用canal同步binlog到kafka,spark streaming消费kafka topic乱码问题
canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有kafka和RocketMQ。
在投递的时候我们使用的是非压平的消息模式(canal.mq.flatMessage =false //是否为flat json格式对象),然后消费topic的时候就一直无法正常显示和序列化,通过kafka-console-consumer.sh命令收到的消息如下图

在github上也能找到相关问题
canal-kafka 数据同步到kafka之后,kafka topic乱码:https://github.com/alibaba/canal/issues/898
canal.kafka 用bin/kafka-console-consumer.sh命令收到乱码:https://github.com/alibaba/canal/issues/1013
在非flatmessage模式下向kafka数据投递传输的是数据包,收到数据后还要解包成对应的message,可参考canal client中的kafka实现, github地址为 https://github.com/alibaba/canal/tree/master/client/src/main/java/com/alibaba/otter/canal/client/kafka
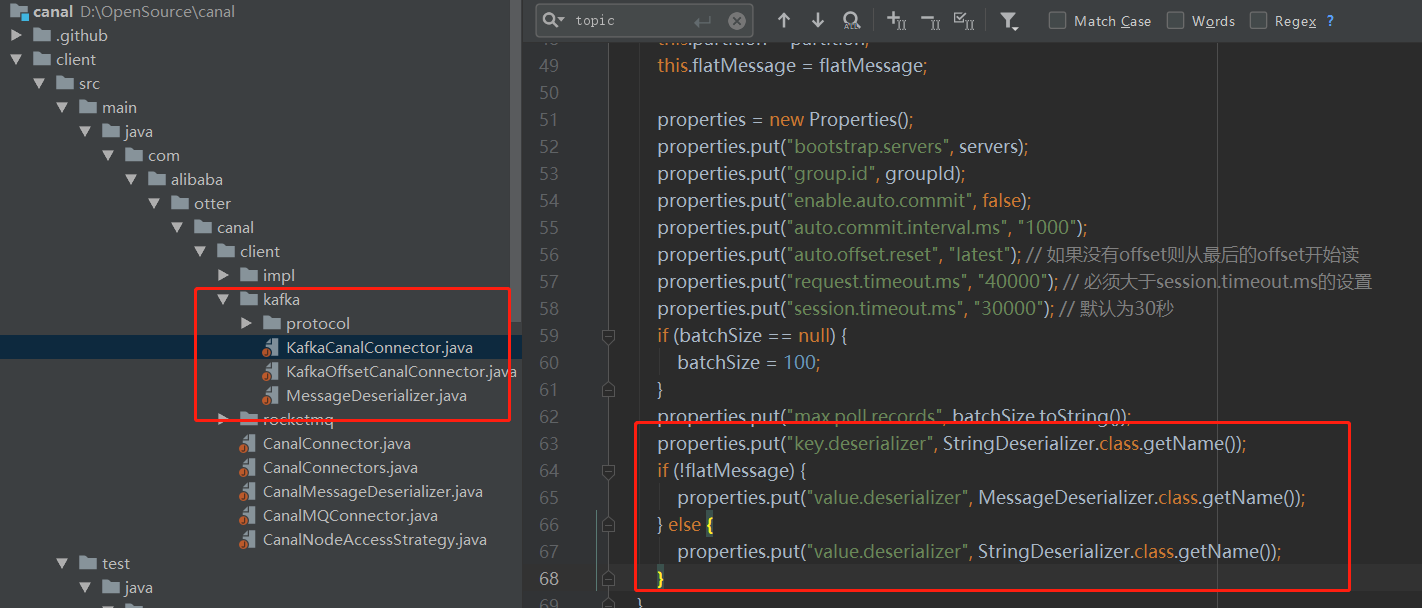
打开连接后 kafkaConsumer = new KafkaConsumer<String, Message>(properties);
参考这种操作只是简单的kafka能够收消息,结合spark streaming收消息也差不多。
在kafkaparam中设置key和value的反序列化方式
"key.deserializer" -> classOf[StringDeserializer].getName
"value.deserializer" -> classOf[MessageDeserializer].getName
在拉取消息的时候设置接受格式为Array[Byte]
val messages = KafkaUtils.createDirectStream[String, Array[Byte], StringDecoder, DefaultDecoder](ssc, kafkaParams, topics)
在处理每个RDD的时候再对内容进行反序列化:
val parData = rdd.mapPartitions(t => {
val mesDesc = new MessageDeserializer
var list = List[consumerUser]()
while (t.hasNext) {
try {
val value = t.next()._2
val message = mesDesc.deserialize("", value)
//val listMaps = CanalParse.parseData(message)
//逻辑
} catch {
case e: Exception => log.error(e)
}
}
list.iterator
})
这样就拿到了message对象。
依赖jar包
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.8.2.1</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.protocol</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.kafka.client</artifactId>
<version>1.1.0</version>
</dependency>
用canal同步binlog到kafka,spark streaming消费kafka topic乱码问题的更多相关文章
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
- spark streaming 消费 kafka入门采坑解决过程
kafka 服务相关的命令 # 开启kafka的服务器bin/kafka-server-start.sh -daemon config/server.properties &# 创建topic ...
- Spark Streaming消费Kafka Direct保存offset到Redis,实现数据零丢失和exactly once
一.概述 上次写这篇文章文章的时候,Spark还是1.x,kafka还是0.8x版本,转眼间spark到了2.x,kafka也到了2.x,存储offset的方式也发生了改变,笔者根据上篇文章和网上文章 ...
- Spark Streaming消费Kafka Direct方式数据零丢失实现
使用场景 Spark Streaming实时消费kafka数据的时候,程序停止或者Kafka节点挂掉会导致数据丢失,Spark Streaming也没有设置CheckPoint(据说比较鸡肋,虽然可以 ...
- spark streaming消费kafka: Java .lang.IllegalStateException: No current assignment for partition
1 原因是: 多个相同的Spark Streaming同时消费同一个topic,导致的offset问题.关掉多余的任务,就ok了.
- kafka + spark Streaming + Tranquility Server发送数据到druid
花了很长时间尝试druid官网上说的Tranquility嵌入代码进行实时发送数据到druid,结果失败了,各种各样的原因造成了失败,现在还没有找到原因,在IDEA中可以跑起,放到线上就死活不行,有成 ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
- Spark Streaming on Kafka解析和安装实战
本课分2部分讲解: 第一部分,讲解Kafka的概念.架构和用例场景: 第二部分,讲解Kafka的安装和实战. 由于时间关系,今天的课程只讲到如何用官网的例子验证Kafka的安装是否成功.后续课程会接着 ...
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
随机推荐
- docker部署archery
一.centos7部署docker 1 通过 uname -r 命令查看你当前的内核版本 uname -r 2 确保 yum 包更新到最新. yum update 3 卸载旧版本 yum remov ...
- 利用SSL-Change Cipher Spec传递信息
Change Cipher Spec 中文翻译为 更改密码规格. 恢复原有会话的SSL握手过程流程如下: 关于如何用Change Cipher Spec传输数据,可以扩展tcp.payload. tc ...
- mongodb增加新字段报错解决方法
今天想在项目的一个集合里增加一个新字段 db.article.update({},{$set:{status:0}},{multi:true}) multi : 可选,mongodb 默认是false ...
- SimpleDateFormat 线程不安全及解决方案
SimpleDateFormat定义 SimpleDateFormat 是一个以与语言环境有关的方式来格式化和解析日期的具体类.它允许进行格式化(日期 -> 文本).解析(文本 -> 日期 ...
- java使用redis数据库
1.安装 Redis 支持 32 位和 64 位,根据实际情况选择不同的安装版本. 安装完成后打开命令提示窗口,切换到redis安装目录,启动redis客户端, redis-cli命令启动redis客 ...
- MyRolan (快速启动小工具)
类似 Rolan的快速启动工具. 启动后隐藏,当鼠标移至左上角时,窗口显示,点击项目可运行程序. GitHub地址: MyRolan . #if defined(UNICODE) && ...
- APK改之理 手游修改改编安卓程序工具安装使用教程
APK改之理 手游修改改编安卓程序工具安装使用教程 --APK破解付费程序 apk改之理是pc平台上一款非常好用的apk反编译工具,他将反编译以及签名等功能集中在一起,并且拥有非常人性化的操作界面,如 ...
- 获取iframe 内容
parent.$.find("iframe")[0].contentWindow.getvalue(); h.find("iframe")[0].content ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 第十四节,OpenCV学习(三)图像的阈值分割
图像的阈值处理 图像的阈值分割:图像的二值化(Binarization) 阈值分割法的特点是:适用于目标与背景灰度有较强对比的情况,重要的是背景或物体的灰度比较单一,而且总可以得到封闭且连通区域的边界 ...