Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。要理解HDFS的内部工作原理,首先要理解什么是分布式文件系统。
1 、分布式文件系统
多台计算机联网协同工作(有时也称为一个集群)就像单台系统一样解决某种问题,这样的系统我们称之为分布式系统。
分布式文件系统是分布式系统的一个子集,它们解决的问题就是数据存储。
换句话说,它们是横跨在多台计算机上的存储系统。存储在分布式文件系统上的数据自动分布在不同的节点上。
分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理来自网络和其它地方的超大规模数据提供所需的扩展能力。
2 、分离元数据和数据:NameNode和DataNode
存储到文件系统中的每个文件都有相关联的元数据。元数据包括了文件名、i 节点(inode )数、数据块位置等,而数据则是文件的实际内容。
在传统的文件系统里,因为文件系统不会跨越多台机器,元数据和数据存储在同一台机器上。
为了构建一个分布式文件系统,让客户端在这种系统中使用简单,并且不需要知道其他客户端的活动,那么元数据需要在客户端以外维护。HDFS的设计理念是拿出一台或多台机器来保存元数据,并让剩下的机器来保存文件的内容。
NameNode和DataNode是HDFS的两个主要组件。其中,元数据存储在NameNode上,而数据存储在DataNode的集群上。NameNode不仅要管理存储在HDFS上内容的元数据,而且要记录一些事情,比如哪些节点是集群的一部分,某个文件有几份副本等。它还要决定当集群的节点宕机或者数据副本丢失的时候系统需要做什么。
存储在HDFS上的每份数据片有多份副本(replica )保存在不同的服务器上。
在本质上,NameNode是HDFS的Master(主服务器),DataNode是Slave (从服务器)。
3 、HDFS写过程
NameNode负责管理存储在HDFS上所有文件的元数据,它会确认客户端的请求,并记录下文件的名字和存储这个文件的DataNode集合。它把该信息存储在内存中的文件分配表里。
例如,客户端发送一个请求给NameNode,说它要将“zhou.log”文件写入到HDFS. 那么,其执行流程如图1 所示。具体为:
- 第一步:客户端发消息给NameNode,说要将“zhou.log”文件写入。(如图1 中的①)
- 第二步:NameNode发消息给客户端,叫客户端写到DataNode A、B 和D ,并直接联系DataNode B. (如图1 中的②)
- 第三步:客户端发消息给DataNode B,叫它保存一份“zhou.log”文件,并且发送一份副本给DataNode A和DataNode D. (如图1 中的③)
- 第四步:DataNode B发消息给DataNode A,叫它保存一份“zhou.log”文件,并且发送一份副本给DataNode D. (如图1 中的④)
- 第五步:DataNode A发消息给DataNode D,叫它保存一份“zhou.log”文件。(如图1 中的⑤)
- 第六步:DataNode D发确认消息给DataNode A. (如图1 中的⑤)
- 第七步:DataNode A发确认消息给DataNode B. (如图1 中的④)
- 第八步:DataNode B发确认消息给客户端,表示写入完成。(如图1 中的⑥)
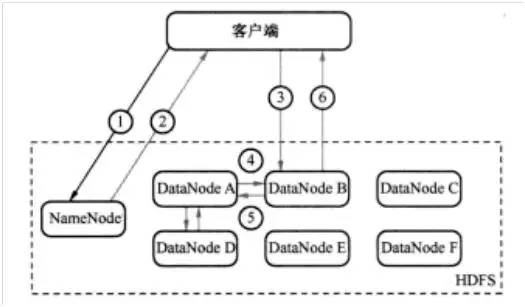
Hadoop图1 HDFS写过程示意图
在分布式文件系统的设计中,挑战之一是如何确保数据的一致性。对于HDFS来说,直到所有要保存数据的DataNodes 确认它们都有文件的副本时,数据才被认为写入完成。因此,数据一致性是在写的阶段完成的。一个客户端无论选择从哪个DataNode读取,都将得到相同的数据。
4 、HDFS读过程
为了理解读的过程,可以认为一个文件是由存储在DataNode上的数据块组成的。客户端查看之前写入的内容的执行流程如图2 所示,具体步骤为:
- 第一步:客户端询问NameNode它应该从哪里读取文件。(如图2 中的①)
- 第二步:NameNode发送数据块的信息给客户端。(数据块信息包含了保存着文件副本的DataNode的IP地址,以及DataNode在本地硬盘查找数据块所需要的数据块ID. )(如图2 中的②)
- 第三步:客户端检查数据块信息,联系相关的DataNode,请求数据块。(如图2 中的③)
- 第四步:DataNode返回文件内容给客户端,然后关闭连接,完成读操作。
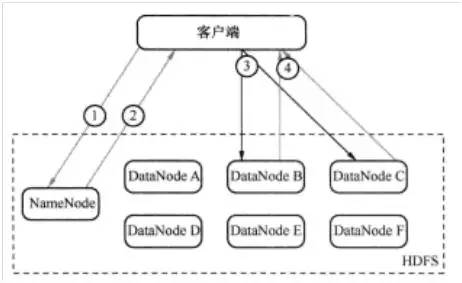
图2 HDFS读过程示意图
客户端并行从不同的DataNode中获取一个文件的数据块,然后联结这些数据块,拼成完整的文件。
5 、通过副本快速恢复硬件故障
当一切运行正常时,DataNode会周期性发送心跳信息给NameNode(默认是每3 秒钟一次)。如果NameNode在预定的时间内没有收到心跳信息(默认是10分钟),它会认为DataNode出问题了,把它从集群中移除,并且启动一个进程去恢复数据。
DataNode可能因为多种原因脱离集群,如硬件故障、主板故障、电源老化和网络故障等。
对于HDFS来说,丢失一个DataNode意味着丢失了存储在它的硬盘上的数据块的副本。假如在任意时间总有超过一个副本存在(默认3 个),故障将不会导致数据丢失。当一个硬盘故障时,HDFS会检测到存储在该硬盘的数据块的副本数量低于要求,然后主动创建需要的副本,以达到满副本数状态。
6 、跨多个DataNode切分文件
在HDFS里,文件被切分成数据块,通常每个数据块64MB~128MB,然后每个数据块被写入文件系统。同一个文件的不同数据块不一定保存在相同的DataNode上。
这样做的好处是,当对这些文件执行运算时,能够通过并行方式读取和处理文件的不同部分。
当客户端准备写文件到HDFS并询问NameNode应该把文件写到哪里时,NameNode会告诉客户端,那些可以写入数据块的DataNode. 写完一批数据块后,客户端会回到NameNode获取新的DataNode列表,把下一批数据块写到新列表中的DataNode上。
原文链接:http://bigdata.idcquan.com/dsjjs/80517.shtml
Hadoop分布式文件系统HDFS的工作原理的更多相关文章
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Hadoop分布式文件系统--HDFS结构分析
转自:http://blog.csdn.net/androidlushangderen/article/details/47377543 HDFS系列:http://blog.csdn.net/And ...
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- 对Hadoop分布式文件系统HDFS的操作实践
原文地址:https://dblab.xmu.edu.cn/blog/290-2/ Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核 ...
- Hadoop 分布式文件系统 - HDFS
当数据集超过一个单独的物理计算机的存储能力时,便有必要将它分不到多个独立的计算机上.管理着跨计算机网络存储的文件系统称为分布式文件系统.Hadoop 的分布式文件系统称为 HDFS,它 是为 以流式数 ...
- Hadoop分布式文件系统HDFS
HDFS的探究: HDFS HDFS是 Hadoop Distribute File System的缩写,是谷歌GFS分布式文件系统的开源实现,Apache Hadoop的一个子项目,HDFS基于流数 ...
- 分布式文件系统之MogileFS工作原理及实现过程
MogileFS是一套高效的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上.MogileFS由3个部分组成: 第1个部分:是server端,包 ...
- CM记录-Hadoop 分布式文件系统HDFS(登录、配置、监控)
1.登录(浏览器输入ip地址:7180,登录用户名和登录密码即可) 2.CM主界面(各个组件,监控图表,绿色代表运行正常.黄色代表运行不良,需要关注根据实际情况调整,红色代表故障,需要排查问题) 3. ...
随机推荐
- UGUI背包系统
在Unity3d中,UGUI提供了Scroll Rect.Grid Layout Group.Mask这三个组件,下面就给大家介绍下如何用这个三个组件来实现滚动视图. 首先放置好背包的背景图 在矩形线 ...
- 我与C++的初识
Q1:学习<C++语言程序设计>课程之前,你知道什么是编程吗?谈谈上这门课之前你对编程的理解,以及你对自己编程能力的评估. A1:在学习<C++语言程序设计>课程之前,我其实对 ...
- StrictRedis
StrictRedis对象⽅法 通过init创建对象,指定参数host.port与指定的服务器和端⼝连接,host默认为localhost,port默认为6379,db默认为0 sr = Strict ...
- 不支持iframe框架?出来吧pdf
<iframe src='http://km.shengaitcm.com/ADC/_layouts/15/WopiFrame.aspx?sourcedoc=%2FADC%2FDocLib6%2 ...
- elasticsearch数据备份与sshfs建立共享文件
1.背景: 最近公司为了适应业务的发展,利用elasticsearch搜索引擎搭建了两个节点.为了防止数据丢失的特殊情况,需要定时做数据备份,而由于elasticsearch为两个节点分别在不同的服务 ...
- LR参数化取值规则总结
我想使用参数化输入设置10个并发用户循环1000次,第一个用户使用参数列表中的前1000个参数(第依次循环使用第一个参数.第二次循环使用第二个参数,依次类推).第二个用户使用参数列表中的2001-30 ...
- 自己动手写java锁
1.LockSupport的park和unpark方法的基本使用,以及对线程中断的响应性 LockSupport是JDK中比较底层的类,用来创建锁和其他同步工具类的基本线程阻塞原语.java锁和同步器 ...
- Description Resource Path Location Type Java compiler level does not match the version of(编译问题)
project 编译问题,需要三处的jdk版本要保持一致,才能编译通过. 1.在项目上右键properties->project Facets->修改右侧的version 保持一致 2. ...
- 中文编码错误,Error output could not be translated from the native locale to UTF-8.
假如使用http访问仓库,用户配置的pre-commit钩子里面如果有中文,可能会出现"Error output could not be translated from the nativ ...
- PostgreSql之在group by查询下拼接列字符串
首先创建group_concat聚集函数: CREATE AGGREGATE group_concat(anyelement) ( sfunc = array_append, -- 每行的操作函数,将 ...