【原创】大数据基础之Parquet(1)简介

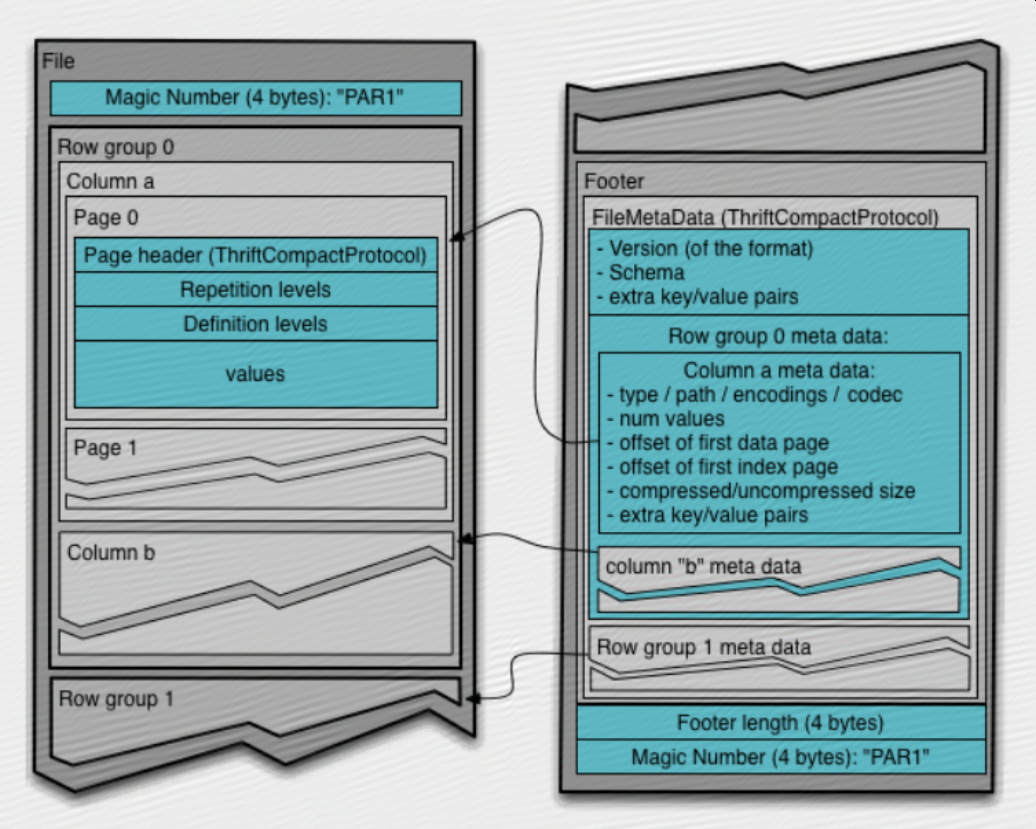
层次结构:
file -> row groups -> column chunks -> pages(data/index/dictionary)
Motivation
We created Parquet to make the advantages of compressed, efficient columnar data representation available to any project in the Hadoop ecosystem.
Parquet is built from the ground up with complex nested data structures in mind, and uses the record shredding and assembly algorithm described in the Dremel paper. We believe this approach is superior to simple flattening of nested name spaces.
Parquet is built to support very efficient compression and encoding schemes. Multiple projects have demonstrated the performance impact of applying the right compression and encoding scheme to the data. Parquet allows compression schemes to be specified on a per-column level, and is future-proofed to allow adding more encodings as they are invented and implemented.
Parquet is built to be used by anyone. The Hadoop ecosystem is rich with data processing frameworks, and we are not interested in playing favorites. We believe that an efficient, well-implemented columnar storage substrate should be useful to all frameworks without the cost of extensive and difficult to set up dependencies.
Parquet是为了让Hadoop生态的任何项目都可以利用压缩和列式存储的优点;Parquet生来就支持复杂的嵌套数据结构,使用了Dremel论文里提到的记录分片和整合算法;Parquet支持高效的压缩和编码scheme,很多项目都证明了这会极大的提升查询性能;
Glossary
Block (hdfs block): This means a block in hdfs and the meaning is unchanged for describing this file format. The file format is designed to work well on top of hdfs.
File: A hdfs file that must include the metadata for the file. It does not need to actually contain the data.
Row group: A logical horizontal partitioning of the data into rows. There is no physical structure that is guaranteed for a row group. A row group consists of a column chunk for each column in the dataset.
Column chunk: A chunk of the data for a particular column. These live in a particular row group and is guaranteed to be contiguous in the file.
Page: Column chunks are divided up into pages. A page is conceptually an indivisible unit (in terms of compression and encoding). There can be multiple page types which is interleaved in a column chunk.
Hierarchically, a file consists of one or more row groups. A row group contains exactly one column chunk per column. Column chunks contain one or more pages.
一个file包含一个或多个row group,一个row group里每个column都包含唯一一个column chunk,一个column chunk包含一个或多个page;
Metadata
There are three types of metadata: file metadata, column (chunk) metadata and page header metadata. All thrift structures are serialized using the TCompactProtocol.
The file metadata contains the locations of all the column metadata start locations.
Metadata is written after the data to allow for single pass writing.
Readers are expected to first read the file metadata to find all the column chunks they are interested in. The columns chunks should then be read sequentially.
有3种元数据:file metadata,column metadata和page header metadata;file metadata包含了所有column metadata的起始位置;reader应该先读file metadata来找到它们感兴趣的column chunk;

The format is explicitly designed to separate the metadata from the data. This allows splitting columns into multiple files, as well as having a single metadata file reference multiple parquet files.
这种格式的设计是为了将metadata和data分离,这样就可以将不同的列的数据拆分到不同的文件,同时有一个metadata文件可以引用多个data文件;
【原创】大数据基础之Parquet(1)简介的更多相关文章
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- 大数据基础知识问答----hadoop篇
handoop相关知识点 1.Hadoop是什么? Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
随机推荐
- 三十三、ajaxFileUpload图片上传
$.ajaxFileUpload({ url : "api/upload/filesUpload", secureuri : false, //一般设置为false fileEle ...
- c++入门之函数指针和函数对象
函数指针可以方便我们调用函数,但采用函数对象,更能体现c++面向对象的程序特性.函数对象的本质:()运算符的重载.我们通过一段代码来感受函数指针和函数对象的使用: int AddFunc(int a, ...
- U盘安装CentOS系统、raid5制作以及nohup的使用
最近折腾服务器,用U盘安装了系统,总结了一些避坑措施: 下载UltraISO工具,用来刻盘 从centos官网下载ISO镜像,然后刻盘 关键是在你进入系统安装界面后,如下: 选中第一项,按tab键(看 ...
- k8s简单的来部署一下tomcat,并测试自愈功能
前言: 2018年12月6日 今天终于把k8s运行tomcat打通了,耗了我几天时间一个一个坑踩过来,不容易啊,废话不多说. 先记录一些操作时的错误: <<<<<< ...
- Javaweb项目 利用JSP响应浏览器
一.javaweb 数据访问流程? 1.浏览器 http 访问服务器 找到 servlet(HttpServeltDemo.java文件) 2.servle 通过dao 访问数据库 数据库将数据返回 ...
- [SimplePlayer] 3. 视频帧同步
Frame Rate 帧率代表的是每一秒所播放的视频图像数目.通常,视频都会有固定的帧率,具体点地说是每一帧的时间间隔都是一样的,这种情况简称为CFR(Constant Frame Rate);另外一 ...
- 六、Java多人博客系统-2.0版本-代码实现
1.前后端分离,后端使用spring boot,只负责提供数据,对外暴露Restful API.前端使用vue,只负责展示数据和向后台提交数据. 2.数据库使用mariadb,存储所有数据. 3.前端 ...
- 基于stm32智能车的设计(ucosiii)---北京之行
实物演示视频:https://v.youku.com/v_show/id_XMzc3MDE3NjMyNA==.html?x&sharefrom=android&sharekey=172 ...
- js侧边菜单
目标 实现一个侧边栏菜单,最多二级,可以收起展开.用于系统左侧的主菜单. 大多数系统都会有这样的菜单,用于导航功能,切换到不同的操作页面.在单页应用系统中,菜单一般是固定在左侧,分组节点上配图标,高亮 ...
- 主席树[可持久化线段树](hdu 2665 Kth number、SP 10628 Count on a tree、ZOJ 2112 Dynamic Rankings、codeforces 813E Army Creation、codeforces960F:Pathwalks )
在今天三黑(恶意评分刷上去的那种)两紫的智推中,突然出现了P3834 [模板]可持久化线段树 1(主席树)就突然有了不详的预感2333 果然...然后我gg了!被大佬虐了! hdu 2665 Kth ...