selenium+java二元素定位
页面元素定位是自动化中最重要的事情, selenium Webdriver 提供了很多种元素定位的方法。 测试人员应该熟练掌握各种定位方法。 使用最简单,最稳定的定位方法。
自动化测试步骤
定位元素》操作元素》验证操作结果》记录测试结果
在自动化测试过程中, 测试程序通常的操作页面元素步骤
1. 找到Web的页面元素,并赋予到一个存储对象中 (WebElement)
2. 对存储页面元素的对象进行操作, 例如:点击链接,在输入框中输入字符等
3. 验证页面上的元素是否符合预期
定位方法
使用WebDriver对象的findElement函数定义一个Web页面元素
使用findElements函数可以定位页面的多个元素
定位的页面元素需要使用WebElement对象来存储,以便后续使用
常用的定位页面元素方法如下, 按推荐排序
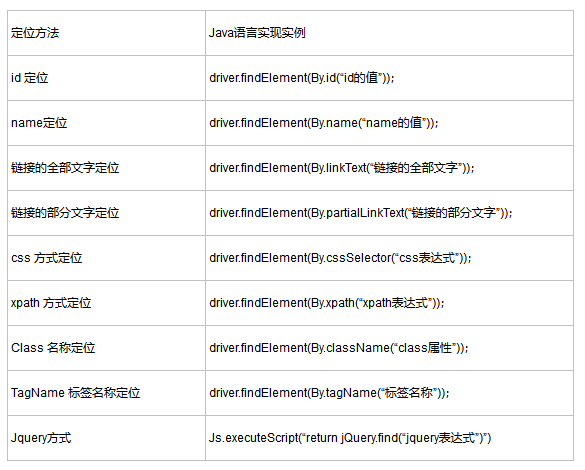
如何定位
在使用selenium webdriver进行元素定位时,通常使用findElement或findElements方法结合By类返回元素句柄来定位元素
findElement() 方法返回一个元素, 如果没有找到,会抛出一个异常 NoElementFindException()
findElements()方法返回多个元素, 如果没有找到,会返回空数组, 不会抛出异常
如何选择 定位方法
策略是, 选择简单,稳定的定位方法。
1. 当页面元素有id属性的时候, 尽量使用id来定位。 没有的话,再选择其他定位方法
2. cssSelector 执行速度快, 推荐使用
3. 定位超链接的时候,可以考虑linkText或partialLinkText: 但是要注意的是 , 文本经常发生改变, 所以不推荐用
3. xpath 功能最强悍。 当时执行速度慢,因为需要查找整个DOM, 所以尽量少用。 实在没有办法的时候,才使用xpath
通过ID查找元素: By.id()
通过页面元素的ID来查找元素是最为推荐的方式, W3C标准推荐开发人员为每一个页面元素都提供独一无二的ID属性
一旦元素被赋予了唯一的ID属性., 我们做自动化测试的时候,很容易定位到元素. 元素的ID被作为首选的识别属性, 因为是最快的识别策略.
以百度主页为例, 搜索框的HTML示例代码如下, 它的ID为kw
<input type="text" autocomplete="off" maxlength="" id="kw" name="wd" class="s_ipt">
"百度一下"搜索按钮元素的HTML示例代码如下, 它ID为su
<input type="submit" class="btn self-btn bg s_btn" id="su" value="百度一下">
在Selenium/WebDriver 中通过ID查找元素的Java示例代码如下
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver; public class Helloworld { public static void main(String[] args) throws InterruptedException {
System.setProperty("webdriver.chrome.driver",
"C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
//设置chromedriver的环境变量路径
WebDriver driver = new ChromeDriver();//创建chromedriver对象
driver.manage().window().maximize(); //使窗体最大化
driver.get("https://www.baidu.com");//获取url
WebElement element = driver.findElement(By.id("kw"));
element.sendKeys("java+selenium");
WebElement b = driver.findElement(By.id("su"));
b.submit();
Thread.sleep();//在页面停留五秒
driver.close();
driver.quit();//quit()方法关闭浏览器
}
}
通过Name查找元素:By.name()
以百度主页为例
WebElement element = driver.findElement(By.name("wd"));
element.sendKeys("java+selenium");
通过TagName查找元素: By.tagName()
通过tagName来搜索元素的时候,会返回多个元素. 因此需要使用findElements()
List<WebElement> buttons = driver.findElements(By.tagName("div"));
System.out.println("Button:" + buttons.size());
注意: 如果使用tagName, 要注意很多HTML元素的tagName是相同的,
比如单选框,复选框, 文本框,密码框.这些元素标签都是input. 此时单靠tagName无法精确获取我们想要的元素, 还需要结合type属性,才能过滤出我们要的元素
List<WebElement> a = driver.findElements(By.tagName("input"));
for(WebElement b:a){
if (b.getAttribute("type").equals("text")) {
System.out.println("input text is :" + b.getText());
}
}
通过ClassName 查找元素 By.className
以淘宝网的主页搜索为例, 其搜索框的HTML代码如下: class="search-combobox-input"
<input autocomplete="off" autofocus="true" accesskey="s" aria-label="请输入搜索文字" name="q" id="q" class="search-combobox-input"
aria-haspopup="true" aria-combobox="list" role="combobox" x-webkit-grammar="builtin:translate" tabindex="">
Java 示例代码如下
WebDriver driver = new FirefoxDriver();
driver.get("http://www.taobao.com");
Thread.sleep();
WebElement searchBox = driver.findElement(By.className("search-combobox-input")); searchBox.sendKeys("羽绒服");
searchBox.submit();
注意:使用className 来进行元素定位时, 有时会碰到一个
通过LinkText查找元素 By.linkText();
<a href="https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F&sms=5"
name="tj_login" class="lb" onclick="return false;">登录</a>
java代码
WebElement element = driver.findElement(By.linkText("登录"));
element.click();
通过PartialLinkText 查找元素 By.partialLinkText()
此方法是上一个方法的加强版, 单你只想用一些关键字匹配的时候,可以使用这个方法,通过部分超链接文字来定位元素
java 代码如下
WebElement loginLink = driver.findElement(By.partialLinkText("登"));
loginLink.click();
注意:用这种方法定位时, 可能会引起的问题是, 当你的页面中不知一个超链接包含“等”时, findElement方法只会返回第一个查找到的元素,而不会返回所有符合条件的元素
如果你想要获得所有符合条件的元素,还是只能用findElements方法
xpath定位
xpath 是XML Path的简称, 由于HTML文档本身就是一个标准的XML页面,所以我们可以使用Xpath 的用法来定位页面元素。
xpath定位缺点
xpath 这种定位方式, webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素, 这是个非常费时的操作, 如果脚本中大量使用xpath做元素定位的话, 脚本的执行速度可能会稍慢
一旦页面结构发生改变,改路径也随之失效,必须重新。 所以不推荐使用绝对路径的写法
绝对路径定位方式
/html/body/div/input[@value="查询"]
WebElement button = driver.findElement(By.xpath("/html/body/div/input[@value='查询']"));
绝对路径 以 "/" 开头, 让xpath 从文档的根节点开始解析
相对路径 以"//" 开头, 让xpath 从文档的任何元素节点开始解析
相对路径定位方式
//input[@value="查询"]
WebElement button = driver.findElement(By.xpath("//input[@value='查询']"));
使用索引号定位
WebElement button = driver.findElement(By.xpath("//input[2]"));
使用页面属性定位
定位被测试页面中的第一个图片元素
//img[@alt='div1-img1']
WebElement button = driver.findElement(By.xpath("//img[@alt='div1-img1']"));
模糊定位start-with关键字
查找图片alt属性开始位置包含'div1'关键字的元素
//img[starts-with(@alt,'div')]
模糊定位contains关键字
查找图片alt属性包含'g1'关键字的元素
//img[contains(@alt,'g1')]
text()函数 文本定位
查找所有文本为"百度搜索" 的元素
driver.findElement(By.xpath("//*[text()='百度搜索']"));
查找所有文本为“搜索” 的超链接
driver.findElement(By.xpath("//a[contains(text(),'搜索')]"));
一下罗列的都是从w3school筛选的,也是常用的一些xpath的语法和函数,牢记:
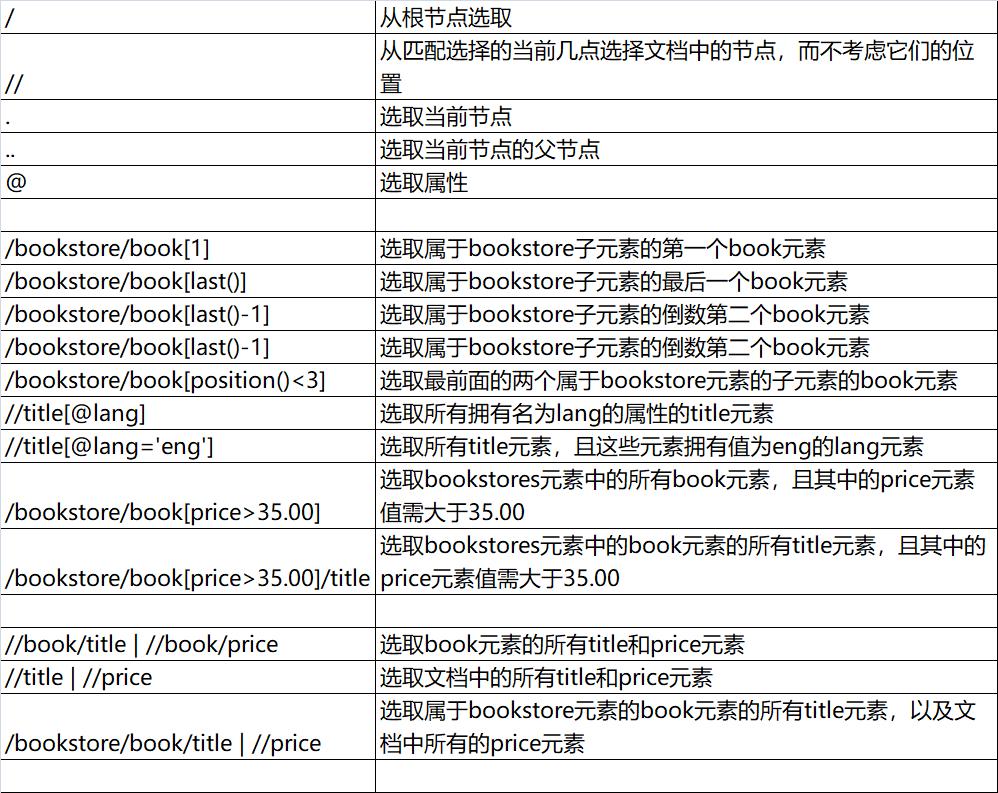
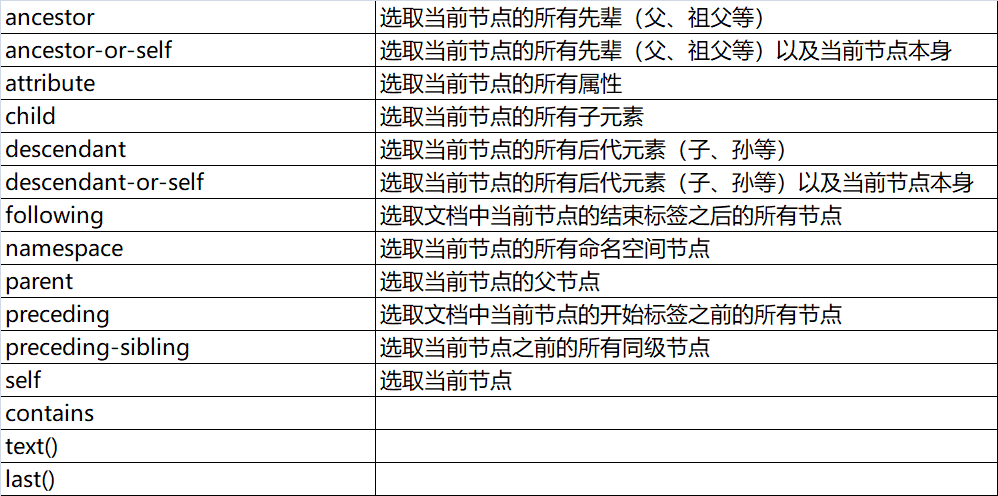
重点需牢记:
CSS定位
CSS定位相对于XPath定位的优点是:css定位更快,语法更简洁。
1、通过id属性定位,需要加上标识符“#”,如:#kw;
element = driver.findElement(By.cssSelector("#kw"));
element.sendKeys("selenium");
2、通过class属性定位,需要加上标识符 “.”,如:.s_ipt;
element = driver.findElement(By.cssSelector(".s_ipt"));
element.sendKeys("selenium");
3、通过标签属性定位,不需要任何标示符,如:input;
//这里运行会报错,因为标签“input”不是唯一的;这里主要是了解写法
element = driver.findElement(By.cssSelector("input"));
element.sendKeys("selenium");
4.以下是定位其它属性的格式;
1)CSS通过name属性定位元素;
element = driver.findElement(By.cssSelector("#su"));
element.click();
2)CSS:通过autocomplete属性定位元素;
element = driver.findElement(By.cssSelector("[autocomplete = 'off']"));
element.sendKeys("autocomplete");
3)CSS通过type属性定位元素;
element = driver.findElement(By.cssSelector("[type = 'submit']"));
element.click();
5.css页可以通过标签与属性的组合来定位元素;
1)CSS通过标签与id属性组合定位元素;
element =driver.findElement(By.cssSelector("input#kw"));
element.sendKeys("selenium");
2)CSS通过标签与class属性定位元素;
element = driver.findElement(By.cssSelector("input.s_ipt"));
element.sendKeys("selenium");
3)CSS通过标签与其它属性组合定位元素;
element = driver.findElement(By.cssSelector("input[autocomplete = 'off']"));
element.sendKeys("selenium");
6.CSS:层级关系定位
//form的id属性
element = driver.findElement(By.cssSelector("form#form>span>input"));
element.sendKeys(""); //form的class属性
element = driver.findElement(By.cssSelector("form.fm>span>input"));
element.sendKeys("");
7.CSS:索引
css也可以通过索引option:nth-child(1)来定位子元素,这点与xpath写法用很大差异;其实很好理解,直接翻译过来就是第几个小孩;
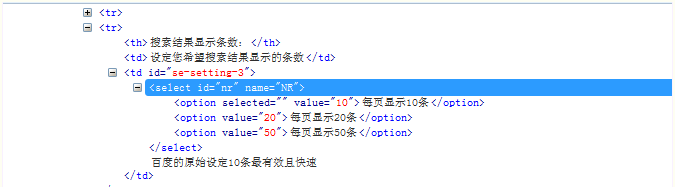
element = driver.findElement(By.cssSelector("select#ft>option:nth-child(1)"));
element.click();
element = driver.findElement(By.cssSelector("select#ft>option:nth-child(2)"));
element.click();
element = driver.findElement(By.cssSelector("select#ft>option:nth-child(3)"));
element.click();
selenium+java二元素定位的更多相关文章
- Python3-Selenium自动化测试框架(二)之selenium使用和元素定位
Selenium自动化测试框架(二)之selenium使用和元素定位 (一)selenium的简单使用 1.导包 from selenium import webdriver 2.初始化浏览器 # 驱 ...
- selenium自动化之元素定位方法
在使用selenium webdriver进行元素定位时,有8种基本元素定位方法(注意:并非只有8种,总共来说,有16种). 分别介绍如下: 1.name定位 (注意:必须确保name属性值在当前ht ...
- Java + Selenium + WebDriver八大元素定位方式
UI自动化测试的第一步就是进行元素定位,下面给大家介绍一下Selenium + WebDriver的八大元素定位方式.现在我们就以百度搜索框为例进行元素定位,如下图: 一.By.name() Java ...
- Selenium 八种元素定位方法
前言: 我们在做WEB自动化时,最根本的就是操作页面上的元素,首先我们要能找到这些元素,然后才能操作这些元素.工具或代码无法像我们测试人员一样用肉眼来分辨页面上的元素.那么我们怎么来定位他们呢? 在学 ...
- selenium常见的元素定位方法
一.获取元素 1)通过谷歌浏览器自动的工具访问百度首页,我们可以看到,页面上的元素都是由一行行的代码组成的,它们之间有层级地组织起来,每个元素之间都有不同的标签和值,我们可以通过这些不同的标签和值来找 ...
- Selenium(一):元素定位
一.Selenium 8种定位方式 baidu.html <form id="form" name="f" action="/s" c ...
- selenium+python自动化元素定位
最近学习自动化测试,终于初步学习完成,需要进行博客日志总结,加深巩固自己的知识. 元素的八种定位方式 1.id 以百度为例子 我们在python输入的元素定位语法:bs.find_element_by ...
- selenium webdriver python 元素定位
总结 定位查找时,返回查找到的第一个match的元素.如果找不到,则 raise NoSuchElementException 单个元素定位: find_element_by_idfind_e ...
- Selenium之WebDriver元素定位方法
Selenium WebDriver 只是 Python 的一个第三方框架, 和 Djangoweb 开发框架属于一个性质. webdriver 提供了八种元素定位方法,python语言中也有对应的方 ...
随机推荐
- 【Linux】-NO.160.Linux.1 -【升级Centos7】
Style:Mac Series:Java Since:2018-09-10 End:2018-09-10 Total Hours:1 Degree Of Diffculty:5 Degree Of ...
- log4cplus在Linux下编译及使用
log4cplus第一次在windows下使用的时候很快就完成了,最近在Linux下尝试使用时遇到了不少问题,主要原因是对Linux的编译连接不熟悉,以下就记录安装使用的过程,希望对需要的人有所帮助. ...
- SV-assertion
断言(assert)是一种描述性语言,通过描述的期望结果来进行仿真验证. 断言有一个更加基础的信息,我们称为属性(property),属性可以作为断言结果,功能覆盖点,形式检查和约束随机激励生成. 断 ...
- get_class __class__ get_called_class 分析记录
首先看代码: class A { use T { T::say as aTsay; } public function say() { echo 'a__class__:' . __CLASS__ . ...
- BELLMEN-FORD普通
#include <iostream> using namespace std; int m, n, u[100010], v[100010], w[100010];int check;i ...
- GridView用法
首先,gridview是封装好的,直接在设计界面使用,基本不需要写代码: 1.绑定数据源 GridView最好与LinQDatasourse配合使用,相匹配绑定数据: 2.外观控制 整体控制 自动选择 ...
- 软件综合实践Axure介绍
首先就是下载安装Axure这款软件了,在百度上搜索“”Axure rp下载“”即可,下载完成后,打开exe安装,根据步骤一步步点击下一步即可完成安装. 运行该软件时会出现类似于填写激活码的东西,这时依 ...
- ARM Mcp2515添加驱动
Mcp2515添加驱动 2012-01-10 21:39:32 上图1: 上图2: 上图3: 之前完成了spi接口驱动,所以mcp2515也是通过spi来读写数据的.就是多加一个中断脚. 另外在2 ...
- 基于ROS完成寻迹运动
安装opencv功能包: $ sudo apt-get install ros-indigo-version-opencv libopencv-dev python-opencv 检测指示线: #! ...
- Python爬虫与一汽项目【一】爬取中海油,邮政,国家电网问题总结
项目介绍 中国海洋石油是爬取的第一个企业,之后依次爬取了,国家电网,中国邮政,这三家公司的源码并没有多大难度, 采购信息地址: 国家电网电子商务平台 http://ecp.sgcc.com.cn/pr ...