MySQL(ORM框架)
day63
参考:http://www.cnblogs.com/wupeiqi/articles/5713330.html
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html |
可以连接不同的数据库。
1. ORM框架:SQLAlchemy
- 作用:
1. 提供简单的规则
2. 自动转换成SQL语句
- DB first: 手动创建数据库以及表 -> ORM框架 -> 自动生成类
- code first: 手动创建类、和数据库 -> ORM框架 -> 以及表
a. 功能
- 创建数据库表
- 连接数据库(非SQLAlchemy,pymyql,mysqldb,....)
- 类转换SQL语句
- 操作数据行
增
删
改
查
- 便利的功能
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine Base = declarative_base()
class UsersType(Base):#必须继承base
__tablename__ = 'usertype'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
title = Column(String(32), nullable=True, index=True)#建立索引 # 创建单表
class Users(Base):#必须继承base
__tablename__ = 'users'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
name = Column(String(32), nullable=True, default='sf', index=True)#建立索引
extra = Column(String(16), unique=True)#唯一索引 user_type_id = Column(Integer, ForeignKey("usertype.id"))#建立外键 user_type_id对应usertype中的id __table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), #联合唯一索引
Index('ix_id_name', 'name', 'extra'), #普通索引
) #连远程 127.0.0.1本机 配置 #最多5个连接
engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow = 5)
Base.metadata.create_all(engine)
实现增、删、改、查
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine Base = declarative_base() class UsersType(Base):#必须继承base
__tablename__ = 'usertype'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
title = Column(String(32), nullable=True, index=True)#建立索引 # 创建单表
class Users(Base):#必须继承base
__tablename__ = 'users'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
name = Column(String(32), nullable=True, default='sf', index=True)#建立索引
extra = Column(String(16), unique=True)#唯一索引 user_type_id = Column(Integer, ForeignKey("usertype.id"))#建立外键 __table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), #联合唯一索引
Index('ix_id_name', 'name', 'extra'),#普通索引
) # #连远程 127.0.0.1本机 配置 #最多5个连接
# engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow = 5)
# Base.metadata.create_all(engine) #创建表
# #Base.metadata.drop_all(engine)# 删掉表 #建表
def create_db():
engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Base.metadata.create_all(engine) # 创建表
#删表
def drop_db():
engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Base.metadata.drop_all(engine) # 创建表 engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Session = sessionmaker(bind=engine)
session = Session() # # 增
# # 添加一行
# # obj1 = UsersType(title="狗剩")#给usertype表添加
# # session.add(obj1)
# '''添加多行数据'''
# objs = [
# UsersType(title='tghh'),
# UsersType(title='sdcs'),
# UsersType(title='cbsu'),
# ]
# session.add_all(objs)
# session.commit() # #查
# user_type_list = session.query(UsersType).all()#其中每一个元素是UserType类型,每一个对象是一行数据
# print(type(user_type_list[0])) #row是UsersType类对象 ,类代指表
# for row in user_type_list:
# print(row.id, row.title) # #查部分 #相当于映射 #相当于where
# user_type_list = session.query(UsersType.id, UsersType.title).filter(UsersType.id > 2)#其中每一个元素是UserType类型,每一个对象是一行数据
# for row in user_type_list:
# print(row.id, row.title) # #删
# session.query(UsersType.id, UsersType.title).filter(UsersType.id > 2).delete()
# session.commit() #改
#session.query(UsersType.id, UsersType.title).filter(UsersType.id > 0).update({'title':"nizhipeng"})#批量更改
#session.query(UsersType.id, UsersType.title).filter(UsersType.id > 0).update({UsersType.title: UsersType.title+"x"}, synchronize_session=False)
session.query(UsersType.id, UsersType.title).filter(UsersType.id > 0).update({"title": UsersType.id + 1}, synchronize_session="evaluate")
session.commit()#需要确认 session.close()
其他:
# 条件
#or,and,in,between
ret = session.query(Users).filter_by(name='alex').all()
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all() # 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()#非 # 限制
ret = session.query(Users)[1:2] #切片limit # 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 分组
from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all() ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()#通过名字分组 # 连表
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() ret = session.query(Person).join(Favor).all() ret = session.query(Person).join(Favor, isouter=True).all() #out join # 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()#上下连接 去重 q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all() # 不去重
其中连表:
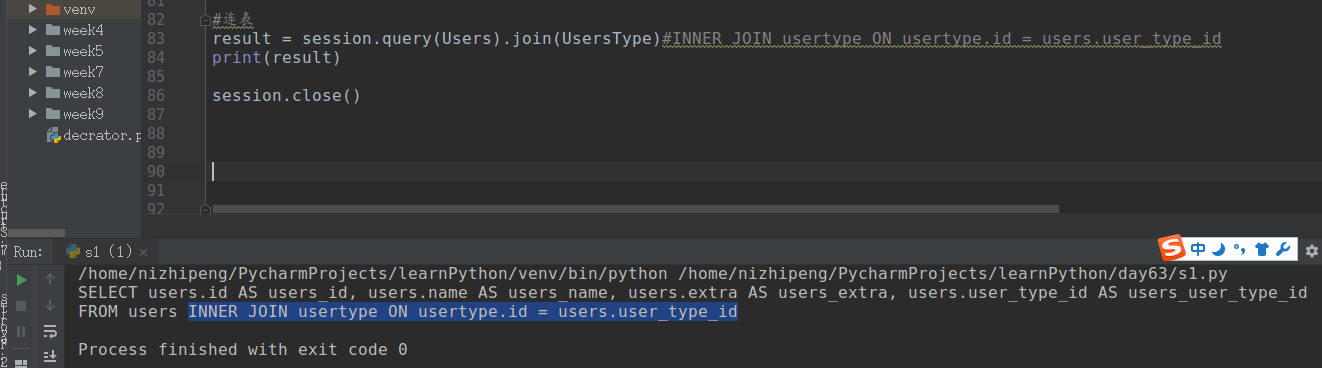
改变左右参数顺序,可设置right join或left join。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine Base = declarative_base() class UsersType(Base):#必须继承base
__tablename__ = 'usertype'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
title = Column(String(32), nullable=True, index=True)#建立索引 # 创建单表
class Users(Base):#必须继承base
__tablename__ = 'users'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
name = Column(String(32), nullable=True, default='sf', index=True)#建立索引
extra = Column(String(16), unique=True)#唯一索引 user_type_id = Column(Integer, ForeignKey("usertype.id"))#建立外键 __table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), #联合唯一索引
Index('ix_id_name', 'name', 'extra'),#普通索引
) # #连远程 127.0.0.1本机 配置 #最多5个连接
# engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow = 5)
# Base.metadata.create_all(engine) #创建表
# #Base.metadata.drop_all(engine)# 删掉表 #建表
def create_db():
engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Base.metadata.create_all(engine) # 创建表
#删表
def drop_db():
engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Base.metadata.drop_all(engine) # 创建表 engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Session = sessionmaker(bind=engine)
session = Session() # #连表
# result = session.query(Users).join(UsersType).all()#INNER JOIN usertype ON usertype.id = users.user_type_id
# print(result) # #子查询
# #select * from (select * from tb) as B
# q1 = session.query(UsersType).filter(UsersType.id > 2).subquery()#子查询 #当做一张表
# result = session.query(q1).all()
# print(result) # #select id, (select id from where user.user_type_id = 1) from xxx;
# result = session.query(UsersType.id, session.query(Users).filter(Users.id == 1).subquery()).all()
# #UsersType.id 加上 Users的第一行
# for row in result:
# print(row) #select * from users where users.user_type_id = usertype.id;
result = session.query(UsersType.id, session.query(Users).filter(Users.user_type_id == UsersType.id).as_scalar())#作为一项
#session.query(Users).as_scalar()#作为一项#带括号(SELECT users.id, users.name, users.extra, users.user_type_id FROM users)
print(result) session.close()
以上为连表与子查询。
relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine Base = declarative_base() class UsersType(Base):#必须继承base
__tablename__ = 'usertype'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
title = Column(String(32), nullable=True, index=True)#建立索引 # 创建单表
class Users(Base):#必须继承base
__tablename__ = 'users'#表名 #自增
id = Column(Integer, primary_key=True, autoincrement=True)#生成三列 Column
name = Column(String(32), nullable=True, default='sf', index=True)#建立索引
extra = Column(String(16), unique=True)#唯一索引 user_type_id = Column(Integer, ForeignKey("usertype.id"))#建立外键 __table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), #联合唯一索引
Index('ix_id_name', 'name', 'extra'),#普通索引
) user_type = relationship('UsersType')
# #连远程 127.0.0.1本机 配置 #最多5个连接
# engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow = 5)
# Base.metadata.create_all(engine) #创建表
# #Base.metadata.drop_all(engine)# 删掉表 #建表
def create_db():
engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Base.metadata.create_all(engine) # 创建表
#删表
def drop_db():
engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Base.metadata.drop_all(engine) # 创建表 engine = create_engine("mysql+pymysql://root:112358@127.0.0.1:3306/nzp?charset=utf8", max_overflow=5)
Session = sessionmaker(bind=engine)
session = Session() # 问题1. 获取用户信息以及与其关联的用户类型名称(FK,Relationship=>正向操作)
user_list = session.query(Users)
for row in user_list:
print(row.name, row.id, row.user_type.title)#row.user_type直接在usertype中将对应的title数据找到了 # 问题2. 获取用户类型
type_list = session.query(UsersType)
for row in type_list:
print(row.id, row.title, session.query(Users).filter(Users.user_type_id == row.id).all()) # type_list = session.query(UserType)
# for row in type_list:
# print(row.id,row.title,row.xxoo) session.close()
也可参考:https://www.jianshu.com/p/9771b0a3e589
MySQL(ORM框架)的更多相关文章
- MySQL—ORM框架,sqlalchemy模块
武老师博客:ORM框架介绍 import os #1.当一类函数公用同样参数时候,可以转变成类运行 - 分类 #2.面向对象: 数据和逻辑组合在一起了 #3. 一类事物共同用有的属性和行为(方法) # ...
- mysql ORM框架及SQLAlchemy
一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取 ...
- Python操作mysql之SQLAchemy(ORM框架)
SQLAchemy SQLAchemy 解析: SQLAchemy是python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作, 简言之便是:将对象转换成SQ ...
- MySQL之ORM框架SQLAlchemy
一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取 ...
- MySQL 第八篇:ORM框架SQLAlchemy
一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取 ...
- mysql八:ORM框架SQLAlchemy
阅读目录 一 介绍 二 创建表 三 增删改查 四 其他查询相关 五 正查.反查 一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进 ...
- Mysql(八):ORM框架SQLAlchemy
一 介绍 SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取 ...
- Django(三) 模型:ORM框架、定义模型类并创建一个对应的数据库、配置Mysql数据库
一.模型概述 https://docs.djangoproject.com/zh-hans/3.0/intro/tutorial02/ https://www.runoob.com/django/dj ...
- 冰冻三尺非一日之寒-mysql(orm/sqlalchemy)
第十二章 mysql ORM介绍 2.sqlalchemy基本使用 ORM介绍: orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似pyt ...
随机推荐
- 操作系统——MiniDos
#include <stdio.h> #include <string.h> #include <windows.h> ],token[],ch,sa[]; ]={ ...
- 练习并熟练掌握交互式 SQL 语言
哈工大数据库系统 实验:练习并熟练掌握交互式 SQL 语言 实验目的:基于给定的 OrderDB 数据库, 练习并熟练掌握交互式 SQL 语言实验环境:sql sever 2008 附:Order ...
- linux安装json
安装Json库 1.下载JsonCpphttp://sourceforge.net/projects/jsoncpp/files/ 2.下载sconshttp://sourceforge.net/pr ...
- oracle常用函数速记
1.截断中文字符串 CREATE OR REPLACE function cn_cutstr(v_str varchar2,v_len number) return varchar2 IS v_i n ...
- 2018.07.17 HAOI2016 找相同字符(SAM)
传送门 就是给两个字符串,让你求公共字串的个数. 本来大佬们都是用的广义后缀自动机,但我感觉后缀自动机已经可以做这道题了.我们对其中一个字串建出后缀自动机,然后用另外一个后缀自动机在上面统计贡献即可. ...
- 22. Valuing Water 珍惜水资源
. Valuing Water 珍惜水资源 ① Humanity uses a little less than half the water available worldwide.Yet occu ...
- Linux服务器部署系列之三—DNS篇
网上介绍DNS的知识很多,在这里我就不再讲述DNS原理及做名词解释了.本篇我们将以一个实例为例来讲述DNS的配置,实验环境如下: 域名:guoxuemin.cn, 子域:shenzhen.guoxue ...
- VHDL 中的数据转换函数
2013年8月5日 ieee.std_logic_arith.all SXT:是对std_logic_vector转换成std_logic_vector数据类型,并进行符号扩展. <slv_sx ...
- SPSS-相关性和回归分析(一元线性方程)案例解析
任何事物和人都不是以个体存在的,它们都被复杂的关系链所围绕着,具有一定的相关性,也会具备一定的因果关系,(比如:父母和子女,不仅具备相关性,而且还具备因果关系,因为有了父亲和母亲,才有了儿子或女儿), ...
- spring boot docker 初尝试
Docker服务中进程间通信通过/var/run/docker.sock实现,默认服务不提供监听端口,因此使用docker remote api 需要手动绑定端口. 在centos7.2下,可以进行这 ...