impala
impala
1.impala是什么:
impala是基于hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。
2.impala与hive的关系:
Impala与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面
1.hive适合长时间的批处理查询分析
2.impala适合实时交互式查询
# 在hive上进行数据转换处理,之后使用impala在hive处理后的结果集上进行快速的数据分析
3.impala简介
1.Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
2.基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
3.是CDH平台首选的PB级大数据实时查询分析引擎
4.impala优劣
优点:
1.基于内存计算,能够对PB集数据进行交互式查询分析
2.无需转换为MR,直接读取HDFS文件
3.兼容数据仓库特性,可对hive数据直接做数据分析
4.兼容hivesql
5.支持列存储
缺点:
1.内存依赖大
2.依赖hive
3.分区较多时,性能瓶颈
4.稳定性不如hive
5.impala组件
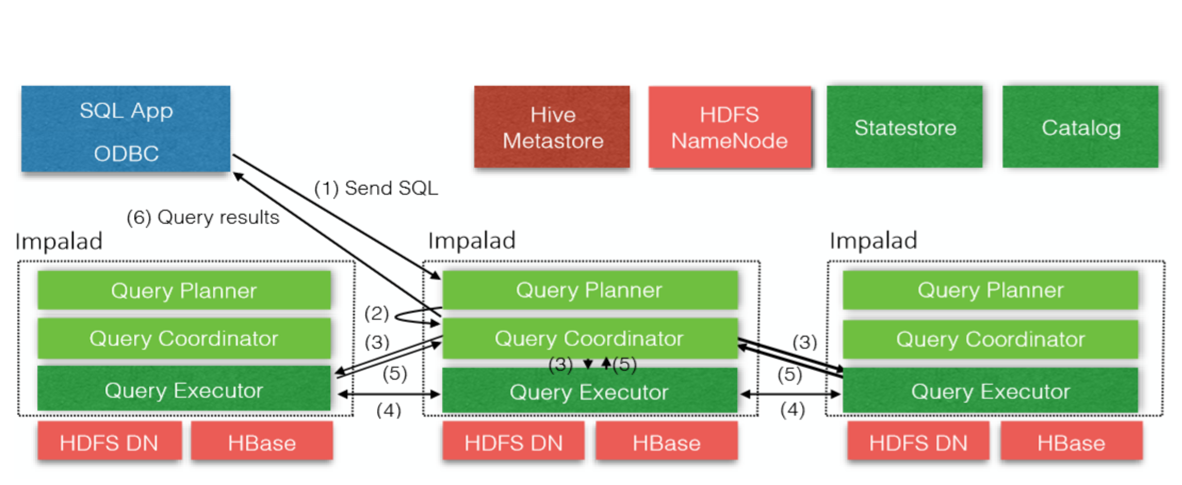
Statestore Daemon
实例*1 - statestored
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息.
负责query的调度 Catalog Daemon
实例*1 - catalogd
分发表的元数据信息到各个impalad中
接收来自statestore的所有请求 Impala Daemon
实例*N – impalad
接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
子节点上的守护进程,负责向statestore保持通信,汇报工作
6.impala shell
外部shell
impala-shell
-h 帮助
-v 版本
-V 详细输出
-queit 关闭详细输出
-p 显示执行计划
-i hostname 连接主机 (数据量较大时,可连接内存(128G)较大的主机执行)
-r 刷新所有元数据
-q query 从命令行执行,不进入impala-shell
-d default_db 指定数据库
-B 去格式化输出
--output_delimiter=character 指定分隔符
--print_header 打印列名
-f query_file 执行文件,逗号分隔
-o filename 输出到指定文件
-c 查询执行失败时继续执行
内部shell
help
connect <hostname:port>
refresh <tablename> 增量刷新元数据库
invalidate metadata 全量刷新元数据库
explain <sql> 显示查询执行计划、步骤信息
set explain_level 设置显示级别(0,1,2,3)
shell <shell> 不退出impala-shell执行Linux命令
profile (查询完成后执行) 查询最近一次查询的底层信息
7.impala 分区&存储
parquet create table ,insert ,load data ,query
text load data
avro 仅仅支持查询,在hive中通过load data加载数据
rcfile 仅仅支持查询,在hive中通过load data加载数据
sequencefile 仅仅支持查询,在hive中通过load data加载数据
添加分区方式
1、partitioned by 创建表时,添加该字段指定分区列表
createt table test (id int,name string) partitioned by (pt_d string); 2、使用alter table 进行分区的添加和删除操作
alter table test add partition (pt_d='');
alter table test drop partition (pt_d='');
alter table test drop partition (pt_d='',pt_h=''); 分区内添加数据
insert into test partition (pt_d='') values (1,'zhangsan'),(2,'lisi') 查询指定分区数据
select id,name from test where pt_d='';
8.impala sql
支持数据类型:
INT
TINYINT
SMALLINT
BIGINT
BOOLEAN
CHAR
VARCHAR
STRING
FLOAT
DOUBLE
REAL
DECIMAL
TIMESTAMP
cdh5.5版本后支持:
支持数据类型:
ARRAY
MAP
STRUCT
Complex
此外,Impala不支持HiveQL以下特性: 1.可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes
2.XML、JSON函数
3.某些聚合函数:
covar_pop, covar_samp, corr, percentile, percentile_approx, histogram_numeric, collect_set
Impala仅支持:AVG,COUNT,MAX,MIN,SUM
4.多Distinct查询
5.UDF、UDAF
6.以下语句:
ANALYZE TABLE (Impala:COMPUTE STATS)、DESCRIBE COLUMN、DESCRIBE DATABASE、EXPORT TABLE、IMPORT TABLE、SHOW TABLE EXTENDED、SHOW INDEXES、SHOW COLUMNS、
创建数据库
create database db1;
use db1; 删除数据库
use default;
drop database db1; 创建表(内部表)
默认方式创建表:
create table t_person1(
id int,
name string
) 指定存储方式:
create table t_person2(
id int,
name string
)
row format delimited
fields terminated by '\0' (impala1.3.1版本以上支持'\0' )
stored as textfile; 其他方式创建内部表
使用现有表结构:
create table tab_3 like tab_1;
指定文本表字段分隔符:
alter table tab_3 set serdeproperties ('serialization.format'=',','field.delim'=','); 插入数据
直接插入值方式:
insert into t_person values (1,hex(‘hello world’)); 从其他表插入数据:
insert (overwrite) into tab_3 select * from tab_2 ;
批量导入文件方式方式:
load data local inpath ‘/xxx/xxx’ into table tab_1; 创建表(外部表)
默认方式创建表:
create external table tab_p1(
id int,
name string
)
location '/user/xxx.txt' 指定存储方式:
create external table tab_p2 like parquet_tab
'/user/xxx/xxx/1.dat'
partition (year int , month tinyint, day tinyint)
location '/user/xxx/xxx'
stored as parquet; 视图
创建视图:
create view v1 as select count(id) as total from tab_3 ; 查询视图:
select * from v1; 查看视图定义:
describe formatted v1 注意:
1)不能向impala的视图进行插入操作
2)insert 表可以来自视图 数据文件处理
加载数据:
1、insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式加载批量数据
2、load data方式:在进行批量插入时使用这种方式比较合适
3、来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。 空值处理:
impala将“\n”表示为NULL,在结合sqoop使用是注意做相应的空字段过滤,
也可以使用以下方式进行处理:
alter table name set tblproperties ("serialization.null.format"="null")
9.impala性能优化
1、SQL优化,使用之前调用执行计划
2、选择合适的文件格式进行存储
3、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表)
4、使用合适的分区技术,根据分区粒度测算
5、使用compute stats进行表信息搜集
6、网络io的优化:
a.避免把整个数据发送到客户端
b.尽可能的做条件过滤
c.使用limit字句
d.输出文件时,避免使用美化输出
7、使用profile输出底层信息计划,在做相应环境优化
impala的更多相关文章
- 安装Impala
1.默认安装好hadoop并且能正常启动(只需hdfs即可)2.安装如下rpm包(需要root权限 注意顺序) bigtop-utils-0.7.0+cdh5.8.2+0-1.cdh5.8.2.p0. ...
- 《开源大数据分析引擎Impala实战》目录
当当网图书信息: http://product.dangdang.com/23648533.html <开源大数据分析引擎Impala实战>目录 第1章 Impala概述.安装与配置.. ...
- 运行impala tpch
1.安装git和下载tpc-h-impala脚步 [root@ip-172-31-34-31 ~]# yum install git [root@ip-172-31-34-31 ~]# git clo ...
- TPCH Benchmark with Impala
1. 生成测试数据在TPC-H的官网http://www.tpc.org/tpch/上下载dbgen工具,生成数据http://www.tpc.org/tpch/spec/tpch_2_17_0.zi ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- Hadoop 之Impala
impala 是基于hive的大数据实时分析查询引擎,直接使用Hive的元数据库metadata意味着impala元数据都存储在hive的metadstore中并且impala兼容hive的 sql解 ...
- 在脚本中刷新impala元信息
刷新impala元信息 impala-shell -q 'invalidate metadata' -i hslave1 impala-shell -q 'select count(*) from p ...
- java通过jdbc连接impala
下载所需jar包:http://www.cloudera.com/downloads/connectors/impala/jdbc/2-5-28.html 选择使用impalajdbc41版本 imp ...
随机推荐
- ant在windows及linux环境下安装
ant下载 http://ant.apache.org/ https://ant.apache.org/bindownload.cgi 历史版本 ant在windows下安装 解压到D盘 新建系统变量 ...
- golang 代码笔记
锁 互斥锁,g0获取锁,到释放锁之间,g1去获取锁失败,阻塞,g0释放锁之后g1获取锁成功,gn阻塞. package main import ( "fmt" "sync ...
- 【NOIP2013模拟】终极武器(经典分析+二分区间)
No.2. [NOIP2013模拟]终极武器 题意: 给定你一些区间,然后让你找出\(1\sim 9\)中的等价类数字. 也就是说在任何一个区间里的任何一个数,把其中后\(k\)位中的某一位换成等价类 ...
- prometheus 标签使用
标签的配置使用 考虑到要明智地使用标签,我们需要给事物重新命名.在一个集中的.复杂的监视环境中,我们有时无法控制正在监视的所有资源以及它们公开的监视数据.重新标记允许在自己的环境中控制.管理和潜在地标 ...
- Python中查看函数相关文档
1.dir查看对象属性 >>> dir(set) ['__and__', '__class__', '__contains__', '__delattr__', '__dir__', ...
- Entity Framework入门教程(12)--- EF进行批量添加/删除
EF6添加了批量添加/删除实体集合的方法,我们可以使用DbSet.AddRange()方法将实体集合添加到上下文,同时实体集合中的每一个实体的状态都标记为Added,在执行SaveChange()方法 ...
- linux 只查看目录下文件夹
只显示目录文件夹 ls -F |grep "/$" 显示 目录权限 ls -al |grep "^d" 只显示文件 ls -al |grep "^-& ...
- RT-SA-2019-003 Cisco RV320 Unauthenticated Configuration Export
Advisory: Cisco RV320 Unauthenticated Configuration Export RedTeam Pentesting discovered that the co ...
- day 15 - 1 内置函数
内置函数 作用域相关 locals() globals() #这两组开始容易搞混 print(locals()) #返回本地作用域中的所有名字 print(globals()) #返回全局作用域中的所 ...
- 《Java编程思想第四版》第 16 章 设计范式-提到观察者模式
在由Gamma,Helm 和 Johnson 编著的<Design Patterns>一书中被定义成一个“里程碑”.那本书列出了解决这个问题的 23 种不同的方法 16.1.2 范式分类 ...