httpclient+jsoup实现小说线上采集阅读
前言
用过老版本UC看小说的同学都知道,当年版权问题比较松懈,我们可以再UC搜索不同来源的小说,并且阅读,那么它是怎么做的呢?下面让我们自己实现一个小说线上采集阅读。(说明:仅用于技术学习、研究)
看小说时,最烦的就是有各种广告,这些广告有些是站长放上去的盈利手段,有些是被人恶意注入。在我的上一篇博客中实现了小说采集并保存到本地TXT文件 HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件,这样我们就可以导入手机用手机阅读软件看小说;那么我们这里实现一个可以在线看小说。
话不多说先看效果
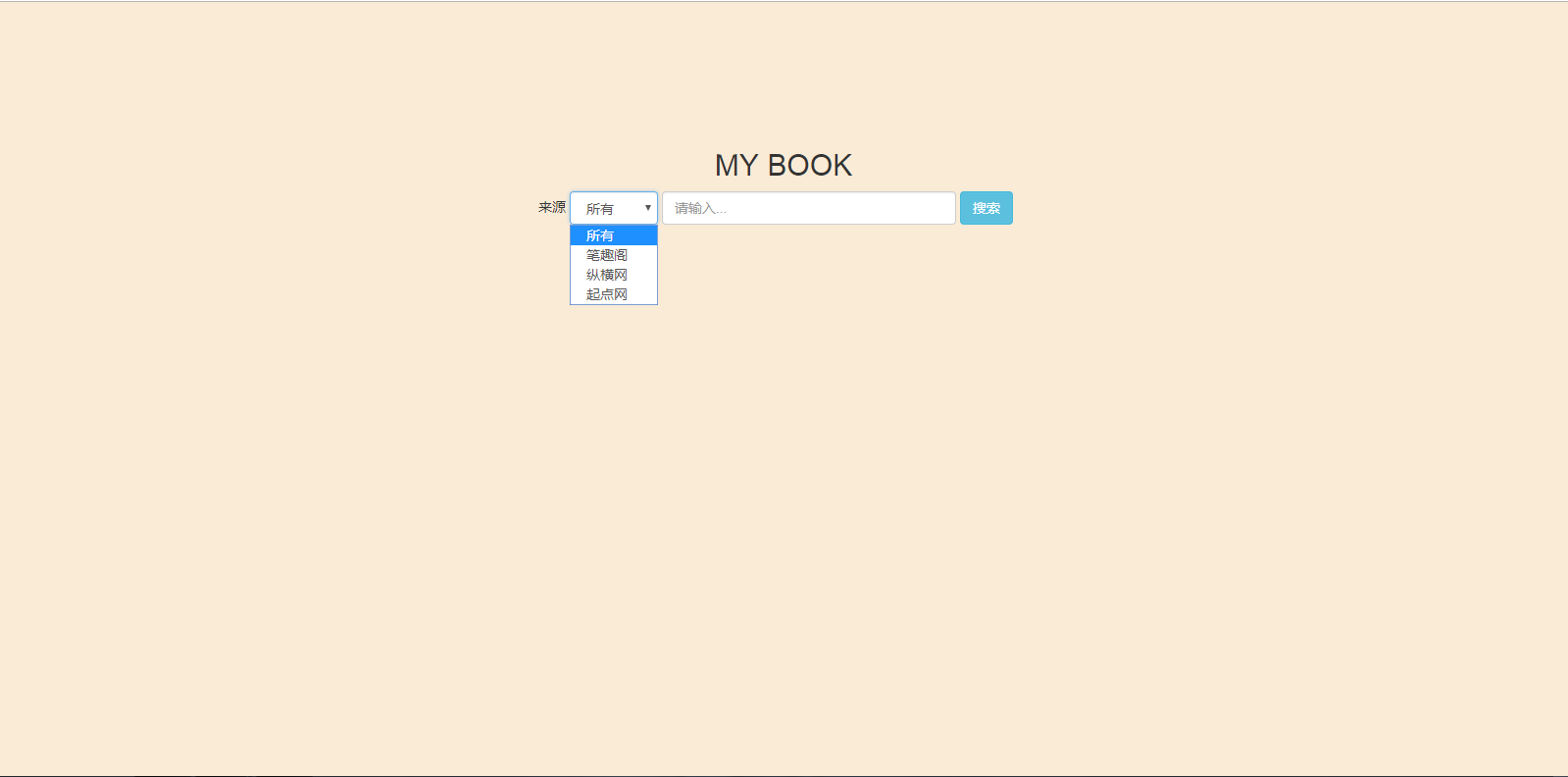
首页:
页面很纯净,目前有三种来源
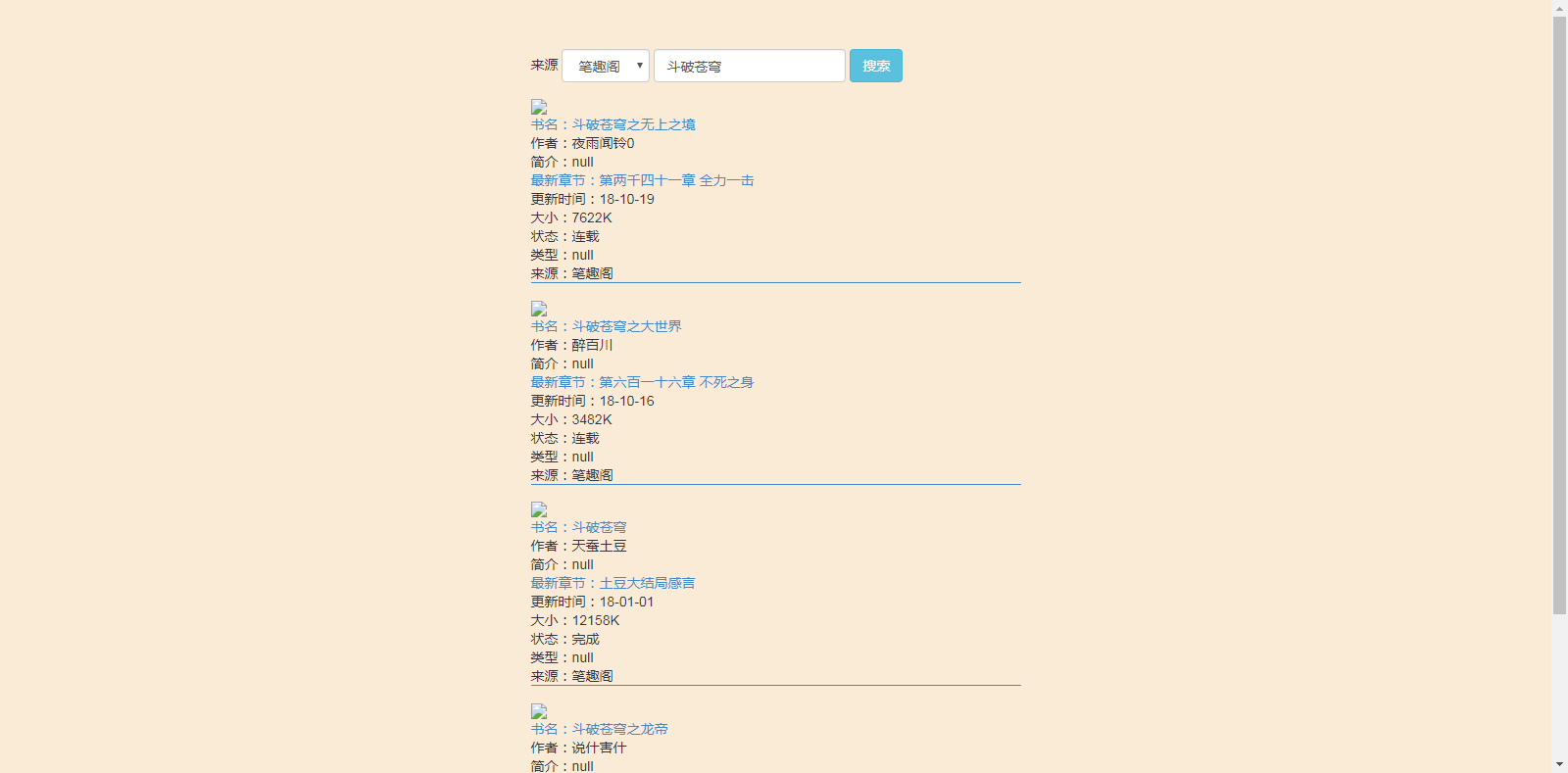
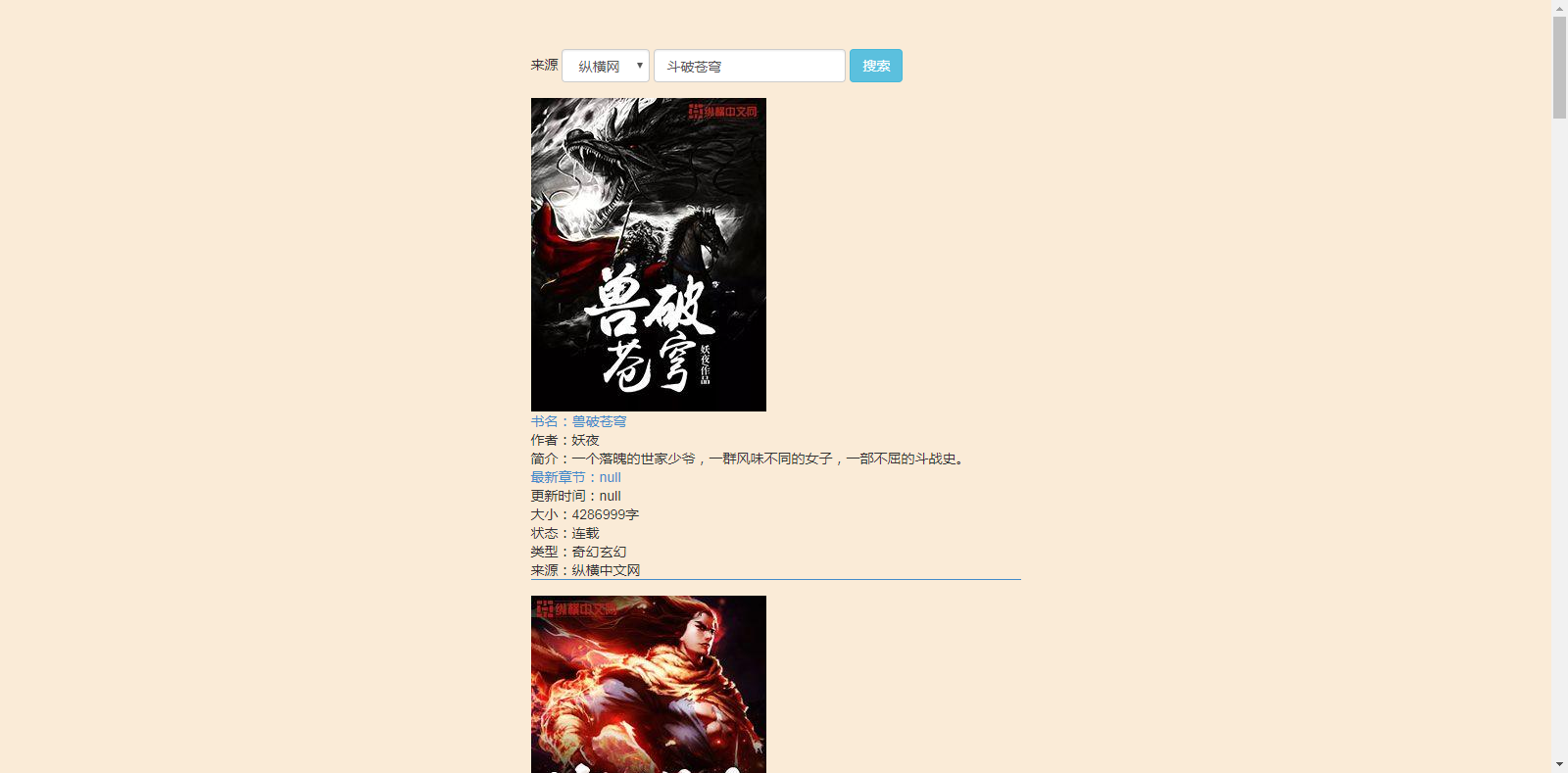
搜索结果页:
三个不同的来源,分页用的是layui的laypage,逻辑分页。(笔趣阁的搜索结果界面没有书本的图片)
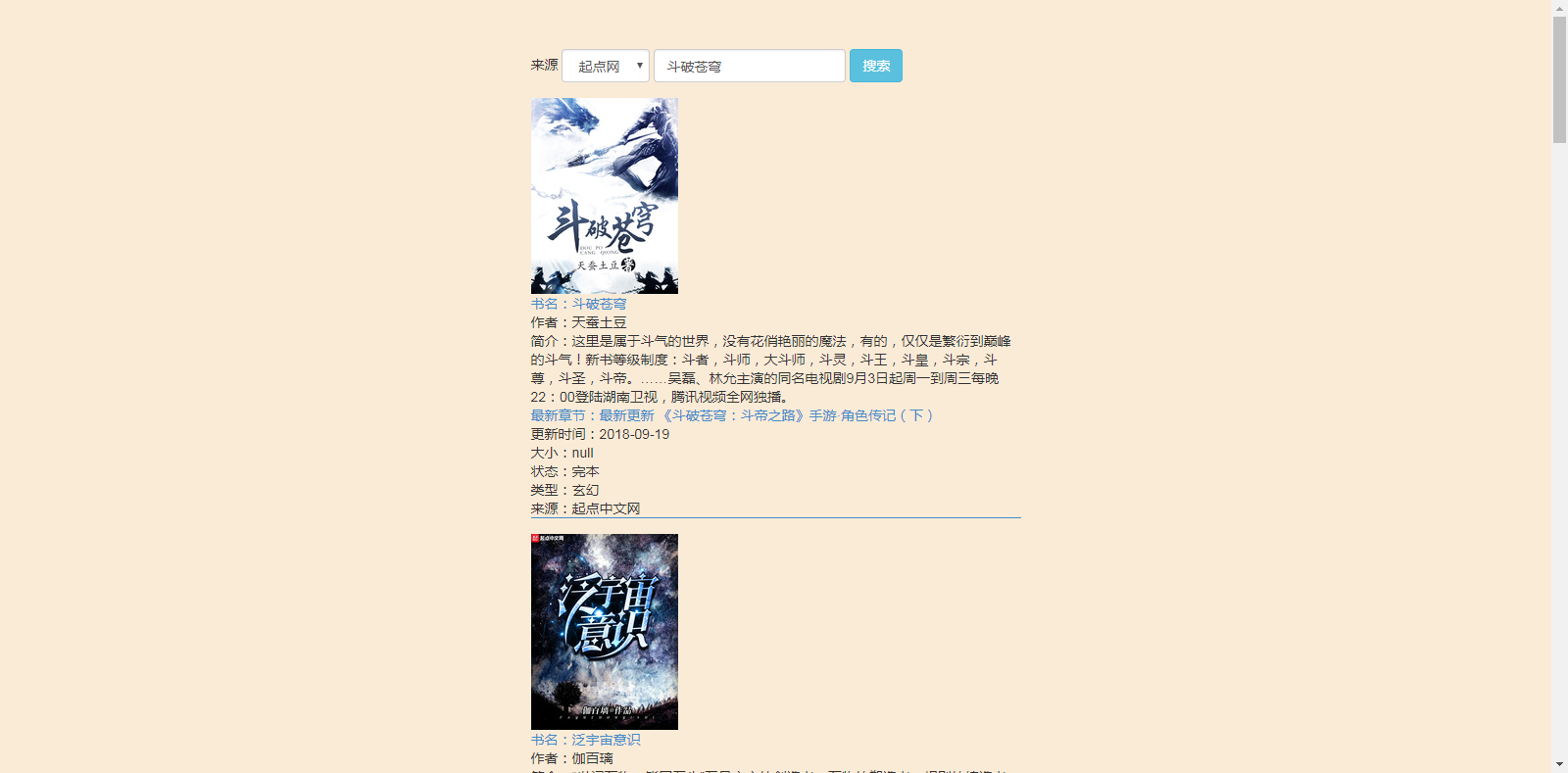
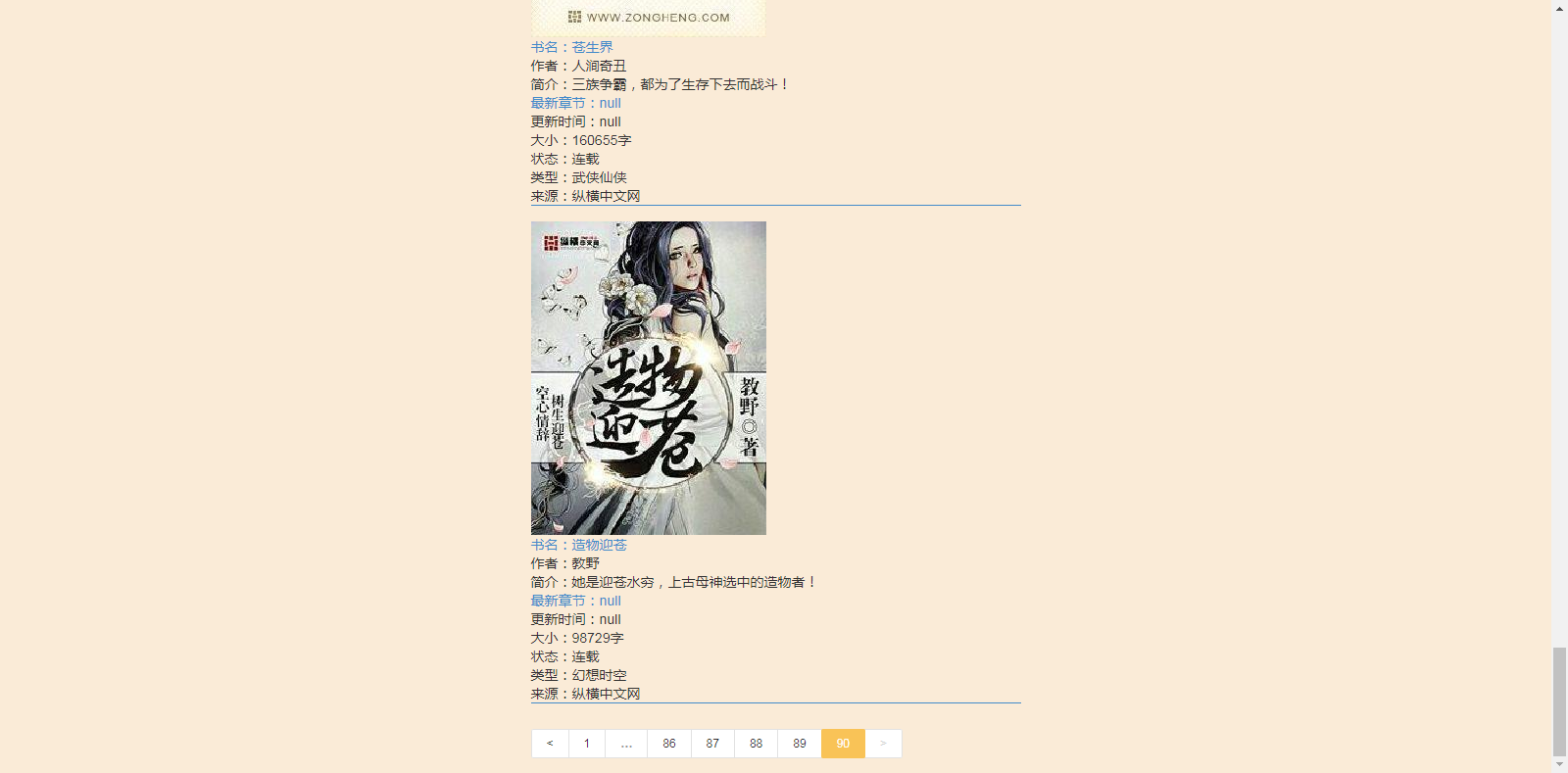
翻页效果:
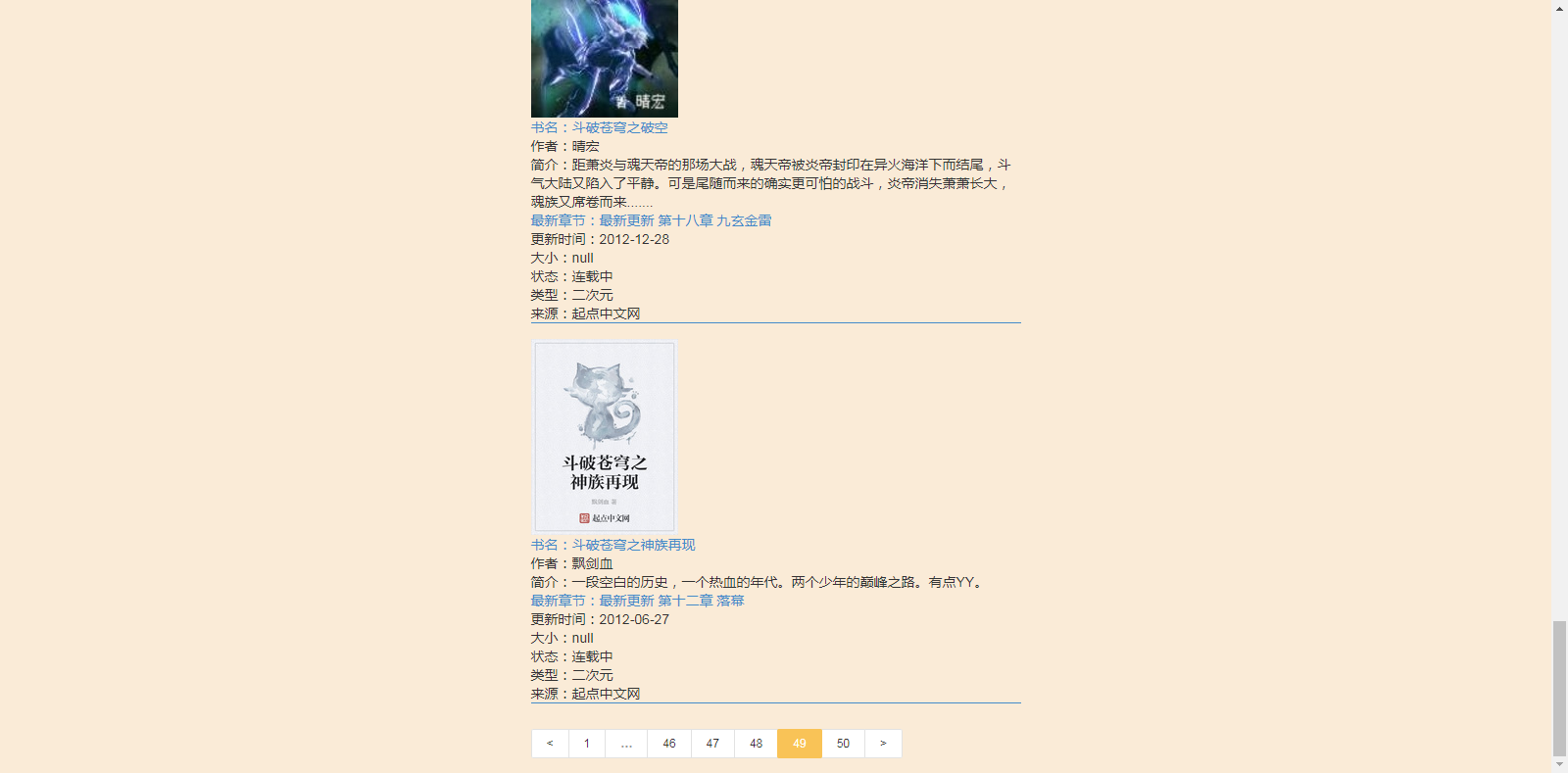
纵横网连简介等都帮我们分词,搞得数据量太大,速度太慢:books.size() < 888
书本详情页:
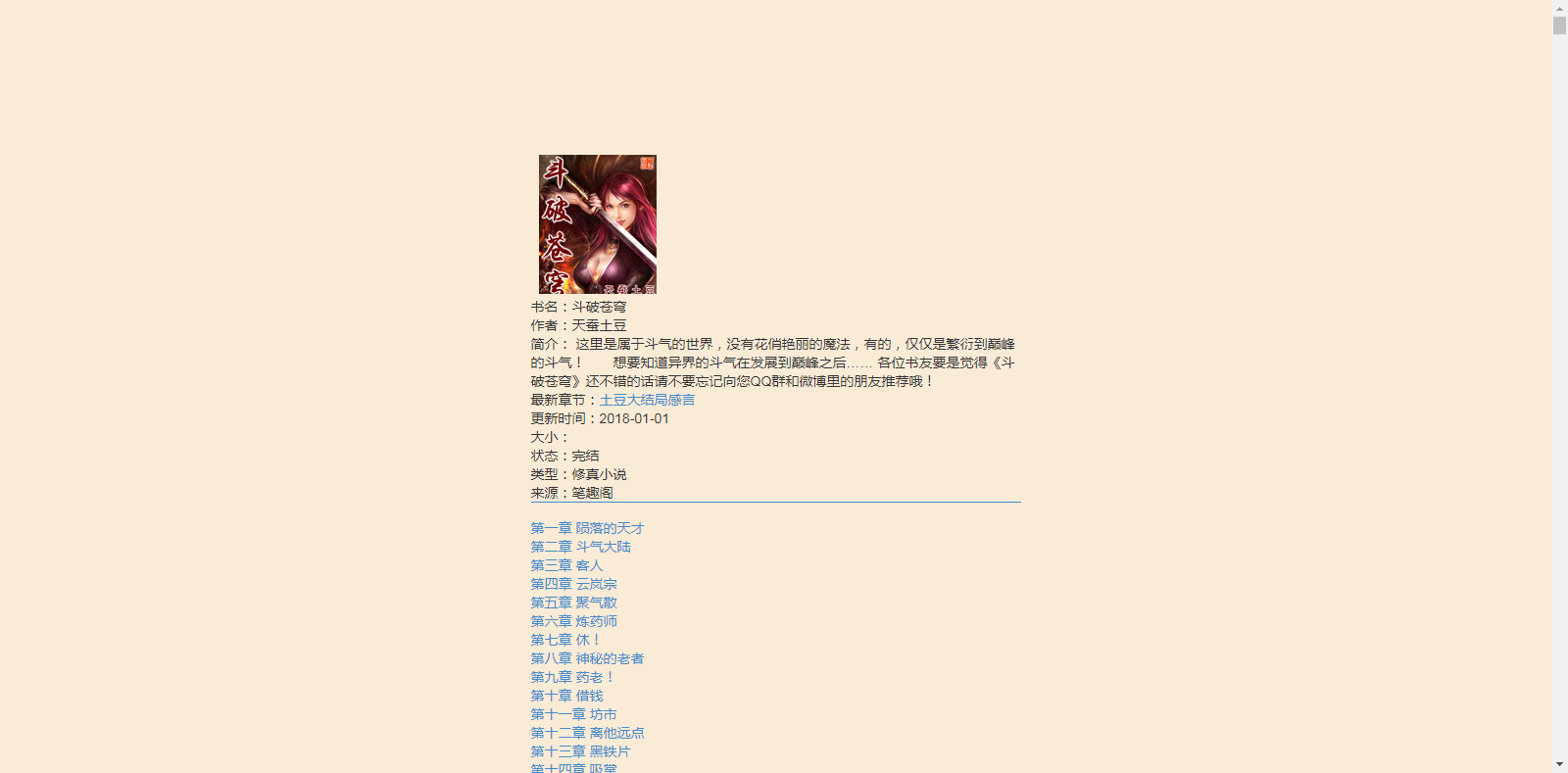

小说阅读页:


上、下一章:

代码与分析
项目是springboot项目,原理非常简单,就是用httpclient构造一个请求头去请求对应的来源链接,用jsoup去解析响应回来的response,
通过jsoup的选择器去找到我们想要的数据,存入实体,放到ModelAndView里面,前端页面用thymeleaf去取值、遍历数据。
但是有一些书是要会员才能看,这种情况下我们需要做模拟登陆才能继续采集,这里只是一个简单的采集,就不做模拟登陆了。
采集过程中碰到的问题:
1、起点中文网采集书本集合时,想要的数据不在页面源码里面


(_4P`Y)P2.png)
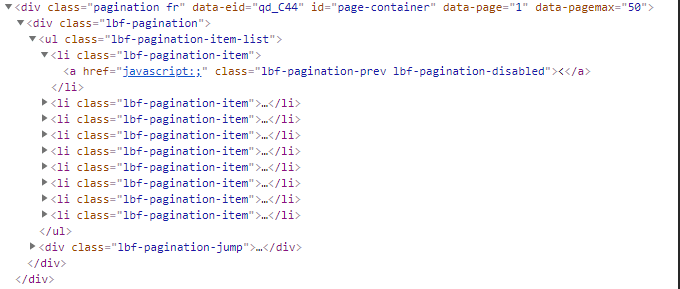
由此推测,page相关的信息,起点中文网是在js代码里面去获取并追加,最后通过network找到它的一些蛛丝马迹
H5N5P8N}V.png)
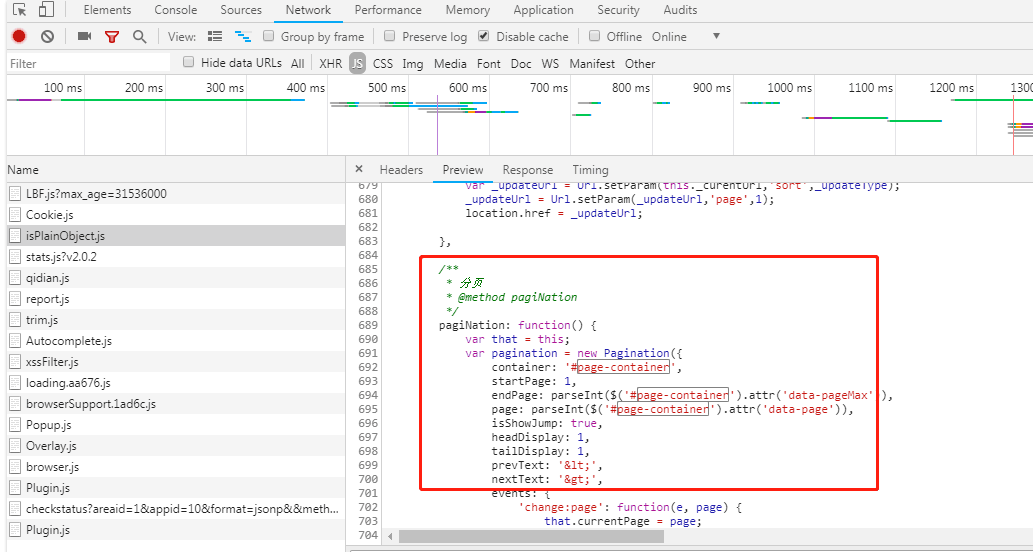


CNL8](HB72$~U)OMF.png)
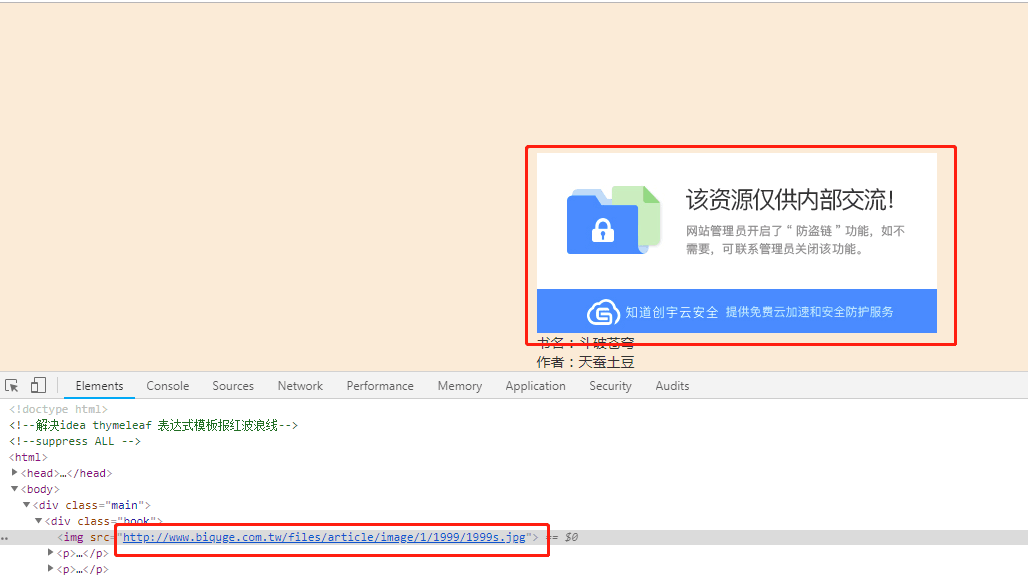
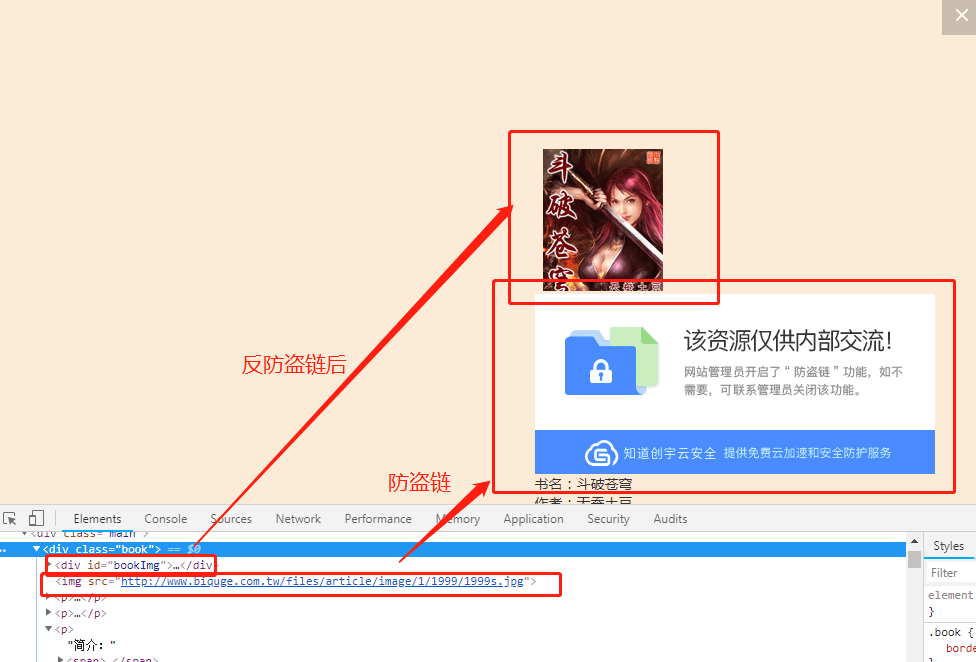
2、笔趣阁查看书本详情,图片防盗链
 ,但当我们把链接用浏览器访问时是可以的
,但当我们把链接用浏览器访问时是可以的
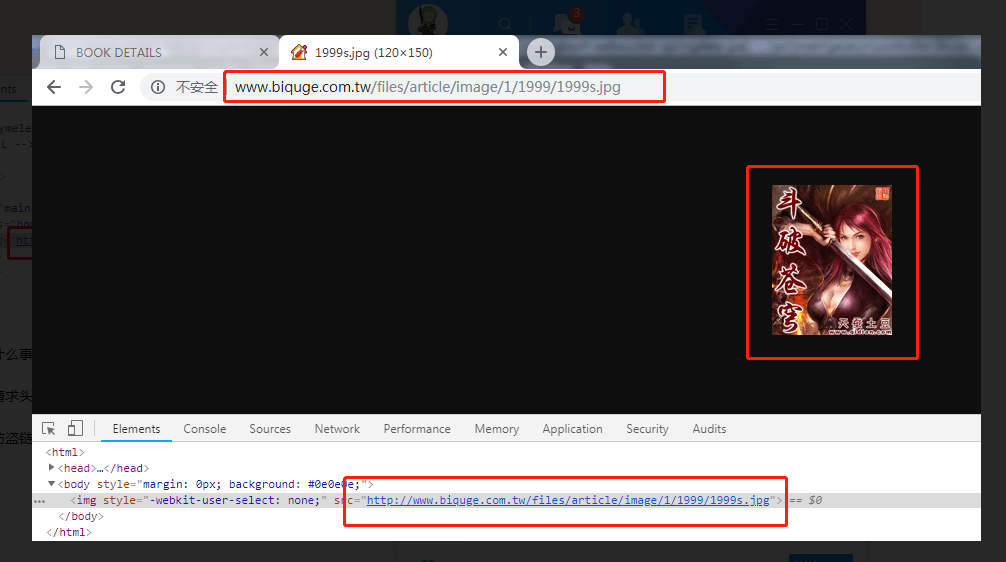




 ;我们直接用大佬的反防盗链方法,并且针对我们的项目改造一下:
;我们直接用大佬的反防盗链方法,并且针对我们的项目改造一下:<div id="bookImg"></div>
/**
* 反防盗链
*/
function showImg(parentObj, url) {
//来一个随机数
var frameid = 'frameimg' + Math.random();
//放在(父页面)window里面 iframe的script标签里面绑定了window.onload,作用:设置iframe的高度、宽度 <script>window.onload = function() { parent.document.getElementById(\'' + frameid + '\').height = document.getElementById(\'img\').height+\'px\'; }<' + '/script>
window.img = '<img src=\'' + url + '?' + Math.random() + '\'/>';
//iframe调用parent.img
$(parentObj).append('<iframe id="' + frameid + '" src="javascript:parent.img;" frameBorder="0" scrolling="no"></iframe>');
} showImg($("#bookImg"), book.img);
 效果最终:
效果最终:
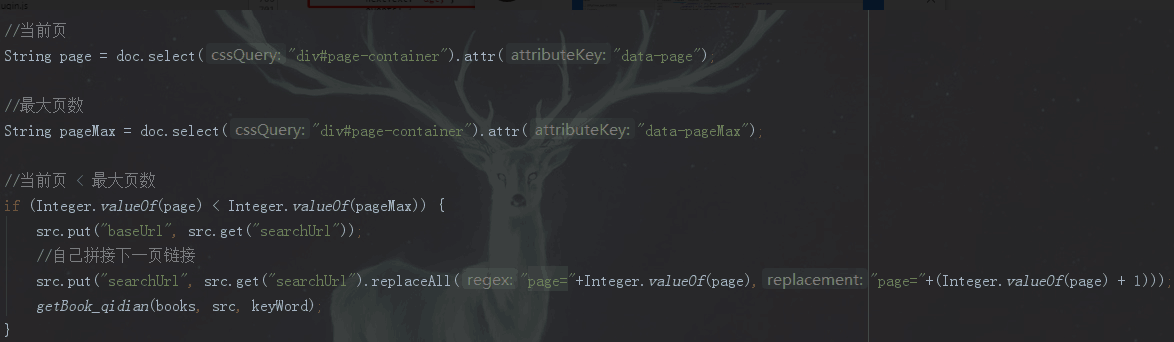
3、采集书本详情时,起点网的目录并没有在html里


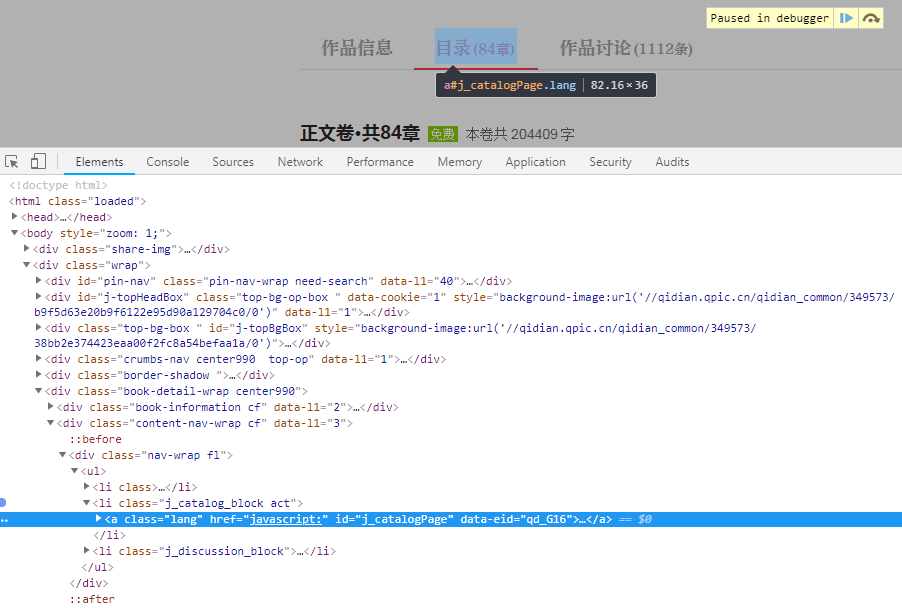

 ,它在js ajax请求数据,进行tab切换,就连总共有多少章,它都是页面加载出来之后ajax请求回来的
,它在js ajax请求数据,进行tab切换,就连总共有多少章,它都是页面加载出来之后ajax请求回来的

看一下他的请求头跟参数
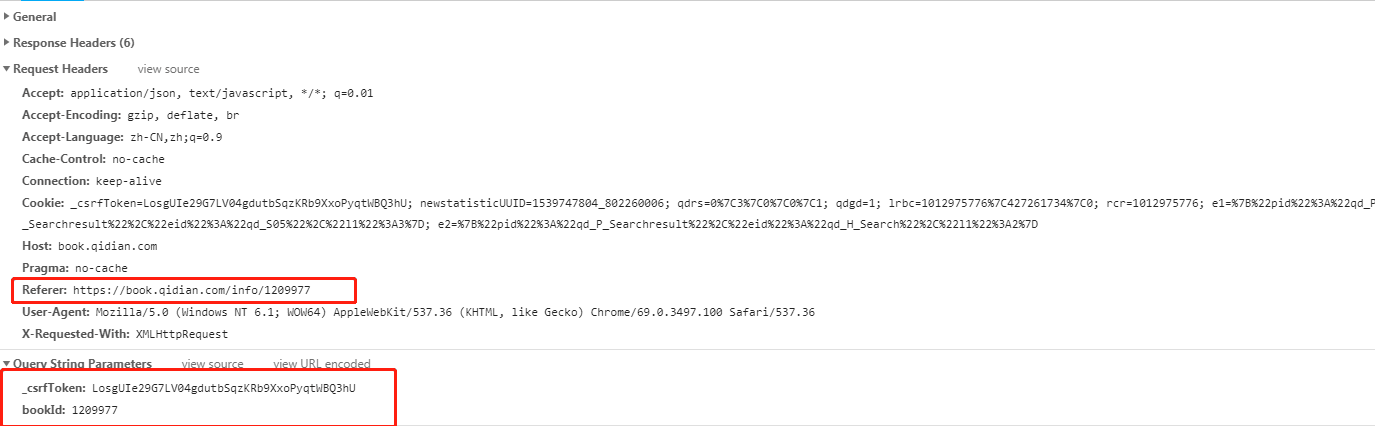
只要我们弄懂_csrfToken参数就可以构造一个get请求  https://book.qidian.com/ajax/book/category?_csrfToken=LosgUIe29G7LV04gdutbSqzKRb9XxoPyqtWBQ3hU&bookId=1209977
https://book.qidian.com/ajax/book/category?_csrfToken=LosgUIe29G7LV04gdutbSqzKRb9XxoPyqtWBQ3hU&bookId=1209977
https://read.qidian.com/chapter/2R9G_ziBVg41/MyEcwtk5i8Iex0RJOkJclQ2cN章节名称
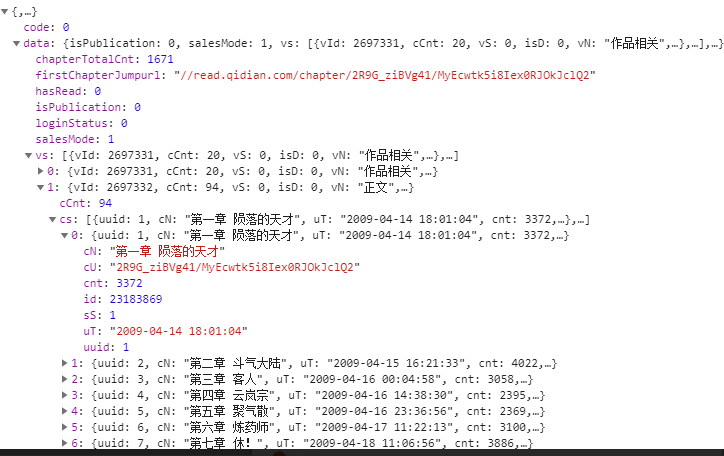
 ,
,
同样的,大部分逻辑都写在注释里面,相信大家都看得懂:
maven引包:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.9</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
书实体类:
/**
* 书对象
*/
@Data
public class Book { /**
* 链接
*/
private String bookUrl; /**
* 书名
*/
private String bookName; /**
* 作者
*/
private String author; /**
* 简介
*/
private String synopsis; /**
* 图片
*/
private String img; /**
* 章节目录 chapterName、url
*/
private List<Map<String,String>> chapters; /**
* 状态
*/
private String status; /**
* 类型
*/
private String type; /**
* 更新时间
*/
private String updateDate; /**
* 第一章
*/
private String firstChapter; /**
* 第一章链接
*/
private String firstChapterUrl; /**
* 上一章节
*/
private String prevChapter; /**
* 上一章节链接
*/
private String prevChapterUrl; /**
* 当前章节名称
*/
private String nowChapter; /**
* 当前章节内容
*/
private String nowChapterValue; /**
* 当前章节链接
*/
private String nowChapterUrl; /**
* 下一章节
*/
private String nextChapter; /**
* 下一章节链接
*/
private String nextChapterUrl; /**
* 最新章节
*/
private String latestChapter; /**
* 最新章节链接
*/
private String latestChapterUrl; /**
* 大小
*/
private String magnitude; /**
* 来源
*/
private Map<String,String> source;
private String sourceKey;
}
小工具类:
/**
* 小工具类
*/
public class BookUtil { /**
* 自动注入参数
* 例如:
*
* @param src http://search.zongheng.com/s?keyword=#1&pageNo=#2&sort=
* @param params "斗破苍穹","1"
* @return http://search.zongheng.com/s?keyword=斗破苍穹&pageNo=1&sort=
*/
public static String insertParams(String src, String... params) {
int i = 1;
for (String param : params) {
src = src.replaceAll("#" + i, param);
i++;
}
return src;
} /**
* 采集当前url完整response实体.toString()
*
* @param url url
* @return response实体.toString()
*/
public static String gather(String url, String refererUrl) {
String result = null;
try {
//创建httpclient对象 (这里设置成全局变量,相对于同一个请求session、cookie会跟着携带过去)
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建get方式请求对象
HttpGet httpGet = new HttpGet(url);
httpGet.addHeader("Content-type", "application/json");
//包装一下
httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36");
httpGet.addHeader("Referer", refererUrl);
httpGet.addHeader("Connection", "keep-alive"); //通过请求对象获取响应对象
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取结果实体
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
result = EntityUtils.toString(response.getEntity(), "GBK");
} //释放链接
response.close();
}
//这里还可以捕获超时异常,重新连接抓取
catch (Exception e) {
result = null;
System.err.println("采集操作出错");
e.printStackTrace();
}
return result;
}
}
Controller层:
/**
* Book Controller层
*/
@RestController
@RequestMapping("book")
public class BookContrller { /**
* 来源集合
*/
private static Map<String, Map<String, String>> source = new HashMap<>(); static {
//笔趣阁
source.put("biquge", BookHandler_biquge.biquge); //纵横中文网
source.put("zongheng", BookHandler_zongheng.zongheng); //起点中文网
source.put("qidian", BookHandler_qidian.qidian);
} /**
* 访问首页
*/
@GetMapping("/index")
public ModelAndView index() {
return new ModelAndView("book_index.html");
} /**
* 搜索书名
*/
@GetMapping("/search")
public ModelAndView search(Book book) {
//结果集
ArrayList<Book> books = new ArrayList<>();
//关键字
String keyWord = book.getBookName();
//来源
String sourceKey = book.getSourceKey(); //获取来源详情
Map<String, String> src = source.get(sourceKey); // 编码
try {
keyWord = URLEncoder.encode(keyWord, src.get("UrlEncode"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
//searchUrl
src.put("searchUrl", BookUtil.insertParams(src.get("searchUrl"), keyWord, "1")); //调用不同的方法
switch (sourceKey) {
case "biquge":
BookHandler_biquge.book_search_biquge(books, src, keyWord);
break;
case "zongheng":
BookHandler_zongheng.book_search_zongheng(books, src, keyWord);
break;
case "qidian":
BookHandler_qidian.book_search_qidian(books, src, keyWord);
break;
default:
//默认所有都查
BookHandler_biquge.book_search_biquge(books, src, keyWord);
BookHandler_zongheng.book_search_zongheng(books, src, keyWord);
BookHandler_qidian.book_search_qidian(books, src, keyWord);
break;
} System.out.println(books.size());
ModelAndView modelAndView = new ModelAndView("book_list.html", "books", books);
try {
modelAndView.addObject("keyWord", URLDecoder.decode(keyWord, src.get("UrlEncode")));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
modelAndView.addObject("sourceKey", sourceKey);
return modelAndView;
} /**
* 访问书本详情
*/
@GetMapping("/details")
public ModelAndView details(String sourceKey,String bookUrl,String searchUrl) {
Map<String, String> src = source.get(sourceKey);
src.put("searchUrl",searchUrl);
Book book = new Book();
//调用不同的方法
switch (sourceKey) {
case "biquge":
book = BookHandler_biquge.book_details_biquge(src, bookUrl);
break;
case "zongheng":
book = BookHandler_zongheng.book_details_zongheng(src, bookUrl);
break;
case "qidian":
book = BookHandler_qidian.book_details_qidian(src, bookUrl);
break;
default:
break;
}
return new ModelAndView("book_details.html", "book", book);
} /**
* 访问书本章节
*/
@GetMapping("/read")
public ModelAndView read(String sourceKey,String chapterUrl,String refererUrl) {
Map<String, String> src = source.get(sourceKey);
Book book = new Book();
//调用不同的方法
switch (sourceKey) {
case "biquge":
book = BookHandler_biquge.book_read_biquge(src, chapterUrl,refererUrl);
break;
case "zongheng":
book = BookHandler_zongheng.book_read_zongheng(src, chapterUrl,refererUrl);
break;
case "qidian":
book = BookHandler_qidian.book_read_qidian(src, chapterUrl,refererUrl);
break;
default:
break;
}
return new ModelAndView("book_read.html", "book", book);
}
}
三个不同来源的Handler处理器,每个来源都有不同的采集规则:
BookHandler_biquge
/**
* 笔趣阁采集规则
*/
public class BookHandler_biquge { /**
* 来源信息
*/
public static HashMap<String, String> biquge = new HashMap<>(); static {
//笔趣阁
biquge.put("name", "笔趣阁");
biquge.put("key", "biquge");
biquge.put("baseUrl", "http://www.biquge.com.tw");
biquge.put("baseSearchUrl", "http://www.biquge.com.tw/modules/article/soshu.php");
biquge.put("UrlEncode", "GB2312");
biquge.put("searchUrl", "http://www.biquge.com.tw/modules/article/soshu.php?searchkey=+#1&page=#2");
} /**
* 获取search list 笔趣阁采集规则
*
* @param books 结果集合
* @param src 源目标
* @param keyWord 关键字
*/
public static void book_search_biquge(ArrayList<Book> books, Map<String, String> src, String keyWord) {
//采集术
String html = BookUtil.gather(src.get("searchUrl"), src.get("baseUrl"));
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); //当前页集合
Elements resultList = doc.select("table.grid tr#nr");
for (Element result : resultList) {
Book book = new Book();
//书本链接
book.setBookUrl(result.child(0).select("a").attr("href"));
//书名
book.setBookName(result.child(0).select("a").text());
//作者
book.setAuthor(result.child(2).text());
//更新时间
book.setUpdateDate(result.child(4).text());
//最新章节
book.setLatestChapter(result.child(1).select("a").text());
book.setLatestChapterUrl(result.child(1).select("a").attr("href"));
//状态
book.setStatus(result.child(5).text());
//大小
book.setMagnitude(result.child(3).text());
//来源
book.setSource(src);
books.add(book);
} //下一页
Elements searchNext = doc.select("div.pages > a.ngroup");
String href = searchNext.attr("href");
if (!StringUtils.isEmpty(href)) {
src.put("baseUrl", src.get("searchUrl"));
src.put("searchUrl", href.contains("http") ? href : (src.get("baseSearchUrl") + href));
book_search_biquge(books, src, keyWord);
} } catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
} /**
* 获取书本详情 笔趣阁采集规则
* @param src 源目标
* @param bookUrl 书本链接
* @return Book对象
*/
public static Book book_details_biquge(Map<String, String> src, String bookUrl) {
Book book = new Book();
//采集术
String html = BookUtil.gather(bookUrl, src.get("searchUrl"));
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html);
//书本链接
book.setBookUrl(doc.select("meta[property=og:url]").attr("content"));
//图片
book.setImg(doc.select("meta[property=og:image]").attr("content"));
//书名
book.setBookName(doc.select("div#info > h1").text());
//作者
book.setAuthor(doc.select("meta[property=og:novel:author]").attr("content"));
//更新时间
book.setUpdateDate(doc.select("meta[property=og:novel:update_time]").attr("content"));
//最新章节
book.setLatestChapter(doc.select("meta[property=og:novel:latest_chapter_name]").attr("content"));
book.setLatestChapterUrl(doc.select("meta[property=og:novel:latest_chapter_url]").attr("content"));
//类型
book.setType(doc.select("meta[property=og:novel:category]").attr("content"));
//简介
book.setSynopsis(doc.select("meta[property=og:description]").attr("content"));
//状态
book.setStatus(doc.select("meta[property=og:novel:status]").attr("content")); //章节目录
ArrayList<Map<String, String>> chapters = new ArrayList<>();
for (Element result : doc.select("div#list dd")) {
HashMap<String, String> map = new HashMap<>();
map.put("chapterName", result.select("a").text());
map.put("url", result.select("a").attr("href"));
chapters.add(map);
}
book.setChapters(chapters); //来源
book.setSource(src); } catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
return book;
} /**
* 得到当前章节名以及完整内容跟上、下一章的链接地址 笔趣阁采集规则
* @param src 源目标
* @param chapterUrl 当前章节链接
* @param refererUrl 来源链接
* @return Book对象
*/
public static Book book_read_biquge(Map<String, String> src,String chapterUrl,String refererUrl) {
Book book = new Book(); //当前章节链接
book.setNowChapterUrl(chapterUrl.contains("http") ? chapterUrl : (src.get("baseUrl") + chapterUrl)); //采集术
String html = BookUtil.gather(book.getNowChapterUrl(), refererUrl);
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); //当前章节名称
book.setNowChapter(doc.select("div.box_con > div.bookname > h1").text()); //删除图片广告
doc.select("div.box_con > div#content img").remove();
//当前章节内容
book.setNowChapterValue(doc.select("div.box_con > div#content").outerHtml()); //上、下一章
book.setPrevChapter(doc.select("div.bottem2 a:matches((?i)下一章)").text());
book.setPrevChapterUrl(doc.select("div.bottem2 a:matches((?i)下一章)").attr("href"));
book.setNextChapter(doc.select("div.bottem2 a:matches((?i)上一章)").text());
book.setNextChapterUrl(doc.select("div.bottem2 a:matches((?i)上一章)").attr("href")); //来源
book.setSource(src); } catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
return book;
}
}
BookHandler_zongheng
/**
* 纵横中文网采集规则
*/
public class BookHandler_zongheng { /**
* 来源信息
*/
public static HashMap<String, String> zongheng = new HashMap<>(); static {
//纵横中文网
zongheng.put("name", "纵横中文网");
zongheng.put("key", "zongheng");
zongheng.put("baseUrl", "http://www.zongheng.com");
zongheng.put("baseSearchUrl", "http://search.zongheng.com/s");
zongheng.put("UrlEncode", "UTF-8");
zongheng.put("searchUrl", "http://search.zongheng.com/s?keyword=#1&pageNo=#2&sort=");
} /**
* 获取search list 纵横中文网采集规则
*
* @param books 结果集合
* @param src 源目标
* @param keyWord 关键字
*/
public static void book_search_zongheng(ArrayList<Book> books, Map<String, String> src, String keyWord) {
//采集术
String html = BookUtil.gather(src.get("searchUrl"), src.get("baseUrl"));
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); //当前页集合
Elements resultList = doc.select("div.search-tab > div.search-result-list");
for (Element result : resultList) {
Book book = new Book();
//书本链接
book.setBookUrl(result.select("div.imgbox a").attr("href"));
//图片
book.setImg(result.select("div.imgbox img").attr("src"));
//书名
book.setBookName(result.select("h2.tit").text());
//作者
book.setAuthor(result.select("div.bookinfo > a").first().text());
//类型
book.setType(result.select("div.bookinfo > a").last().text());
//简介
book.setSynopsis(result.select("p").text());
//状态
book.setStatus(result.select("div.bookinfo > span").first().text());
//大小
book.setMagnitude(result.select("div.bookinfo > span").last().text());
//来源
book.setSource(src);
books.add(book);
} //下一页
Elements searchNext = doc.select("div.search_d_pagesize > a.search_d_next");
String href = searchNext.attr("href");
//最多只要888本,不然太慢了
if (books.size() < 888 && !StringUtils.isEmpty(href)) {
src.put("baseUrl", src.get("searchUrl"));
src.put("searchUrl", href.contains("http") ? href : (src.get("baseSearchUrl") + href));
book_search_zongheng(books, src, keyWord);
} } catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
} /**
* 获取书本详情 纵横中文网采集规则
* @param src 源目标
* @param bookUrl 书本链接
* @return Book对象
*/
public static Book book_details_zongheng(Map<String, String> src, String bookUrl) {
Book book = new Book();
//采集术
String html = BookUtil.gather(bookUrl, src.get("searchUrl"));
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); //书本链接
book.setBookUrl(bookUrl);
//图片
book.setImg(doc.select("div.book-img > img").attr("src"));
//书名
book.setBookName(doc.select("div.book-info > div.book-name").text());
//作者
book.setAuthor(doc.select("div.book-author div.au-name").text());
//更新时间
book.setUpdateDate(doc.select("div.book-new-chapter div.time").text());
//最新章节
book.setLatestChapter(doc.select("div.book-new-chapter div.tit a").text());
book.setLatestChapterUrl(doc.select("div.book-new-chapter div.tit a").attr("href"));
//类型
book.setType(doc.select("div.book-label > a").last().text());
//简介
book.setSynopsis(doc.select("div.book-dec > p").text());
//状态
book.setStatus(doc.select("div.book-label > a").first().text()); //章节目录
String chaptersUrl = doc.select("a.all-catalog").attr("href");
ArrayList<Map<String, String>> chapters = new ArrayList<>();
//采集术
for (Element result : Jsoup.parse(BookUtil.gather(chaptersUrl, bookUrl)).select("ul.chapter-list li")) {
HashMap<String, String> map = new HashMap<>();
map.put("chapterName", result.select("a").text());
map.put("url", result.select("a").attr("href"));
chapters.add(map);
}
book.setChapters(chapters);
//来源
book.setSource(src);
} catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
return book;
} /**
* 得到当前章节名以及完整内容跟上、下一章的链接地址 纵横中文网采集规则
* @param src 源目标
* @param chapterUrl 当前章节链接
* @param refererUrl 来源链接
* @return Book对象
*/
public static Book book_read_zongheng(Map<String, String> src,String chapterUrl,String refererUrl) {
Book book = new Book(); //当前章节链接
book.setNowChapterUrl(chapterUrl.contains("http") ? chapterUrl : (src.get("baseUrl") + chapterUrl)); //采集术
String html = BookUtil.gather(book.getNowChapterUrl(), refererUrl);
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); //当前章节名称
book.setNowChapter(doc.select("div.title_txtbox").text()); //删除图片广告
doc.select("div.content img").remove();
//当前章节内容
book.setNowChapterValue(doc.select("div.content").outerHtml()); //上、下一章
book.setPrevChapter(doc.select("div.chap_btnbox a:matches((?i)下一章)").text());
book.setPrevChapterUrl(doc.select("div.chap_btnbox a:matches((?i)下一章)").attr("href"));
book.setNextChapter(doc.select("div.chap_btnbox a:matches((?i)上一章)").text());
book.setNextChapterUrl(doc.select("div.chap_btnbox a:matches((?i)上一章)").attr("href")); //来源
book.setSource(src); } catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
return book;
}
}
BookHandler_qidian
/**
* 起点中文网采集规则
*/
public class BookHandler_qidian { /**
* 来源信息
*/
public static HashMap<String, String> qidian = new HashMap<>(); static {
//起点中文网
qidian.put("name", "起点中文网");
qidian.put("key", "qidian");
qidian.put("baseUrl", "http://www.qidian.com");
qidian.put("baseSearchUrl", "https://www.qidian.com/search");
qidian.put("UrlEncode", "UTF-8");
qidian.put("searchUrl", "https://www.qidian.com/search?kw=#1&page=#2");
} /**
* 获取search list 起点中文网采集规则
*
* @param books 结果集合
* @param src 源目标
* @param keyWord 关键字
*/
public static void book_search_qidian(ArrayList<Book> books, Map<String, String> src, String keyWord) {
//采集术
String html = BookUtil.gather(src.get("searchUrl"), src.get("baseUrl"));
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); //当前页集合
Elements resultList = doc.select("li.res-book-item");
for (Element result : resultList) {
Book book = new Book();
/*
如果大家打断点在这里的话就会发现,起点的链接是这样的
//book.qidian.com/info/1012786368 以两个斜杠开头,不过无所谓,httpClient照样可以请求
*/
//书本链接
book.setBookUrl(result.select("div.book-img-box a").attr("href"));
//图片
book.setImg(result.select("div.book-img-box img").attr("src"));
//书名
book.setBookName(result.select("div.book-mid-info > h4").text());
//作者
book.setAuthor(result.select("div.book-mid-info > p.author > a").first().text());
//类型
book.setType(result.select("div.book-mid-info > p.author > a").last().text());
//简介
book.setSynopsis(result.select("div.book-mid-info > p.intro").text());
//状态
book.setStatus(result.select("div.book-mid-info > p.author > span").first().text());
//更新时间
book.setUpdateDate(result.select("div.book-mid-info > p.update > span").text());
//最新章节
book.setLatestChapter(result.select("div.book-mid-info > p.update > a").text());
book.setLatestChapterUrl(result.select("div.book-mid-info > p.update > a").attr("href"));
//来源
book.setSource(src);
books.add(book);
} //当前页
String page = doc.select("div#page-container").attr("data-page"); //最大页数
String pageMax = doc.select("div#page-container").attr("data-pageMax"); //当前页 < 最大页数
if (Integer.valueOf(page) < Integer.valueOf(pageMax)) {
src.put("baseUrl", src.get("searchUrl"));
//自己拼接下一页链接
src.put("searchUrl", src.get("searchUrl").replaceAll("page=" + Integer.valueOf(page), "page=" + (Integer.valueOf(page) + 1)));
book_search_qidian(books, src, keyWord);
} } catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
} /**
* 获取书本详情 起点中文网采集规则
* @param src 源目标
* @param bookUrl 书本链接
* @return Book对象
*/
public static Book book_details_qidian(Map<String, String> src, String bookUrl) {
Book book = new Book(); //https
bookUrl = "https:" + bookUrl; //采集术
String html = BookUtil.gather(bookUrl, src.get("searchUrl"));
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); //书本链接
book.setBookUrl(bookUrl);
//图片
String img = doc.select("div.book-img > a#bookImg > img").attr("src");
img = "https:" + img;
book.setImg(img);
//书名
book.setBookName(doc.select("div.book-info > h1 > em").text());
//作者
book.setAuthor(doc.select("div.book-info > h1 a.writer").text());
//更新时间
book.setUpdateDate(doc.select("li.update em.time").text());
//最新章节
book.setLatestChapter(doc.select("li.update a").text());
book.setLatestChapterUrl(doc.select("li.update a").attr("href"));
//类型
book.setType(doc.select("p.tag > span").first().text());
//简介
book.setSynopsis(doc.select("div.book-intro > p").text());
//状态
book.setStatus(doc.select("p.tag > a").first().text()); //章节目录 //创建httpclient对象 (这里设置成全局变量,相对于同一个请求session、cookie会跟着携带过去)
BasicCookieStore cookieStore = new BasicCookieStore();
CloseableHttpClient httpClient = HttpClients.custom().setDefaultCookieStore(cookieStore).build();
//创建get方式请求对象
HttpGet httpGet = new HttpGet("https://book.qidian.com/");
httpGet.addHeader("Content-type", "application/json");
//包装一下
httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36");
httpGet.addHeader("Connection", "keep-alive");
//通过请求对象获取响应对象
CloseableHttpResponse response = httpClient.execute(httpGet);
//获得Cookies
String _csrfToken = "";
List<Cookie> cookies = cookieStore.getCookies();
for (int i = 0; i < cookies.size(); i++) {
if("_csrfToken".equals(cookies.get(i).getName())){
_csrfToken = cookies.get(i).getValue();
}
} //构造post
String bookId = doc.select("div.book-img a#bookImg").attr("data-bid");
HttpPost httpPost = new HttpPost(BookUtil.insertParams("https://book.qidian.com/ajax/book/category?_csrfToken=#1&bookId=#2",_csrfToken,bookId));
httpPost.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36");
httpPost.addHeader("Connection", "keep-alive");
//通过请求对象获取响应对象
CloseableHttpResponse response1 = httpClient.execute(httpPost);
//获取结果实体(json格式字符串)
String chaptersJson = "";
if (response1.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
chaptersJson = EntityUtils.toString(response1.getEntity(), "UTF-8");
} //java处理json
ArrayList<Map<String, String>> chapters = new ArrayList<>(); JSONObject jsonArray = JSONObject.fromObject(chaptersJson);
Map<String,Object> objectMap = (Map<String, Object>) jsonArray; Map<String, Object> objectMap_data = (Map<String, Object>) objectMap.get("data");
List<Map<String, Object>> objectMap_data_vs = (List<Map<String, Object>>) objectMap_data.get("vs");
for(Map<String, Object> vs : objectMap_data_vs){
List<Map<String, Object>> cs = (List<Map<String, Object>>) vs.get("cs");
for(Map<String, Object> chapter : cs){
Map<String, String> map = new HashMap<>();
map.put("chapterName", (String) chapter.get("cN"));
map.put("url", "https://read.qidian.com/chapter/"+(String) chapter.get("cU"));
chapters.add(map);
}
} book.setChapters(chapters); //来源
book.setSource(src); //释放链接
response.close();
} catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
return book;
} /**
* 得到当前章节名以及完整内容跟上、下一章的链接地址 起点中文网采集规则
* @param src 源目标
* @param chapterUrl 当前章节链接
* @param refererUrl 来源链接
* @return Book对象
*/
public static Book book_read_qidian(Map<String, String> src,String chapterUrl,String refererUrl) {
Book book = new Book(); //当前章节链接
book.setNowChapterUrl(chapterUrl.contains("http") ? chapterUrl : (src.get("baseUrl") + chapterUrl)); //采集术
String html = BookUtil.gather(book.getNowChapterUrl(), refererUrl);
try {
//解析html格式的字符串成一个Document
Document doc = Jsoup.parse(html); System.out.println(html); //当前章节名称
book.setNowChapter(doc.select("h3.j_chapterName").text()); //删除图片广告
doc.select("div.read-content img").remove();
//当前章节内容
book.setNowChapterValue(doc.select("div.read-content").outerHtml()); //上、下一章
book.setPrevChapter(doc.select("div.chapter-control a:matches((?i)下一章)").text());
String prev = doc.select("div.chapter-control a:matches((?i)下一章)").attr("href");
prev = "https:"+prev;
book.setPrevChapterUrl(prev);
book.setNextChapter(doc.select("div.chapter-control a:matches((?i)上一章)").text());
String next = doc.select("div.chapter-control a:matches((?i)上一章)").attr("href");
next = "https:"+next;
book.setNextChapterUrl(next); //来源
book.setSource(src); } catch (Exception e) {
System.err.println("采集数据操作出错");
e.printStackTrace();
}
return book;
}
}
四个html页面:
book_index
<!DOCTYPE html>
<!--解决idea thymeleaf 表达式模板报红波浪线-->
<!--suppress ALL -->
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>MY BOOK</title>
<!-- 新 Bootstrap 核心 CSS 文件 -->
<link rel="stylesheet" href="http://cdn.static.runoob.com/libs/bootstrap/3.3.7/css/bootstrap.min.css">
<style> body{
background-color: antiquewhite;
} .main{
margin: auto;
width: 500px;
margin-top: 150px;
} #bookName{
width: 300px;
} #title{
text-align: center;
}
</style>
</head>
<body>
<div class="main">
<h2 id="title">MY BOOK</h2>
<form class="form-inline" method="get" th:action="@{/book/search}">
来源
<select class="form-control" id="source" name="sourceKey">
<option value="">所有</option>
<option value="biquge">笔趣阁</option>
<option value="zongheng">纵横网</option>
<option value="qidian">起点网</option>
</select>
<input type="text" id="bookName" name="bookName" class="form-control" placeholder="请输入..."/>
<button class="btn btn-info" type="submit">搜索</button>
</form>
</div>
</body>
</html>
book_list
<!DOCTYPE html>
<!--解决idea thymeleaf 表达式模板报红波浪线-->
<!--suppress ALL -->
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>BOOK LIST</title>
<!-- 新 Bootstrap 核心 CSS 文件 -->
<link rel="stylesheet" href="http://cdn.static.runoob.com/libs/bootstrap/3.3.7/css/bootstrap.min.css">
<link rel="stylesheet" href="http://hanlei.online/Onlineaddress/layui/css/layui.css"/>
<style>
body {
background-color: antiquewhite;
} .main {
margin: auto;
width: 500px;
margin-top: 50px;
} .book {
border-bottom: solid #428bca 1px;
} .click-book-detail, .click-book-read {
cursor: pointer;
color: #428bca;
} .click-book-detail:hover {
color: rgba(150, 149, 162, 0.47);
} .click-book-read:hover {
color: rgba(150, 149, 162, 0.47);
}
</style>
</head>
<body>
<div class="main">
<form class="form-inline" method="get" th:action="@{/book/search}">
来源
<select class="form-control" id="source" name="sourceKey">
<option value="">所有</option>
<option value="biquge" th:selected="${sourceKey} == 'biquge'">笔趣阁</option>
<option value="zongheng" th:selected="${sourceKey} == 'zongheng'">纵横网</option>
<option value="qidian" th:selected="${sourceKey} == 'qidian'">起点网</option>
</select>
<input type="text" id="bookName" name="bookName" class="form-control" placeholder="请输入..."
th:value="${keyWord}"/>
<button class="btn btn-info" type="submit">搜索</button>
</form>
<br/>
<div id="books"></div>
<div id="page"></div>
</div>
</body>
<!-- jquery在线版本 -->
<script src="http://libs.baidu.com/jquery/2.1.4/jquery.min.js"></script>
<script src="http://hanlei.online/Onlineaddress/layui/layui.js"></script>
<script th:inline="javascript">
var ctx = /*[[@{/}]]*/'';
var books = [[${books}]];//取出后台数据
var nums = 10; //每页出现的数量
var pages = books.length; //总数 /**
* 传入当前页,根据nums去计算,从books集合截取对应数据做展示
*/
var thisDate = function (curr) {
var str = "",//当前页需要展示的html
first = (curr * nums - nums),//展示的第一条数据的下标
last = curr * nums - 1;//展示的最后一条数据的下标
last = last >= books.length ? (books.length - 1) : last;
for (var i = first; i <= last; i++) {
var book = books[i];
str += "<div class='book'>" +
"<img class='click-book-detail' data-bookurl='" + book.bookUrl + "' data-sourcekey='" + book.source.key + "' data-searchurl='" + book.source.searchUrl + "' src='" + book.img + "'></img>" +
"<p class='click-book-detail' data-bookurl='" + book.bookUrl + "' data-sourcekey='" + book.source.key + "' data-searchurl='" + book.source.searchUrl + "'>书名:" + book.bookName + "</p>" +
"<p>作者:" + book.author + "</p>" +
"<p>简介:" + book.synopsis + "</p>" +
"<p class='click-book-read' data-chapterurl='" + book.latestChapterUrl + "' data-sourcekey='" + book.source.key + "' data-refererurl='" + book.source.refererurl + "'>最新章节:" + book.latestChapter + "</p>" +
"<p>更新时间:" + book.updateDate + "</p>" +
"<p>大小:" + book.magnitude + "</p>" +
"<p>状态:" + book.status + "</p>" +
"<p>类型:" + book.type + "</p>" +
"<p>来源:" + book.source.name + "</p>" +
"</div><br/>";
}
return str;
}; //获取一个laypage实例
layui.use('laypage', function () {
var laypage = layui.laypage; //调用laypage 逻辑分页
laypage.render({
elem: 'page',
count: pages,
limit: nums,
jump: function (obj) {
//obj包含了当前分页的所有参数,比如:
// console.log(obj.curr); //得到当前页,以便向服务端请求对应页的数据。
// console.log(obj.limit); //得到每页显示的条数
document.getElementById('books').innerHTML = thisDate(obj.curr);
},
prev: '<',
next: '>',
theme: '#f9c357',
})
}); $("body").on("click", ".click-book-detail", function (even) {
var bookUrl = $(this).data("bookurl");
var searchUrl = $(this).data("searchurl");
var sourceKey = $(this).data("sourcekey");
window.location.href = ctx + "/book/details?sourceKey=" + sourceKey + "&searchUrl=" + searchUrl + "&bookUrl=" + bookUrl;
});
$("body").on("click", ".click-book-read", function (even) {
var chapterUrl = $(this).data("chapterurl");
var refererUrl = $(this).data("refererurl");
var sourceKey = $(this).data("sourcekey");
window.location.href = ctx + "/book/read?sourceKey=" + sourceKey + "&refererUrl=" + refererUrl + "&chapterUrl=" + chapterUrl;
});
</script>
</html>
book_details
<!DOCTYPE html>
<!--解决idea thymeleaf 表达式模板报红波浪线-->
<!--suppress ALL -->
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>BOOK DETAILS</title>
<!-- 新 Bootstrap 核心 CSS 文件 -->
<link rel="stylesheet" href="http://cdn.static.runoob.com/libs/bootstrap/3.3.7/css/bootstrap.min.css">
<link rel="stylesheet" href="http://hanlei.online/Onlineaddress/layui/css/layui.css"/>
<style>
body {
background-color: antiquewhite;
} .main {
margin: auto;
width: 500px;
margin-top: 150px;
} .book {
border-bottom: solid #428bca 1px;
} .click-book-detail, .click-book-read {
cursor: pointer;
color: #428bca;
} .click-book-detail:hover {
color: rgba(150, 149, 162, 0.47);
} .click-book-read:hover {
color: rgba(150, 149, 162, 0.47);
} a {
color: #428bca;
} </style>
</head>
<body>
<div class="main">
<div class='book'>
<div id="bookImg"></div>
<p>书名:<span th:text="${book.bookName}"></span></p>
<p>作者:<span th:text="${book.author}"></span></p>
<p>简介:<span th:text="${book.synopsis}"></span></p>
<p>最新章节:<a th:href="${book.latestChapterUrl}" th:text="${book.latestChapter}"></a></p>
<p>更新时间:<span th:text="${book.updateDate}"></span></p>
<p>大小:<span th:text="${book.magnitude}"></span></p>
<p>状态:<span th:text="${book.status}"></span></p>
<p>类型:<span th:text="${book.type}"></span></p>
<p>来源:<span th:text="${book.source.name}"></span></p>
</div>
<br/>
<div class="chapters" th:each="chapter,iterStat:${book.chapters}">
<p class="click-book-read" th:attr="data-chapterurl=${chapter.url},data-sourcekey=${book.source.key},data-refererurl=${book.bookUrl}" th:text="${chapter.chapterName}"></p>
</div>
</div>
</body>
<!-- jquery在线版本 -->
<script src="http://libs.baidu.com/jquery/2.1.4/jquery.min.js"></script>
<script th:inline="javascript">
var ctx = /*[[@{/}]]*/'';
var book = [[${book}]];//取出后台数据 /**
* 反防盗链
*/
function showImg(parentObj, url) {
//来一个随机数
var frameid = 'frameimg' + Math.random();
//放在(父页面)window里面 iframe的script标签里面绑定了window.onload,作用:设置iframe的高度、宽度 <script>window.onload = function() { parent.document.getElementById(\'' + frameid + '\').height = document.getElementById(\'img\').height+\'px\'; }<' + '/script>
window.img = '<img src=\'' + url + '?' + Math.random() + '\'/>';
//iframe调用parent.img
$(parentObj).append('<iframe id="' + frameid + '" src="javascript:parent.img;" frameBorder="0" scrolling="no"></iframe>');
} showImg($("#bookImg"), book.img); $("body").on("click", ".click-book-read", function (even) {
var chapterUrl = $(this).data("chapterurl");
var refererUrl = $(this).data("refererurl");
var sourceKey = $(this).data("sourcekey");
window.location.href = ctx + "/book/read?sourceKey=" + sourceKey + "&refererUrl=" + refererUrl + "&chapterUrl=" + chapterUrl;
}); </script>
</html>
book_read
<!DOCTYPE html>
<!--解决idea thymeleaf 表达式模板报红波浪线-->
<!--suppress ALL -->
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>BOOK READ</title>
<style>
body {
background-color: antiquewhite;
} .main {
padding: 10px 20px;
} .click-book-detail, .click-book-read {
cursor: pointer;
color: #428bca;
} .click-book-detail:hover {
color: rgba(150, 149, 162, 0.47);
} .click-book-read:hover {
color: rgba(150, 149, 162, 0.47);
} .float-left{
float: left;
margin-left: 70px;
}
</style>
</head>
<body>
<div class="main">
<!-- 章节名称 -->
<h3 th:text="${book.nowChapter}"></h3>
<!-- 章节内容 -->
<p th:utext="${book.nowChapterValue}"></p>
<!-- 上、下章 -->
<p class="click-book-read float-left"
th:attr="data-chapterurl=${book.nextChapterUrl},data-sourcekey=${book.source.key},data-refererurl=${book.nowChapterUrl}"
th:text="${book.nextChapter}"></p>
<p class="click-book-read float-left"
th:attr="data-chapterurl=${book.prevChapterUrl},data-sourcekey=${book.source.key},data-refererurl=${book.nowChapterUrl}"
th:text="${book.prevChapter}"></p>
</div>
</body>
<!-- jquery在线版本 -->
<script src="http://libs.baidu.com/jquery/2.1.4/jquery.min.js"></script>
<script th:inline="javascript">
var ctx = /*[[@{/}]]*/'';
$("body").on("click", ".click-book-read", function (even) {
var chapterUrl = $(this).data("chapterurl");
var refererUrl = $(this).data("refererurl");
var sourceKey = $(this).data("sourcekey");
window.location.href = ctx + "/book/read?sourceKey=" + sourceKey + "&refererUrl=" + refererUrl + "&chapterUrl=" + chapterUrl;
});
</script>
</html>
补充
2019-07-17补充:我们之前三个来源网站的baseUrl都是用http,但网站后面都升级成了https,例如笔趣阁:
导致抓取数据时报错
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.ssl.Alerts.getSSLException(Alerts.java:192)
at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1949)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:302)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:296)
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1514)
at sun.security.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:216)
at sun.security.ssl.Handshaker.processLoop(Handshaker.java:1026)
at sun.security.ssl.Handshaker.process_record(Handshaker.java:961)
at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1062)
at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1375)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1403)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1387)
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.createLayeredSocket(SSLConnectionSocketFactory.java:396)
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.connectSocket(SSLConnectionSocketFactory.java:355)
at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:142)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:373)
at org.apache.http.impl.execchain.MainClientExec.establishRoute(MainClientExec.java:381)
at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:237)
at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:185)
at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89)
at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:111)
at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83)
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:108)
at cn.huanzi.qch.spider.novelreading.util.BookUtil.gather(BookUtil.java:81)
at cn.huanzi.qch.spider.novelreading.pojo.BookHandler_biquge.book_search_biquge(BookHandler_biquge.java:43)
at cn.huanzi.qch.spider.novelreading.controller.BookContrller.search(BookContrller.java:78)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:215)
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:142)
at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:102)
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:895)
at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:800)
at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1038)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:942)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:998)
at org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:890)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:634)
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:875)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:741)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:231)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:99)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:92)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.springframework.web.filter.HiddenHttpMethodFilter.doFilterInternal(HiddenHttpMethodFilter.java:93)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:200)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:199)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96)
at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:490)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:139)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:74)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:343)
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:408)
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66)
at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:770)
at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1415)
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:748)
解决办法:参考https://blog.csdn.net/xiaoxian8023/article/details/49865335,绕过证书验证
在BookUtil.java中新增方法
/**
* 绕过SSL验证
*/
private static SSLContext createIgnoreVerifySSL() throws NoSuchAlgorithmException, KeyManagementException {
SSLContext sc = SSLContext.getInstance("SSLv3"); // 实现一个X509TrustManager接口,用于绕过验证,不用修改里面的方法
X509TrustManager trustManager = new X509TrustManager() {
@Override
public void checkClientTrusted(
java.security.cert.X509Certificate[] paramArrayOfX509Certificate,
String paramString) throws CertificateException {
} @Override
public void checkServerTrusted(
java.security.cert.X509Certificate[] paramArrayOfX509Certificate,
String paramString) throws CertificateException {
} @Override
public java.security.cert.X509Certificate[] getAcceptedIssuers() {
return null;
}
}; sc.init(null, new TrustManager[]{trustManager}, null);
return sc;
}
然后在gather方法中改成这样获取httpClient
/**
* 采集当前url完整response实体.toString()
*
* @param url url
* @return response实体.toString()
*/
public static String gather(String url, String refererUrl) {
String result = null;
try {
//采用绕过验证的方式处理https请求
SSLContext sslcontext = createIgnoreVerifySSL(); // 设置协议http和https对应的处理socket链接工厂的对象
Registry<ConnectionSocketFactory> socketFactoryRegistry = RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", PlainConnectionSocketFactory.INSTANCE)
.register("https", new SSLConnectionSocketFactory(sslcontext))
.build();
PoolingHttpClientConnectionManager connManager = new PoolingHttpClientConnectionManager(socketFactoryRegistry);
HttpClients.custom().setConnectionManager(connManager); //创建自定义的httpclient对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(connManager).build(); //创建httpclient对象 (这里设置成全局变量,相对于同一个请求session、cookie会跟着携带过去)
// CloseableHttpClient httpClient = HttpClients.createDefault(); //创建get方式请求对象
HttpGet httpGet = new HttpGet(url);
httpGet.addHeader("Content-type", "application/json");
//包装一下
httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36");
httpGet.addHeader("Referer", refererUrl);
httpGet.addHeader("Connection", "keep-alive"); //通过请求对象获取响应对象
CloseableHttpResponse response = httpClient.execute(httpGet);
//获取结果实体
if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
result = EntityUtils.toString(response.getEntity(), "GBK");
} //释放链接
response.close();
}
//这里还可以捕获超时异常,重新连接抓取
catch (Exception e) {
result = null;
System.err.println("采集操作出错");
e.printStackTrace();
}
return result;
}
这样就可以正常抓取了
我们之前获取项目路径用的是
var ctx = /*[[@{/}]]*/'';
突然发现不行了,跳转的路径直接是/开头,现在改成这样获取
//项目路径
var ctx = [[${#request.getContextPath()}]];
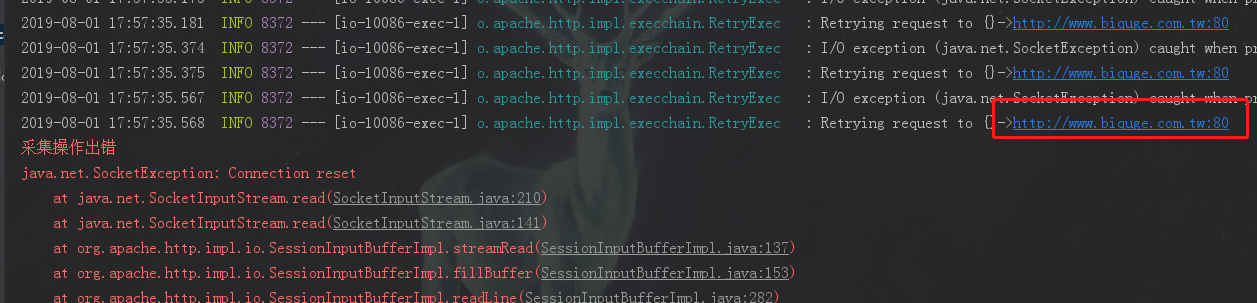
2019-08-01补充:大家如果看到有这个报错,连接被重置,不要慌张,有可能是网站换域名了比如现在我们程序请求的是http://www.biquge.com.tw,但这个网址已经不能访问了,笔趣阁已经改成https://www.biqudu.net/,我们改一下代码就可以解决问题,要注意检查各个源路径是否能正常访问,同时对方也可能改页面格式,导致我们之前的规则无法匹配获取数据,这种情况只能重新编写爬取规则了
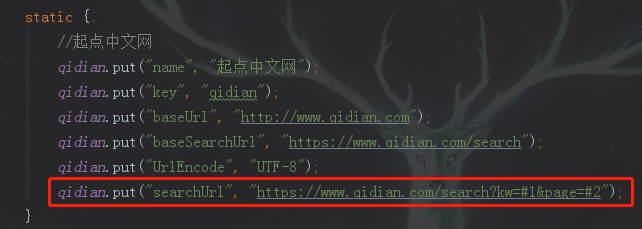
2019-08-02补充:发现了个bug,我们的BookUtil.insertParams方法原理是替换#字符串
/**
* 自动注入参数
* 例如:
*
* @param src http://search.zongheng.com/s?keyword=#1&pageNo=#2&sort=
* @param params "斗破苍穹","1"
* @return http://search.zongheng.com/s?keyword=斗破苍穹&pageNo=1&sort=
*/
public static String insertParams(String src, String... params) {
int i = 1;
for (String param : params) {
src = src.replaceAll("#" + i, param);
i++;
}
return src;
}
但是我们在搜索的时候,调用参数自动注入,形参src的值是来自静态属性Map,初始化的时候有两个#字符串,在进行第一次搜索之后,#字符串被替换了,后面再进行搜索注入参数已经没有#字符串了,因此后面的搜索结果都是第一次的结果...
解决:获取来源时不是用=赋值,而是复制一份,三个方法都要改
修改前:
//获取来源详情
Map<String, String> src = source.get(sourceKey);
修改后:
//获取来源详情,复制一份
Map<String, String> src = new HashMap<>();
src.putAll(source.get(sourceKey));
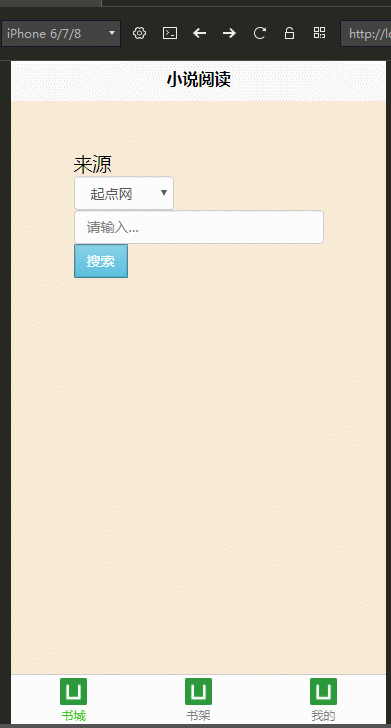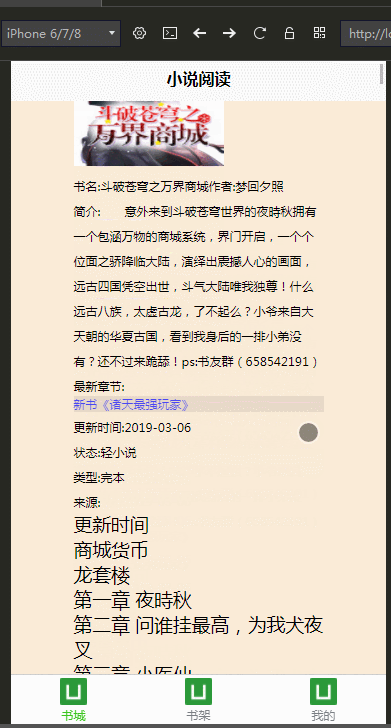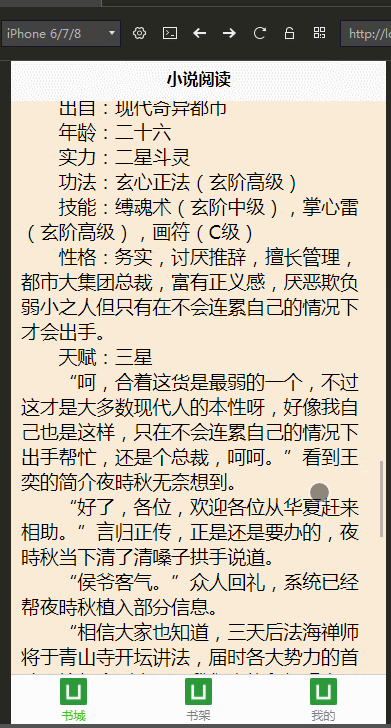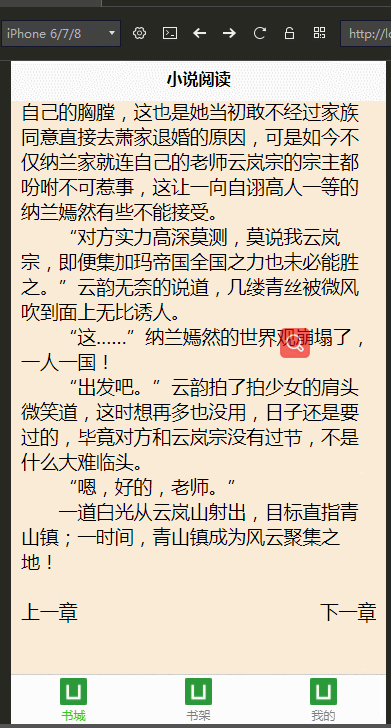
多端开发
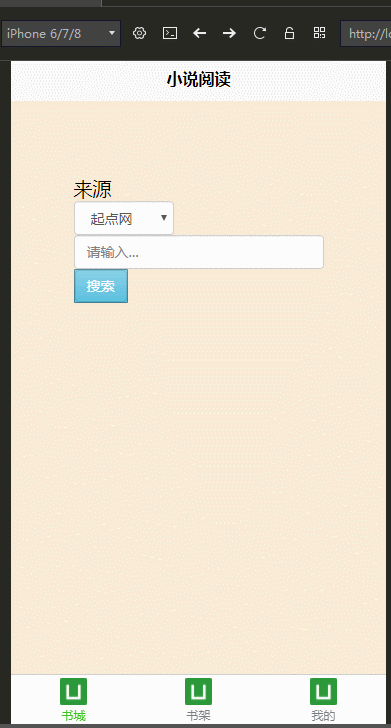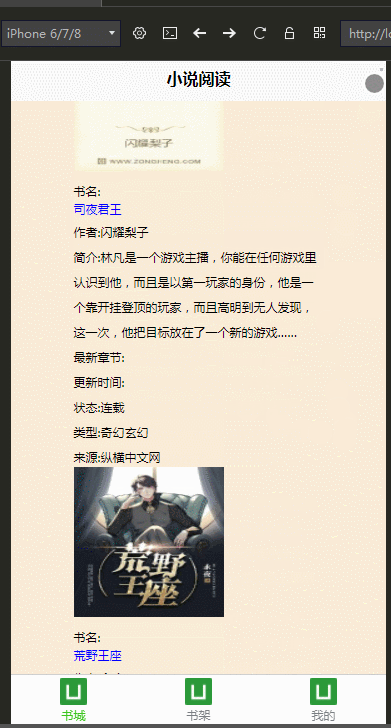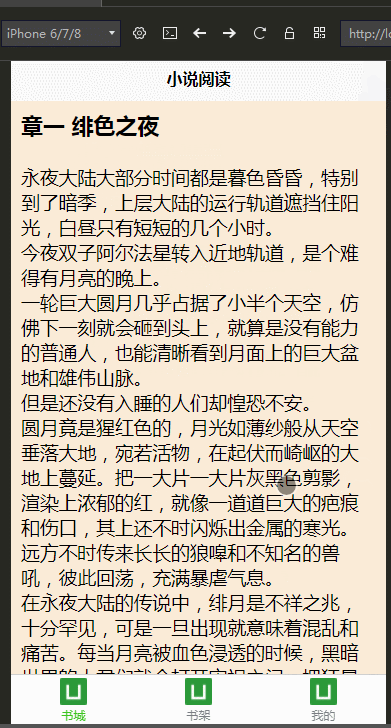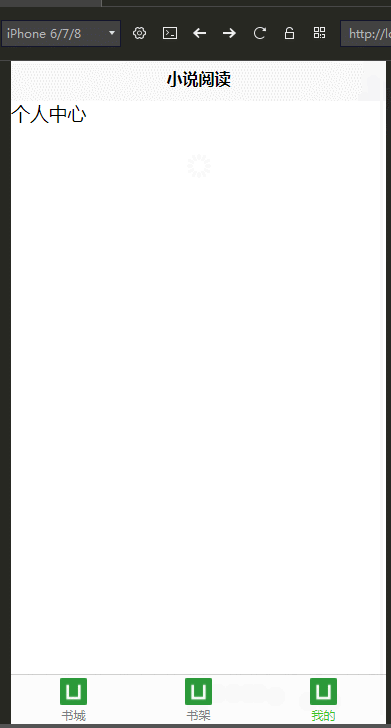
公司最近打算做手机端,学习了DCloud公司的uni-app,开发工具是HBuilderX,并用我们的小说爬虫学习、练手,做了个H5手机端的页面
DCloud公司官网:https://www.dcloud.io/
uni-app官网:https://uniapp.dcloud.io/
uni-app 是一个使用 Vue.js 开发所有前端应用的框架,开发者编写一套代码,可编译到iOS、Android、H5、以及各种小程序等多个平台。
效果图:
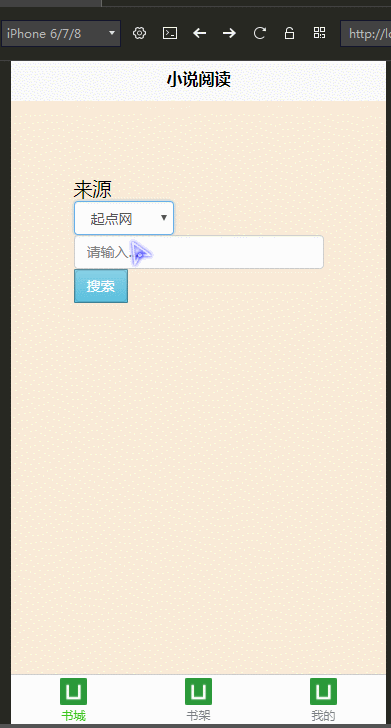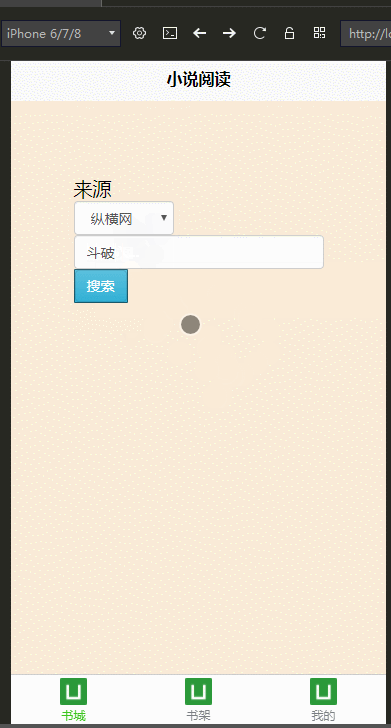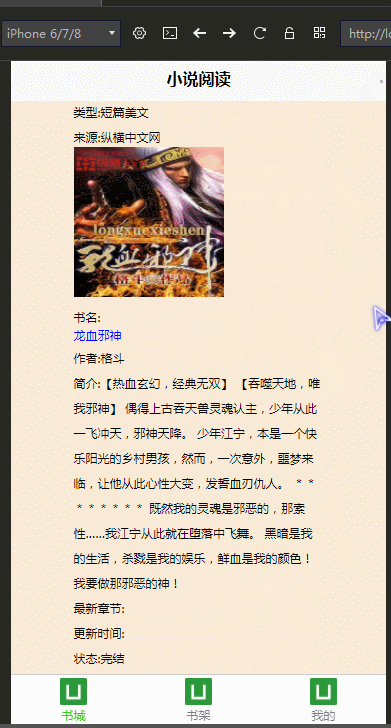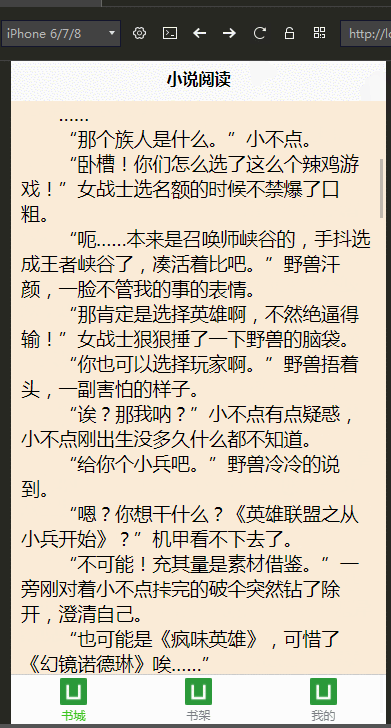
代码开源
代码已经开源、托管到我的GitHub、码云:
GitHub:https://github.com/huanzi-qch/spider
码云:https://gitee.com/huanzi-qch/spider
httpclient+jsoup实现小说线上采集阅读的更多相关文章
- Flume线上日志采集【模板】
Flume线上日志采集[模板] 预装软件 Java HDFS Lzo/Lzop 系统版本 Flume 1.5.0-cdh5.4.0 系统流程图 flume-env.sh配置文件 export JAVA ...
- 线上SQL优化
最近在线上发现很多性能有问题的sql,开发写sql语句的时候,没充分考虑是否用上索引了,所以这个坑得DBA来填,好了,废话不多说,把一些线上的优化经验跟大家分享. 由于是线上的表,所以就不公开具体的表 ...
- 原创 记录一次线上Mysql慢查询问题排查过程
背景 前段时间收到运维反馈,线上Mysql数据库凌晨时候出现慢查询的报警,并把原始sql发了过来: --去除了业务含义的sql update test_user set a=1 where id=1; ...
- 【重装系统】线上Linux服务器(2TB)分区参考方案
如果是线上服务器,假设它是 2TB 的 SATA 硬盘.8GB 内存,建议按如下方式进行分区: / 20480M(20G)(主分区) /boot 128M swap 10240M /data 2016 ...
- 一次线上http接口调用不通相关的解决过程
2016-05-25 08:58:34 昨天线上小白系统因为调用外部http接口,超时不释放,导致页面反应很慢,时间一长,报502错误. 上网查了下,502错误是因为服务对于客户的请求没有得到及时的反 ...
- HBase工程师线上工作经验总结----HBase常见问题及分析
阅读本文可以带着下面问题:1.HBase遇到问题,可以从几方面解决问题?2.HBase个别请求为什么很慢?你认为是什么原因?3.客户端读写请求为什么大量出错?该从哪方面来分析?4.大量服务端excep ...
- (转)HBase工程师线上工作经验总结----HBase常见问题及分析
阅读本文可以带着下面问题:1.HBase遇到问题,可以从几方面解决问题?2.HBase个别请求为什么很慢?你认为是什么原因?3.客户端读写请求为什么大量出错?该从哪方面来分析?4.大量服务端excep ...
- 一个purge参数引发的惨案——从线上hbase数据被删事故说起
在写这篇blog前,我的心情久久不能平静,虽然明白运维工作如履薄冰,但没有料到这么一个细小的疏漏会带来如此严重的灾难.这是一起其他公司误用puppet参数引发的事故,而且这个参数我也曾被“坑过”. ...
- Linux基本命令(6)线上查询的命令
线上查询的命令 命令 功能 man 查询和解释一个命令的使用方法,以及这个命令的说明事项 locate 定位文件和目录 whatis 寻找某个命令的含义 6.1 man命令 man命令用来查询和解释一 ...
随机推荐
- h5软键盘挡住输入框问题解决(android)
问题 移动端浏览器中的表单在部分android机型上测试,点击靠下的输入框时会遇到弹出的软键盘挡住输入框问题 ios可自身弹起(ios自身的调整偶尔也会出问题,例如第三方键盘会遮挡,原因是第三方输入法 ...
- [转]XModem协议
出处:XModem协议 XModem协议介绍:XModem是一种在串口通信中广泛使用的异步文件传输协议,分为XModem和1k-XModem协议两种,前者使用128字节的数据块,后者使用1024字节即 ...
- Nginx的虚拟主机配置
虚拟主机技术能够让同一台服务器.同一组Nginx进程上运行多个网站,降低了资金和服务器资源的损耗.Nginx可以配置三种类型的虚拟主机,本文就是主要介绍这三种虚拟主机配置方式. 配置基于IP的虚拟主机 ...
- [LeetCode] Masking Personal Information 给个人信息打码
We are given a personal information string S, which may represent either an email address or a phone ...
- windows10下Kafka环境搭建
内容小白,包含JDK+Zookeeper+Kafka三部分.JDK:1) 安装包:Java SE Development Kit 9.0.1 下载地址:http://www.oracle ...
- swust oj 987
输出用先序遍历创建的二叉树是否为完全二叉树的判定结果 1000(ms) 10000(kb) 2553 / 5268 利用先序递归遍历算法创建二叉树并判断该二叉树是否为完全二叉树.完全二叉树只能是同深度 ...
- Springboot入门之分布式事务管理
springboot默认集成事务,只主要在方法上加上@Transactional即可. 分布式事务一种情况是针对多数据源,解决方案这里使用springboot+jta+atomikos来解决 一.po ...
- C++之几个最常
1.同类对象间的数据共享——静态成员 静态数据成员声明静态数据成员要采用关键字static:类静态数据成员的定义和初始化定义:static 数据类型 成员名:初始化:数据类型 类名::静态数据成员名= ...
- Bugly 多渠道热更新解决方案
作者:巫文杰 Gradle使用productFlavors打渠道包的痛 有很多同学可能会采用配置productFlavors来打渠道包,主要是它是原生支持,方便开发者输出不同定制版本的apk,举个例子 ...
- [Swift]LeetCode47. 全排列 II | Permutations II
Given a collection of numbers that might contain duplicates, return all possible unique permutations ...