Java泛型底层源码解析-ArrayList,LinkedList,HashSet和HashMap
声明:以下源代码使用的都是基于JDK1.8_112版本
1. ArrayList源码解析
<1. 集合中存放的依然是对象的引用而不是对象本身,且无法放置原生数据类型,我们需要使用原生数据类型的包装类才能加入到集合中去
<2. 集合中放置的都是Object类型,因此取出来的也是Object类型,那么必须要使用强制类型转换将其转换为真正需要的类型即放置进行的类型
ArrayList list = new ArrayList();
list.add(new Integer(4)); list.add("abc");
System.out.println((Integer)list.get(0));
System.out.println((String)list.get(1));
<3. ArrayList底层采用数组实现,当使用不带参数的构造方法生成ArrayList对象时,实际上会在底层生成一个长度为10的Object类型数组。
这里需要区分JDK版本的区别,jdk1.6或之前底层在扩容的时候使用的是基本乘法运算:(oldCapacity * 3)/2 + 1 ; 而在jdk1.7之后底层在扩容的时候采用位移运算,且也没有多加1操作:oldCapacity + (oldCapacity >> 1) (我猜想应该是充分考虑提升运算性能)
即:JDK1.6以及之前扩容规则为:1.5倍+1 ; JDK1.7以及之后扩容规则为:1.5倍
<4. 真正的扩容是将原数组的内容复制到新数组当中,并且后续增加的内容都会放到这个新的数组当中去。
这里贴出来jdk1.8扩容代码:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
其中elementData定义如下:
transient Object[] elementData; // non-private to simplify nested class access
transient Object[] elementData;,细心的盆友可以看出它的关键字是transient,看到这个关键字,都以为此数组是不可序列化的,其实不然,因为ArrayList实现了Serializable的writeObject()可以定制化,ArrayList实现writeObject并且强制将 transient elementData 序列化。那么为什么这样设计呢?个人认为是因为ArrayList内部实现是数组,大部分情况下会有空值,比如elementData的大小是10,但实际只有6个元素,那么剩下的4个元素没有实际的意义,如果直接将此标识为可序列化,那么最终会把空值同样序列化,因此将elementData设计为transient,然后实现Serializable的writeObject()方法将其序列化,只序列化实际存储的元素,而不是整个数组。当然还是个人认为,降低序列化的传输量来变向的提升性能(速度)
这里如果有盆友不理解transient相关概念,请查看我的另一篇博客:http://www.cnblogs.com/liang1101/p/6382765.html
<5. boolean add(E) 和 void add(int, E) 底层使用的方法不同
直接add对象到集合中默认是将该对象加入到数据最末端,这样也是最快的,即:elementData[size++] = e;-->将元素赋值给数组顺序的最后一位
而指定插入位置的add方法则需要从指定位置+1的位置开始往后使用System.arraycopy方法赋值数组操作,之后再将对应的元素赋值,具体源代码:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
5 //public static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
对应还有set(int, E)、remove(int)、remove(Object)等都是类似的行为,即数组是怎么操作的ArrayList底层就应该是怎么操作的。
2. LinkedList源码解析
LinkedList底层源码是采用双向链表的方式实现的,具体双向列表初始化定义如下:
1 private static class Node<E> {
2 E item; //结点的值
3 Node<E> next; //结点的后继指针
4 Node<E> prev; //结点的前驱指针
5 //构造函数完成Node成员的赋值
6 Node(Node<E> prev, E element, Node<E> next) {
7 this.item = element;
8 this.next = next;
9 this.prev = prev;
10 }
11 }
何为双向列表,单向链表为通过后继可以找到下一个指向的元素;双向链表为既可以通过后继找到下一个指向的元素,也可以通过前驱找到前一个元素。基于链表实现的方式使得LinkedList在插入和删除时更优于ArrayList,而随机访问则比ArrayList逊色些。那么剩下的add、remove等方法就是改变相应的指向即可,这个实现起来就很简单了,这里就不再做详细的说明了,不会的可以查看一下源代码就明白了。
3. HashSet源码解析
首先,咱们经常使用的HashSet的无参构造函数,那么来看一下对应的源码:
/**
* Constructs a new, empty set; the backing HashMap instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
从以上源代码可以看出,HashSet底层是使用HashMap来实现的,且对应HashMap默认初始长度为16,对应的负载因子为0.75。那我们再看看常用的add()、remove()、iterator()等方法源代码:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
其中PRESENT常量定义如下:
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
从以上源代码发现,当使用add()方法将对象添加到Set当中时,实际上是将该对象作为底层所维护的Map对象的key,而value则是同一个Object对象(该对象我们其实是用不上的)
那么既然HashSet底层直接使用的是HashMap进行维护,那么我们的重点就是要分析HashMap底层源代码到底是什么情况。
4. HashMap源码解析
首先,咱们经常使用的HashMap的无参构造函数,那么来看一下对应的源码:(JDK1.8代码)
/**
* Constructs an empty HashMap with the default initial capacity (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
而对应的JDK1.7和JDK1.6代码有一定的区别,如下:
/**
* Constructs an empty HashMap with the default initial capacity (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
}
由上面不同版本比较发现,在1.8之后其他不必要的参数都已经修改为全局默认值,不需要在每次申请的时候再进行开辟。我的理解可能为了提升创建对象的性能,可见java底层为了提升性能可谓是下足了功夫。
再来看下他们共同的常量设置:
/**
* The default initial capacity - MUST be a power of two.
* JDK1.8
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka-->as known as(亦称) 16
//static final int DEFAULT_INITIAL_CAPACITY = 16; //JDK1.7 OR JDK1.6源代码 static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f;
看见了没,这么细小的优化真的是"无所不用其极"了,java一直秉承着:快才是王道的真理,做的很到位啊!其中需要注意到注释标红的地方,意思是对应的HashMap初始大小"必须为2的整数倍"才可以,这点需要注意,具体原因请继续往后看,后面有详细的解释说明。
通过JDK1.7的HashMap构造函数可以发现并推断,HashMap底层实现也是基于数组实现的,但是该数组为Entry对象数组,不过这点通过查看源代码发现1.7之前是直接使用Entry对象来操作的,在1.8之后换为Node对象了,它们两者都是继承自Map.Entry<K,V>,所以都是一样的,我猜想应该是为了区别Map中的Entry对象防止混用,故将底层封装对象该名为Node,具体就上源代码看吧:
JDK1.8源码:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
JDK1.7和JDK1.6源码:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
通过源代码发现,在构造节点的时候又一个next属性,其实它就是指向下一个的引用,不难推测到HashMap底层其实是:基于数组和单向链表结合的存储方式实现。其中不同版本的JDK存取值都是要计算key值的hash值,计算hash值的作用就是避免hash碰撞,尽量减少单向链表的产生,因为链表中查找一个元素需要遍历。HashMap底层结构图:
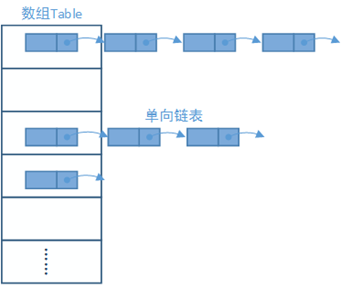
这里需要提到的是,使用hashMap的时候,引入的key对象必须重写hashCode()和equal()两个函数,原因可以参考源码判断条件(if (e.hash == hash && ((k = e.key) == key || key.equals(k)))),如果hashCode()没重写,则压根找不到对应数组,如果equal()没重写,则无法判断key值的内容是否相等。
Get — 获取数据
1.7底层源码使用的是有一个很关键的地方为:
static int indexFor(int h, int length) {
return h & (length-1);
}
第一次看到这个方法很是不理解,不是应该用 h % length吗?其实这里用了一个非常巧妙的方法来取这个余数。在计算机中CPU做除法运算、取余运算耗费的CPU周期都比较长,一般几十个CPU周期,而位移运算、位运算只用一个CPU周期。这样对于性能要求高的地方,就可以用位运算代替普通的除法、取余等运算,JDK源码中有很多这样的例子。
为了能够使用位运算求出这个余数,length必须是2的N次方,这也是我们上面初始化数组大小时要求的,然后使用 h & (length-1),就可以求出余数。具体的算法推导,请自行搜索。
我们用个例子来说明下,如一个Key经过运算的hash为21,length为16:
直接取余运算:21 % 16 = 5
位运算:10101(21) & 01111(16-1) = 00101(5)
哇,这就是计算机运算的魅力,这就是算法的作用。
另外,在java8之后hashmap进行了优化:由于单向链表的查询时间复杂度为O(n),在极端情况下可能存在性能问题,于是java8针对链表长度大于8的情况会使用时间复杂度为O(log n)的红黑树进行存储来提升存储查询的效率。具体可以查看java8的源代码
addEntry — 添加数据
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
threshold:HashMap实际可以存储的Key的个数,如果size大于threshold,说明HashMap已经太饱和了,非常容易发生hash碰撞,导致单向链表的产生。
在inflateTable方法中,我们可以看到
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
所以这个值是由HashMap的capacity 和负载因子(loadFactor默认:0.75)计算出来的。loadFactor越小,相同的capacity就更频繁地扩容,这样的好处是HashMap会很大,产生hash碰撞的几率就更小,但需要的内存也更多,这就是所谓的空间换时间。
在这里也注意,扩容时会直接将原来容量乘以2,满足了length为2的N次方的条件。
整个处理过程:
put的时候,首先会根据key的hashCode值计算出一个位置,该位置就是此对象准备往数组中存放的位置。如果该位置没有对象存在,就将此对象直接放到数组当中;如果该位置已经有对象存在,则顺着此存在的对象的链开始寻找(Entry或Node类有一个其自身类型的 next 成员变量,指向了该对象的下一个对象),如果此链上有对象的话,再去使用equals方法进行比较,都比较完发现都是false,则将该对象放到数组中,然后将数组中该位置以前存在的那个对象链接到此对象的后面。(这个是因为我们一般后进入的数据应该是属于比较新或热的数据,用户一般常用的是最新数据,故将后进入的数据优先放入到数组上可以直接查询到,将以前存在的数据往列表上顺延)
HashMap源码自我认知总结
(1)HashMap的内部存储结构其实是数组和链表的结合。当实例化一个HashMap时,系统会创建一个长度为Capacity的Entry数组,这个长度被称为容量(Capacity),在这个数组中可以存放元素的位置我们称之为“桶”(bucket),每个bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。每个bucket中存储一个元素,即一个Entry对象,但每一个Entry对象可以带一个引用变量,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Entry链。
(2) 在存储一对值时(Key—->Value对),实际上是存储在一个Entry的对象e中,程序通过key计算出Entry对象的存储位置。换句话说,Key—->Value的对应关系是通过key—-Entry—-value这个过程实现的,所以就有我们表面上知道的key存在哪里,value就存在哪里。
(3)HashMap的冲突处理是用的是链地址法, 将所有哈希地址相同的记录都链接在同一链表中。也就是说,当HashMap中的每一个bucket里只有一个Entry,不发生冲突时,HashMap是一个数组,根据索引可以迅速找到Entry。但是,当发生冲突时,单个的bucket里存储的是一个Entry链,系统必须按顺序遍历每个Entry,直到找到为止。为了减少数据的遍历,冲突的元素都是直接插入到当前的bucket中的,所以,最早放入bucket中的Entry,位于Entry链中的最末端。这从put(K key,V value)中也可以看出,在同一个bucket存储Entry链的情况下,新放入的Entry总是位于bucket中。
生产应用总结
HashMap是一个非常高效的Key、Value数据结构,GET的时间复杂度为:O(1) ~ O(n),我们在使用HashMap时需要注意以下几点:
1. 声明HashMap时最好使用带initialCapacity的构造函数,传入数据的最大size,可以避免内部数组resize;
2. 性能要求高的地方,可以将loadFactor设置的小于默认值0.75,使hash值更分散,用空间换取时间;
以上都是个人的见解,有什么不对的或者有什么建议的欢迎指正,希望不吝赐教哈!后续我会将其他源码心得持续更新的,敬请关注哈!!!另外,JDK1.8对应的HashMap有了很大的改变,底层不仅使用了数组 + 链表,还使用了 红黑二叉树 用来提升查询性能,这快需要单独提出一章来说这块的内容;还有,针对多线程下的ConcurrentHashMap也是一个比较重要的知识点,也需要单独拿出来说一下。如果有感兴趣的盆友,欢迎查看我后续的博客:http://www.cnblogs.com/liang1101/p/6407871.html
Java泛型底层源码解析-ArrayList,LinkedList,HashSet和HashMap的更多相关文章
- Java泛型底层源码解析--ConcurrentHashMap(JDK1.7)
1. Concurrent相关历史 JDK5中添加了新的concurrent包,相对同步容器而言,并发容器通过一些机制改进了并发性能.因为同步容器将所有对容器状态的访问都串行化了,这样保证了线程的安全 ...
- Java容器源码解析之——LinkedList
我们直接从源码来分析LinkedList的结构: public class LinkedList<E> extends AbstractSequentialList<E> im ...
- 【Java实战】源码解析Java SPI(Service Provider Interface )机制原理
一.背景知识 在阅读开源框架源码时,发现许多框架都支持SPI(Service Provider Interface ),前面有篇文章JDBC对Driver的加载时应用了SPI,参考[Hibernate ...
- Java之ConcurrentHashMap源码解析
ConcurrentHashMap源码解析 目录 ConcurrentHashMap源码解析 jdk8之前的实现原理 jdk8的实现原理 变量解释 初始化 初始化table put操作 hash算法 ...
- Java线程池源码解析
线程池 假如没有线程池,当存在较多的并发任务的时候,每执行一次任务,系统就要创建一个线程,任务完成后进行销毁,一旦并发任务过多,频繁的创建和销毁线程将会大大降低系统的效率.线程池能够对线程进行统一的分 ...
- Java 8 ThreadLocal 源码解析
Java 中的 ThreadLocal是线程内的局部变量, 它为每个线程保存变量的一个副本.ThreadLocal 对象可以在多个线程中共享, 但每个线程只能读写其中自己的副本. 目录: 代码示例 源 ...
- Java集合框架源码(二)——hashSet
注:本人的源码基于JDK1.8.0,JDK的版本可以在命令行模式下通过java -version命令查看. 在前面的博文(Java集合框架源码(一)——hashMap)中我们详细讲了HashMap的原 ...
- JAVA常用集合源码解析系列-ArrayList源码解析(基于JDK8)
文章系作者原创,如有转载请注明出处,如有雷同,那就雷同吧~(who care!) 一.写在前面 这是源码分析计划的第一篇,博主准备把一些常用的集合源码过一遍,比如:ArrayList.HashMap及 ...
- java集合类型源码解析之ArrayList
前言 作为一个老码农,不仅要谈架构.谈并发,也不能忘记最基础的语言和数据结构,因此特开辟这个系列的文章,争取每个月写1~2篇关于java基础知识的文章,以温故而知新. 如无特别之处,这个系列文章所使用 ...
随机推荐
- Notes of Daily Scrum Meeting(11.13)
Notes of Daily Scrum Meeting(11.13) 今天邹欣老师给我们讲课大家还是很有收获的,大家课堂的参与度确实有了很大的提升,而且邹欣老师关于项目Scrum Meeting报告 ...
- 2-Tenth Scrum Meeting20151210
任务分配 闫昊: 今日完成:请假.(编译) 明日任务:参加会议讨论,安排任务分工. 唐彬: 今日完成:请假.(编译) 明日任务:参加会议讨论,安排任务分工. 史烨轩: 今日完成:请假.(编译) 明日任 ...
- second scrum meeting - 151026
摘要:这一周的工作其实进行的并没有很迅速~不过我们团队的每个人都在慢慢进行自己的工作,并且我们也完成了大致的页面设计,开发了主页面的框架,并且我们也会开始着手学习服务器的操作,还有更加完善主页面的框架 ...
- 20172301 2017-2018-2 《程序设计与数据结构》实验一《Java开发环境的熟悉》实验报告
20172301 2017-2018-2 <程序设计与数据结构>实验一<Java开发环境的熟悉>实验报告 课程:<程序设计与数据结构> 班级: 1723 姓名: 郭 ...
- 20162328蔡文琛week08
学号 20162328 <程序设计与数据结构>第X周学习总结 教材学习内容总结 错误和异常代表不常见的或不正确处理的对象. 抛出异常时输出的消息提供了方法调用栈的轨迹. 每个catch子句 ...
- Java锁的种类以及辨析
锁作为并发共享数据,保证一致性的工具,在JAVA平台有多种实现(如 synchronized 和 ReentrantLock等等 ) .这些已经写好提供的锁为我们开发提供了便利,但是锁的具体性质以及类 ...
- beat冲刺(3/7)
目录 摘要 团队部分 个人部分 摘要 队名:小白吃 组长博客:hjj 作业博客:beta冲刺(3/7) 团队部分 后敬甲(组长) 过去两天完成了哪些任务 整理博客 ppt模板 接下来的计划 做好机动. ...
- Java编写的电梯模拟系统《结对作业》
作业代码:https://coding.net/u/liyi175/p/Dianti/git 伙伴成员:李伊 http://home.cnblogs.com/u/Yililove/ 对于这次作业,我刚 ...
- SQL语句中的output用法
private void button2_Click(object sender, RoutedEventArgs e) { using (SqlConnection conn = new SqlCo ...
- #Leetcode# 451. Sort Characters By Frequency
https://leetcode.com/problems/sort-characters-by-frequency/ Given a string, sort it in decreasing or ...