bsdiff差分算法
bsdiff的基本原理
bsdiff是由Conlin Percival开源的一个优秀的差分算法,而且是跨平台的。在Android系统中所使用的imgdiff本质上就是bsdiff。
bsdiff的依据
在传统更新中,包含了复制和插入两种操作,复制指的是找到old文件中所匹配的部分,将其复制到新文件中。插入指的是将old文件中所没有的数据插入到新文件中。这种方式在二进制文件更新中并不适用,因为对源代码进行少量的修改就会导致二进制文件产生较大的差异,从而复制和插入指令增多,生成的更新包远大于理想状态。所以bsdiff并没有这样做,在一个新的二进制文件,往往会包含这样几部分:不受更新代码影响的部分,更新代码后直接影响的部分,更新代码后间接影响的部分。
不受更新代码影响的部分:这一区域变化非常稀疏,即使有变化也是部分指针或寄存器的地址进行了一两个字节的变动,这就导致字节差异几乎为0
更新代码后间接影响的部分:在更新了源代码后,有些代码和数据的地址会发生偏移,而且偏移值相同。
也就是说,在新旧两个文件中,源代码块相同的部分,字节差异为0或一个固定值,这个固定值就是地址变化的偏移量。由于这一特性,导致产生的数据将会是高度可压缩的。在bsdiff算法中会找到这两部分,求出字节差异,作为diff string并进行压缩保存。
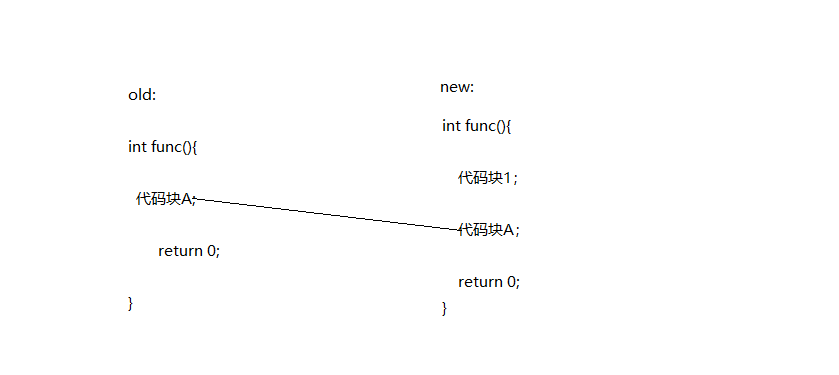
如图在old中添加代码块1(和代码块A不相关),在二进制文件中会导致代码块A的地址发生偏移,偏移值是相同的,这样old中的代码块A和new中的代码块A求字节差异时就会为一个固定值,具有高度可压缩性。
更新代码后直接影响的部分:如上图,当添加了代码块1后,会导致二进制文件产生新的数据,这部分数据在old中并不存在,bsdiff算法会将其作为extra string进行压缩保存。所以到这里我们能够得出bsdiff的更新数据=diff string+extra string。
bsdiff更新数据的基本结构
bsdiff更新数据由四部分组成:Header,ctrl block,diff block,extra block。
Header的结构:
| start/bytes | length/bytes | content |
| 0 | 8 | "BSDIFF40" |
| 8 | 8 | the length of ctrl block |
| 16 | 8 | the length of diff block |
| 24 | 8 | 新文件的大小 |
ctrl block:这部分内容是由(x,y,z)组成。x代表从old中读取x字节和diff block中读取x字节做字节加运算,y代表从extra block中读取y字节数据并且插入到新文件中,z代表在old中向前移动z字节。
diff block:记录了diff string,也就是字节的差值
extra block:记录了new文件中新生成的字节值
算法基本分析
bsdiff主要可以分为三部分:
1.通过排序技术对old文件的内容进行排序,形成字典序。这里的排序使用的是后缀排序时间复杂度nlogn,空间复杂度O(n),当然也可以使用hash技术进行排序。
2.通过二分法查找最长的匹配len,有了这个len,就可以计算出diff string,和extra string.
3.将diff string+extra string压缩到更新文件中。
关于后缀排序和二分法查找可以自行百度或google。下面边阅读代码边进行分析
off_t *I;
off_t scan,pos,len;
off_t lastscan,lastpos,lastoffset;
off_t oldscore,scsc;
off_t s,Sf,lenf,Sb,lenb;
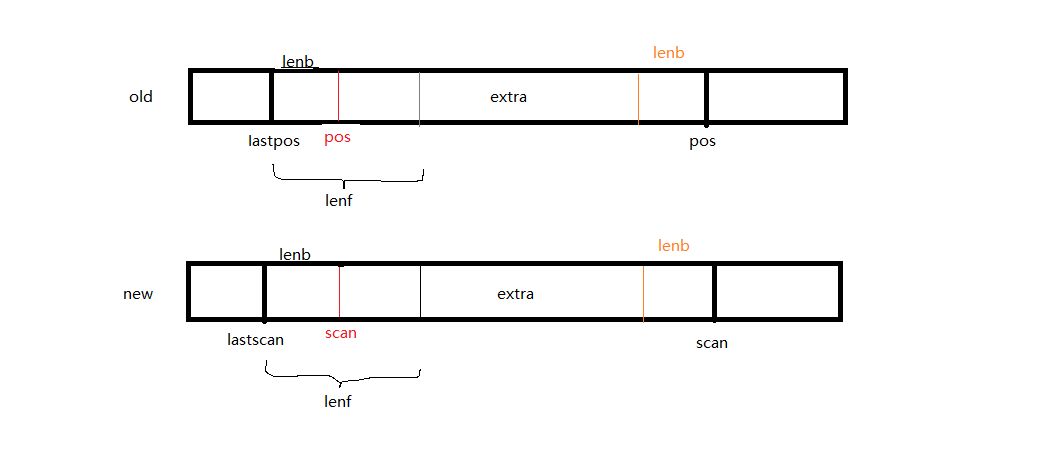
上面有几个变量代表的意义,对分析算法有着很重要的意义。I代表已经排好的字典序,scan代表new中要查询的字符,pos代表old中相匹配的字符,len代表匹配的长度,lastscan=scan-lenb,lastpos=pos-lenb。lastoffset=scan-pos。lastoffset为new和old的偏移量,如果在old中的内容A在new中可以找到,而且A+lastoffset=new中的A,则认为old和new中的A相同。oldscore代表相同内容的len,scsc代表new中开始和old中比较是否相同开始的位置,而old中开始的位置是scsc+lastoffset。lenf代表扩展前缀,lenb代表扩展后缀。
while(scan<newsize) {
oldscore=;
for(scsc=scan+=len;scan<newsize;scan++) {
len=search(I,old,oldsize,new+scan,newsize-scan,
,oldsize,&pos);
printf("len==%d\n",len);
for(;scsc<scan+len;scsc++)
if((scsc+lastoffset<oldsize) &&
(old[scsc+lastoffset] == new[scsc]))
oldscore++;
printf("oldscore+===%d\n",oldscore);
if(((len==oldscore) && (len!=)) ||
(len>oldscore+)) break;
if((scan+lastoffset<oldsize) &&
(old[scan+lastoffset] == new[scan]))
oldscore--;
printf("oldscore-====%d\n",oldscore);
};
if((len!=oldscore) || (scan==newsize)) {
printf("cal len=%d,scan=%d\n",len,scan);
s=;Sf=;lenf=;
for(i=;(lastscan+i<scan)&&(lastpos+i<oldsize);) {
if(old[lastpos+i]==new[lastscan+i]) s++;
i++;
if(s*-i>Sf*-lenf) { Sf=s; lenf=i; };
};
printf("Sf=%d,lenf=%d\n",Sf,lenf);
lenb=;
if(scan<newsize) {
s=;Sb=;
for(i=;(scan>=lastscan+i)&&(pos>=i);i++) {
if(old[pos-i]==new[scan-i]) s++;
if(s*-i>Sb*-lenb) { Sb=s; lenb=i; };
};
printf("Sb=%d,lenb=%d\n",Sb,lenb);
};
if(lastscan+lenf>scan-lenb) {
overlap=(lastscan+lenf)-(scan-lenb);
s=;Ss=;lens=;
for(i=;i<overlap;i++) {
if(new[lastscan+lenf-overlap+i]==
old[lastpos+lenf-overlap+i]) s++;
if(new[scan-lenb+i]==
old[pos-lenb+i]) s--;
if(s>Ss) { Ss=s; lens=i+; };
};
lenf+=lens-overlap;
lenb-=lens;
};
for(i=;i<lenf;i++)
db[dblen+i]=new[lastscan+i]-old[lastpos+i];
for(i=;i<(scan-lenb)-(lastscan+lenf);i++)
eb[eblen+i]=new[lastscan+lenf+i];
dblen+=lenf;
eblen+=(scan-lenb)-(lastscan+lenf);
offtout(lenf,buf);
BZ2_bzWrite(&bz2err, pfbz2, buf, );
if (bz2err != BZ_OK)
errx(, "BZ2_bzWrite, bz2err = %d", bz2err);
offtout((scan-lenb)-(lastscan+lenf),buf);
BZ2_bzWrite(&bz2err, pfbz2, buf, );
if (bz2err != BZ_OK)
errx(, "BZ2_bzWrite, bz2err = %d", bz2err);
offtout((pos-lenb)-(lastpos+lenf),buf);
BZ2_bzWrite(&bz2err, pfbz2, buf, );
if (bz2err != BZ_OK)
errx(, "BZ2_bzWrite, bz2err = %d", bz2err);
lastscan=scan-lenb;
lastpos=pos-lenb;
lastoffset=pos-scan;
};
};
这一部分是bsdiff的核心,主要的工作就是查询到len,比较new和old中的内容是否相同,如果len范围内都相同则直接进行下一次循环。如果不相同的字节数大于8或scan达到了最大则跳出对应的循环,开始生成lenf,lenb,extra数据等。lenf其实就是diff string,可以看到diff string就是由lastscan到scan与lastpos到pos这个区间得到的,这个区间会被划分为lenf,代表diff string,而剩下的部分即为extra string。lenf代表的扩展前缀,其实也就是diff string. lenb代表的是扩展后缀,会在下次生成diff string时包含进去。那么为什么要这样做呢?因为在匹配到最长的len后,bsdiff并不是直接将匹配到的内容打包,而是从lastscan到scan开始前向延伸进行后缀扩展,得到lenf,称为扩展前缀。在lastscan也包含了扩展后缀,扩展前缀和扩展后缀必须至少有50%与old相同。如图所示:
算法实例
下面以一个例子解释bsdiff运行过程:
old:abcdfghilklmnopqrstuvwxyz1234567890abcd
new:abcdffhijkluvaxyz123456789zxcvbnm
1.首先获取到字典序
qsufsort:I[]==,,
qsufsort:I[]==,, qsufsort:I[]==,,0abcd qsufsort:I[]==,,1234567890abcd qsufsort:I[]==,,234567890abcd qsufsort:I[]==,,34567890abcd qsufsort:I[]==,,4567890abcd qsufsort:I[]==,,567890abcd qsufsort:I[]==,,67890abcd qsufsort:I[]==,,7890abcd qsufsort:I[]==,,890abcd qsufsort:I[]==,,90abcd qsufsort:I[]==,,abcd qsufsort:I[]==,,abcdfghilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,bcd qsufsort:I[]==,,bcdfghilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,cd qsufsort:I[]==,,cdfghilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,d qsufsort:I[]==,,dfghilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,fghilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,ghilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,hilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,ilklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,klmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,lklmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,lmnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,mnopqrstuvwxyz1234567890abcd qsufsort:I[]==,,nopqrstuvwxyz1234567890abcd qsufsort:I[]==,,opqrstuvwxyz1234567890abcd qsufsort:I[]==,,pqrstuvwxyz1234567890abcd qsufsort:I[]==,,qrstuvwxyz1234567890abcd qsufsort:I[]==,,rstuvwxyz1234567890abcd qsufsort:I[]==,,stuvwxyz1234567890abcd qsufsort:I[]==,,tuvwxyz1234567890abcd qsufsort:I[]==,,uvwxyz1234567890abcd qsufsort:I[]==,,vwxyz1234567890abcd qsufsort:I[]==,,wxyz1234567890abcd qsufsort:I[]==,,xyz1234567890abcd qsufsort:I[]==,,yz1234567890abcd qsufsort:I[]==,,z1234567890abcd
2.new:abcdffhijkl-old:abcdfghilkl 字节值相减获得diffstring
3.new:uvaxyz123456789-old:uvwxyz123456789 字节值相减获得diff string
4.zxcvbnm作为extra string进行打包
5.通过bzip2压缩生成升级文件。bzip2具有高度可压缩性,非常适合bsdiff
参考链接:
bsdiff官方网站
http://www.daemonology.net/bsdiff/
bsdfii介绍
http://www.daemonology.net/papers/bsdiff.pdf
bsdiff理解
https://cloud.tencent.com/developer/article/1008518
bsdiff理解
https://blog.csdn.net/darling757267/article/details/80652267
编译bsdiff所遇到问题的解决方法
https://www.cnblogs.com/rainboy2010/p/7400317.html
bsdiff差分算法的更多相关文章
- 洛谷 [USACO17OPEN]Bovine Genomics G奶牛基因组(金) ———— 1道骗人的二分+trie树(其实是差分算法)
题目 :Bovine Genomics G奶牛基因组 传送门: 洛谷P3667 题目描述 Farmer John owns NN cows with spots and NN cows without ...
- 【matlab】运动目标检测之"背景差分算法“
clear; clc; i1=imread('D:\Work\1.png'); i2=imread('D:\Work\2.png'); i1=rgb2gray(i1); i2=rgb2gray(i2) ...
- Codeforces 191C (LCA+树上差分算法)
题面 传送门 题目大意: 给出一棵树,再给出k条树上的简单路径,求每条边被不同的路径覆盖了多少次 分析 解决这个问题的经典做法是树上差分算法 它的思想是把"区间"修改转化为左右端点 ...
- 【蓝桥杯C/C++组】备赛基础篇之差分算法
一.个人理解 前面学习了前缀和算法,对于访问任意区间的速度是比较快的,但如果我们要修改某个区间的数呢,对于前缀和算法来说这还是有点棘手. 所以我们来学学新的算法:差分算法! 前缀和数组储存的是前n个数 ...
- Myers差分算法的理解、实现、可视化
作者:Oto_G QQ: 421739728 目录 简介 基础 差异的描述 好的差异比较 算法介绍 名词解释 两个定理 绘制编辑图 感谢 简介 本文章对Myers差分算法(Myers Diff Alg ...
- matlab差分算法
今天实现了<一类求解方程全部根的改进差分进化算法>(by 宁桂英,周永权),虽然最后的实现结果并没有文中分析的那么好,但是本文依然是给了一个求解多项式全部实根的基本思路.思路是对的,利用了 ...
- 强化学习-时序差分算法(TD)和SARAS法
1. 前言 我们前面介绍了第一个Model Free的模型蒙特卡洛算法.蒙特卡罗法在估计价值时使用了完整序列的长期回报.而且蒙特卡洛法有较大的方差,模型不是很稳定.本节我们介绍时序差分法,时序差分法不 ...
- DOM Diff(差分)算法
1. 算法由来 React调用render()方法后,会生成一个React元素组成的树. 再次调用,生成一个新的树.React比较两者的差异,然后更新UI. 如果单纯使用算法,来查找两个DOM树的差异 ...
- Android 增量更新(BSDiff / bspatch)
Android 增量更新 BSDiff / bspatchhttp://www.daemonology.net/bsdiff/android的代码目录下 \external\bsdiff bsdiff ...
随机推荐
- bottle模板中的替换
line是模板中一行的内容,类似: {{x}}testinfo{{x+10}} x=10时,模板输出: 10testinfo20 x = 10 splits = re.split(r'\{\{(.*? ...
- Zynq系列程序逻辑固化方法
1.创建一个BOOT镜像 该小节主要讲述zynq平台利用软件套件SDK创建一个可固化BOOT镜像. 1.1 选择Ad9361_Eque1工程,选择Xilinx Tools → Create Boot ...
- python 3 字符编码解码问题
python2与python3 字符编码都做了很大的调整,区别: 1.python2字符串默认有两种类型,unicode和str.'你好' !=u'你好' python3字符串默认只有str一种类型, ...
- exp/expdp 与 imp/impdp命令导入导出数据库详解
一.exp命令导出数据库 如何使exp的帮助以不同的字符集显示:set nls_lang=simplified chinese_china.zhs16gbk,通过设置环境变量,可以让exp的帮助以中文 ...
- Java的URL类(一)
转:https://www.cnblogs.com/blackiesong/p/6182038.html Java的URL类(一) Java的网络类可以让你通过网络或者远程连接来实现应用.而且,这个平 ...
- select 下拉选择自动到textarea框
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 从hivesql结果中读取数值到shell变量的方法
为了检查hive表中的数据,并统计展现,需要将查出的结果传入到shell变量,然后统一输出到文本. 最后使用了以下两个方法: 方法一 QUAN=$(hive -S -e "select co ...
- Github Page搜索工具更新 - 探索功能
探索功能提供了一种快速访问有意思的Github Page的途径,每周探索功能会更新有趣的搜索词条,你可以点击感兴趣的词条来获取该词条对应的Github Page. 首批Github Page探索词条包 ...
- IntelliJ常用快捷键及配置
IntelliJ常用快捷键及配置 目录: 1.常用快捷键: 2.常用配置: 1.常用快捷键: (1)psvm:创建main函数 (2)fori:for (int i = 0; i < ; i++ ...
- Spring4.x Jpa + hibernate的配置(废弃JpaTemplate)
近年来 ORM(Object-Relational Mapping,对象关系映射,即实体对象和数据库表的映射)技术市场热闹非凡,各种各样的持久化框架应运而生,其中影响最大的是 Hibernate 和 ...