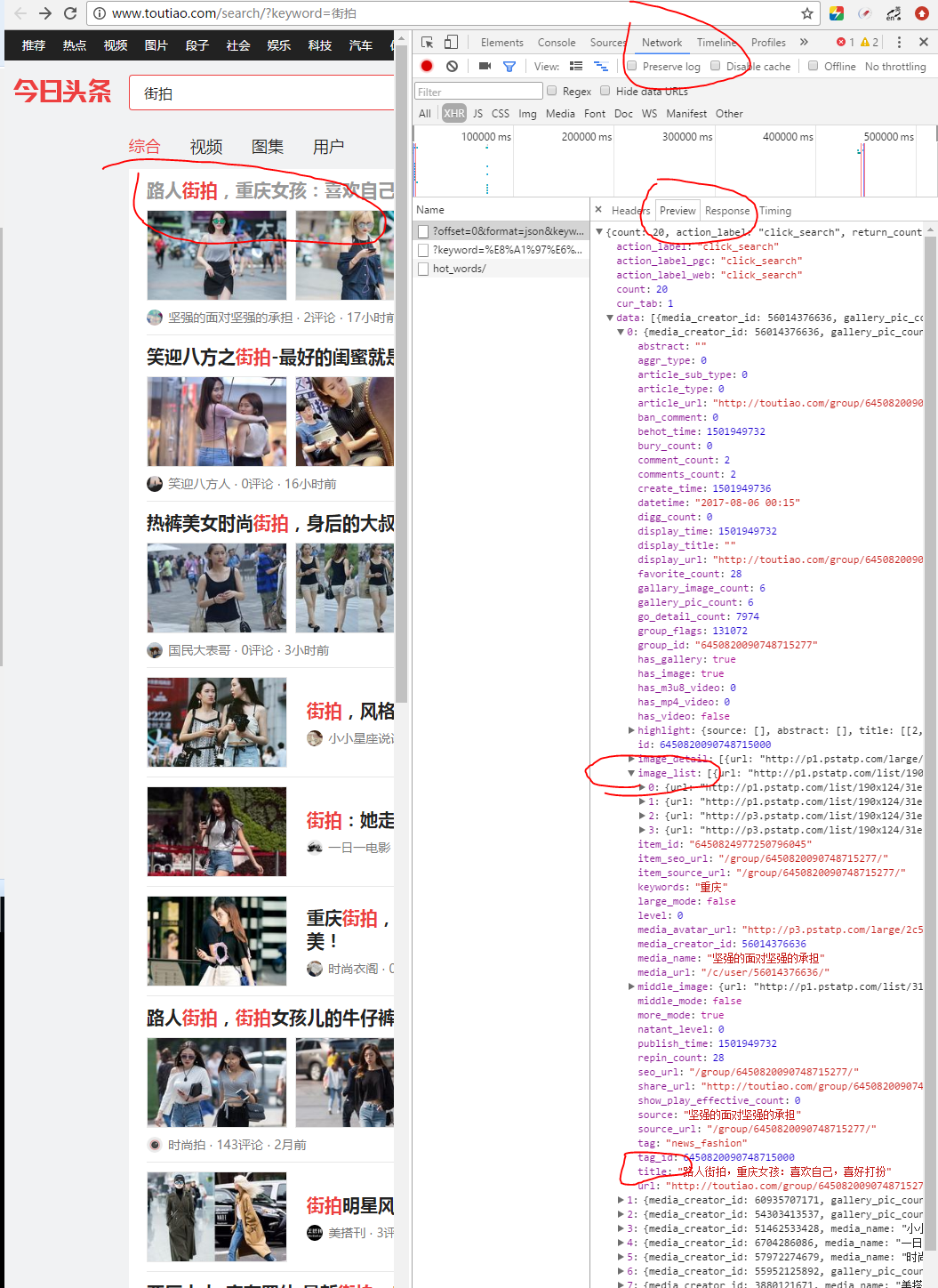
2、
通过requests获得response,进行json解析。
还是一样的网页,切换到Preview,可以看到json的数据内容。title在['date'][0]['title']下,其他类似。
import json
import requests,os
def download_pic(file,name,html):
r = requests.get(html)
filename=os.path.join(file,name+'.jpg')
with open(filename,'wb') as f:
f.write(r.content) url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1' res = requests.get(url)
json_data = json.loads(res.text)
data = json_data['data']
for i in data:
print i['title']
file_path = os.getcwd()+'\image'
print file_path
for p in i['image_detail']:
print p['url']
name = p['url'].split('/')[-1]
download_pic(file_path,name,p['url'])
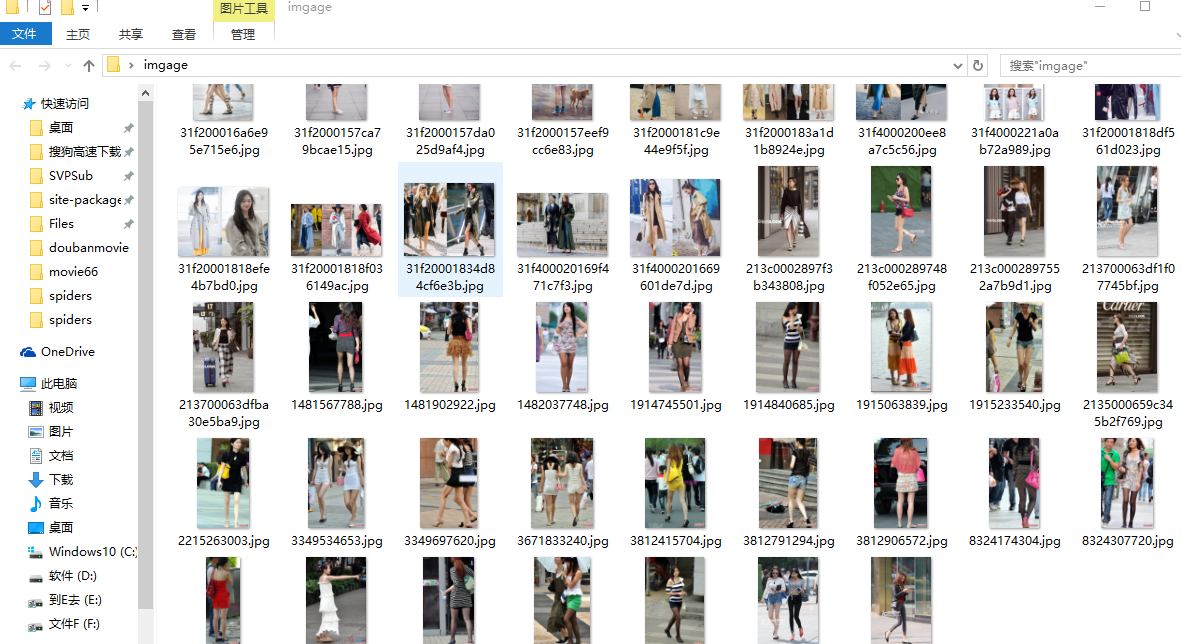
在当前目录新建image文件夹,然后爬虫下载图片。
图片名截取url链接的后面部分31e30003d4be75c719ae.jpg
例如http://p3.pstatp.com/large/31e30003d4be75c719ae
结果如下:(仅供学习交流)
循环什么的没写只爬取前20个链接的图片。
--------------------------------------------------------------------------------------------------------------
http://jandan.net/ooxx——煎蛋网
同样是妹子图,有些网页不涉及json动态加载的就比较简单了,用beautifulsoup即可
贴上代码匿了
import requests,os,time
from bs4 import BeautifulSoup
def download_pic(file,name,html):
r = requests.get(html)
filename=os.path.join(file,name+'.jpg')
with open(filename,'wb') as f:
f.write(r.content) def get_url(url):
res = requests.get(url)
soup = BeautifulSoup(res.text,'lxml')
data = soup.select(' div.text > p > img')
print data
for i in data:
s = i.attrs['src'][2:]
print s
file_path = os.getcwd()+'\imgage1'
print file_path
name = i.attrs['src'].split('/')[-1]
download_pic(file_path,name,'http://'+s) for i in reversed(range(236)):
url = 'http://jandan.net/ooxx/page-'+str(i)+'#comments'
if requests.get(url).status_code == 200:
get_url(url)
time.sleep(5)
python爬虫—— 抓取今日头条的街拍的妹子图的更多相关文章
- 分析 ajax 请求并抓取 “今日头条的街拍图”
今日头条抓取页面: 分析街拍页面的 ajax 请求: 通过在 XHR 中查看内容,获取 url 链接,params 参数信息,将两者进行拼接后取得完整 url 地址.data 中的 article_u ...
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- python多线程爬取-今日头条的街拍数据(附源码加思路注释)
这里用的是json+re+requests+beautifulsoup+多线程 1 import json import re from multiprocessing.pool import Poo ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
随机推荐
- 日志RedisTemplate 存储
import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis. ...
- SCRUM MASTER检查单
转自:http://www.scrumcn.com/agile/scrum-knowledge-library/scrum.html#tab-id-18 一位合格的ScrumMaster通常能够同时处 ...
- 【管理学】PDCA
- codeforces 864 E. Fire(背包+思维)
题目链接:http://codeforces.com/contest/864/problem/E 题解:这题一看就很像背包但是这有3维限制也就是说背包取得先后也会对结果有影响.所以可以考虑sort来降 ...
- hdu 4734 F(x)(数位dp+优化)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4734 题意:我们定义十进制数x的权值为f(x) = a(n)*2^(n-1)+a(n-1)*2(n-2 ...
- NOIP 2016 蚯蚓 题解
一道有趣的题目,首先想到合并果子,然而发现会超时,我们可以发现首先拿出来的切掉后比后拿出来切掉后还是还长,即满足单调递增,故建立三个队列即可. 代码 #include<bits/stdc++.h ...
- 【Offer】[51] 【数组中的逆序对】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对.输入一个数组,求出这个数组中的逆序对的总数.例如,在数组 ...
- 大数据Hadoop基础入门到精通
1.hadoop前世今生: 1) 搜索引擎:网络爬虫+索引服务器(生成索引+检索) 2) Doung Cutting 3) Nutch a.分布式存储 b.分布式计算 4)GFS论文 doung c ...
- Python(Head First)学习笔记:一
目录: 1 认识Python:Python的特点.安装.开发环境搭建 2 共享代码:连接共享社区.语法.函数.技巧 3 文件与异常:调试.处理错误.迭代.改进.完善 4 持久存储:文件存储.读写 5 ...
- idea报错 Error creating bean with name 'requestMappingHandlerMapping' defined in class path resource
核对一下控制器是不是写了相同的路径...org.springframework.beans.factory.BeanCreationException: Error creating bean wit ...