Scrapy架构概述
Scrapy架构概述
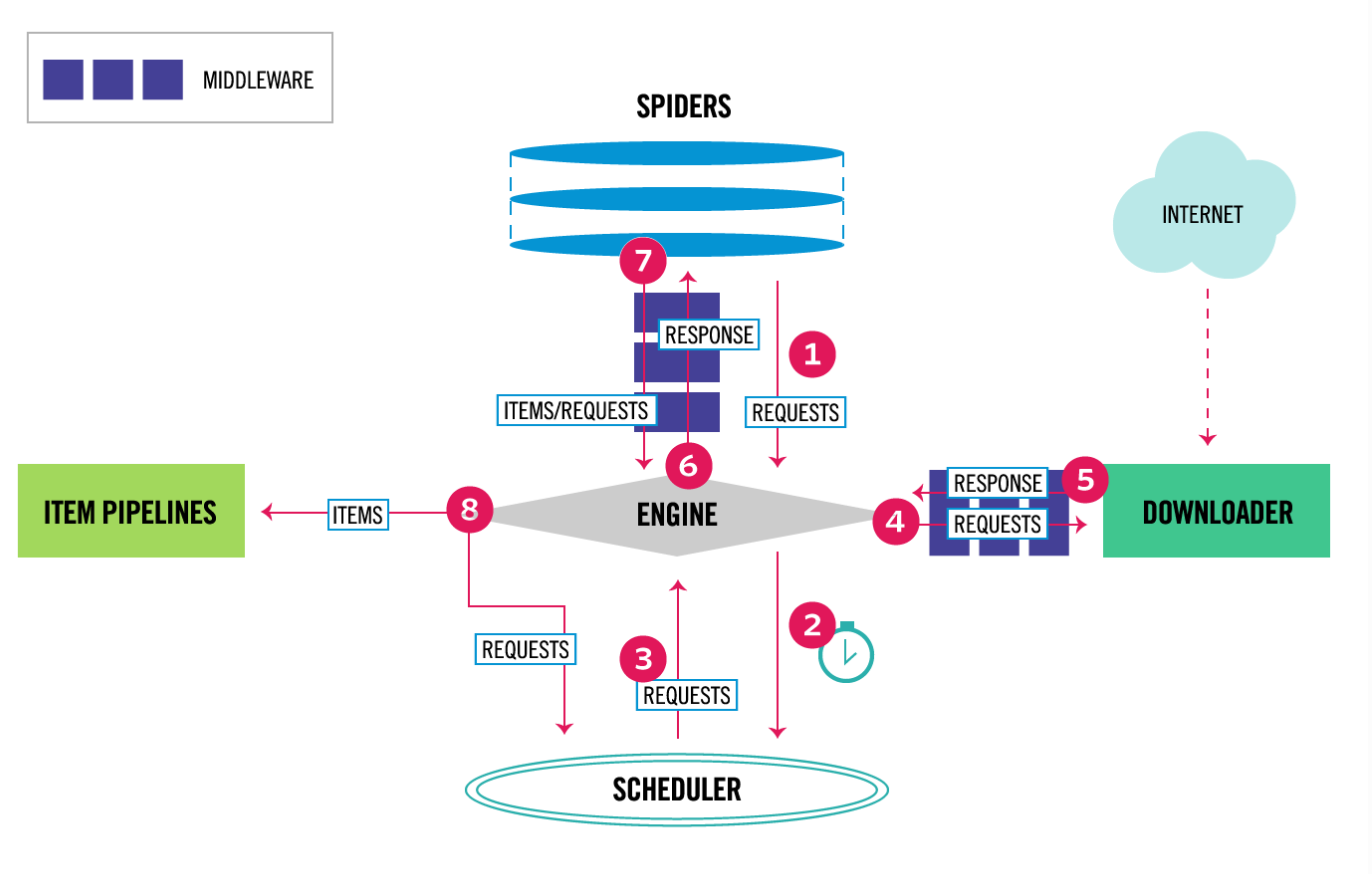
1, 从最初自己编写的spiders,获取到start_url,并且封装成Request对象。
2,通过engine(引擎)调度给SCHEDULER(Requests管理调度器)。
3,SCHEDULER管理ENGINE传递过来的所有Requests,通过优先级,传递给ENGINE。
4,ENGINE 将传递过来的Request对象传递给Downloader(下载器),但是在传递之间会通过MiddleWare(中间件)对Requests进行包装,添加头部,代理IP之类的。
5,Downloader(下载器)将包装好的Requests进行下载,并将下载后的Response对象传递给Engin。
6,Engin将Response对象传递给自己编码的Spider,但是中间仍有对于Response加工的中间件,在spider中通过自己编写的规则对内容进行提取。
7,提取完成后会产生两种对象,一个是自己想要的数据,存储在Item中;另一个是想要继续爬取的URL,包装成Request一并传递给Engine
8,Engine获取到 7 传递过来的Item,将其传递给ItemPipelines(Item管道,将Item中数据写入存储);获取到 7 传递来的Requests对象,跟之前一样,交给SCHEDULER进行管理调度
9,SCHEDULER中没有Requests对象需要下载时,爬虫关闭。
Scrapy架构概述的更多相关文章
- Python -- Scrapy 架构概览
架构概览 本文档介绍了Scrapy架构及其组件之间的交互. 概述 接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详 ...
- 老李推荐: 第14章2节《MonkeyRunner源码剖析》 HierarchyViewer实现原理-HierarchyViewer架构概述
老李推荐: 第14章2节<MonkeyRunner源码剖析> HierarchyViewer实现原理-HierarchyViewer架构概述 HierarchyViewer库的引入让M ...
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- MySQL逻辑架构概述
1.MySQL逻辑架构 MySQL逻辑架构图 MySQL逻辑架构分四层 1.连接层:主要完成一些类似连接处理,授权认证及相关的安全方案. 2.服务层:在 MySQL据库系统处理底层数据之前的所有工作都 ...
- scrapy架构简介
一.scrapy架构介绍 1.结构简图: 主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine ...
- 大型互联网架构概述 关于架构的架构目标 典型实现 DNS CDN LB WEB APP SOA MQ CACHE STORAGE
大型互联网架构概述 目录 架构目标 典型实现 DNS CDN LB WEB APP SOA MQ CACHE STORAGE 本文旨在简单介绍大型互联网的架构和核心组件实现原理. 理论上讲,从安装配置 ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- Tornado之架构概述图
一.Tornado之架构概述图 二.Application类详细分析: #!/usr/bin/env python # -*- coding: utf8 -*- # __Author: "S ...
随机推荐
- [Deep Learning] 深度学习中消失的梯度
好久没有更新blog了,最近抽时间看了Nielsen的<Neural Networks and Deep Learning>感觉小有收获,分享给大家. 了解深度学习的同学可能知道,目前深度 ...
- Could not find a package configuration file provided by "Qt5Widgets"
解决: sudo apt install qttools5-dev
- python&django 实现页面中关联查询小功能(基础篇)
效果 实现效果图如下,根据过滤条件查询相关信息. 知识点 1.配置URL,在路由中使用正则表达式 2.过滤查询 代码 setting.py from django.contrib import adm ...
- HtmlWebpackPlugin用的html的ejs模板文件中如何使用条件判断
折腾: [已解决]给react-hot-boilerplate中的index.html换成用HtmlWebpackPlugin自动生成html 期间,已经有了思路了,但是不知道如何在ejs的html中 ...
- pwnable.tw start&orw
emm,之前一直想做tw的pwnable苦于没有小飞机(,今天做了一下发现都是比较硬核的pwn题目,对于我这种刚入门?的菜鸡来说可能难度刚好(orz 1.start 比较简单的一个栈溢出,给出一个li ...
- 爬虫 解析库re,Beautifulsoup,
re模块 点我回顾 Beautifulsoup模块 #安装 Beautiful Soup pip install beautifulsoup4 #安装解析器 Beautiful Soup支持Pytho ...
- Windows【端口被占用,杀死想啥的端口】
windows 两步方法 netstat -ano | findstr "8080" taskkill /pid 4136-t -f linux 两步方法 ps -ef | gre ...
- vue请求网络图片403错误,图片有占位但是显示不出来解决办法
在index.html 增加一个meta标签 <meta name="referrer" content="no-referrer" />
- http 四大特征
- requests基本应用
requests基本功能详解 import requests response = requests.get('https://www.baidu.com') print('type属性:',type ...