xv6课本翻译之——第0章 操作系统接口
Chapter 0
第0章
Operating system interfaces
操作系统接口
The job of an operating system is to share a computer among multiple programs and to provide a more useful set of services than the hardware alone supports. The operating system manages and abstracts the low-level hardware, so that, for example, a word processor need not concern itself with which type of disk hardware is being used. It also multiplexes the hardware, allowing many programs to share the computer and run (or appear to run) at the same time. Finally, operating systems provide controlled ways for programs to interact, so that they can share data or work together.
操作系统的工作就是在多个程序这间共享计算机并且提供一些比起硬件单独提供的更有用的服务。操作系统管理并抽象底层的硬件,这样,例如,一个字处理程序不必关心使用了哪种类的磁盘。它也复用硬件,允许更多 多的程序去共享计算机并且在同一时间运行(或者表现出来是这样运行的)。最后,操作系统为程序之间的交互提供一种可控制的方法。这样它们可以共享数据或一起工作。
An operating system provides services to user programs through an interface. Designing a good interface turns out to be difficult. On the one hand, we would like the interface to be simple and narrow because that makes it easier to get the implementation right. On the other hand, we may be tempted to offer many sophisticated features to applications. The trick in resolving this tension is to design interfaces that rely on a few mechanisms that can be combined to provide much generality.
操作系统通过接口为用户程序提供服务。设计一个好的接口是很难的。另一面,我们倾向接口应该简单并且有限,因为这会使权限实现更容易。而另一方面来说,我们可能企图向程序去提供很多复杂特性。解决这种矛盾的办法是设计接口时依赖较少机制而不是将简单的组合起来。
This book uses a single operating system as a concrete example to illustrate operating system concepts. That operating system, xv6, provides the basic interfaces introduced by Ken Thompson and Dennis Ritchie’s Unix operating system, as well as mimicking Unix’s internal design. Unix provides a narrow interface whose mechanisms combine well, offering a surprising degree of generality. This interface has been so successful that modern operating systems—BSD, Linux, Mac OS X, Solaris, and even, to a lesser extent, Microsoft Windows—have Unix-like interfaces. Understanding xv6 is a good start toward understanding any of these systems and many others.
这本书使用一个单机操作系统作为具体例子来解释操作系统的概念。这个操作系统,xv6,提供基本的接口,这些接口来自由Ken Thompson和 Dennis Ritchie编写的Unix 操作系统,同时也模仿Unix的内部设计。Unix提供了有限的接口,这些接口有很好的组合机制,具有令人惊喜的一般度。这些接口相当成功,以至于现代操作系统——BSD,Linux,Mac OS X,Solaris,even等都有限地扩展它们,微软的windows——有类Unix接口理解xv6对于理解这些操作或其他系统都是一个很好的开始。
As shown in Figure 0-1, xv6 takes the traditional form of a kernel, a special program that provides services to running programs. Each running program, called a process, has memory containing instructions, data, and a stack. The instructions implement the program’s computation. The data are the variables on which the computation acts. The stack organizes the program’s procedure calls.
正如图0-1所示,xv6使用了传统的内核形式,一个特定的程序为运行的程序提供服务。每个运行的程序,被叫做进程,拥有包含指令、数据和栈的内存。指令实现程序的计算。数据在计算过程中是可变的。栈用来规划程序运行时的过程调用。
When a process needs to invoke a kernel service, it invokes a procedure call in the operating system interface. Such a procedure is called a system call. The system call enters the kernel; the kernel performs the service and returns. Thus a process alternates between executing in user space and kernel space.
当一个进程需要调用内核服务时,它激活一个操作系统接口提供的一个过程。这样的一个过程被叫做系统调用。系统调用进入内核。内核完成服务并返回。这样一个进程就完成了内核空间和用户内容的转换。
The kernel uses the CPU’s hardware protection mechanisms to ensure that each process executing in user space can access only its own memory. The kernel executes with the hardware privileges required to implement these protections; user programs execute without those privileges. When a user program invokes a system call, the hardware raises the privilege level and starts executing a pre-arranged function in the kernel.
内核使用CPU的硬件保护机制来确保每个运行在用户空间的进程仅能访问它自己的内存。内核在硬件特权上运行需要实现这些保护;用户程序在执行时没有这些特权。当一个用户程序激活一个系统调用时,硬件提升特权级别并开始执行事先安排好的内核功能。
The collection of system calls that a kernel provides is the interface that user programs see. The xv6 kernel provides a subset of the services and system calls that Unix kernels traditionally offer. Figure 0-2 lists all xv6’s system calls.
内核提供的系统调用集合是用户程序可以看到的接口。Xv6内核提供传统Unix内核提供的服务和系统调用的一个子集。图0-2列出了所以xv6提供的系统调用。
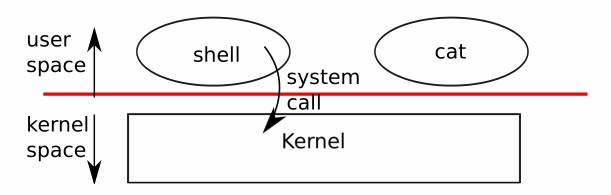
Figure 0-1. A kernel and two user processes.
图0-1:内核和两个用户进程
The rest of this chapter outlines xv6’s services—processes, memory, file descriptors, pipes, and file system—and illustrates them with code snippets and discussions of how the shell uses them. The shell’s use of system calls illustrates how carefully they have been designed.
本章的剩余部分勾勒出xv6的服务——进程、内存、文件描述符、管道以及文件系统——并且使用代码片段解释它们的实现并讨论了shell如何使用它们。Shell使用系统调用解释了为何设计它们时要小心。
The shell is an ordinary program that reads commands from the user and executes them, and is the primary user interface to traditional Unix-like systems. The fact that the shell is a user program, not part of the kernel, illustrates the power of the system call interface: there is nothing special about the shell. It also means that the shell is easy to replace; as a result, modern Unix systems have a variety of shells to choose from, each with its own user interface and scripting features. The xv6 shell is a simple implementation of the essence of the Unix Bourne shell. Its implementation can be found at line (8350) .
Shell是一个普通程序,它从用户读取命令并执行它们,对于传统的类Unix系统来说是主要的用户接口。事实上shell就是一个用户程序,不是内核的一部分,解释系统调用接口的威力:对于shell来说没有特殊的地方。这也意味着shell是很容易被替换的;现代unix系统有很多shell可以选择,每一个都有自己的用户接口和实现特性。Xv6的shell是Unix Bourne shell的一个简单实现。它的具体实现代码可以在以下代码处找到(8350)。
Processes and memory
进程和内存
An xv6 process consists of user-space memory (instructions, data, and stack) and per-process state private to the kernel. Xv6 can time-share processes: it transparently switches the available CPUs among the set of processes waiting to execute. When a process is not executing, xv6 saves its CPU registers, restoring them when it next runs the process. The kernel associates a process identifier, or pid, with each process.
一个xv6进程由用户内存空间和对内核可见的进程状态组成。Xv6可以在多个进程间共享时间:它在一系列等待执行的进程间透明地切换可用的CPU。当一个进程不运行时,xv6保存它的CPU寄存器,当它下次运行时再恢复它们。内核使用进程标识关联每一个进程,或者叫pid。
A process may create a new process using the fork system call. Fork creates a new process, called the child process, with exactly the same memory contents as the calling process, called the parent process. Fork returns in both the parent and the child. In the parent, fork returns the child’s pid; in the child, it returns zero. For example, consider the following program fragment:
一个进程可以使用fork的系统调用来创建一个新的进程。Fork创建一个新的进程,叫子进程,使用和调用进程完全相同的内存内容,调用进程叫做父进程。Fork在父进程和子进程中均返回。在父进程中,返回子进程的pid(进程标识),在子进程中它返回0。例如,考虑以下的程序片段:
int pid = fork();
if(pid > 0){
printf("parent: child=%d\n", pid);
pid = wait();
printf("child %d is done\n", pid);
} else if(pid == 0){
printf("child: exiting\n");
exit();
} else {
printf("fork error\n");
}
The exit system call causes the calling process to stop executing and to release resources such as memory and open files. The wait system call returns the pid of an exited child of the current process; if none of the caller’s children has exited, wait waits for one to do so. In the example, the output lines
Exit系统调用导致调用的进程退出执行,并且释放如内存和打开的文件等资源。Wait系统调用返回当前进程中结束的子进程的pid;如果调用者的子进程没有结束,wait会等待其中一个退出。在例子中,输出如下
parent: child=1234
child: exiting
might come out in either order, depending on whether the parent or child gets to its printf call first. After the child exits the parent’s wait returns, causing the parent to print
可能输出会有不同顺序,这也依赖于父进程或子进程哪个首先获得printf系统调用。在子进程结束后,父进程的wait调用会返回,导致父进程打印
parent: child 1234 is done
Note that the parent and child were executing with different memory and different registers: changing a variable in one does not affect the other.
注意,父进程和子进程在不同的内存中执行,并且寄存器内容也不同:改变其中某个进程的变量不影响另一个。
System call Description
系统调用描述
|
fork() |
Create process |
|
exit() |
Terminate current process |
|
wait() |
Wait for a child process to exit |
|
kill(pid) |
Terminate process pid |
|
getpid() |
Return current process’s id |
|
sleep(n) |
Sleep for n seconds |
|
exec(filename, *argv) |
Load a file and execute it |
|
sbrk(n) |
Grow process’s memory by n bytes |
|
open(filename, flags) |
Open a file; flags indicate read/write |
|
read(fd, buf, n) |
Read n byes from an open file into buf |
|
write(fd, buf, n) |
Write n bytes to an open file |
|
close(fd) |
Release open file fd |
|
dup(fd) |
Duplicate fd |
|
pipe(p) |
Create a pipe and return fd’s in p |
|
chdir(dirname) |
Change the current directory |
|
mkdir(dirname) |
Create a new directory |
|
mknod(name, major, minor) |
Create a device file |
|
fstat(fd) |
Return info about an open file |
|
link(f1, f2) |
Create another name (f2) for the file f1 |
|
unlink(filename) |
Remove a file |
Figure 0-2. Xv6 system calls
图0-2:xv6 的系统调用
The exec system call replaces the calling process’s memory with a new memory image loaded from a file stored in the file system. The file must have a particular format, which specifies which part of the file holds instructions, which part is data, at which instruction to start, etc. xv6 uses the ELF format, which Chapter 2 discusses in more detail. When exec succeeds, it does not return to the calling program; instead, the instructions loaded from the file start executing at the entry point declared in the ELF header. Exec takes two arguments: the name of the file containing the executable and an array of string arguments. For example:
Exec系统调用使用从文件中加载的内存映像来替换调用进程的内存。这个文件必须具有特别的格式,指定文件的哪部分包含指令,哪部分是数据,从哪个指令开始,等等。Xv6使用ELF格式,第二章会有更细节的讨论。当exec调用成功,它不返回到调用程序;相反,从文件中加载的指令会在ELF并没有中声明的进入点处开始执行。Exec需要两个参数:包含可执行指令的文件名称和开始参数的一个数组。例如:
char *argv[3];
argv[0] = "echo";
argv[1] = "hello";
argv[2] = 0;
exec("/bin/echo", argv);
printf("exec error\n");
This fragment replaces the calling program with an instance of the program /bin/echo running with the argument list echo hello. Most programs ignore the first argument, which is conventionally the name of the program.
这个代码片段中用一个带有echo hello参数列表的程序/bin/echo来代替调用程序。大部分程序会忽略第一个参数,因为它们通常都是程序的名称。
The xv6 shell uses the above calls to run programs on behalf of users. The main structure of the shell is simple; see main (8501) . The main loop reads the input on the command line using getcmd. Then it calls fork, which creates a copy of the shell process. The parent shell calls wait, while the child process runs the command. For example, if the user had typed ‘‘echo hello’’ at the prompt, runcmd would have been called with ‘‘echo hello’’ as the argument. runcmd (8406) runs the actual command. For ‘‘echo hello’’, it would call exec (8426) . If exec succeeds then the child will execute instructions from echo instead of runcmd. At some point echo will call exit, which will cause the parent to return from wait in main (8501) . You might wonder why fork and exec are not combined in a single call; we will see later that separate calls for creating a process and loading a program is a clever design.
Xv6的shell使用上面的调用来运行代表用户的程序。Shell的主要架构是很简单的;见main(8501)。一个主循环使用getcmd通过命令行来读取输入的命令。然后它会调用fork来创建一个shell进程的副本。当子进程运行命令时,父shell调用wait。例如,如果用户输入“echo hello”,runcmd会被调用并将“echo hello”作为参数。Runcmd(8406)运行实际的命令。对于“echo hello”来说,它会调用exec(8426)。如果exec成功则子进程会执行echo的指令来代替runcmd。在某个点上,echo会调用exit,这会导致父进程从wait返回到main(8501)中。你可能想知道为什么fork和exec不被组合到一个单独的调用中;在后面我们会看到对于创建一个进程并调用一个程序独立的调用是聪明的设计。
Xv6 allocates most user-space memory implicitly: fork allocates the memory required for the child’s copy of the parent’s memory, and exec allocates enough memory to hold the executable file. A process that needs more memory at run-time (perhaps for malloc) can call sbrk(n) to grow its data memory by n bytes; sbrk returns the location of the new memory.
Xv6隐含地分配大部分用户空间内存:fork定位内存需要子进程拷贝父进程的内存,exec分配足够的内存去装载可执行文件。如果一个进程在运行时需要更多的内存(可能使用malloc),可以调用sbrk(n)来以字节为单位扩展它的数据内存;sbrk返回新的内存位置。
Xv6 does not provide a notion of users or of protecting one user from another; in Unix terms, all xv6 processes run as root.
Xv6不提供用户概念,也没有一个用户到另一个用户之间的保护;在unix概念中,所有的xv6进程都运行在root级别。
I/O and File descriptors
I/O和文件描述符
A file descriptor is a small integer representing a kernel-managed object that a process may read from or write to. A process may obtain a file descriptor by opening a file, directory, or device, or by creating a pipe, or by duplicating an existing descriptor. For simplicity we’ll often refer to the object a file descriptor refers to as a ‘‘file’’; the file descriptor interface abstracts away the differences between files, pipes, and devices, making them all look like streams of bytes.
文件描述符是一个小的整数代表一个内核管理对象,进程可以使用它来读取或写入文件内容。进程通过打开一个文件、目录、设备、创建一个管道、或者复制一个已存在的描述符来获得一个新的描述符。为简单起见,我们经常使用“file”来引用一个文件描述符对象;文件描述符的抽象使得不同文件、管道和设备之间看来起都象一个字节流。
Internally, the xv6 kernel uses the file descriptor as an index into a per-process table, so that every process has a private space of file descriptors starting at zero. By convention, a process reads from file descriptor 0 (standard input), writes output to file descriptor 1 (standard output), and writes error messages to file descriptor 2 (standard error). As we will see, the shell exploits the convention to implement I/O redirection and pipelines. The shell ensures that it always has three file descriptors open (8507) , which are by default file descriptors for the console.
在内部,xv6内核把文件描述符作为进程表中的一个索引,以至于每个进程都拥有独立的文件描述符空间,且索引都从0开始。按照惯例,进程从文件描述符0(标准输入)读取内容,向文件描述符1(标准输出)写入内容,并且向文件描述符2(标准错误输出)输出错误信息。就象我们看到的一样,shell利用这个惯例来实现I/O重定向和管道输出。Shell确保它总有三个文件描述符被打开(8507),这些都是控制台(console)的默认描述符。
The read and write system calls read bytes from and write bytes to open files named by file descriptors. The call read(fd, buf, n) reads at most n bytes from the file descriptor fd, copies them into buf, and returns the number of bytes read. Each file descriptor that refers to a file has an offset associated with it. Read reads data from the current file offset and then advances that offset by the number of bytes read: a subsequent read will return the bytes following the ones returned by the first read. When there are no more bytes to read, read returns zero to signal the end of the file.
读取和写入的系统调用通过描述符来向打开的文件读取或写入字节。调用read(fd, buf, n)从描述符fd所代表的文件中读取至少n个字节,拷贝它们到指定的buf中,然后返回一个记取的具体字节数量。每一个引用文件的描述符都有一个读写偏移时与之相联系。Read从当前文件偏移处读取数据,并使用读取到的字节数量来增加偏移量:下一次读取会从上一次读取的位置开始。当没有数据可读取时,read返回0来表示文件的结尾。
The call write(fd, buf, n) writes n bytes from buf to the file descriptor fd and returns the number of bytes written. Fewer than n bytes are written only when an error occurs. Like read, write writes data at the current file offset and then advances that offset by the number of bytes written: each write picks up where the previous one left off.
调用write(fd, buf, n)会从缓存buf的位置读取n个字节将其写入到文件描述符fd引用的文件中,并返回写入的具体字节数。仅当有错误发生时才会写入少于n个字节。就象read一样,write将数据写入到当前文件偏移处,并将写入的字节数增加到当前偏移量:每次的写入都会从上一次位置处开始。
The following program fragment (which forms the essence of cat) copies data from its standard input to its standard output. If an error occurs, it writes a message to the standard error.
下面的程序片段(来自于cat的核心代码)从标准输入拷贝数据到标准输出。如果有错误发生,它会打印一条信息到标准错误输出。
char buf[512];
int n;
for(;;){
n = read(0, buf, sizeof buf);
if(n == 0)
break;
if(n < 0){
fprintf(2, "read error\n");
exit();
}
if(write(1, buf, n) != n){
fprintf(2, "write error\n");
exit();
}
}
The important thing to note in the code fragment is that cat doesn’t know whether it is reading from a file, console, or a pipe. Similarly cat doesn’t know whether it is printing to a console, a file, or whatever. The use of file descriptors and the convention that file descriptor 0 is input and file descriptor 1 is output allows a simple implementation of cat.
在上面的代码片段中有一件事请注意,cat不知道他是否正在从一个文件或者控制台还是管道读取内容。简单来说,cat也不知道内容输出的目的是控制台,还是一个文件,它也不关心这些。文件描述符的使用,按照惯例文件描述符0是输入,文件描述符1是输出,这样的使cat的实现简单化。
The close system call releases a file descriptor, making it free for reuse by a future open, pipe, or dup system call (see below). A newly allocated file descriptor is always the lowest-numbered unused descriptor of the current process.
Close系统调用释放文件描述符,并使它可以重新用来打开文件、管道或复制系统调用时的文件描述符(看下面)。后分配的文件描述符总当前进程中未占用的最小的文件描述符。
File descriptors and fork interact to make I/O redirection easy to implement. Fork copies the parent’s file descriptor table along with its memory, so that the child starts with exactly the same open files as the parent. The system call exec replaces the calling process’s memory but preserves its file table. This behavior allows the shell to implement I/O redirection by forking, reopening chosen file descriptors, and then execing the new program. Here is a simplified version of the code a shell runs for the command cat <input.txt:
文件描述符和fork的相互作用使I/O重定向变得实现。Fork在拷贝父进程的内存内容时一并将文件描述符表也拷贝了一份,这样,子进程开始执行时会拥有和父进程相同的打开文件。系统调用exec替换进程的内存内容,但保留它的文件描述符表。这个行为允许shell通过创建子进程(fork)、重新打开选择的文件描述符以及执行新的程序来进行I/O重定向。下面是一个简单的shell的版本实现,运行命令 cat < input.txt:
char *argv[2];
argv[0] = "cat";
argv[1] = 0;
if(fork() == 0) {
close(0);
open("input.txt", O_RDONLY);
exec("cat", argv);
}
After the child closes file descriptor 0, open is guaranteed to use that file descriptor for the newly opened input.txt: 0 will be the smallest available file descriptor. Cat then executes with file descriptor 0 (standard input) referring to input.txt.
在子进程关闭文件描述符0后,open保证为新打开的文件input.txt使用那个文件描述符:0将是最小可用的文件描述符。然后Cat执行时文件描述符0(标准输入)会引用input.txt。
The code for I/O redirection in the xv6 shell works in exactly this way (8430) . Recall that at this point in the code the shell has already forked the child shell and that runcmd will call exec to load the new program. Now it should be clear why it is a good idea that fork and exec are separate calls. This separation allows the shell to fix up the child process before the child runs the intended program.
在xv6的shell工作时重定向I/O的代码一直如此工作(8430)。在代码的这个位置重新调用它,shell已经重新创建一个子shell进程,并且runcmd会调用exec来载入新的程序。现在应该明白,为什么 fork和exec被设计成分开的两个调用是一个好的主意了。分开设计允许shell在子进程运行预期的程序前来修正它。
Although fork copies the file descriptor table, each underlying file offset is shared between parent and child. Consider this example:
尽管fork拷贝文件描述符表,其中的每个文件偏移也被在父子进程间共享。考虑如下例子:
if(fork() == 0) {
write(1, "hello ", 6);
exit();
} else {
wait();
write(1, "world\n", 6);
}
At the end of this fragment, the file attached to file descriptor 1 will contain the data hello world. The write in the parent (which, thanks to wait, runs only after the child is done) picks up where the child’s write left off. This behavior helps produce sequential output from sequences of shell commands, like (echo hello; echo world)>output.txt.
在这个代码片段结束后,附加到文件描述符1的文件将包含数据hello world。父进程中(在这里,要感谢wait,仅在子进程结束会才会运行)的写入会等待子进程写入结束。这个行为可以制造在shell命令的顺序输出,就象这样:(echo hello; echo world)>output.txt。
The dup system call duplicates an existing file descriptor, returning a new one that refers to the same underlying I/O object. Both file descriptors share an offset, just as the file descriptors duplicated by fork do. This is another way to write hello world into a file:
Dup系统调用会复制一个已存在的文件描述符,返回一个新的并且指向相同的I/O对象。所有的文件描述符共享同一个偏移,正如通过fork进行复制的文件描述符一样。下面是将hello world写入到一个文件中的另一个方法:
fd = dup(1);
write(1, "hello ", 6);
write(fd, "world\n", 6);
Two file descriptors share an offset if they were derived from the same original file descriptor by a sequence of fork and dup calls. Otherwise file descriptors do not share offsets, even if they resulted from open calls for the same file. Dup allows shells to implement commands like this: ls existing-file non-existing-file > tmp12>&1. The 2>&1 tells the shell to give the command a file descriptor 2 that is a duplicate of descriptor 1. Both the name of the existing file and the error message for the non-existing file will show up in the file tmp1. The xv6 shell doesn’t support I/O redirection for the error file descriptor, but now you know how to implement it.
两个文件描述符如果是通过顺序执行fork和dup调用获得和并且指向相同的原始文件,那它们将共享同一个文件偏移量。否则文件描述符不共享偏移,哪怕它们是对同一个文件进行的open调用获得的。Dup允许shell象下面一样来实现命令:ls 存的文件 不存在的文件 > tmp1 2 > &1。这里2 > &1 告诉shell给这个命令使用文件描述符2且由文件描述符1复制。存在的文件和对于不存在的文件的错误信息将会显示在文件tmp1中。Xv6的shell不支持对错误输出的文件描述符I/O重定向,但现在你知道如何实现它。
File descriptors are a powerful abstraction, because they hide the details of what they are connected to: a process writing to file descriptor 1 may be writing to a file, to
a device like the console, or to a pipe.
文件描述符是一个强大的抽象,因为它隐藏了连接到哪里的细节:进程向文件描述符1写入内容可能写到一个文件中,也可能写到象控制台这样的设备中,或者写到一个管道中。
Pipes
管道
A pipe is a small kernel buffer exposed to processes as a pair of file descriptors, one for reading and one for writing. Writing data to one end of the pipe makes that data available for reading from the other end of the pipe. Pipes provide a way for processes to communicate.
管道是的一个缓冲区,提供给进程一对文件描述符,一个用于读取,另一个用于写入。写数据到一个管道终端会使管道的另一个读取终端中有数据可用。管道提供一种进程间的通信方法。
The following example code runs the program wc with standard input connected to the read end of a pipe.
下面的例子代码运行一个叫wc的程序,它将标准输入连接到一个管道的读取终端。
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p);
if(fork() == 0) {
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
exec("/bin/wc", argv);
} else {
write(p[1], "hello world\n", 12);
close(p[0]);
close(p[1]);
}
The program calls pipe, which creates a new pipe and records the read and write file descriptors in the array p. After fork, both parent and child have file descriptors referring to the pipe. The child dups the read end onto file descriptor 0, closes the file descriptors in p, and execs wc. When wc reads from its standard input, it reads from the pipe. The parent writes to the write end of the pipe and then closes both of its file descriptors.
程序调用pipe来创建一个新的管道,并将读取与写入的文件描述符保存在数组p中。在fork之后,父子进程均拥有管道的文件描述符。子进程复制(dup)读终端到文件描述符0,然后关闭数组p中的文件描述符,之后执行exec wc。当wc从标准输入读取内容时,它会从管道中读取。父进程向管道的写终端写入数据,然后将所有的文件描述符关闭。
If no data is available, a read on a pipe waits for either data to be written or all file descriptors referring to the write end to be closed; in the latter case, read will return 0, just as if the end of a data file had been reached. The fact that read blocks until it is impossible for new data to arrive is one reason that it’s important for the child to close the write end of the pipe before executing wc above: if one of wc’s file descriptors referred to the write end of the pipe, wc would never see end-of-file.
如果没有数据可用,管道的读终端将等待数据被写入或者所有的指定写终端的文件描述符被关闭;后一种情况中,read会返回0,就象数据文件到尾一样。读动作会一直阻塞直到不可能有新数据到来,这就是为什么子进程在执行wc之前要关闭管道的写终端的重要原因:如果wc的一个文件描述符引用到管道的写终端,wc将永远看不到文件结束符。
The xv6 shell implements pipelines such as grep fork sh.c | wc -l in a manner similar to the above code (8450) . The child process creates a pipe to connect the left end of the pipeline with the right end. Then it calls runcmd for the left end of the pipeline and runcmd for the right end, and waits for the left and the right ends to finish, by calling wait twice. The right end of the pipeline may be a command that itself includes a pipe (e.g., a | b | c), which itself forks two new child processes (one for b and one for c). Thus, the shell may create a tree of processes. The leaves of this tree are commands and the interior nodes are processes that wait until the left and right children complete. In principle, you could have the interior nodes run the left end of a pipeline, but doing so correctly would complicate the implementation.
Xv6实现管道流象grep fork sh.c | wc –l,和上面的代码是相似的方式(8450)。子进程创建一个管道来连接一个管道流的左端和右端。然后它分别为管道流的左端和右端调用runcmd,之后通过调用两次wait来等待左端和右端结束。管道流的右端或能是一个自身就包含管道的命令(如 a | b | c),这命令会fork两个新的子进程(一个给b,另一个给c)。这样,shell会创建一个进程树。树的叶子是命令,内部节点是等待左、右子进程结束的进程。原则来说,你可以让内部节点运行在管道流的左端,但正确实现它会很复杂。
Pipes may seem no more powerful than temporary files: the pipeline
管道看起来并不比临时文件更强大:管道流
echo hello world | wc
could be implemented without pipes as
不用管道也以象下面这样实现
echo hello world >/tmp/xyz; wc </tmp/xyz
There are at least three key differences between pipes and temporary files. First, pipes automatically clean themselves up; with the file redirection, a shell would have to be careful to remove /tmp/xyz when done. Second, pipes can pass arbitrarily long streams of data, while file redirection requires enough free space on disk to store all the data. Third, pipes allow for synchronization: two processes can use a pair of pipes to send messages back and forth to each other, with each read blocking its calling process until the other process has sent data with write.
管道和临时文件至少有三个关键不同点。首先,管道自动清除自身;而用文件重定向功能,在任务完成后shell必须小心去删除/tmp/xyz文件。第二,管道可以传递做生意长度的数据流,而文件重定向需要足够的磁盘空间来保存数据。第三,管道允许同步:两个进程使用一对管道可以互相向前或向后发送消息,读取数据进程在读取时会阻塞直到发送数据进程完成写入。
File system
文件系统
The xv6 file system provides data files, which are uninterpreted byte arrays, and directories, which contain named references to data files and other directories. Xv6 implements directories as a special kind of file. The directories form a tree, starting at a special directory called the root. A path like /a/b/c refers to the file or directory named c inside the directory named b inside the directory named a in the root directory /. Paths that don’t begin with / are evaluated relative to the calling process’s current directory, which can be changed with the chdir system call. Both these code fragments open the same file (assuming all the directories involved exist):
Xv6文件系统提供包含原生的字节数组的数据文件、包含具有名称的数据文件或其他目录的目录。Xv6将目录视为一种特殊的文件。目录树从一个被叫做root的特殊目录开始。类似/a/b/c的路径指向一个叫做c的文件或目录,它被叫做b的目录所包含,而b目录又被a目录所包含,最终,a目录被叫做/的根目录所包含。不以/开始的路径的计算从调用进程的当前目录开始,当前目录可以使用chdir系统调用来个性。下面的这些代码片段均打开一个相同的文件(假定所有涉及的目录均存在):
chdir("/a");
chdir("b");
open("c", O_RDONLY);
open("/a/b/c", O_RDONLY);
The first fragment changes the process’s current directory to /a/b; the second neither refers to nor modifies the process’s current directory.
第一个代码片段更改进程的当前目录为/a/b;而第二个不涉及修改进程的当前目录。
There are multiple system calls to create a new file or directory: mkdir creates a new directory, open with the O_CREATE flag creates a new data file, and mknod creates a new device file. This example illustrates all three:
有多个系统调用来创建一个新文件或目录:mkdir创建一个新的目录,带O_CREATE标识的open创建一个新的数据文件,mknod创建一个新的设备文件。下面的例子解释这三个命令的用法:
mkdir("/dir");
fd = open("/dir/file", O_CREATE|O_WRONLY);
close(fd);
mknod("/console", 1, 1);
Mknod creates a file in the file system, but the file has no contents. Instead, the file’s metadata marks it as a device file and records the major and minor device numbers (the two arguments to mknod), which uniquely identify a kernel device. When a process later opens the file, the kernel diverts read and write system calls to the kernel device implementation instead of passing them to the file system. fstat retrieves information about the object a file descriptor refers to. It fills in a struct stat, defined in stat.h as:
Mknod在文件系统中创建一个没有任何内容的文件。相反,这个文件的原数据标识表明它是一个设备文件,并且记录了主、副设备号(mknod的两个参数),这是内核设备的唯一标识。当后来的进程打开这个文件,内核将read和write系统调用分开交给内核的设备实现代码,而不是将它们传递到文件系统。Fstat调用获取关于文件描述符对象引用对象的信息。它会填充一个stat结构,这个结构定义在stat.h中:
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEV 3 // Device
struct stat {
short type; // Type of file
int dev; // File system’s disk device
uint ino; // Inode number
short nlink; // Number of links to file
uint size; // Size of file in bytes
};
A file’s name is distinct from the file itself; the same underlying file, called an inode, can have multiple names, called links. The link system call creates another file system name referring to the same inode as an existing file. This fragment creates a new file named both a and b.
一个文件本身有明确的名字;一个相同的基本文件,也叫inode可以有多个名称,叫link。Link系统调用创建另一个文件系统的名字并将其指向一个已存在的相同的inode。下面的代码片段创建一个新文件叫a和b。
open("a", O_CREATE|O_WRONLY);
link("a", "b");
Reading from or writing to a is the same as reading from or writing to b. Each inode is identified by a unique inode number. After the code sequence above, it is possible to determine that a and b refer to the same underlying contents by inspecting the result of fstat: both will return the same inode number (ino), and the nlink count will be set to 2.
对a文件进行读写和向b文件进行读写是相同的。每个inode都是唯一的inode数字。在上面的代码行运行之后,通过fstat来查看返回结果,你会发现a和b都指向同一个基本内容:都返回同一个inode编号(ino),并且nlink计数都被设置为2。
The unlink system call removes a name from the file system. The file’s inode and the disk space holding its content are only freed when the file’s link count is zero and no file descriptors refer to it. Thus adding unlink("a"); to the last code sequence leaves the inode and file content accessible as b. Furthermore,
Unlink系统调用从文件系统中删除一个名称。这个文件的inode和磁盘空间会保留直到这个文件的连接计数(link count)被置为0,并且没有文件描述符再指向它。因此当增加 unlink(“a”)语句在上面的代码片段后,会保留inode和文件内容,并且作为b的名称可被访问。进一步,
fd = open("/tmp/xyz", O_CREATE|O_RDWR);
unlink("/tmp/xyz");
is an idiomatic way to create a temporary inode that will be cleaned up when the process closes fd or exits.
上面的是符合语言的习惯的代码用来创建一个临时inode并且在进程关闭fd或退出时会被清理。
Xv6 commands for file system operations are implemented as user-level programs such as mkdir, ln, rm, etc. This design allows anyone to extend the shell with new user commands. In hind-sight this plan seems obvious, but other systems designed at the time of Unix often built such commands into the shell (and built the shell into the kernel).
Xv6文件系统的命令操作是在用户级别的程序上来实现的,比如:mkdir、ln、rm等等。这种设计允许任何人使用新的命令来扩展shell。从后见之明的角度看这种设计更明显,但在unix同时设计的其他系统的经常内建这些命令到shell中(并且将shell内建到内核中)。
One exception is cd, which is built into the shell (8516) . cd must change the current working directory of the shell itself. If cd were run as a regular command, then the shell would fork a child process, the child process would run cd, and cd would change the child’s working directory. The parent’s (i.e., the shell’s) working directory would not change.
Cd是一个例外,它被内建到shell中(8516)。Cd必须切换shell本身的当前工作目录。如果cd象一般命令一样,那么shell必须fork一个子进程来运行cd,并且cd将切换子进程的工作目录。而父进程(也是shell)的工作目录将不会被切换。
Real world
真实的世界
Unix’s combination of the ‘‘standard’’ file descriptors, pipes, and convenient shell syntax for operations on them was a major advance in writing general-purpose reusable programs. The idea sparked a whole culture of ‘‘software tools’’ that was responsible for much of Unix’s power and popularity, and the shell was the first so-called ‘‘scripting language.’’ The Unix system call interface persists today in systems like BSD, Linux, and Mac OS X.
包含了标准的文件描述符、管道以及符合习惯的语法操作的shell的unix,对于书写一般目标可重用程序来说是主要进展。这种设计激发了软件工具文化,这种文化促进了unix的发展和流行,并且shell是第一个“脚本语言”。Unix系统调用接口在今天多个系统中存在,如BSD、linux和Mac OS X。
Modern kernels provide many more system calls, and many more kinds of kernel services, than xv6. For the most part, modern Unix-derived operating systems have not followed the early Unix model of exposing devices as special files, like the console device file discussed above. The authors of Unix went on to build Plan 9, which applied the ‘‘resources are files’’ concept to modern facilities, representing networks, graphics, and other resources as files or file trees.
现代内核比xv6提供更多的系统调用和更多的内核类服务。对于大部分来说,现代的unix衍生操作系统没有遵循早期unix模式(将设备做为特殊文件),象上面讨论的控制台设备文件。Unix的作者继续构建Plan 9,它将为现代设备提供资源文件的概念,如网络、图形和其他资源都被作为文件或文件树。
The file system abstraction has been a powerful idea, most recently applied to network resources in the form of the World Wide Web. Even so, there are other models for operating system interfaces. Multics, a predecessor of Unix, abstracted file storage in a way that made it look like memory, producing a very different flavor of interface. The complexity of the Multics design had a direct influence on the designers of Unix, who tried to build something simpler.
文件系统的抽象是一个强大的概念,尤其是最近实现的标准的www的网络资源。尽管如此,对于操作系统接口来说还存在其他的模式。多路信息计算系统(Multics),unix的前身,使用另一种方式来抽象文件存储,使其更象内存,提供不同的接口风格。复杂的多路信息计算系统(Multics)的设计对于unix的设计有一个很直接的影响,试图使一切更简单。
This book examines how xv6 implements its Unix-like interface, but the ideas and concepts apply to more than just Unix. Any operating system must multiplex processes onto the underlying hardware, isolate processes from each other, and provide mechanisms for controlled inter-process communication. After studying xv6, you should be able to look at other, more complex operating systems and see the concepts underlying xv6 in those systems as well.
这本书解释了为何xv6的接口是类unix的,但想法和概念不仅局限于unix。任何操作系统都必须在基本硬件上提供多进程,进程隔离,以及进程间通信机制。在学习了xv6之后,你应当去看看其他的,更复杂的操作系统,看看那些xv6和那些系统中都存在的概念。
xv6课本翻译之——第0章 操作系统接口的更多相关文章
- 【翻译】XV6-DRAFT as of September 3,2014 第0章 操作系统接口
操作系统接口 操作系统的任务是让多个程序共享计算机(资源),并且提供一系列基于计算机硬件的但更有用的服务.操作系统管理并且把底层的硬件抽象出来,举例来说,一个文字处理软件(例如word)不需要关心计算 ...
- xv6课本翻译之——附录A Pc的硬件
Appendix A 附录A PC hardware Pc的硬件 This appendix describes personal computer (PC) hardware, the platfo ...
- XV6操作系统接口
操作系统接口 操作系统的工作是(1)将计算机的资源在多个程序间共享,并且给程序提供一系列比硬件本身更有用的服务.(2)管理并抽象底层硬件,举例来说,一个文字处理软件(比如 word)不用去关心自己使用 ...
- 《Introduction to Tornado》中文翻译计划——第五章:异步Web服务
http://www.pythoner.com/294.html 本文为<Introduction to Tornado>中文翻译,将在https://github.com/alioth3 ...
- 翻译连载 | 第 9 章:递归(下)-《JavaScript轻量级函数式编程》 |《你不知道的JS》姊妹篇
原文地址:Functional-Light-JS 原文作者:Kyle Simpson-<You-Dont-Know-JS>作者 关于译者:这是一个流淌着沪江血液的纯粹工程:认真,是 HTM ...
- 翻译连载 | 第 10 章:异步的函数式(上)-《JavaScript轻量级函数式编程》 |《你不知道的JS》姊妹篇
原文地址:Functional-Light-JS 原文作者:Kyle Simpson-<You-Dont-Know-JS>作者 关于译者:这是一个流淌着沪江血液的纯粹工程:认真,是 HTM ...
- 翻译连载 | 第 10 章:异步的函数式(下)-《JavaScript轻量级函数式编程》 |《你不知道的JS》姊妹篇
原文地址:Functional-Light-JS 原文作者:Kyle Simpson-<You-Dont-Know-JS>作者 关于译者:这是一个流淌着沪江血液的纯粹工程:认真,是 HTM ...
- 翻译连载 | 第 11 章:融会贯通 -《JavaScript轻量级函数式编程》 |《你不知道的JS》姊妹篇
原文地址:Functional-Light-JS 原文作者:Kyle Simpson-<You-Dont-Know-JS>作者 关于译者:这是一个流淌着沪江血液的纯粹工程:认真,是 HTM ...
- [翻译] C# 8.0 新特性 Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南) 【由浅至深】redis 实现发布订阅的几种方式 .NET Core开发者的福音之玩转Redis的又一傻瓜式神器推荐
[翻译] C# 8.0 新特性 2018-11-13 17:04 by Rwing, 1179 阅读, 24 评论, 收藏, 编辑 原文: Building C# 8.0[译注:原文主标题如此,但内容 ...
随机推荐
- css图片精灵
<ul> <li class="top"> <em>01</em> <p><a href="http:/ ...
- Spring的IOC和AOP之深剖
今天,既然讲到了Spring 的IOC和AOP,我们就必须要知道 Spring主要是两件事: 1.开发Bean:2.配置Bean.对于Spring框架来说,它要做的,就是根据配置文件来创建bean实例 ...
- 浅谈Angular的 $q, defer, promise
浅谈Angular的 $q, defer, promise 时间 2016-01-13 00:28:00 博客园-原创精华区 原文 http://www.cnblogs.com/big-snow/ ...
- 20个不可思议的 WebGL 示例和演示
WebGL 是一项在网页浏览器呈现3D画面的技术,有别于过去需要安装浏览器插件,通过 WebGL 的技术,只需要编写网页代码即可实现3D图像的展示.WebGL 可以为 Canvas 提供硬件3D加速渲 ...
- 可空类型(Nullable<T>)及其引出的关于explicit、implicit的使用
问题一:Nullable<T>可赋值为null 先看两行C#代码 int? i1 = null; int? i2 = new int?(); int? 即Nullable<int&g ...
- MarkdownPad 2 常用快捷键
Ctrl + I : 斜体 Ctrl + B : 粗体 Ctrl + G : 图片 Ctrl + Q : 引用 Ctrl + 1 : 标题 1 Ctrl + 2 : 标题 2 Ctrl + 3 : 标 ...
- iOS角度与弧度转换
在iOS中图片的旋转单位为弧度而不是角度,所以经常会在两者之间进行转换 弧度转角度 #define RADIANS_TO_DEGREES(radians) ((radians) * (180.0 / ...
- Git使用详细教程(一)
很久不发博客,最近有兴趣想写点东西,但 Live Writer 不支持从Word复制图片,疯狂吐槽下 Git使用详细教程(一) Git使用详细教程(二) 该教程主要是Git与IntelliJ IDEA ...
- 记录一次Quartz2D学习(四)
(三)内主要讲了图片与文字的绘制 本次主要讲解 绘制状态的保存与恢复,以及对它的使用 4.绘制状态 4.1 绘制状态的保存与恢复,以及对它的应用 TIP:通过对保存恢复绘制状以及多次的渲染,可以绘制出 ...
- yii2中如何使用modal弹窗之基本使用
作者:白狼 出处:http://www.manks.top/yii2_modal_baseuse.html 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接, ...