sklearn交叉验证2-【老鱼学sklearn】
过拟合
过拟合相当于一个人只会读书,却不知如何利用知识进行变通。
相当于他把考试题目背得滚瓜烂熟,但一旦环境稍微有些变化,就死得很惨。
从图形上看,类似下图的最右图:
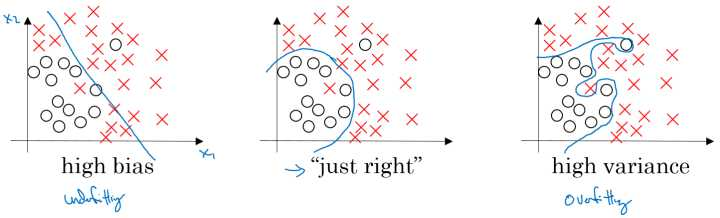
从数学公式上来看,这个曲线应该是阶数太高的函数,因为一般任意的曲线都能由高阶函数来拟合,它拟合得太好了,因此丧失了泛化的能力。
用Learning curve 检视过拟合
首先加载digits数据集,其包含的是手写体的数字,从0到9:
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
然后用SVC(支持向量机)对手写体数字进行分类,当然,这里要介绍的核心函数是learning_curve,先上代码看看:
# 导入支持向量机
from sklearn.svm import SVC
model = SVC(gamma=0.001)
train_sizes, train_loss, test_loss = learning_curve(model, X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
# 平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
在learning_curve中设置了十一法的数据,同时在打分时使用了neg_mean_squared_error方式,也就是方差值,因此这个最后的得分值是负数;train_sizes指定了5轮检视学习曲线(10%, 25%, 50%, 75%, 100%):
最后,我们把根据每轮的训练集大小对于最终得分的影响程度画个图,相当于做题数量的多少跟最终考试成绩的关系图:
# 可视化图形
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_loss_mean, label="Train")
plt.plot(train_sizes, test_loss_mean, label="Test")
plt.legend()
plt.show()
显示图形为:
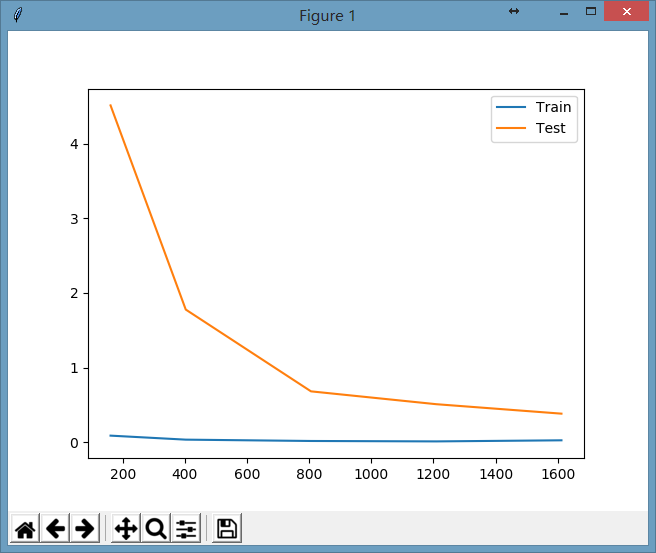
看起来随着做题数量的增加,考试成绩越来越好了(损失函数的值越来越小了),并且考试成绩在慢慢逼近平常的训练成绩。
完整的代码如下:
from sklearn.datasets import load_digits
# 加载数据
digits = load_digits()
X = digits.data
y = digits.target
# 加载学习曲线模块
from sklearn.model_selection import learning_curve
import numpy as np
# 导入支持向量机
from sklearn.svm import SVC
model = SVC(gamma=0.001)
train_sizes, train_loss, test_loss = learning_curve(model, X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
# 平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 可视化图形
import matplotlib.pyplot as plt
plt.plot(train_sizes, train_loss_mean, label="Train")
plt.plot(train_sizes, test_loss_mean, label="Test")
plt.legend()
plt.show()
如果我们把上面代码中SVC参数的gamma值设置为0.1,显示出的图形为:
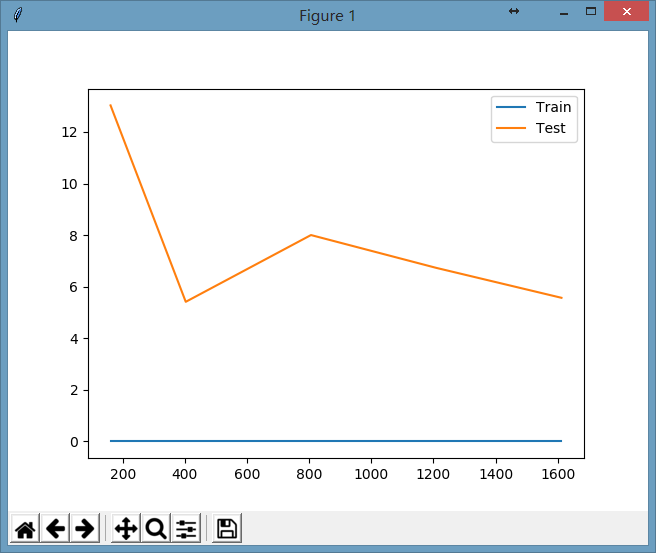
在上面的图形中,我们会发现再增加训练集的数据并没有使测试集的损失值下降,相当于一个人按照他的学习方式做训练题已经够多了,你做更多的训练题都无法提高你的考试成绩了,这时可能需要考虑的是稍微改变一下你的学习方法说不定就能提高考试成绩呢。
这也说明了,在某些情况下题海战术不一定奏效了。
在机器学习中表示为所学到的模型可能太复杂了,产生了过拟合(过拟合表现为训练集的损失函数在下降,但测试集的损失函数不降反升),不具备泛化能力,例如下图中绿色曲线就是一个过拟合的表现:
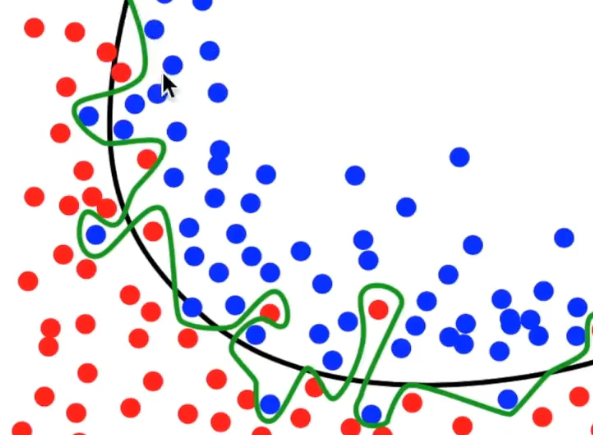
相应的损失函数曲线显示如下所示:
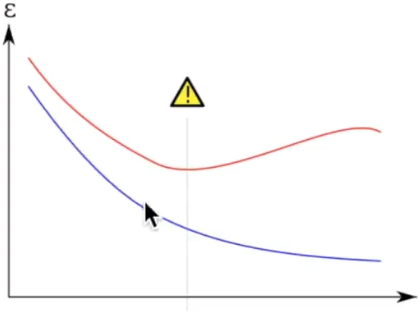
因此如果我们想要查看是否有过拟合,可以通过learning_curve函数来进行并以可视化的方式来查看结果。
sklearn交叉验证2-【老鱼学sklearn】的更多相关文章
- sklearn交叉验证-【老鱼学sklearn】
交叉验证(Cross validation),有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法.于是可以先在一个子集上做分析, 而其它子集则用来做后续对此分析的确认及验证. 一开始 ...
- sklearn交叉验证3-【老鱼学sklearn】
在上一个博文中,我们用learning_curve函数来确定应该拥有多少的训练集能够达到效果,就像一个人进行学习时需要做多少题目就能拥有较好的考试成绩了. 本次我们来看下如何调整学习中的参数,类似一个 ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
- sklearn数据库-【老鱼学sklearn】
在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练. 本节就来看看sklearn提供了哪些可供训练的数据集. 这些数据位于datasets中,网址为:htt ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn标准化-【老鱼学sklearn】
在前面的一篇博文中关于计算房价中我们也大致提到了标准化的概念,也就是比如对于影响房价的参数中有面积和户型,面积的取值范围可以很广,它可以从0-500平米,而户型一般也就1-5. 标准化就是要把这两种参 ...
- 二分类问题续 - 【老鱼学tensorflow2】
前面我们针对电影评论编写了二分类问题的解决方案. 这里对前面的这个方案进行一些改进. 分批训练 model.fit(x_train, y_train, epochs=20, batch_size=51 ...
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- 机器学习- Sklearn (交叉验证和Pipeline)
前面一节咱们已经介绍了决策树的原理已经在sklearn中的应用.那么这里还有两个数据处理和sklearn应用中的小知识点咱们还没有讲,但是在实践中却会经常要用到的,那就是交叉验证cross_valid ...
随机推荐
- Nginx ServerName指令
L:47
- python之反射和内置函数__str__、__repr__
一.反射 反射类中的变量 反射对象中的变量 反射模块中的变量 反射本文件中的变量 .定义:使用字符串数据类型的变量名 来获取这个变量的值 例如: name = 'xiaoming' print(nam ...
- java 11 Stream 加强
Stream 是 Java 8 中的新特性,Java 9 开始对 Stream 增加了以下 4 个新方法. 1) 增加单个参数构造方法,可为null Stream.ofNullable(null).c ...
- [HNOI2016]矿区
[HNOI2016]矿区 平面图转对偶图 方法: 1.分成正反两个单向边,每个边属于一个面 2.每个点按照极角序sort出边 3.枚举每一个边,这个边的nxt就是反边的前一个(这样找到的是面的边逆时针 ...
- 内网ntp时间同步配置
选择局域网中的一台机器作为ntp服务器,在ntp server上安装并启动ntpd客户端上要关闭ntpd,安装ntpdateCentOS7上这两个软件都是自带的,只需根据需要打开或者关闭.注意客户端机 ...
- 柳叶刀重磅出击!全外显子测序在胎儿结构异常的评估Whole-exome sequencing in the evaluation of fetal structural anomalies: a prospective cohort study
柳叶刀发表的文献解读:Whole-exome sequencing in the evaluation of fetal structural anomalies: a prospective coh ...
- DirectX11 With Windows SDK--07 添加光照与常用几何模型
前言 对于3D游戏来说,合理的光照可以让游戏显得更加真实.接下来会介绍光照的各种分量,以及常见的光照模型.除此之外,该项目还用到了多个常量缓冲区,因此还会提及HLSL的常量缓冲区打包规则以及如何设置多 ...
- Elasticsearch High Level Rest Client 发起请求的过程分析
本文讨论的是JAVA High Level Rest Client向ElasticSearch6.3.2发送请求(index操作.update.delete--)的一个详细过程的理解,主要涉及到Res ...
- [物理学与PDEs]第3章习题1 只有一个非零分量的磁场
设磁场 ${\bf H}$ 只有一个非零分量, 试证明 $$\bex ({\bf H}\cdot\n){\bf H}={\bf 0}. \eex$$ 证明: 不妨设 ${\bf H}=(0,0,H_3 ...
- Mysq登陆后执行命令提示You must SET PASSWORD before executing this statement
mysql 安装完成后,在输入命令行时,提示:You must SET PASSWORD before executing this statement 提示必须设置密码,我想不是已经设置了密码吗? ...