043 hive数据同步到mysql
一:意义
1.意义
如果可以实现这个功能,就可以使用spark代替sqoop,功能程序就实现这个功能。
二:hive操作
1.准备数据
启动hive
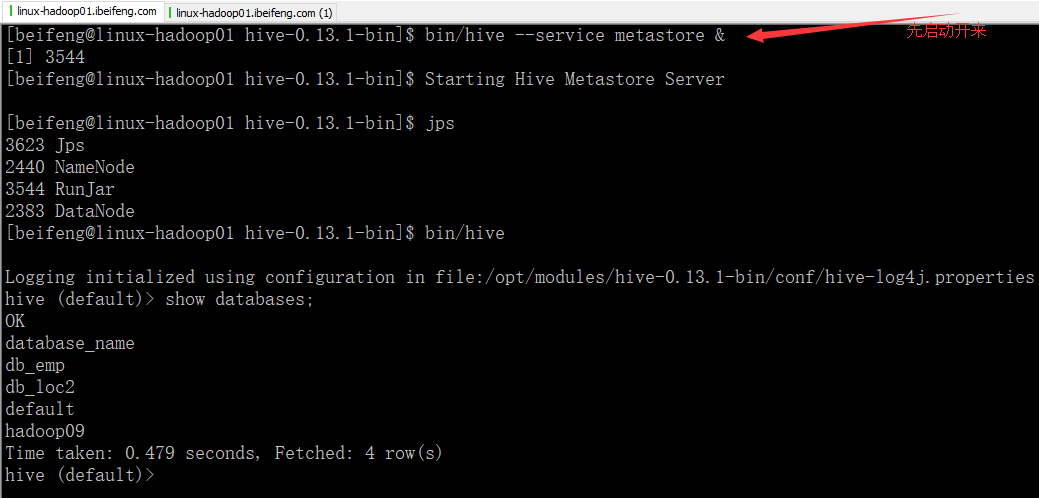
否则报错,因为在hive与spark集成的时候,配置过配置项。

后来,又看见这个文档,感觉很好的解释了我存在的问题:https://blog.csdn.net/freedomboy319/article/details/44828337
2.新建部门员工表
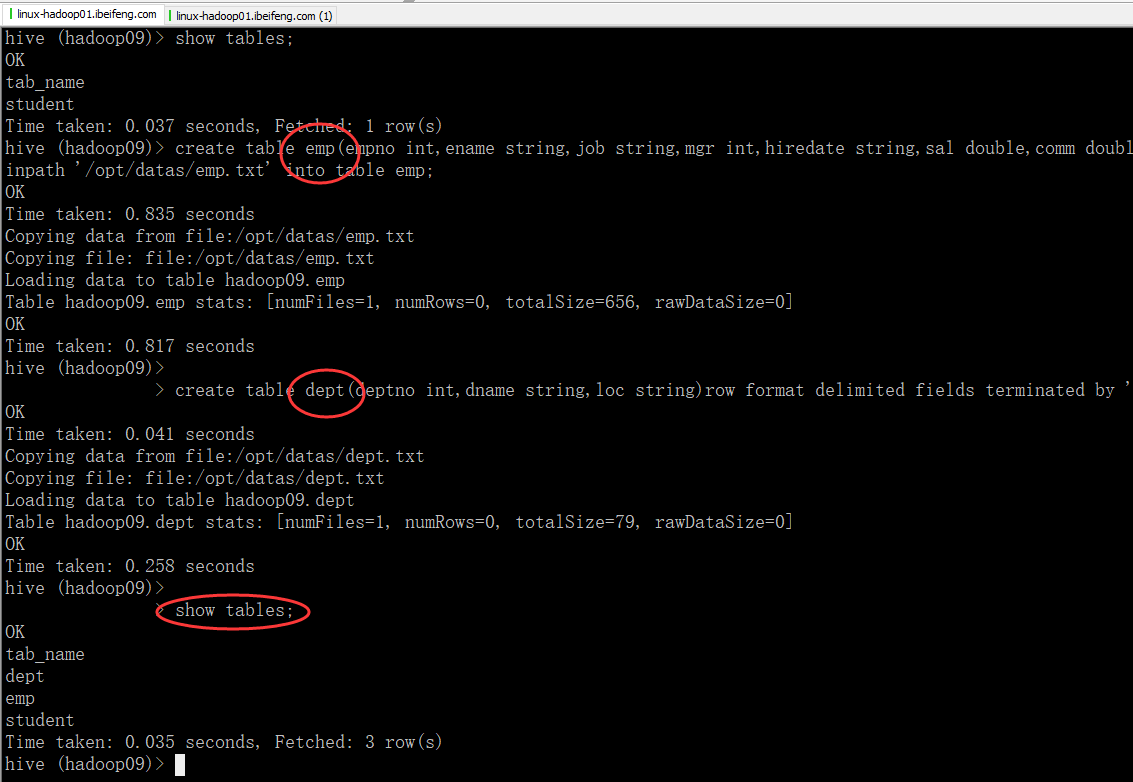
-》创建员工表
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/emp.txt' into table emp; -》部门表
create table dept(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/datas/dept.txt' into table dept;
3.效果
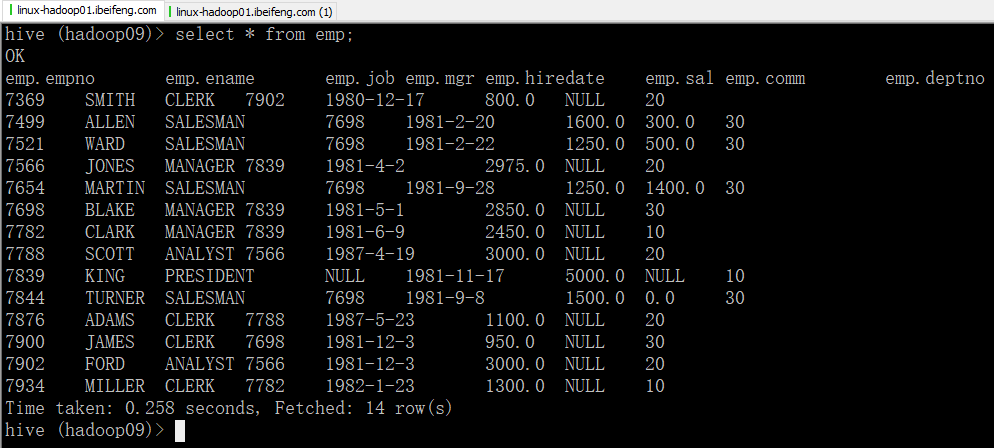
三:程序
1.大纲
2.前提
需要hive-site.xml
3.需要的依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency> <!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>6.0.4</version>
</dependency>
4.报错如下
Exception in thread "main" java.sql.SQLNonTransientConnectionException: CLIENT_PLUGIN_AUTH is required
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:550)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:537)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:527)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:512)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:480)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:498)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:494)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:72)
at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:1634)
at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:637)
at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:351)
at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:224)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.apply(JdbcUtils.scala:61)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.apply(JdbcUtils.scala:52)
at org.apache.spark.sql.DataFrameWriter.jdbc(DataFrameWriter.scala:278)
at com.scala.it.HiveToMysql$.main(HiveToMysql.scala:28)
at com.scala.it.HiveToMysql.main(HiveToMysql.scala)
Caused by: com.mysql.cj.core.exceptions.UnableToConnectException: CLIENT_PLUGIN_AUTH is required
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.mysql.cj.core.exceptions.ExceptionFactory.createException(ExceptionFactory.java:54)
at com.mysql.cj.core.exceptions.ExceptionFactory.createException(ExceptionFactory.java:73)
at com.mysql.cj.mysqla.io.MysqlaProtocol.rejectConnection(MysqlaProtocol.java:319)
at com.mysql.cj.mysqla.authentication.MysqlaAuthenticationProvider.connect(MysqlaAuthenticationProvider.java:207)
at com.mysql.cj.mysqla.io.MysqlaProtocol.connect(MysqlaProtocol.java:1361)
at com.mysql.cj.mysqla.MysqlaSession.connect(MysqlaSession.java:132)
at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:1754)
at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:1624)
... 8 more
原因:
mysql-connect版本不匹配,换5.1.17版本。
5.程序
package com.scala.it import java.util.Properties import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} object HiveToMysql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("hive-yo-mysql")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc)
val (url, username, password) = ("jdbc:mysql://linux-hadoop01.ibeifeng.com:3306/hadoop09", "root", "123456")
val props = new Properties()
props.put("user", username)
props.put("password", password) // ==================================
// 第一步:同步hive的dept表到mysql中
sqlContext
.read
.table("hadoop09.dept") // database.tablename
.write
.mode(SaveMode.Overwrite) // 存在覆盖
.jdbc(url, "mysql_dept", props)
}
}
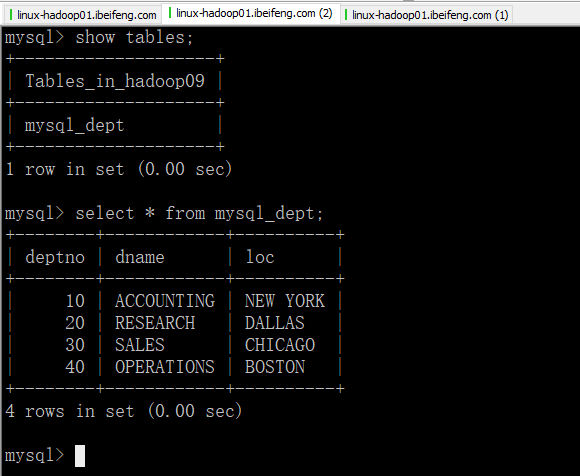
6.效果
043 hive数据同步到mysql的更多相关文章
- 2个CDH的hive数据同步
算法和数仓共用一套hive数据: CM: 真实数据: 都存在共享存储: oss, s3,ufile上. CDH配置能访问的权限(key)
- 使用 sqoop 将 hive 数据导出到 mysql (export)
使用sqoop将hive中的数据传到mysql中 1.新建hive表 hive> create external table sqoop_test(id int,name string,age ...
- Canal - 数据同步 - 阿里巴巴 MySQL binlog 增量订阅&消费组件
背景 早期,阿里巴巴 B2B 公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求 ,主要是基于trigger的方式获取增量变更.从 2010 年开始,公司开始逐步尝试数据库日志解析,获取增量变 ...
- [转]实现Hive数据同步更新的shell脚本
引言: 上一篇文章<Sqoop1.4.4 实现将 Oracle10g 中的增量数据导入 Hive0.13.1 ,并更新Hive中的主表>http://www.linuxidc.com/Li ...
- ODBC数据管理器 SqlServer实时数据同步到MySql
---安装安装mysqlconnector http://www.mysql.com/products/connector/ /* 配置mysqlconnector ODBC数据管理器->系统D ...
- talend hive数据导入到mysql中
thiveInput->tmap->tMysqloutput thiveInput: tmap: tmysqlOutput:注意编码问题:noDatetimeStringSync=true ...
- [Sqoop]将Hive数据表导出到Mysql
业务背景 mysql表YHD_CATEG_PRIOR的结构例如以下: -- Table "YHD_CATEG_PRIOR" DDL CREATE TABLE `YHD_CATEG_ ...
- sqoop用法之mysql与hive数据导入导出
目录 一. Sqoop介绍 二. Mysql 数据导入到 Hive 三. Hive数据导入到Mysql 四. mysql数据增量导入hive 1. 基于递增列Append导入 1). 创建hive表 ...
- 记一次sqoop同步到mysql
工作中需要用到将hive的数据导一份到mysql中,需求是这样的:hive每天会产生一份用户标签(tag)发生变化的结果表user_tag,这份结果同步到mysql中,并且保持一份全量表,存储当前用户 ...
随机推荐
- Android直连SQL Server数据库
1. 下载jtds,一个开放源代码的Java实现的JDBC驱动,地址:http://sourceforge.net/projects/jtds/ 2. 添加jtds到当前Android项目中,本人使用 ...
- CDH hive metastore启动报错:Unknown column 'A0.SCHEMA_VERSION_V2' in 'field list'
新集群CDH版本,刚刚搭建起来,5个节点起了1个hive服务,另外5个节点又单独起了1个hive服务,一共2个人hive服务.老哥对其中的一个hive进行了数据迁移,对hive数据库进行了替换,就这样 ...
- JsRender 前端渲染模板基础学习
JsRender前端渲染模板 使用模板,可以预先自定义一些固定格式的HTML标签,在需要显示数据时,再传入真实数据组装并展示在Web页中:避免了在JS中通过“+”等手动分割.连接字符串的复杂过程:针对 ...
- Confluence 6 查看内容索引概要
内容索引,通常也被称为查找索引,这个索引被用来在 Confluence 中支持查找.这个索引同时也被其他的一些功能使用,例如在归档邮件中构建邮件主题,View Space Activity 的特性和将 ...
- vue 树状图数据的循环 递归循环
在main.js中注册一个子组件 在父组件中引用 树状图的数据格式 绑定一个数据传入子组件,子组件props接收数据 子组件中循环调用组件,就实现了递归循环
- 关于ios进入后台界面后 播放声音解决方案
1 最近我在做环信视频通话时,遇到了一个新功能就是APP在后台的时候能对方能视频或者音频过来的时候 能够播放声音 根据查询相关资料得到如下解决办法 NSError *error; AVAudioSes ...
- java多线程快速入门(十八)
Lock锁是JDK1.5之后推出的并发包里面的关键字(注意捕获异常,释放锁) Lock与synchronized的区别 Lock锁可以人为的释放锁(相当于汽车中的手动挡) synchronized当线 ...
- LeetCode(94):二叉树的中序遍历
Medium! 题目描述: 给定一个二叉树,返回它的中序 遍历. 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,3,2] 进阶: 递归算法很简单,你可以通过迭代算法完成吗 ...
- 步步为营103-ZTree 二级联动
1:添加引用 <%--流程类别多选--引用js和css文件--开始--%> <link rel="stylesheet" href="../css/zT ...
- Python深度学习案例2--新闻分类(多分类问题)
本节构建一个网络,将路透社新闻划分为46个互斥的主题,也就是46分类 案例2:新闻分类(多分类问题) 1. 加载数据集 from keras.datasets import reuters (trai ...