初识spark的MLP模型
初识Spark的MLP模型
1. MLP介绍
Multi-layer Perceptron(MLP),即多层感知器,是一个前馈式的、具有监督的人工神经网络结构。通过多层感知器可包含多个隐藏层,实现对非线性数据的分类建模。MLP将数据分为训练集、测试集、检验集。其中,训练集用来拟合网络的参数,测试集防止训练过度,检验集用来评估网络的效果,并应用于总样本集。当因变量是分类型的数值,MLP神经网络则根据所输入的数据,将记录划分为最适合类型。常被MLP用来进行学习的反向传播算法,在模式识别的领域中算是标准监督学习算法,并在计算神经学及并行分布式处理领域中,持续成为被研究的课题。MLP已被证明是一种通用的函数近似方法,可以被用来拟合复杂的函数,或解决分类问题。
2. 使用Java进行开发
2.1开发环境准备
- 基本Java开发环境
Eclipse,Maven,Jdk1.7
- spark开发需要环境
Windows操作系统保存训练模型必须要依赖于hadoop-common-2.2.0-bin-master,如果不保存模型不需要配置此环境,linux操作系统不需要配置此环境。
配置此环境有以下两种方法:
- 直接在代码最开始写
System.setProperty("hadoop.home.dir", "D:\\Programe\\hadoop-common-2.2.0-bin-master");
- 配置入环境变量
直接在Windows的系统变量里面配置HADOOP_HOME,然后在PATH里面配置HADOOP_HOME/bin
2.2项目搭建
- 创建简单的maven项目
- 在pom下增加下列jar
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.3</version>
<scope>runtime</scope>
</dependency>
注意:本例使用jdk1.7,spark2.2.x要求jdk1.8。
2.3官网实例
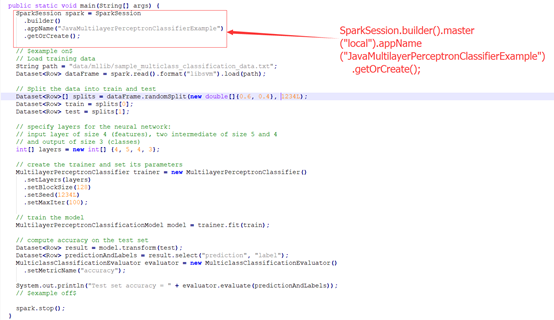
注意:创建SparkSession时添加.master(“local”)
2.4保存训练模型
上例是直接使用数据训练模型之后进行预测,大多数情况是模型只需训练一次,之后就可以直接使用,于是Spark提供了保存模型的方法。
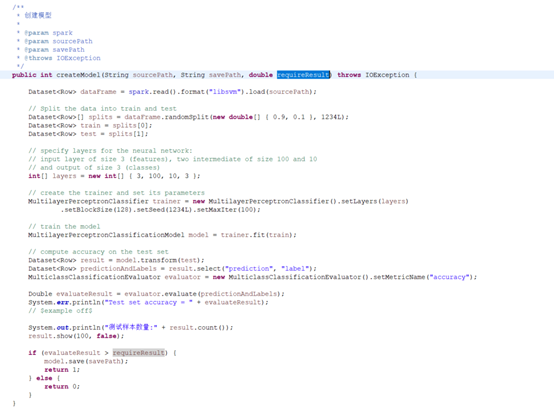
2.5获取训练模型

2.6其他相关知识
- Java类型数据转换为Spark数据类型
略
- 如何从word生成Spark可加载的libsvm的文档
略
3. 参考文档
hadoop-common-2.2.0-bin-master下载地址
https://github.com/srccodes/hadoop-common-2.2.0-bin
Spark的MPL例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
代码例子官网地址(2.4.0版本与本文版本不一样,但是没有影响)
https://github.com/apache/spark/tree/master/examples/src/main/java/org/apache/spark/examples
初识spark的MLP模型的更多相关文章
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- 初识Spark(Spark系列)
1.Spark Spark是继Hadoop之后,另外一种开源的高效大数据处理引擎,目前已提交为apach顶级项目. 效率: 据官方网站介绍,Spark是Hadoop运行效率的10-100倍(随内存计算 ...
- Spark之编程模型RDD
前言:Spark编程模型两个主要抽象,一个是弹性分布式数据集RDD,它是一种特殊集合,支持多种数据源,可支持并行计算,可缓存:另一个是两种共享变量,支持并行计算的广播变量和累加器. 1.RDD介绍 S ...
- Spark分布式计算执行模型
引言 相对Hadoop, Spark在处理需要迭代运算的机器学习训练等任务上有着很大性能提升,同时提供了批处理.实时数据处理.机器学习以及图算法等一站式的服务,因此最近大家一起来学习Spark,特别是 ...
- Spark2.1.0之初识Spark
随着近十年互联网的迅猛发展,越来越多的人融入了互联网——利用搜索引擎查询词条或问题:社交圈子从现实搬到了Facebook.Twitter.微信等社交平台上:女孩子们现在少了逛街,多了在各大电商平台上的 ...
- Spark 决策树--回归模型
package Spark_MLlib import org.apache.spark.ml.Pipeline import org.apache.spark.ml.evaluation.Regres ...
- Spark 决策树--分类模型
package Spark_MLlib import org.apache.spark.ml.Pipeline import org.apache.spark.ml.classification.{D ...
- Spark Core源代码分析: Spark任务运行模型
DAGScheduler 面向stage的调度层,为job生成以stage组成的DAG,提交TaskSet给TaskScheduler运行. 每个Stage内,都是独立的tasks,他们共同运行同一个 ...
- 带你初识Angular中MVC模型
简介 MVC是一种使用 MVC(Model View Controller 模型-视图-控制器)设计模式,该模型的理念也被许多框架所吸纳,比如,后端框架(Struts.Spring MVC等).前端框 ...
随机推荐
- zookeeper启动报 Unexpected exception, exiting abnormally 错误
启动zookeeper---jps,未出现QuorumPeerMain进程 原因: 电脑中的某些进程占用了2181 port 通过 sudo netstat -nltp|grep 2181查看进程并k ...
- linux中ip命令使用介绍
ifconfig是CentOS 5.6系统中经典的配置网络的命令,但是到了CentOS 7的时候,命令就变成了ip了,我们也要学习,我们也要与时俱进.跟随高手一起学习 查看链路 ip link sho ...
- ----Androd 系统开机显示白条提示 “there is internal problem with your device, Contact your manufacture ... ”
ref: https://www.theandroidsoul.com/how-to-fix-theres-an-internal-problem-with-your-device-error-on- ...
- oracle 查看处理锁表
--查出sid,serial#select b.username,b.sid,b.serial#,logon_time from v$locked_object a,v$session b where ...
- systemctl启动tomcat后,jps看不到进程
centos7 写了tomcat的启动脚本,脚本从网上copy的. [Unit]Description=tomcat-1After=syslog.target network.target remot ...
- OO电梯调度
告别了三次奇妙无比的求导作业之后,我们就开始搭建一部自己的电梯了.相信我们不同同学的电梯运行方式肯定各具特色吧,但值得肯定的是,在艰苦的走完了三次电梯逐步改进的作业之后,我们的电梯在正常情况下应该是可 ...
- 循环输入到列表的基础方法 -----python-----
print('向列表中添加元素(输入“#”结束)\n并查看添加完的列表') list1=[] while 1: username=input('>>>') if (username. ...
- 认识border
标签(空格分隔): border border的认识: border:边框的意思,描述盒子的边框,边框有三个要素: 粗细, 线性样式 ,颜色: <!DOCTYPE html> <ht ...
- linux/centOS 下安装 ngnix
Nginx 是一款轻量级的 Web 服务器/反向代理服务器,比较流行,建议在 Linux 下安装运行. Nginx 需要的依赖 它们包括:gcc,openssl,zlib,pcre(可通过rpm -q ...
- PHP : MySQLi【面向过程】操作数据库【 连接、建库、建表、增、删、改、查、关闭】
<?php /** *数据库操作关键函数 *mysql_connect:连接数据 *mysql_error:最后一次sql动作错误信息 *mysqli_query:执行sql语句,增删该查 *m ...