《A Knowledge-Grounded Neural Conversation Model》
abstract
现在的大多数模型都可以被应用在闲聊场景下,但是还没有证据表明他们可以应用在更有用的对话场景下。这篇论文提出了一个知识驱动的,带有背景知识的神经网络对话系统,目的是为了在对话中产生更有意义的回复。以seq2seq模型为基础(传统的seq2seq只能学习到句子的骨架而不包括有效的信息),用对话历史和外界的facts去规范回答。模型具有通用性,可以应用在open-domain。

introduction
这个模型不是像传统的对话系统有明确的任务目标,通过少量数据去训练在一定的回复骨架下的预定义好的槽值填充,也不是传统的没什么有用信息的闲聊,它的目标是和用户一同完成一个目标不是特别明确,但是有信息含量的对话(上述两种的综合),外部数据的连接来自于网络文本数据,不是数据库里的结构化数据,因此扩充外部数据更容易。
这是第一个大规模,完全数据驱动的充分高效利用外部知识的神经网络模型。
background
构建完全数据驱动的转换模型的主要挑战是,世界上大多数知识都没有在任何现有的会话数据集中完全表示。虽然得益于社交媒体的快速发展,这些数据集(Serban et al.2015)的规模已经大幅增长,但这些数据集仍然远远不能和维基百科,Foursquare,Goodreads,或IMDB相比。该问题极大地限制了现有数据驱动的会话模型的发展,因为它们必须如图1中那样回避或偏向地响应,尤其是对于在会话训练数据中表现不佳的那些实体。另一方面,即使包含大多数实体的会话数据可能存在,我们仍然会面临挑战,因为这样的大型数据集难以应用于模型培训,并且数据中展示的许多会话模式(例如,对于类似实体)将会冗余的。
论文的方法旨在避免冗余,并尝试更好地概括现有的会话数据,如图2所示。虽然图中的对话涉及特定的场所,产品和服务,但会话模式是一般的,同样适用于其他实体,这样的话对于以个新的场景,我们只需要去扩充我们的facts库,而不用重新训练整个模型。(传统对话系统会利用预定义好的槽值去填充对话骨架(图中的加粗文本))

学的是对话行为,变化的是facts
model
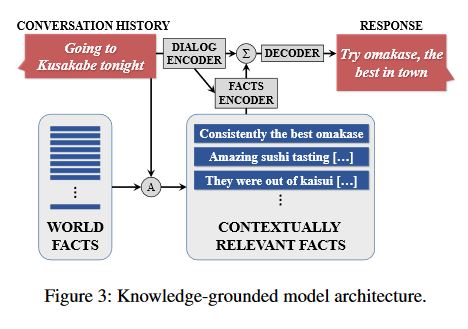
根据句子中的关键词在facts库中检索和本对话相关的facts。
模型的训练使用multi-task学习,分为两部分:
- 任务一:有外部信息的回复,encoder的输入是({f1,f2,...,S},R)
- 任务二:hi的回复:how are you之类无有效信息的闲聊回复,encoder的输入时(S,R)
分为两部分做有三个好处:
- 当只基于对话历史的encoder,decoder训练完之后,再进行包括facts的encoder,decoder的训练时,就可以进行warm start training,
- 不同数据集灵活应变
- 如果将任务一的回复替换为某一fact(R= fi),这就使得任务一相似于一个自编码器,进而使得产生的回复更加有效。more informative
dialog encoder and decoder
encoder和decoder都使用RNN,cell is GRU
facts encoder
由memory-network-model以及end-to-end memery networks演化而来(一个实体在对话中被提到了--之后基于用户输入和对话历史对facts进行检索,进而生成答案)
datasets
- twitter:conversational
(no facts:key to learning the conversational structure or backbone.) - foursquare :non-conversational
(tip date:comments left by customers about restaurants and other, usually commercial, establishments.) 1M grounded dataset
tip为foursquare中的词,handles为twitter上的对话中对应的多个tip的“slot”,例如在twitter中的某句话,@handle 很便宜,物美价廉。这里的handle可以对应的tip有很多,tip = ‘衣服’ or tip = ‘食品’。
轮数为两轮的对话,依据foursquare中的tipdata,在twitter中找到相关的handles和其相关的包含foursquare中实体的对话。另外,这个对话中的第一轮包括一个商户名字的句柄(用@表示)或者和句柄匹配的哈希标签。因为对话目的是模拟真实用户之间的对话,所以把那些包含,由用户使用在foursquare中的句柄生成的回复,的对话删掉(也就是说这句话是用户通过一些词在软件中让软件生成的,而不是他自己嘴里说出来的)。
- grounded conversation dataset:
对于每个handle,有两种打分function: - 基于所有包含这个handle的tips训练的1-gram LM的困惑度
- 卡方分数,用来测量每个token包含的handle相关的内容有多少
通过这两个分数和人工选择,最后选出4k的对话数据作为有效的数据集用来做validation dataset和测试集,这些对话需要从训练数据中抽离。
15k(way1)+15k(way2)+15k(random)->10k(sampled)->4k(human-judge reranking)
实验
- 多任务训练:
- FACTStask:We expose the full model to ({f1,...,fn,S},R)training examples.
- NOFACTStask: We expose the model without fact en-coder to (S,R) examples.
- AUTOENCODERtask: This is similar to the FACTStask,except that we replace the response with each of the facts,i.e., this model is trained on({f1,...,fn,S},fi)exam-ples. There arentimes many samples for this task thanfor the FACTStask.4
- decoding and reranking
验证集:
This yields the following reranking score:
logP(R|S,F) +λlogP(S|R) +γ|R|
- the log-likelihoodlogP(R|S,F)according to the decoder;
- word count;
- the log-likelihoodlogP(S|R)of the source giventhe response.
λ and γ are free parameters, which we tune on our development N-best lists using MERT (Och 2003) by optimizing BLEU.
- evaluation matrics
BLEU automatic evaluation,perplexity,lexiel diversity
Automatic evaluation is augmented with human judgments of appropriateness and informativeness
results
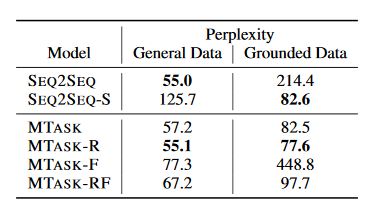
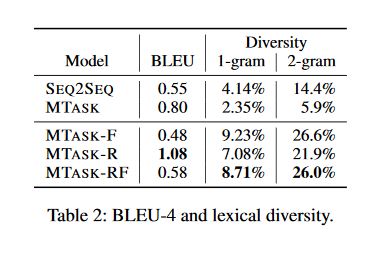
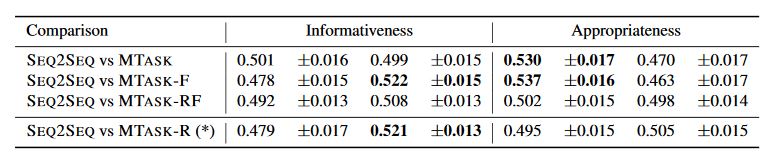
- ==SEQ2SEQ==: Trained on task NOFACTS with the 23M gen-eral conversation dataset. Since there is only one task, it is not per sea multi-task setting.
- ==SEQ2SEQ-S==: SEQ2SEQ model that is trained on the NOFACTS task with 1M grounded dataset (without the facts)
- ==MTASK==: Trained on two instances of the NOFACTS task, respectively with the 23M general dataset and 1M grounded dataset (but without the facts). While not an in-teresting system in itself, we include it to assess the effect of multi-task learning separately from facts.
- ==MTASK-R==: Trained on the NOFACTS task with the 23M dataset, and the FACTS task with the 1M groundeddataset.
- ==MTASK-F==: Trained on the NOFACTS task with the 23Mdataset, and the AUTOENCODERtask with the 1M dataset.
- ==MTASK-RF==: Blends MTASK-F and MTASK-R, as it incorporates 3 tasks: NOFACTS with the 23M generaldataset, FACTSwith the 1M grounded dataset, and AU-TOENCODER again with the 1M dataset.
《A Knowledge-Grounded Neural Conversation Model》的更多相关文章
- 和S5933比较起来,开发PLX9054比较不幸,可能是第一次开发PCI的缘故吧。因为,很多PCI的例子都是对S5933,就连微软出版的《Programming the Microsoft Windows Driver Model》都提供了一个完整的S5933的例子。 在这篇有关DDK的开发论文里。
和S5933比较起来,开发PLX9054比较不幸,可能是第一次开发PCI的缘故吧.因为,很多PCI的例子都是对S5933,就连微软出版的<Programming the Microsoft Wi ...
- 《Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering》论文整理
融合异构知识进行常识问答 论文标题 -- <Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense ...
- 大数据理论篇 - 通俗易懂,揭秘谷歌《The Dataflow Model》的核心思想(一)
目录 前言 目标 核心的设计原则 通用的数据处理流程 切合实际的解决方案 总结 延伸阅读 最后 作者:justmine 头条号:大数据达摩院 创作不易,未经授权,禁止转载,否则保留追究法律责任的权利. ...
- 《An Attentive Survey of Attention Models》阅读笔记
本文是对文献 <An Attentive Survey of Attention Models> 的总结,详细内容请参照原文. 引言 注意力模型现在已经成为神经网络中的一个重要概念,并已经 ...
- 《ASP.NET MVC 5框架揭秘》样章发布
今天算是新作<ASP.NET MVC 5框架揭秘>正式上架销售的日子(目前本书在互动网已经到货),为了让更多适合的朋友们能够阅读此书,同时也避免让不适合的读者误买此书,特将此书的样章发布出 ...
- 新作《ASP.NET MVC 5框架揭秘》正式出版
ASP.NET MVC是一个建立在ASP.NET平台上基于MVC模式的Web开发框架,它提供了一种与Web Form完全不同的开发方式.ASP.NET Web Form借鉴了Windows Form基 ...
- 《zw版·Halcon-delphi系列原创教程》 酸奶自动分类脚本(机器学习、人工智能)
<zw版·Halcon-delphi系列原创教程>酸奶自动分类脚本(机器学习.人工智能) Halcon强大的图像处理能力,令人往往会忽视其内核,是更加彪悍的机器学习.人工智能. ...
- 《zw版·Halcon-delphi系列原创教程》 Halcon分类函数013,shape模型
<zw版·Halcon-delphi系列原创教程> Halcon分类函数013,shape模型 为方便阅读,在不影响说明的前提下,笔者对函数进行了简化: :: 用符号“**”,替换:“pr ...
- 《zw版·Halcon-delphi系列原创教程》 Halcon分类函数009,Measure,测量函数
<zw版·Halcon-delphi系列原创教程> Halcon分类函数009,Measure,测量函数 为方便阅读,在不影响说明的前提下,笔者对函数进行了简化: :: 用符号“**”,替 ...
随机推荐
- vue日历控件,自定义选择年月 选择年月日 选择年月日时 选择年月日时分,自定义日期范围
下载地址:https://pan.baidu.com/s/1iEZl4kDkEg4ybwqc7aI7vQ 注:功能更加全面的日历控件请访问:https://www.cnblogs.com/mrzhu/ ...
- [GXOI/GZOI2019]与或和
考虑拆位,计算每一个二进制位的贡献. 问题转化为求一个01矩阵的全0/1的子矩形个数. 考虑计算以第i行第j列为右下角的合法子矩形个数. 发现合法的左上角范围向左是单调下降的. 可以用一个单调栈来维护 ...
- 微信小程序开发和h5的区别
1. 开发小程序时,每个页面一定要在app.json文件中注册,页面文件夹和其包含的四个文件的名字要保持一致. 2. 小程序发起的都是HTTPS网络请求,在开发调试的过程中可以不校验协议和TLS版本, ...
- WPF前台界面显示“未将对象引用设置到对象的实例”
在做即时通信项目中,使用WPF的MVVM模式,如果在前台绑定VM,经常会显示波浪线,鼠标放上去提示未将对象引用设置到对象的实例,但程序能正常运行,后来发现如果前台不绑定VM,在后台cs里绑定就不会出现 ...
- python--多线程多进程
一.进程 对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程.进程是很多资源 ...
- hive -- 自定义函数和Transform
hive -- 自定义函数和Transform UDF操作单行数据, UDAF:聚合函数,接受多行数据,并产生一个输出数据行 UDTF:操作单个数据 使用udf方法: 第一种: add jar xxx ...
- vscode相关配置
一.插件 二.首先项设置: { "git.enableSmartCommit": true, "gitlens.advanced.messages": { &q ...
- express应用程序生成器
1.express 是node.js的后端开发框架,angular是node.js 的前端开发框架 2.express 的三个核心概念:路由.中间件.模板引擎 一.安装express应用服务程序生成器 ...
- Java中判断对象是否为空的方法
首先来看一下工具StringUtils的判断方法: 一种是org.apache.commons.lang3包下的: 另一种是org.springframework.util包下的.这两种S ...
- crontab 每分钟、每小时、每天、每周、每月、每年执行
每分钟执行 * * * * * 每小时执行 0 * * * * 每天执行 0 0 * * * 每周执行 0 0 * * 0 每月执行 0 0 1 * * 每年执行 0 0 1 1 * 每小时的第3和第 ...