拟牛顿法/Quasi-Newton,DFP算法/Davidon-Fletcher-Powell,及BFGS算法/Broyden-Fletcher-Goldfarb-Shanno
拟牛顿法/Quasi-Newton,DFP算法/Davidon-Fletcher-Powell,及BFGS算法/Broyden-Fletcher-Goldfarb-Shanno
转载须注明出处:http://www.codelast.com/
在最优化领域,有几个你绝对不能忽略的关键词:拟牛顿、DFP、BFGS。名字很怪,但是非常著名。下面会依次地说明它们分别“是什么”,“有什么用” 以及 “怎么来的”。
但是在进入正文之前,还是要先提到一个概念上的区别,否则将影响大家的理解:其实DFP算法、BFGS算法都属于拟牛顿法,即,DFP、BFGS都分别是一种拟牛顿法。
先说一点轻松的——我至少要让一小部分人对这篇文章“有点兴趣”(要不然岂不白写了)。有人对这些数学的概念很烦,很没心情看下去,他们可能会说:这些枯燥的东西到底有什么用?举一个简单的例子吧,假设你每周要去市区里很多地方玩,周一可能要去打篮球、朋友聚会、跳舞,周二可能要去唱歌、逛街,周三可能要去看电影、踢足球(如果不踢的话就会去喝咖啡),……你已经形成了一定的生活规律,但是这些活动不是一定会发生的,每样活动都可能受到一定因素的影响,例如如果下雨的话,你有80%的可能就不去逛街了;例如你要是看了一部悲剧题材的电影之后,你有70%的可能就不去踢足球了。从某一天开始,把你每天的活动情况全部记录下来,包括一些最可能的影响因素(当然,这个影响因素可能不是你主观意识到的,例如下雨,是可以通过已经成为事实的天气情况记录下来的),这样连续记录很长时间以后(例如半年),我们就有了你活动的历史数据,根据这些历史数据,我们可以建立一个数学模型,用BFGS算法来求解(“求解”什么东西此处不谈),这样,我们就有了预测未来的能力——假设今天是周三,你中午看了一部电影:《世贸中心》(哥看过,让人无比心痛),然后你在某网站上“签到”,表示你看过了这部电影,那么,本该在周三下午踢球的你还会继续去踢球吗?根据那些可能影响你活动的种种因素,我们可以计算出你最有可能做(或者不做)的事情——假设我们计算结果是:你不会去踢球了,你会去喝咖啡。好,看完电影你打开手机,上某网站“签到”的之后,它就会自动向你推送在你附近(通过GPS或者基站可以定位你的手机)的信息,让你感觉:咦,好神奇,它怎么知道我想喝咖啡呢?那是因为你已经告诉了它你太多的历史信息,它太“了解”你了,以至于都可以预测出你将要做什么了。知道为什么有那么多网站提供“签到”功能了吧,哼哼,可以完全地掌握用户的兴趣爱好等信息,大有商业价值。
怎么样,这算不算与你的生活息息相关呢?在信息时代,这些都是完全可以做到的,并且人们正在一点一点地将它们实现和完善。在实际的应用中,问题可能很复杂,而前面所说的用BFGS算法来求解可能并不适用,但是这里只是举了一个例子,说明有类似的问题,是有可能用它来解决的。这也是研究“最优化”理论非常有意义的一个明证。
好了,现在可以开始说理论的东西了。先从拟牛顿法(Quasi-Newton)说起。这个怪怪的名词其实很形象:这是一种”模拟“的牛顿法。那么,它模拟了牛顿法的哪一部分呢?答:模拟的就是牛顿法中的搜索方向(可以叫作”牛顿方向“)的生成方式。
什么?牛顿法是什么?本文是基于你已经知道牛顿法的原理的假设,如果你不清楚,那么可以看我这篇文章,里面非常简单而又清晰地描述了牛顿法的原理。
了解了牛顿法的原理,我们就知道了:在每一次要得到新的搜索方向的时候,都需要计算Hesse矩阵(二阶导数矩阵)。在自变量维数非常大的时候,这个计算工作是非常耗时的,因此,拟牛顿法的诞生就有意义了:它采用了一定的方法来构造与Hesse矩阵相似的正定矩阵,而这个构造方法计算量比牛顿法小。这就是对它”有什么用“的回答了。
(1)DFP算法
下面,就从DFP算法来看看“拟牛顿”是如何实现的(DFP算法是以Davidon、Fletcher、Powell三位牛人的名字的首字母命名的)。
前面说了,Hesse矩阵在拟牛顿法中是不计算的,拟牛顿法是构造与Hesse矩阵相似的正定矩阵,这个构造方法,使用了目标函数的梯度(一阶导数)信息和两个点的“位移”(Xk-Xk-1)来实现。有人会说,是不是用Hesse矩阵的近似矩阵来代替Hesse矩阵,会导致求解效果变差呢?事实上,效果反而通常会变好。有人又会问为什么?那么就简要地说一下——
由牛顿法的原理可知如下几个等式:
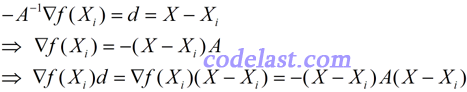
若最后一个等式子的最左边 < 0,即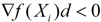 ,就是直观概念上的“沿方向d上,目标函数值下降”的表达。而在逐步寻找最优解的过程中,我们是要求目标函数值下降的,因此,应该有-(X-Xi)A(X-Xi) < 0,也即 (X-Xi)A(X-Xi) > 0。这表明矩阵A是正定的。而在远离极小值点处,Hesse矩阵一般不能保证正定,使得目标函数值不降反升。而拟牛顿法可以使目标函数值沿下降方向走下去,并且到了最后,在极小值点附近,可使构造出来的矩阵与Hesse矩阵“很像”了,这样,拟牛顿法也会具有牛顿法的二阶收敛性。
,就是直观概念上的“沿方向d上,目标函数值下降”的表达。而在逐步寻找最优解的过程中,我们是要求目标函数值下降的,因此,应该有-(X-Xi)A(X-Xi) < 0,也即 (X-Xi)A(X-Xi) > 0。这表明矩阵A是正定的。而在远离极小值点处,Hesse矩阵一般不能保证正定,使得目标函数值不降反升。而拟牛顿法可以使目标函数值沿下降方向走下去,并且到了最后,在极小值点附近,可使构造出来的矩阵与Hesse矩阵“很像”了,这样,拟牛顿法也会具有牛顿法的二阶收敛性。
由于涉及到Hesse矩阵(二阶导数矩阵),我们当然要从目标函数 f(X) 的泰勒展开式说开去。与最优化理论中的很多问题一样,在这里,我们依然要假设目标函数可以用二次函数进行近似(实际上很多函数都可以用二次函数很好地近似):
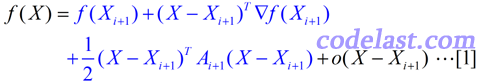
忽略高阶无穷小部分,只看前面的3项,其中A为目标函数的Hesse矩阵(二阶导数矩阵)。此式两边对X求导得:
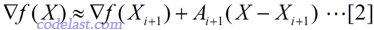
于是,当 X=Xi 时,将[2]式两边均左乘(Ai+1)-1,有:
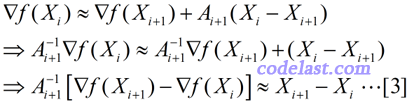
上式左右两边近似相等,但如果我们把它换成等号,并且用另一个矩阵H来代替上式中的A-1,则得到:
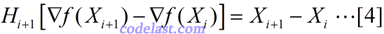
这个方程,就是拟牛顿方程,其中的矩阵H,就是Hesse矩阵的逆矩阵的一个近似矩阵。但是,从初始的H0开始,如何得到每一步迭代过程中需要的H1,H2,……呢?在迭代过程中生成的矩阵序列H0,H1,H2,……中,每一个矩阵Hi+1,都是由前一个矩阵Hi修正得到的,这个修正方法有很多种,这里只说DFP算法的修正方法。设:
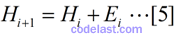
然后又有问题:矩阵E怎么求?再设:
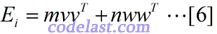
其中,m和n均为实数,v和w均为N维向量。将[6]代入[5]式,再将[5]式代入[4]式,可得:

[8]式与[7]式完全相同,只不过用简化的记号重写了一下。如果求出了m,n,v,w,就可以知道[6]式怎么求,从而进一步知道[5]式怎么求,从而我们的问题就彻底解决了。符合[7]这个方程的v,w可能有很多,但是我们有没有可能找到v,w的一个“特例”,使之符合这个等式呢?仔细观察一下,是可以找到的:[7]式的右边两个向量相减的结果,是一个n×1的向量,因此,等式左边的计算结果当然也是一个n×1的向量(每一项都是一个n×1的向量),所以我们把[7]式写成了[8]式的样子,可以看到,其中的第二、第三项中的括号里的向量的点积均为实数,这里,可以使第一个括号中的mvTqi值为1,使第二个括号中的nwTqi值为-1,这样的话,v只要取si,w只要取Hiqi,就可以使[8]式成立了。的确,这种带有一点猜测性质的做法,确实可以让我们找到一组适合的m,n,v,w值。
所以,我们得到的m,n,v,w值如下:
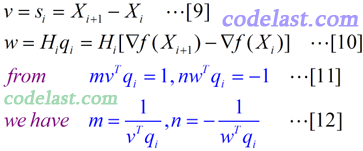
现在我们几乎大功告成了:将[8]~[11]代入[6]式,然后再将[6]代入[5]式,就得到了Hesse矩阵的逆矩阵的近似阵H的计算方法:
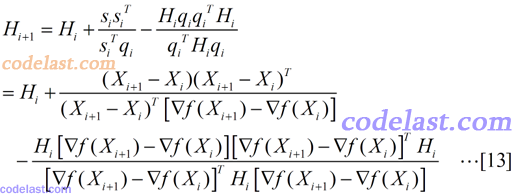
在上面的推导过程中,有人可能觉得有点无厘头:为什么[6]式要那样假设,是怎么想到的?我能给出的答案是:这一点我也没想明白。如果你知道,请告诉我,非常感谢。某些书上经常写类似于“很显然,XXX”之类的话,从一个定理直接得出了一个让人摸不着头脑的结论,而作为我这样比较笨的人来说,我觉得写书的很多专家们认为“很显然”的东西一点也不“显然”,甚至于有时候,我觉得那就像凤姐突然变成了范冰冰一样——一下子变出来了一个漂亮的结论,难以相信。所以这也是为什么我花费了很多时间,来把一些“很显然”的东西记下来,写明白的原因了。对于大多数牛人,他们需要的当然不是这种思维跨度这么小的文章,而是那种从地球可以一下子飞到火星的文章。所以,我写的东西不适合于水平高的人看,我只期望能帮助一小部分人就知足了。
说到这里,那么到底什么是DFP算法呢?上面的矩阵H的计算方法就是其核心,下面再用简单的几句话描述一下DFP算法的流程:
已知初始正定矩阵H0,从一个初始点开始(迭代),用式子 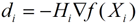 来计算出下一个搜索方向,并在该方向上求出可使目标函数极小化的步长α,然后用这个步长,将当前点挪到下一个点上,并检测是否达到了程序中止的条件,如果没有达到,则用上面所说的[13]式的方法计算出下一个修正矩阵H,并计算下一个搜索方向……周而复始,直到达到程序中止条件。
来计算出下一个搜索方向,并在该方向上求出可使目标函数极小化的步长α,然后用这个步长,将当前点挪到下一个点上,并检测是否达到了程序中止的条件,如果没有达到,则用上面所说的[13]式的方法计算出下一个修正矩阵H,并计算下一个搜索方向……周而复始,直到达到程序中止条件。
有人会说,上面那些乱七八糟的都是搞什么啊,猜来猜去的就折腾出了一个公式,然后就确定这公式能用了?就不怕它在迭代的时候根本无法寻找到目标函数的极小值?正因为有这些疑问,所以在这里,还要提及一个非常重要的问题:我们通过带有猜测性质的做法,得到了矩阵H的计算公式,但是,这个修正过的矩阵,能否保持正定呢?前面已经说了,矩阵H正定是使目标函数值下降的条件,所以,它保持正定性很重要。可以证明,矩阵H保持正定的充分必要条件是:
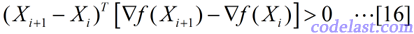
并且,在迭代过程中,这个条件也是容易满足的。此结论的证明并不复杂,但是为了不影响本文的主旨,这里就没有必要写出来了。总之,我觉得作为一个最优化的学习者来说,首先要关注的是不是这些细节问题,而是先假设这些算法都适用,然后等积累到一定程度了,再去想“为什么能适用”的问题。
(2)BFGS算法
在上面的DFP算法的推导中,我们得到了矩阵H的计算公式,而BFGS算法和它有点像,但是比它形式上复杂一点。尽管它更复杂,但是在BFGS算法被Broyden,Fletcher,Goldfarb,Shanno四位牛人发明出来到现在的40多年时间里,它仍然被认为是最好的拟牛顿算法。历史总是这样,越往后推移,人们要超越某种技术所需的时间通常就越长。但是我们很幸运地可以站在巨人的肩膀上,从而可以在使用前人已经发明的东西的基础上感叹一声:这玩意太牛了。
好吧,又扯远了…… 回到中心主题,看看在BFGS算法中,与上面的[13]式一样的矩阵H是如何计算的:
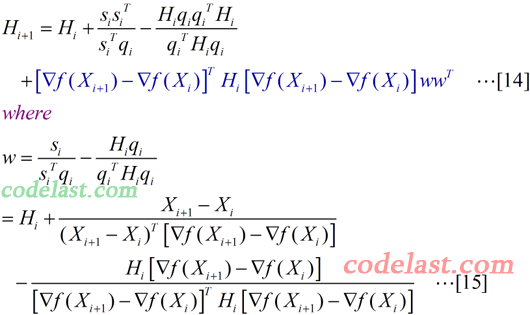
在[14]式中,最后一项(深蓝色的部分)就是BFGS比DFP多出来的东西。其中,w为一个n×1的向量。我们看到,由于向量w的表达式太长,所以没有把它直接写在[14]式中,而是单独列在了[15]式里。
可能[14]式一看就让人头晕,所以先来弱弱地解释一下这个式子的计算结果(如果你觉得好雷人,那么请直接无视):wwT是一个n×1的向量与一个1×n的向量相乘,结果为一个n×n的矩阵,而[14]式中最后一项里,除了wwT之外的那一部分是(1×n)向量、n×n矩阵、n×1向量相乘,结果为一实数,因此[14]式最后一项结果为一个n×n矩阵,这与[14]式等号左边的矩阵H为n×n矩阵一致。这一点没有问题了。
在目标函数为二次型(“在数学中,二次型是一些变量上的二次齐次多项式”)时,无论是DFP还是BFGS——也就是说,无论[14]式中有没有最后一项——它们均可以使矩阵H在n步之内收敛于A-1。
延伸阅读:BFGS有一个变种(我不知道这样称呼是否正确),叫作“Limited-memory BFGS”,简称“L-BFGS”或“LM-BFGS”(这里的“LM”与Levenberg-Marquard算法没有关系),从它的名字上看,你肯定能猜到,使用L-BFGS算法来编写程序时,它会比BFGS算法占用的内存小。从前面的文章中,我们知道,BFGS在计算过程中要存储一个n×n的矩阵,当维数n很大的时候,这个内存占用量会很大——例如,在10万维的情况下,假设矩阵H中的元素以double来存储,那么,内存占用即为100000×100000×8÷1024÷1024÷1024≈74.5(GB),这太惊人了,一般的服务器几乎无法承受。所以,使用L-BFGS来降低内存使用量在某些情况下是非常有意义的。
关于L-BFGS的英文解释,请点击这个Wiki链接。由于我还没有深入学习L-BFGS,所以没办法在这里详细叙述了。

拟牛顿法/Quasi-Newton,DFP算法/Davidon-Fletcher-Powell,及BFGS算法/Broyden-Fletcher-Goldfarb-Shanno的更多相关文章
- 最优化算法【牛顿法、拟牛顿法、BFGS算法】
一.牛顿法 对于优化函数\(f(x)\),在\(x_0\)处泰勒展开, \[f(x)=f(x_0)+f^{'}(x_0)(x-x_0)+o(\Delta x) \] 去其线性部分,忽略高阶无穷小,令\ ...
- 牛顿法与拟牛顿法学习笔记(四)BFGS 算法
机器学习算法中经常碰到非线性优化问题,如 Sparse Filtering 算法,其主要工作在于求解一个非线性极小化问题.在具体实现中,大多调用的是成熟的软件包做支撑,其中最常用的一个算法是 L-BF ...
- 最优化算法:BFGS算法全称和L-BFGS算法全称
在最优化算法研究中按时间先后顺序出现了许多算法包括如下几种,这里介绍下他们的全称和英文名称: 1.最速下降法(Gradient descent) 2.牛顿法(Newton method) 3. 共轭梯 ...
- 数据结构与算法JavaScript (五) 串(经典KMP算法)
KMP算法和BM算法 KMP是前缀匹配和BM后缀匹配的经典算法,看得出来前缀匹配和后缀匹配的区别就仅仅在于比较的顺序不同 前缀匹配是指:模式串和母串的比较从左到右,模式串的移动也是从 左到右 后缀匹配 ...
- 【原创】机器学习之PageRank算法应用与C#实现(1)算法介绍
考虑到知识的复杂性,连续性,将本算法及应用分为3篇文章,请关注,将在本月逐步发表. 1.机器学习之PageRank算法应用与C#实现(1)算法介绍 2.机器学习之PageRank算法应用与C#实现(2 ...
- EM算法(4):EM算法证明
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(4):EM算法证明 1. 概述 上一篇博客我们已经讲过 ...
- EM算法(3):EM算法运用
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(3):EM算法运用 1. 内容 EM算法全称为 Exp ...
- EM算法(1):K-means 算法
目录 EM算法(1):K-means 算法 EM算法(2):GMM训练算法 EM算法(3):EM算法运用 EM算法(4):EM算法证明 EM算法(1) : K-means算法 1. 简介 K-mean ...
- 最小生成树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind
最小支撑树树--Prim算法,基于优先队列的Prim算法,Kruskal算法,Boruvka算法,“等价类”UnionFind 最小支撑树树 前几节中介绍的算法都是针对无权图的,本节将介绍带权图的最小 ...
随机推荐
- C#简单窗体应用程序(二)
使用C#创建控制台应用程序的基本步骤: (1)创建项目: (2)用户界面设计: (3)属性设置: (4)编写程序代码: (5)保存.调试.运行: 例题:设计登录界面,效果如下: 第一步:创建项目: 文 ...
- MongoDB安装笔记
2017年11月17日,在Windows Service 2008R2上成功安装MongoDB. 版本:mongodb-win32-x86_64-2008plus-ssl-3.4.6-signed.m ...
- java中的Serializable接口的作用
实现java.io.Serializable 接口的类是可序列化的.没有实现此接口的类将不能使它们的任一状态被序列化或逆序列化. 序列化类的所有子类本身都是可序列化的.这个序列化接口没有任何方法和域, ...
- PBS命令和使用
PBS是公开源代码的作业管理系统,在此环境下运行,用户不需要指定程序在哪些节点上运行,程序所需的硬件资源由PBS管理和分配. PBS(Portable Batch System)是由NASA开发的灵活 ...
- 【Linux笔记】linux crontab实现自动化任务
在服务器中我们经常需要定时自动让程序自动进行数据备份.程序备份.执行某个进程等等操作,在linux服务器一般使用crontab实现,而windows下使用计划任务实现,crontab是linux系统下 ...
- 小菜菜mysql练习50题解析——数据准备
附上数据准备: 学生表 create table Student(SId varchar(10),Sname varchar(10),Sage datetime,Ssex varchar(10)); ...
- es各类SearchType的意思
元素 含义 QUERY_THEN_FETCH 查询是针对所有的块执行的,但返回的是足够的信息,而不是文档内容(Document).结果会被排序和分级,基于此,只有相关的块的文档对象会被返回.由于被取到 ...
- linux系统下 git 使用教程
一.初始化 1.首先安装git软件,安装环境是centos 7.x下的云服务器.使用命令: #yum install git 2.设置用户名和邮箱(必须): # git config --global ...
- 获取远程图片的Blob资源
原文地址:http://www.cnblogs.com/JimmyBright/p/7681092.html 思路:js获取远程资源的blob会涉及到跨域的问题,所以需要中转一下,具体是使用php的c ...
- 主机 & 虚拟机 & 开发板 三者的恩爱情仇
# 主机 & 虚拟机 & 开发板 > 三者网络连通性,使用ping命令检测 @ Bridge 模式 ## 主机 & 虚拟机 主机与虚拟机相当于一个网络里的两台主机,都有各 ...