大数据项目测试<二>项目的测试工作

大数据的测试工作:
1、模块的单独测试
2、模块间的联调测试
3、系统的性能测试:内存泄露、磁盘占用、计算效率
4、数据验证(核心)
下面对各个模块的测试工作进行单独讲解。
0. 功能测试
1. 性能测试
2. 自动化测试
3. 文档评审
4. 脚本开发
一、后台数据处理端
后端的测试重点,主要集中在数据的采集处理、标签计算效率、异常数据排查(功能),测试脚本编写(HiveQL)、自动化脚本编写(造数据、数据字段检查等)
1.数据的采集处理(Extract-Transform-Load)
ETL:即将数据从源系统加载到数据仓库的过程。源系统包括:数据文件(excel、log等)、RDD数据库、非RDD数据库等;
extract:从源系统提取需求数据。
transform:清洗数据(数据格式转化、异常数据处理等)。
Load:将清洗的数据加载至数据仓库。

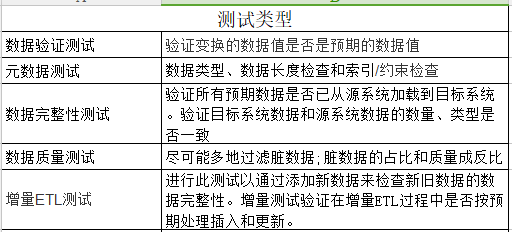
ETL测试:即确保根据需求将源系统的数据经过处理后加载到目标的数据是准确的。即源和目的数据之间转化过程中的数据验证。
测试类型
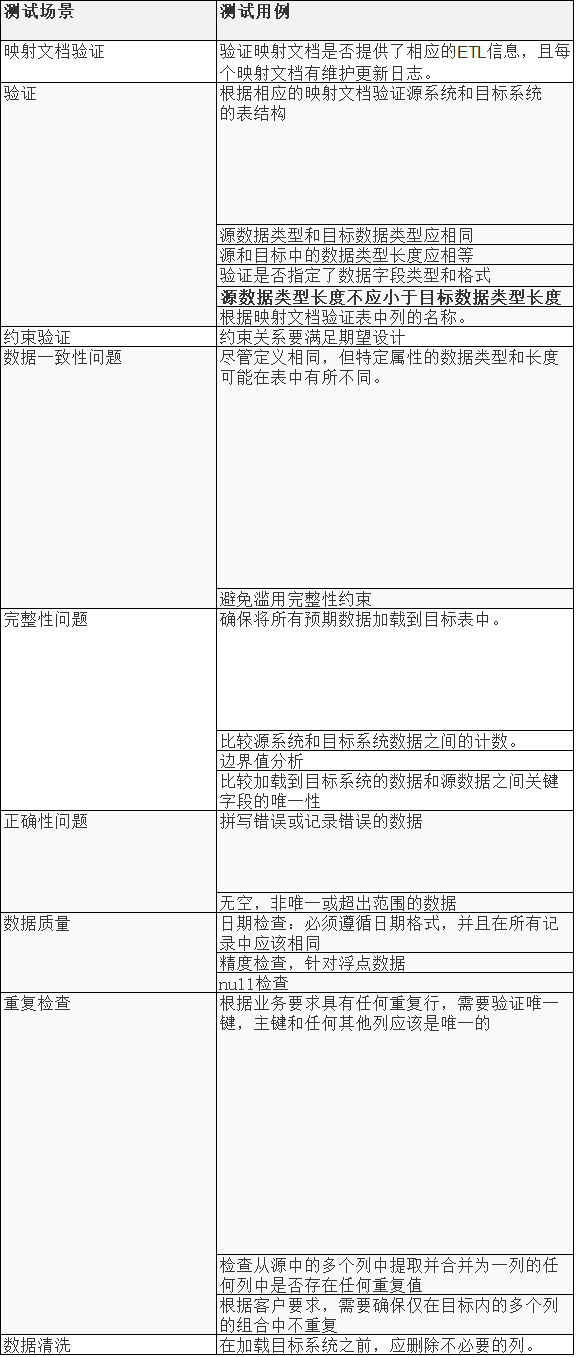
测试场景
券商等金融机构,其用户每天都会产生大量的交易数据,这部分数据最初都会存储在客户的关系型数据库中(oracle),因此后台每天需要先进行数据采集,将数据采集至Hadoop的hdfs系统;数据采集过后,需要对源数据进行一次数据清洗工作:过滤异常数据(NULL)、筛掉关联性较高的数据。
2.标签计算效率
根据标签文档编写hiveSQL、MR等标签计算代码,针对hiveSQL,不同的开发人员编写的sql质量不同,执行的效率也不相同;此部分不仅需要开发人员具备基本的复杂sql编写功底,也需要开发人员掌握一定的sql性能调优能力;在数据,服务器配置一定的情况下,效率的提升来源于对sql的优化;
由于hivesql的计算(都会转化成一个MR),需要大量的读写数据到磁盘的操作,因此计算效率较低;
impala则是将数据push到内存中,然后从内存中读取数据,效率有大幅提升,但是耗费了较高的服务器内存,成本较高;
Spark :内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销;
3.异常数据排查
异常值:分为两类:null,计算错误的值。 (1)Null值(标签下的数据均为NULL),首先 需求排查是否是数据的影响(例如 依赖数据缺失)。其次排查依赖数据的因素后,就需要排查是否是hiveSQL编写的问题和MR代码问题。(2)标签计算错误: 通过手工根据标签公式计算标签的值和通过hive计算得出的值进行对比,如果不一致,则需要排查是否是hivesql没有对标签公式进行精确实现。计算错误的值可以分为两类:1.明显错误(可以通过sql筛选出来的异常值,针对存在阈值的标签,比如股票仓位:仓位不得>1,如果出现>1的数据,则可以断定此标签计算有问题);2.非明显错误(此部分无法筛选出来,必须通过计算才能验证)
由于此部分计算好的数据需要导入到中台进行进一步运用,所以此部分的数据准确性有至关重要的作用。(测试人员需要对业务十分了解)
二、中台管理端
中台产品一般以web服务呈现。测试内容除了与普通的Java web项目相同,还要测试后台数据Export中台的过程中,数据类型、准确性、完整性、性能进行测试。
就目前的项目而言:测试计划的内容包括:需求文档测试、后台导出表的测试(表字段类型、数据完整性、浮点型数据精度、导出性能等)、中台接口测试(自动化)、前端UI页面测试、性能测试、安全测试、兼容性测试。
需求文档:需求点梳理、整理测试点、编写测试用例
数据连表导出:后台数据和中台数据的类型、精度要保持一致(中台数据库为MySQL,数据类型可能和后台的数据类型定义不一致,要确保数据类型转化的正确性);
中台接口测试:此部分可以进行接口自动化测试。
UI页面测试:根据需求文档、UI设计图编写测试用例
性能测试:中台接口的压测、中台服务缓存数据占服务器的内存空间测试
安全测试:根据公司安全测试手册进行测试(安全漏洞扫描)
兼容性测试:IE10
三、前端应用端
主要是app端的测试工作:一般的app测试工作,数据的核对(类型、精度等)
四、结尾
可以看出来,整个项目始终包含数据的验证工作。
附录:
异常值检查: https://www.cnblogs.com/xiaohuahua108/p/6237906.html
spark 优势: https://www.zhihu.com/question/31930662
接口测试: https://www.cnblogs.com/iloverain/p/9429116.html
大数据项目测试<二>项目的测试工作的更多相关文章
- 大数据入门:Maven项目的创建及相关配置
目录 Maven项目的创建及相关配置 一.Maven的介绍 1.Maven是什么: 2.Maven作用: 3.Maven项目的目录结构: 4.Maven的三点坐标: 5.maven的pom文件: 6. ...
- SqlBulkCopy类进行大数据(一万条以上)插入测试
好多天没写博客了,刚刚毕业一个多月! 关于上一篇博客中提到的,在进行批量数据插入数据库的时候可以通过给存储过程传递一个类型为Table的参数进行相关操作,在这个过程中本人没有进行效率的测试.后来查找发 ...
- SqlBulkCopy类进行大数据(10000万条以上)插入测试
好多天没写博客了,刚刚毕业一个多月,在IT的路上真是迷茫啊! 关于上一篇博客中提到的,在进行批量数据插入数据库的时候可以通过给存储过程传递一个类型为Table的参数进行相关操作,在这个过程中本人没有进 ...
- 转:SqlBulkCopy类进行大数据(一万条以上)插入测试
转自:https://www.cnblogs.com/LenLi/p/3903641.html 结合博主实例,自己测试了一下,把数据改为3万行更明显!! 关于上一篇博客中提到的,在进行批量数据插入数据 ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 入门大数据---Spark车辆监控项目
一.项目简介 这是一个车辆监控项目.主要实现了三个功能: 1.计算每一个区域车流量最多的前3条道路. 2.计算道路转换率 3.实时统计道路拥堵情况(当前时间,卡口编号,车辆总数,速度总数,平均速度) ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
随机推荐
- git 之连接tfs的git服务器
tfs中的git的管理,注意区分是主页地址,还是代码地址,代码地址中会有 _git http://ip:8080/tfs/p/elasticsearch6.2.0 http://ip:8080/t ...
- ISO 2501 quality model division 学习笔记
作为一个测试,学习质量模型,能够帮你 在测试设计的时候,从多个角度来思考测试用例的设计.而不仅仅是从 功能上, 同时 需要结合自己的产品,选择自己的侧重点,譬如我们公司的产品,安全性这一块 就比较小, ...
- python入门(十四):面向对象(属性、方法、继承、多继承)
1.任何东西1)属性(特征:通常可以用数据来描述)(类变量和实例变量)2)可以做一些动作(方法) 类来管理对象的数据.属性:类变量和实例变量(私有变量)方法: 1)实例方法 2)类方法 ...
- springboot+maven多模块工程dependency not found
参见:https://blog.csdn.net/m0_37943753/article/details/81031319. 重点是<dependencyManagement>标签的作用, ...
- python之字符串及其方法---整理集
字符串方法 1.capitalize方法:字符串首字母大写 举例: test="alex" v=test.capitalize() print(v) 返回结果: Alex 2.ca ...
- Servle第四篇(会话技术之cookie)
会话技术 什么是会话技术 基本概念: 指用户开一个浏览器,访问一个网站,只要不关闭该浏览器,不管该用户点击多少个超链接,访问多少资源,直到用户关闭浏览器,整个这个过程我们称为一次会话. 为什么我们要使 ...
- mysql concat筛选查询重复数据
SELECT * from (SELECT *,concat(field0,field1)as c from tableName) tt GROUP BY c HAVING count(c) > ...
- Java中代理
普通代理(最简单的代理) 需要有两个实现同一个接口的类,一个是被代理的类,一个是代理类 被代理类中我们按照自己想实现的功能重写接口中的方法 代理类中因为需要代理被代理类,所以在代理类中需要有个被代理类 ...
- C# 两个datatable中的数据快速比较返回交集或差集[z]
最基本的写法无非是写多层foreach循环,数据量多了,循环的次数是乘积增长的. 这里推荐使用Except()差集.Intersect()交集,具体性能没有进行对比. 如果两个datatable的字段 ...
- 6B - 火星A+B
读入两个不超过25位的火星正整数A和B,计算A+B.需要注意的是:在火星上,整数不是单一进制的,第n位的进制就是第n个素数.例如:地球上的10进制数2,在火星上记为“1,0”,因为火星个位数是2进制的 ...