vs2015编译caffe
有些时候,需要在python3的环境下import caffe,需要用vs2015在python3的环境下,编译pycaffe。
microsoft的windows版本的caffe,依赖的库NugetPackages,是基于vs2013,python2.7编译的,编译的pycaffe在python3的环境下不能用。
用vs2015编译caffe,网上有两种方法,
一,编译用cmake编译BVLC版本的caffe,看起来比较复杂,没有尝试。
二,编译happynear(峰神)版本的caffe,第三方库,有网友已经编译好了。
本文采用的第二种思路。
参考博客:https://blog.csdn.net/xingchenbingbuyu/article/details/72765612
用vs2015在happynear版本的caffe上编译。
下载caffe源码,happynear版本的caffe,王峰大神修改后的caffe源码。
https://github.com/happynear/caffe-windows
该网页中,峰神分享了第三方库,其中有一些库,是基于python2.7编译的。
有网友分享了一份基于python3编译的第三方库,
https://github.com/happynear/caffe-windows/issues/262
该第三方库的链接:
https://pan.baidu.com/s/1o_qGgZQ0M5Z06TuEQxkF2g icsq
将这些库复制到caffe_root/windows/thirdparty中,
我的电脑上没有gpu,所以编译的是cpu版本的caffe
修改CommonSettings.props这个配置文件,

编译cpu模式的时候,

将这一行去掉,要不然会报错,找不到cufft.lib的文件
用vs2015打开这个caffe解决方案,
编译libcaffe,caffe,基本没有啥问题。主要的问题出现在编译pycaffe上。
首先需要配置一下,python的环境
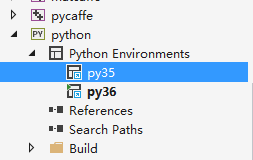
开始的时候,我用python3.5的环境编译的pycaffe,报错找不到python3.6.lib。
以为是python的环境没有配置,导致找不到库文件。重新配置python路径,编译了好几次,都在编译pycaffe的时候,失败,找不到python36.lib。
猜测,可能是下载的第三方库,是基于python3.6编译的。
在conda配置了一个python3.6的环境,py36
Prefix path: D:\Anaconda3\envs\py36\
Interpreter path: D:\Anaconda3\envs\py36\python.exe
Windowed interpreter: D:\Anaconda3\envs\py36\pythonw.exe
Library path: D:\Anaconda3\Lib
Language version: 3.5 这个选项中最高的就是3.5,没有3.6,就选了个3.5,貌似不影响最后的编译。
依次编译libcaffe,caffe,pycaffe,编译成功。
在python中import caffe
将caffe_root\Build\x64\Release\pycaffe路径下的caffe文件夹拷贝到py36/Lib/site-packages中。
即可在python3.6的环境下import caffe
不需要将..\caffe_root\Build\x64\Release 的路径添加到环境变量中,也可import caffe
因为生成的pycaffe/caffe中包含了一些dll文件。
vs2015编译caffe的更多相关文章
- win10+vs2015编译caffe的cpu debug版本、部署matcaffe
一.编译caffe 1.安装python-3.5.2-amd64.exe https://www.python.org/ftp/python/3.5.2/python-3.5.2-amd64.exe ...
- 实践详细篇-Windows下使用VS2015编译安装Caffe环境(CPU ONLY)
学习深度学习背景 最近在做一款抢票软件,由于12306经常检测账号状态,抢票抢着抢着就需要重新登录了,然后登录是需要验证码的.所以我最开始是想到了使用java基于感知哈希算法pHash做相似度匹配识别 ...
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- caffe搭建--caffe- win10 vs2015 编译(支持GPU)--注意在cmake的时候需要根据情况仔细修改配置
--http://blog.csdn.net/longji/article/details/60964998 注意: 在cmake的时候需要根据情况仔细修改配置,比如,如果gpu的能力不足3.0的话, ...
- 使用vs2015编译、部署ssd-caffe(weiliu89版,CPU模式)
前因项目所需,须训练一个快速模型以实现目标物体的实时检测.历经多次实践,发现MobileNetSSD网络符合要求,故在本人工作PC上部署weiliu89版本的ssd-caffe以期用之训练项目要求之模 ...
- VS2015编译boost1.62
VS2015编译boost1.62 Boost库是一个可移植.提供源代码的C++库,作为标准库的后备,是C++标准化进程的开发引擎之一. Boost库由C++标准委员会库工作组成员发起,其中有些内容有 ...
- VS2015编译Qt5.7.0生成支持XP的静态库(很不错)
一.编译工具 1.VS2015 编译Qt5.7.0的所需VS版本:Visual Studio 2013 (Update1)或Visual Studio 2015 (Update2).因为Update补 ...
- ubuntu14.04下安装cudnn5.1.3,opencv3.0,编译caffe及配置matlab和python接口过程记录
已有条件: ubuntu14.04+cuda7.5+anaconda2(即python2.7)+matlabR2014a 上述已经装好了,开始搭建caffe环境. 1. 装cudnn5.1.3,参照: ...
- ubuntu下编译caffe
Ubuntu下编译caffe 纯粹是个人编译的记录.不用CUDA(笔记本是amd卡,万恶的nvidia):不手动编译依赖包(apt-get是用来干啥的?用来直接装二进制包,以及自动解决依赖项的) ca ...
随机推荐
- django js引入失效问题
今天将项目中html文件下的自定义scrept代码单独独立,结果js引入无效,没有任何时间效果,在浏览器查看引入文件也正常. 后来发现自己引入的位置不对,js的引入文件应该放在body体内,而我把他们 ...
- java学习之匿名内部类
/*匿名内部类 * * 一般用于抽象类和接口 * 因为他们不能实例化对象所以可以通过匿名内部类来帮助他们实例化 * 下面demo是抽象类的例子 * * */ abstract class Cat{ a ...
- Kendo DropDownListFor值传不回去的小坑
做项目时,在KendoWindow弹框里面写了个表单提交,不小心把AreaId 下拉框设置了Name为“OrderAreaId”.在后台接收不到AreaId的参数.后来才发现是Name的设置强行把A ...
- web攻击之xss(一)
1,xss简介 跨站脚本攻击(Cross Site Scripting),为了不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS.恶意攻击 ...
- OpenStack-Neutron-Fwaas-代码【一】
Kilo的代码中对Fwaas做了优化,可以将规则应用到单个路由上 但是juno里面还是应用到租户的所有路由上的,因此对juno的代码做了修改 1. 介绍 在FWaaS中,一个租户可以创建多个防火墙,而 ...
- 【SparkStreaming学习之三】 SparkStreaming和kafka整合
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- 韩顺平Linux学习笔记
第 一 章 Linux开山篇 1.1 Linux课程的内容介绍 1.2Linux的学习方向 1.2.1. Linux运维工程师:主要做大公司中的电脑系统维护,保证服务器的正常运行,如服务器的优化 ...
- PyTorch in Action: A Step by Step Tutorial
PyTorch in Action: A Step by Step Tutorial PyTorch in Action: A Step by Step Tutorial Installation ...
- 《CSS世界》读书笔记(十二)
<!-- <CSS世界>张鑫旭著 --> 正确看待 CSS 世界里的 margin 合并 什么是 margin 合并 块元素的上外边距(margin-top)与下外边距(mar ...
- Bootstrap的$(...).modal is not a function错误
使用模态对话框的时候报错了,$(...).modal is not a function 有点蒙,modal是boostrap的函数,而我已经导入了 然后在pycharm的terminal中看到了这一 ...