requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来。
首先进行url分析,可以看到:
歌手网页:

薛之谦网页:

可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 30 14:18:33 2017 @author: 24630
""" import requests
from lxml import etree
import urllib.parse as urlparse # 获得热门的前几个有封面的歌手
def get_info_artist(url):
html = requests.get(url).text
html=etree.HTML(html)
hotlist = html.xpath('//div[@class="hot-head clearfix"]/dl/dd/a[1]/@href')
return hotlist def get_info_single(url):
html = requests.get(url).text
html=etree.HTML(html)
songlist = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/text()')
albumlist = html.xpath('//div[@class="song-item"]//span[@class="album-title"]/a[1]/text()')
downloadUrl = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/@href') #无法找到下一页的跳转连接
#next_page = //div[@class="page-inner"]/a[last()]/text()
print(len(songlist)) url = 'http://music.baidu.com/artist'
hotlist = get_info_artist(url)
#urljoin主要是拼接URL,
#它以base作为其基地址,
#然后与url中的相对地址相结合组成一个绝对URL地址。
#函数urljoin在通过为URL基地址附加新的文件名的方式来处理同一位置处的若干文件的时候格外有用。
#需要注意的是:
#如果基地址并非以字符/结尾的话,那么URL基地址最右边部分就会被这个相对路径所替换。
#如果希望在该路径中保留末端目录,应确保URL基地址以字符/结尾。 for u in hotlist:
#获得单个歌手的链接
url_singer = urlparse.urljoin(url,u)
get_info_single(url_singer)
可以看到,我读完一页后,想要继续进行下一页的数据的获取就没那么容易了。

有时候显示:

至于怎么获得下一页的信息:

通过上面可以分析,上面三处有数据的地方分别是点击下一页的时候产生的,可以在上面找一下。
这个时候,可以分析到:
实际上,跳转路径的动态请求隐藏在:

这样一个路径下。
因此,实际上可以构建该路径进行获取歌曲信息。

可以看到,该路径下动态请求的页面是一个json格式数据,可以通过json解析,获取其中的html源码。
代码修改为:
import requests
from lxml import etree
import urllib.parse as urlparse
import json,re,os
import sqlite3 def writeDB(song_dict):
global num
c = conn.cursor()
sql = '''insert into baiduMusic (id, songName,singer,albumname,download) values (?,?,?,?,?)'''
para = (num,song_dict['歌曲'],song_dict['歌手'],song_dict['专辑'],song_dict['下载路径'])
c.execute(sql,para)
conn.commit()
num += 1 # 获得热门的前几个有封面的歌手
def get_info_artist(url):
html = requests.get(url).text
html=etree.HTML(html)
hotlist = html.xpath('//div[@class="hot-head clearfix"]/dl/dd/a[1]/@href')
return hotlist def get_info_single(url):
re_com = re.compile('artist/(\d+)')
ting_uid = re_com.findall(url)[0]
get_info_single_page(0,ting_uid) def get_info_single_page(i,ting_uid):
page = 'http://music.baidu.com/data/user/getsongs?start={0}&ting_uid={1}'.format(i,ting_uid) html = requests.get(page).text
html = json.loads(html)["data"]["html"]
html=etree.HTML(html)
songlist = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/text()')
albumlist = html.xpath('//div[@class="song-item"]//span[@class="album-title"]/a[1]/text()')
downloadUrl = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/@href')
try:
singer = html.xpath('//div[@class="song-item"]//span[@class="song-title "]/a[1]/@title')[0]
re_com = re.compile('(\S+?)《') #这种解析歌手的方法不好,为了省事先这么弄的
singer = re_com.findall(singer)[0]
except:
singer = ' '
print(singer)
for songName,album,download in zip(songlist,albumlist,downloadUrl):
song_dict = {}
song_dict['歌曲'] = songName
song_dict['歌手'] = singer
song_dict['专辑'] = album
song_dict['下载路径'] = download
writeDB(song_dict)
#歌曲都获取全了,即获得某一页歌曲数少于25
if (len(songlist) == 25):
get_info_single_page(i+25,ting_uid) num = 1
if not os.path.isfile('test.db'):
conn = sqlite3.connect('test.db') c = conn.cursor()
c.execute('''create table baiduMusic (id integer primary key,songName varchar(10),singer varchar(10),
albumname varchar(10),
download varchar(10));''')
conn.commit()
else:
conn = sqlite3.connect('test.db')
url = 'http://music.baidu.com/artist'
hotlist = get_info_artist(url)
#urljoin主要是拼接URL,
#它以base作为其基地址,
#然后与url中的相对地址相结合组成一个绝对URL地址。
#函数urljoin在通过为URL基地址附加新的文件名的方式来处理同一位置处的若干文件的时候格外有用。
#需要注意的是:
#如果基地址并非以字符/结尾的话,那么URL基地址最右边部分就会被这个相对路径所替换。
#如果希望在该路径中保留末端目录,应确保URL基地址以字符/结尾。 for u in hotlist:
#获得单个歌手的链接
url_singer = urlparse.urljoin(url,u)
get_info_single(url_singer) conn.close()
最终获得效果:
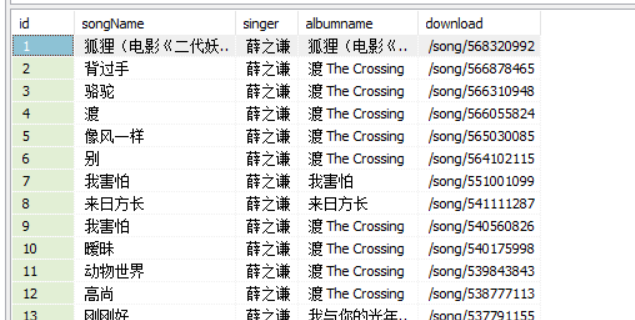
当然,上面的download链接是歌曲的跳转链接,如果需要下载的话,可以继续分析:
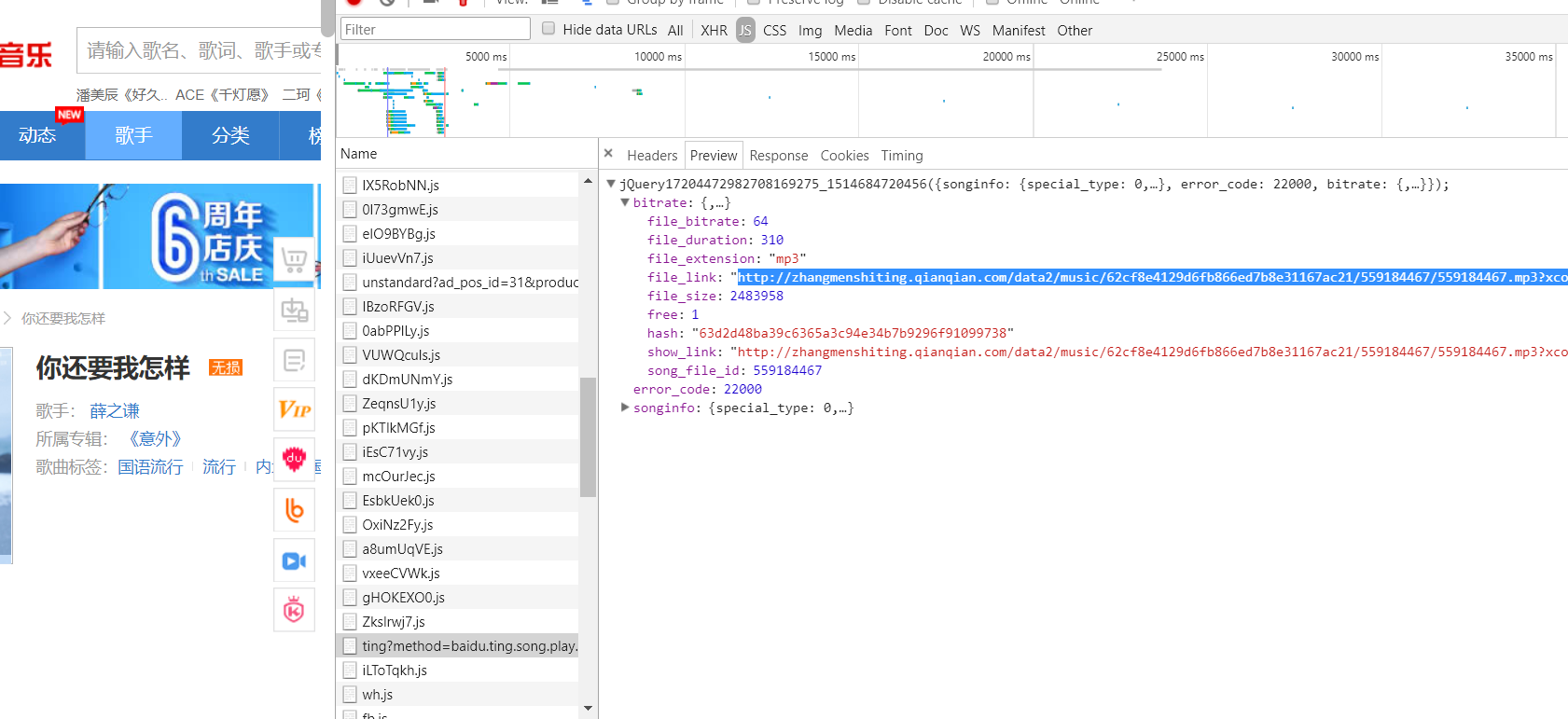
如上,可以继续分析如何构建歌曲文件的url,然后完成下载。
requests爬取百度音乐的更多相关文章
- python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html 在下面这种类型文件中的请求头的url打开后会得到一个页面 你会得到如下图 ...
- Python 爬虫实例(14) 爬取 百度音乐
#-*-coding:utf-8-*- from common.contest import * import urllib def spider(): song_types = ['新歌','热歌' ...
- requests爬取百度贴吧:python 美女 3
import requests import sys class Tieba(object): def __init__(self, tieba_name, pn): self.tieba_name ...
- requests+xpath+map爬取百度贴吧
# requests+xpath+map爬取百度贴吧 # 目标内容:跟帖用户名,跟帖内容,跟帖时间 # 分解: # requests获取网页 # xpath提取内容 # map实现多线程爬虫 impo ...
- 利用python的爬虫技术爬取百度贴吧的帖子
在爬取糗事百科的段子后,我又在知乎上找了一个爬取百度贴吧帖子的实例,为了巩固提升已掌握的爬虫知识,于是我打算自己也做一个. 实现目标:1,爬取楼主所发的帖子 2,显示所爬去的楼层以及帖子题目 3,将爬 ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- python3 爬取qq音乐作者所有单曲 并且下载歌曲
1 import requests import re import json import os # 便于存放作者的姓名 zuozhe = [] headers = {'User-Agent': ' ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
随机推荐
- python 操作 Redis
目录 Redis 模块基本介绍 参考 redis redis-py 的 API 连接 redis 普通连接 连接池 redis 字符串操作 单次设置key-value 批量设置key-value re ...
- 自动检测SOCKET链接断开
如何判断SOCKET已经断开 最近在做一个服务器端程序,C/S结构.功能方面比较简单就是client端与server端建立连接,然后发送消息给server.我在server端会使用专门的线程处理一条s ...
- 64_t7
texlive-ulqda-bin-svn13663.0-33.20160520.fc26.2..> 24-May-2017 15:57 33102 texlive-ulqda-doc-svn2 ...
- iBt(001-004)原文与试译
Unit 001 Basic building materials include: timber, mud, stone, marble, brick, tile, steel, and cemen ...
- HDU 6061 RXD and functions
题目链接:HDU-6061 题意:给定f(x),求f(x-A)各项系数. 思路:推导公式有如下结论: 然后用NTT解决即可. 代码: #include <set> #include < ...
- yum怎么用?
一.yum 简介 yum,是Yellow dog Updater, Modified 的简称,是杜克大学为了提高RPM 软件包安装性而开发的一种软件包管理器.起初是由yellow dog 这一发行版的 ...
- Vue 进阶教程之:详解 v-model
分享 Vue 官网教程上关于 v-model 的讲解不是十分的详细,写这篇文章的目的就是详细的剖析一下, 并介绍 Vue 2.2 v-model改进的地方,然后穿插的再说点 Vue 的小知识. 在 V ...
- MongoDB安全:创建第1个、第2个、第3个用户
Windows 10家庭中文版,MongoDB3.6.3, 前言 使用mongod命令基于某个空白文件夹(存放数据)启动MongoDB服务器时,要是没有使用--auth选项,启动后,任何客户端是可以无 ...
- 数据库-mysql数据类型
MySQL 数据类型 MySQL中定义数据字段的类型对你数据库的优化是非常重要的. MySQL支持多种类型,大致可以分为三类:数值.日期/时间和字符串(字符)类型. 数值类型 MySQL支持所有标准S ...
- 安装pywin32模块
1.先下载pywin32对于的版本 下载地址:python for windows extensions 2.选择自己对应的版本,我的是python3.5版本 注意注意注意:此处一定要看清楚自己的py ...