HashMap内部结构及实现原理
简单介绍
在研究HashMap之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
简易HashMap V1.0版本
V1.0版本我们需要实现Map的几个重要的功能:
可以存放键值对
可以根据键查找到值
键不能重复
class CustomHashMap {
CustomEntry[] arr = new CustomEntry[990];
int size;
public void put(Object key, Object value) {
CustomEntry e = new CustomEntry(key, value);
for (int i = 0; i < size; i++) {
if (arr[i].key.equals(key)) {
// 如果有key值相等,直接覆盖value
arr[i].value = value;
return;
}
}
arr[size++] = e;
}
public Object get(Object key) {
for (int i = 0; i < size; i++) {
if (arr[i].key.equals(key)) {
return arr[i].value;
}
}
return null;
}
public boolean containsKey(Object key) {
for (int i = 0; i < size; i++) {
if (arr[i].key.equals(key)) {
return true;
}
}
return false;
}
public static void main(String[] args) {
CustomHashMap map = new CustomHashMap();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k2", "v4");
System.out.println(map.get("k2"));
}
}
class CustomEntry {
Object key;
Object value;
public CustomEntry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
public Object getKey() {
return key;
}
public void setKey(Object key) {
this.key = key;
}
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
上面就是我们自定义的简单Map实现,可以完成V1.0提出的几个功能点,但是大家有木有发现,这个Map是基于数组实现的,不管是put还是get方法,每次都要循环去做数据的对比,可想而知效率会很低,现在数组长度只有990,那如果数组的长度很长了,岂不是要循环很多次。既然问题出现了,我们有没有更好的办法做改进,使得效率提升,答案是肯定,下面就是V2.0版本升级。
简易HashMap V2.0版本
V2.0版本需要处理问题如下:
减少遍历次数,提升存取数据效率
在做改进之前,我们先思考一下,有没有什么方式可以在我们放数据的时候,通过一次定位,就能将这个数放到某个位置,而再我们获取数据的时候,直接通过一次定位就能找到我们想要的数据,那样我们就减少了很多迭代遍历次数。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
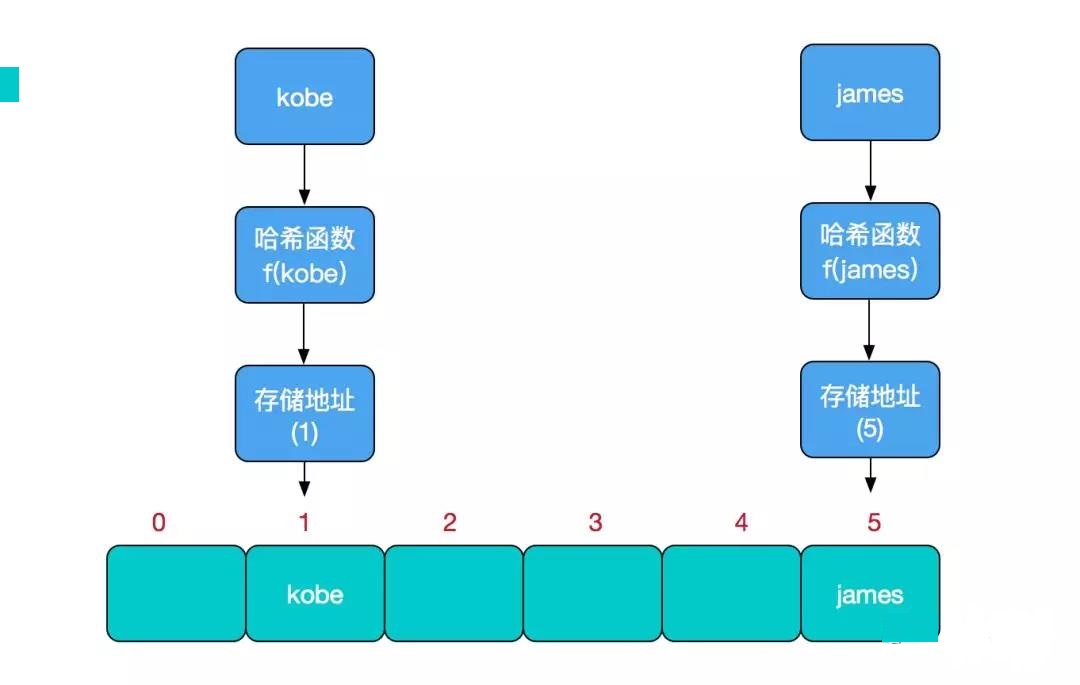
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
class CustomHashMap {
CustomEntry[] arr = new CustomEntry[999];
public void put(Object key, Object value) {
CustomEntry entry = new CustomEntry(key, value);
// 使用Hash码对999取余数,那么余数的范围肯定在0到998之间
// 你可能也发现了,不管怎么取余数,余数也会有冲突的时候(暂时先不考虑,后面慢慢道来)
// 至少现在我们存数据的效率明显提升了,key.hashCode() % 999 相同的key算出来的结果肯定是一样的
int a = key.hashCode() % 999;
arr[a] = entry;
}
public Object get(Object key) {
// 取数的时候也通过一次定位就找到了数据,效率明显得到提升
return arr[key.hashCode() % 999].value;
}
public static void main(String[] args) {
CustomHashMap map = new CustomHashMap();
map.put("k1", "v1");
map.put("k2", "v2");
System.out.println(map.get("k2"));
}
}
class CustomEntry {
Object key;
Object value;
public CustomEntry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
public Object getKey() {
return key;
}
public void setKey(Object key) {
this.key = key;
}
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
通过上面的代码,我们知道余数也有冲突的时候,不一样的key计算出相同的地址,那么这个时候我们又要怎么处理呢?
哈希冲突
如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
通过上面的说明知道,HashMap的底层是基于数组+链表的方式,此时,我们需要再对V2.0的Map再次升级
public class CustomHashMap {
LinkedList[] arr = new LinkedList[999];
public void put(Object key, Object value) {
CustomEntry entry = new CustomEntry(key, value);
int a = key.hashCode() % arr.length;
if (arr[a] == null) {
LinkedList list = new LinkedList();
list.add(entry);
arr[a] = list;
} else {
LinkedList list = arr[a];
for (int i = 0; i < list.size(); i++) {
CustomEntry e = (CustomEntry) list.get(i);
if (entry.key.equals(key)) {
e.value = value;// 键值重复需要覆盖
return;
}
}
arr[a].add(entry);
}
}
public Object get(Object key) {
int a = key.hashCode() % arr.length;
if (arr[a] != null) {
LinkedList list = arr[a];
for (int i = 0; i < list.size(); i++) {
CustomEntry entry = (CustomEntry) list.get(i);
if (entry.key.equals(key)) {
return entry.value;
}
}
}
return null;
}
public static void main(String[] args) {
CustomHashMap map = new CustomHashMap();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k2", "v3");
System.out.println(map.get("k2"));
}
}
class CustomEntry {
Object key;
Object value;
public CustomEntry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
public Object getKey() {
return key;
}
public void setKey(Object key) {
this.key = key;
}
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}

简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
HashMap源码
从上面的推导过程,我们逐渐清晰的认识了HashMap的实现原理,下面我们通过阅读部分源码,来看看HashMap(基于JDK1.7版本)
transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
...
}
可以看出,HashMap中维护了一个Entry为元素的table,transient修饰表示不参与序列化。每个Entry元素存储了指向下一个元素的引用,构成了链表。
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果 i 索引处的 Entry 不为 null,通过循环不断遍历 e 元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 如果i索引处的Entry为null,表明此处还没有Entry。
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
}
从源码可以看出,大致过程是,当我们向HashMap中put一个元素时,首先判断key是否为null,不为null则根据key的hashCode,重新获得hash值,根据hash值通过indexFor方法获取元素对应哈希桶的索引,遍历哈希桶中的元素,如果存在元素与key的hash值相同以及key相同,则更新原entry的value值;如果不存在相同的key,则将新元素从头部插入。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
HashMap内部结构及实现原理的更多相关文章
- Map实现之HashMap(结构及原理)(转)
java.util包中的集合类包含 Java 中某些最常用的类.最常用的集合类是 List 和 Map.List 的具体实现包括 ArrayList 和 Vector,它们是可变大小的列表,比较适合构 ...
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- HashMap底层结构、原理、扩容机制
https://www.jianshu.com/p/c1b616ff1130 http://youzhixueyuan.com/the-underlying-structure-and-princip ...
- 详解HashMap的内部工作原理
本文将用一个简单的例子来解释下HashMap内部的工作原理.首先我们从一个例子开始,而不仅仅是从理论上,这样,有助于更好地理解,然后,我们来看下get和put到底是怎样工作的. 我们来看个非常简单的例 ...
- 关于HashMap put元素的原理
HashMap集合put元素的原理:(1)计算key的hashCode(2)将key的hashCode作为计算因子,通过哈希算法计算HashMap的数组下标index(3)如果index下标的数组元素 ...
- HashMap的底层实现原理
HashMap的底层实现原理1,属性static final int MAX_CAPACITY = 1 << 30;//1073741824(十进制)0100000000000000000 ...
- HashMap底层实现及原理
注意:文章的内容基于JDK1.7进行分析.1.8做的改动文章末尾进行讲解. 一.先来熟悉一下我们常用的HashMap: 1.HashSet和HashMap概述 对于HashSst及其子类而 ...
- Java集合:HashMap底层实现和原理(源码解析)
Note:文章的内容基于JDK1.7进行分析.1.8做的改动文章末尾进行讲解. 一.先来熟悉一下我们常用的HashMap: 1.概述 HashMap基于Map接口实现,元素以键值对的方式存储,并且允许 ...
- hashmap的一些基础原理
本文来源于翁舒航的博客,点击即可跳转原文观看!!!(被转载或者拷贝走的内容可能缺失图片.视频等原文的内容) 若网站将链接屏蔽,可直接拷贝原文链接到地址栏跳转观看,原文链接:https://www.cn ...
随机推荐
- Huawei BGP和OSPF双边界重分布(二)
网络拓扑: 本例主要配置和例一致,主要是在AR3260-AR1和AR3260-AR2的路由域的边界上,从AR3260-AR1上重分布进BGP 65001的路由的时候打tag 650011,在AR326 ...
- vue 存取、设置、清除cookie
步骤: 第一步:assets目录下添加cookie.js文件 export function setCookie(c_name,value,expire) { var date=new Date() ...
- vscode 好用插件
1.查询文件路径../../有提示: Path Intellisense 2.require 时的包提示(最新版的vscode已经集成此功能) : Npm Intellisense 3.自动帮你完成 ...
- 正向与反向拓扑排序的区别(hdu 1285 确定比赛名次和hdu 4857 逃生)
确定比赛名次 Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Total Submis ...
- Eclipse常用快捷键--摘录他人
Eclipse常用快捷键 1几个最重要的快捷键 代码助手:Ctrl+Space(简体中文操作系统是Alt+/) 快速修正:Ctrl+1 单词补全:Alt+/ 打开外部Java文档:Shift+F2显示 ...
- HTML导出Excel文件(兼容IE及所有浏览器)
注意:IE浏览器需要以下设置: 打开IE,在常用工具栏中选择“工具”--->Internet选项---->选择"安全"标签页--->选择"自定义级别&q ...
- ubuntu 中 vim 的使用
安装 sudo apt install vim vim file_name #创建或者打开文件 vim file_name 定位到文件开头 vim file_name + 定位到文件末尾 vim f ...
- JavaScript 引用错误
在学习vue时 出现无法实现效果原始设置 <script src="js/lib/vue2.min.js"/><script src="js/lib/v ...
- docker镜像运行错误排查
docker做服务时,如果客户端无法连接,错误排查: 1.先使用 docker ps 查看镜像是否都在运行中,如果没有就进入镜像查看日志 2.如果确定代码及配置文件没有问题,就需要检查镜像的替换是否正 ...
- 团队Scrum冲刺阶段-Day 6
选择困难症的福音--团队Scrum冲刺阶段-Day 6 今日进展 编写提问部分 游戏分类的界面全部写完了!!!! 临时大家决定没有BGM的app不是一个完整的app,所以在大家共同学习的努力下,听完四 ...