最大熵模型和EM算法
一、极大似然
已经发生的事件是独立重复事件,符合同一分布
已经发生的时间是可能性(似然)的事件
利用这两个假设,已经发生时间的联合密度值就最大,所以就可以求出总体分布f中参数θ
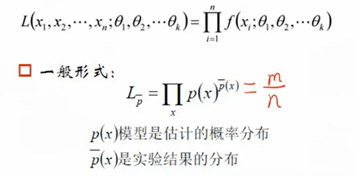
用极大似然进行机器学习
有监督学习:最大熵模型
无监督学习:GMM
二、熵和信息
自信息i(x) = -log(p(x)) 信息是对不确定性的度量。概率是对确定性的度量,概率越大,越确定,可能性越大。信息越大,越不确定。
熵是对平均不确定性的度量。熵是随机变量不确定性的度量,不确定性越大,熵值越大。
H(x) = -∑p(x)logP(x)
互信息,其实我不不关心一个事件的大小,更关心的是知道某个信息之后,对于你关心的那个事件的不确定性的减少。互信息是对称的。
i(y, x) = i(y) – i(y|x) = log(p(y|x)/p(y))
平均互信息
决策树中的“信息增益”其实就是平均互信息I(x, y), 后面那部分就是互信息,前面p(x,y)相当于权重。这就与机器学习相关的点了。平均互信息=熵-条件熵
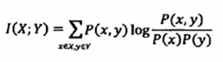
信息论与机器学习的关系
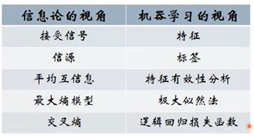
交叉熵
评价两个概率分布的差异性,比如一个概率分布是01分布,另一个概率分布也是01分布,但是他们分布的概率不一样,一个3/7,一个是6/4
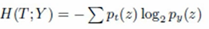
逻辑回归中的交叉熵代价函数,用来衡量误差,a是预测值,y是实际值
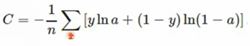
相对熵(KL散度) 也是衡量两个概率分布的差异性,可以理解成一种广泛的距离。不具有对称性。
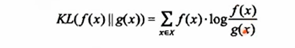
三、最大熵原理
(比较理想的模型,实际实现的时候计算量比较大,只适合于自然语言处理中的一小部分问题,在近两年大家提到的频率没有那么高了,因为deeplearning的兴起,很多用神经网络替换了。)
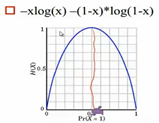
凡是已知的条件认为是一种约束,对于未知的条件,我们认为是均匀分布的且没有任何偏见。条件熵最大是一个自然的规律,它意味着我们所有的条件概率的分布在约束条件下也符合平均的。
承认已知事物,对未知事务不做任何假设,没有任何偏见,熵取最大的时候,是各个概率都相等的时候
最大熵存在且唯一(凸优化)
最大熵原理进行机器学习
最大化条件熵得出的结果就是我们要得到的条件概率的分布P(y|x),就是我们要求的模型
x表示特征,y表示标签
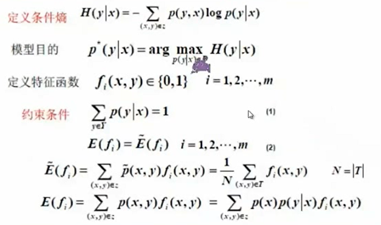
理解约束条件

若引入新知识,p(y4)=0.5

再次引入新知识,条件概率约束,怎么样得到无偏的最大熵模型。

用凸优化(求最小值)理论求解Maxent
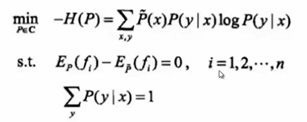
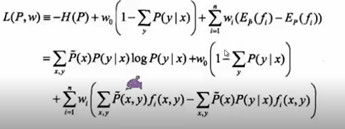
原始问题是求凸函数的最小值,对偶问题是求其对偶函数的最大值,在最大函数不是凸的情况下,原来问题的最小值会比对偶问题的最大值还大一点点,有一段gap,但对于凸函数来说gap会等于0,所有只要求对偶问题的最大值就够了,就能够求到原始问题最小值对应的值。题就相当于解完了。

泛函求导,由于P不是一个变量,是一个函数,所以涉及到泛函求导。

求偏导,得到条件概率,得到我们苦苦追寻的p(y|x),其中的w是我们要求的。
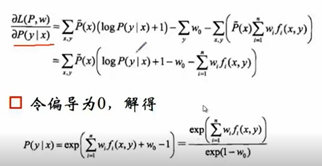
但是上面这个条件概率所有情况加起来是不等于1的,所以我们进行归一化,将值相加再除以它,下面就是最大熵模型的形式,一个非常简单的形式——指数函数。确定指数函数的参数就是训练的过程。最原始的训练方法是GIS,后面又提出IIS。下图还举了一个最大熵模型转换为Logistic回归的例子,对输入x和输出y去做一个f(x,y)的定义的时候,可以转化。


主要应用:自然语言处理中的词性标注、句法分析。最大熵的库:github上面minixalpha/Pycws 用最大熵完成抽取的特征

四、EM算法
EM算法在高斯模型里面的体现
EM算法求解GMM问题,下面是个无监督的问题。男女在身高上都符合高斯分布,是属于女生的分布多还是属于男生的分布多,哪个分布多点,就属于哪类。

上面那个例子就是,两个高斯分布,高斯分布男,高斯分布女,并分别对应概率π1,π2(相当于系数权重)

拟合出一套对数似然函数,括号里面是一个Xi出现的概率,权重相乘加和后就是结果
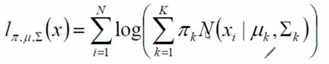
r(i,k)可以看成是其中一个高斯分布在生成数据xi时所作的贡献,先假定参数已知。

基于已经知道的值,做一个加和就能反过来求μ和西格玛和π,其中Nk是某一个高斯型对所有身高的人数的贡献,即对每个确定的组分对所有人求和,比如高斯分布女的概率求所有人加和,这个值应该就是所有女生的人数。

EM算法最原始的思路



凸函数 函数的期望大于等于期望的函数
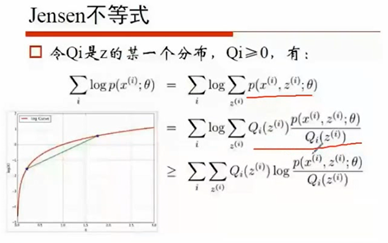

当Q等于下个这个值时,等号成立

求Q的过程就是求E(期望),然后再基于Q,求紧下界的最大值,从而求出θ。反复迭代得到

最终要求的是隐含变量Z,Q是为了方便求解Z引入的一个中间变量,Q是Z的某一个分布。Q通过jensen不等式和一系列的值,E步过程求得值。Z对应到我们上面高斯分布模型里面就是上面的π,Q是上面的r(i,k)。EM算法是一种框架,Z可以是你要求的任何变量。
最大熵模型和EM算法的更多相关文章
- 混合高斯模型和EM算法
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类别标签用表示 ...
- 高斯混合模型和EM算法
使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类别标签用表示.与k- ...
- HMM模型和Viterbi算法
https://www.cnblogs.com/Denise-hzf/p/6612212.html 一.隐含马尔可夫模型(Hidden Markov Model) 1.简介 隐含马尔可夫模型并不是俄罗 ...
- 混合高斯模型和EM
<统计学习方法>这本书上写的太抽象,可参考这位大神的:http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html
- EM算法【转】
混合高斯模型和EM算法 这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与K-means一样,给定的训练样本是, ...
- 机器学习算法总结(六)——EM算法与高斯混合模型
极大似然估计是利用已知的样本结果,去反推最有可能(最大概率)导致这样结果的参数值,也就是在给定的观测变量下去估计参数值.然而现实中可能存在这样的问题,除了观测变量之外,还存在着未知的隐变量,因为变量未 ...
- EM 算法-对鸢尾花数据进行聚类
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍过K 均值算法,它是一种聚类算法.今天介绍EM 算法,它也是聚类算法,但比K 均值算法更加灵活强大. ...
- (转载)OSI七层参考模型和TCP/IP四层参考模型
Mallory 网络模型概念浅析 网络模型一般是指OSI七层参考模型和TCP/IP四层参考模型. #只是一种设计==模型# Open System Interconnect的缩写,意为开放式系统互 ...
- Java内存模型和JVM内存管理
Java内存模型和JVM内存管理 一.Java内存模型: 1.主内存和工作内存(即是本地内存): Java内存模型的主要目标是定义程序中各个变量的访问规则,即在JVM中将变量存储到内存和从内存中取 ...
随机推荐
- 容易被误读的IOSTAT
iostat(1)是在Linux系统上查看I/O性能最基本的工具,然而对于那些熟悉其它UNIX系统的人来说它是很容易被误读的.比如在HP-UX上 avserv(相当于Linux上的 svctm)是最重 ...
- linux vi粘贴格式易错乱
对于一些冗长的代码完全可以粘贴的时候,vi粘贴所有格式全部错乱,完全无法阅读. 解决办法:esc进入命令行模式后,输入 :set paste,然后再i进入粘贴编辑模式,即可正常复制并保留原有格式-
- threejs学习笔记(二)
THREE.WebGLRenderer THREE.Scene THREE.OrthographicCamera正交相机 THREE.PerspectiveCamera透视相机 renderer.se ...
- MySQL之视图、触发器、事务、存储过程、函数
一 视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,可以将该结果集当做表来使用. 使用视图我们可以把查询过程中的 ...
- 【原创】讲讲亿级PV的负载均衡架构
引言 本来没想写这个题材的,为了某某童鞋能够更好的茁壮成长,临时写一篇负载均衡的.负载均衡,大家可能听过什么3层负载均衡.4层负载均衡.7层负载均衡什么的?那这是怎么分的呢,ok,是根据osi七层网络 ...
- HTML多图无缝循环翻页效果
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- AtCoDeerくんと選挙速報 / AtCoDeer and Election Report AtCoder - 2140 (按比例扩大)
Problem Statement AtCoDeer the deer is seeing a quick report of election results on TV. Two candidat ...
- JS/JQuery 设置input等标签设置和取消只读属性
<input type="text" id="HouseName" value="" align="left"/& ...
- [转帖]UTC时间、GMT时间、本地时间、Unix时间戳
UTC时间.GMT时间.本地时间.Unix时间戳 https://www.cnblogs.com/xwdreamer/p/8761825.html 引用: https://blog.csdn.net/ ...
- 整合Spring5+Struts2.5+Hibernate5+maven
1. 使用Eclipse创建Maven项目 2. 配置pom.xml引入需要的依赖包 <dependencies> <dependency> <groupId>ju ...