【转载】路径双反斜杠!!!Python IDLE或Python shell中切换路径 切换目录os.chdir("C:\\python37\\2019pythonshel37\\diedai")
Python IDLE或shell中切换路径
在Python自带的编辑器IDLE中或者python shell中不能使用cd命令,那么跳到目标路径呢。方法是使用os包下的相关函数实现路径切换功能。
import os
os.getcwd() #获取当前路径
os.chdir("D:\\test") #跳到目标路径下
os.chdir('D:\\test') #单引号、双引号都可以
错误:
>>> os.chdir("C:\\python37\2019pythonshel37\diedai")
Traceback (most recent call last):
File "<pyshell#56>", line 1, in <module>
os.chdir("C:\\python37\2019pythonshel37\diedai")
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'C:\\python37\x819pythonshel37\\diedai'
正确:
>>> os.chdir("C:\\python37\\2019pythonshel37\\diedai")
[转载]说说Python程序的执行过程
1. Python是一门解释型语言?
我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!
为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。
2. 解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
再换成C#,C#首先是通过编译器将C#文件编译成IL文件,然后在通过CLR将IL文件编译成机器文件。所以我们说C#是一门纯编译语言,但是C#是一门需要二次编译的语言。同理也可等效运用到基于.NET平台上的其他语言。
3. Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java
java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
4. 简述Python的运行过程
在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
5. 运行一段Python程序
我们来写一段程序实际运行一下:
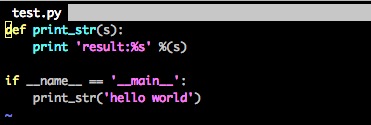
程序本身毫无意义。我们继续看:
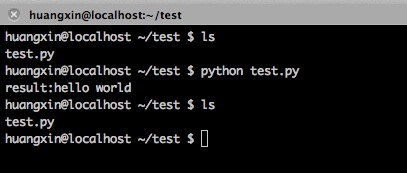
然而我们在程序中并没有看到pyc文件,仍然是test.py孤零零地呆在那!
那么我们换一种写法,我们把print_str方法换到另外的一个python模块中:
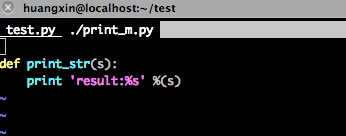
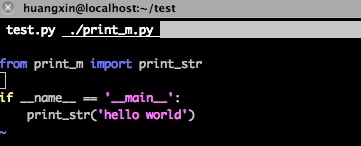
然后运行程序:
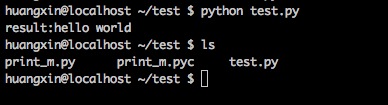
这个时候pyc文件出现了,其实认真思考一下不难得到原因,我们考虑一下实际的业务情况。
6. pyc的目的是重用
回想本文的第二段在解释编译型语言和解释型语言的优缺点时,我说编译型语言的优点在于,我们可以在程序运行时不用解释,而直接利用已经“翻译”过的文件。也就是说,我们之所以要把py文件编译成pyc文件,最大的优点在于我们在运行程序时,不需要重新对该模块进行重新的解释。
所以,我们需要编译成pyc文件的应该是那些可以重用的模块,这于我们在设计软件类时是一样的目的。所以Python的解释器认为:只有import进来的模块,才是需要被重用的模块。
这个时候也许有人会说,不对啊!你的这个问题没有被解释通啊,我的test.py不是也需要运行么,虽然不是一个模块,但是以后我每次运行也可以节省时间啊!
OK,我们从实际情况出发,思考下我们在什么时候才可能运行python xxx.py文件:
A. 执行测试时。
B. 开启一个Web进程时。
C. 执行一个程序脚本。
我们逐个来说,第一种情况我们就不用多说了,这个时候哪怕所有的文件都没有pyc文件都是无所谓的。
第二种情况,我们试想一个webpy的程序把,我们通常这样执行:

抑或者:

然后这个程序就类似于一个守护进程一样一直监视着8181/9002端口,而一旦中断,只可能是程序被杀死,或者其他的意外情况,那么你需要恢复要做的是把整个的Web服务重启。那么既然一直监视着,把PyCodeObject一直放在内存中就足够了,完全没必要持久化到硬盘上。
最后一个情况,执行一个程序脚本,一个程序的主入口其实很类似于Web程序中的Controller,也就是说,他负责的应该是Model之间的调度,而不包含任何的主逻辑在内,如我在http://www.cnblogs.com/kym/archive/2010/07/19/1780407.html中所提到,Controller应该就是一个Facade,无任何的细节逻辑,只是把参数转来转去而已,那么如果做算法的同学可以知道,在一段算法脚本中,最容易改变的就是算法的各个参数,那么这个时候给持久化成pyc文件就未免有些画蛇添足了。
所以我们可以这样理解Python解释器的意图,Python解释器只把我们可能重用到的模块持久化成pyc文件。
7. pyc的过期时间
说完了pyc文件,可能有人会想到,每次Python的解释器都把模块给持久化成了pyc文件,那么当我的模块发生了改变的时候,是不是都要手动地把以前的pyc文件remove掉呢?
当然Python的设计者是不会犯这么白痴的错误的。而这个过程其实就取决于PyCodeObject是如何写入pyc文件中的。
我们来看一下import过程的源码吧:

这段代码比较长,我们只来看我标注了的代码,其实他在写入pyc文件的时候,写了一个Long型变量,变量的内容则是文件的最近修改日期,同理,我们再看下载入pyc的代码:
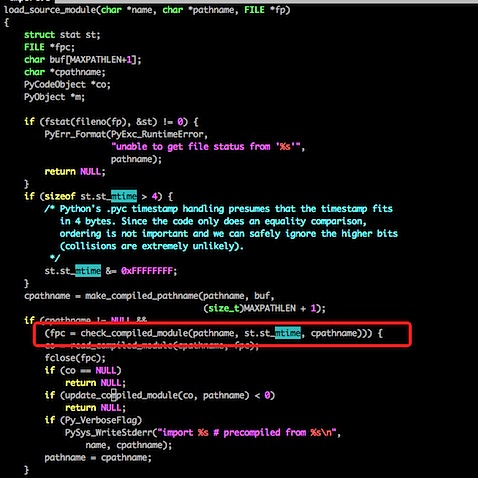
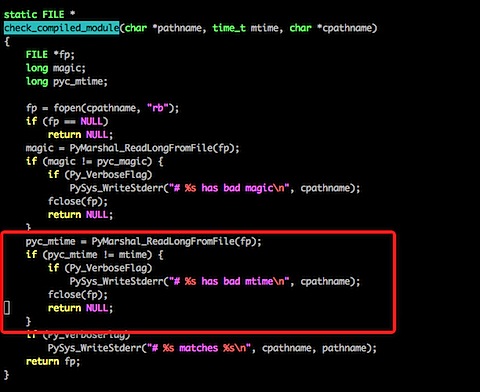
不用仔细看代码,我们可以很清楚地看到原理,其实每次在载入之前都会先检查一下py文件和pyc文件保存的最后修改日期,如果不一致则重新生成一份pyc文件。
8. 写在最后的
其实了解Python程序的执行过程对于大部分程序员,包括Python程序员来说意义都是不大的,那么真正有意义的是,我们可以从Python的解释器的做法上学到什么,我认为有这样的几点:
A. 其实Python是否保存成pyc文件和我们在设计缓存系统时是一样的,我们可以仔细想想,到底什么是值得扔在缓存里的,什么是不值得扔在缓存里的。
B. 在跑一个耗时的Python脚本时,我们如何能够稍微压榨一些程序的运行时间,就是将模块从主模块分开。(虽然往往这都不是瓶颈)
C. 在设计一个软件系统时,重用和非重用的东西是不是也应该分开来对待,这是软件设计原则的重要部分。
D. 在设计缓存系统(或者其他系统)时,我们如何来避免程序的过期,其实Python的解释器也为我们提供了一个特别常见而且有效的解决方案。
【转载】路径双反斜杠!!!Python IDLE或Python shell中切换路径 切换目录os.chdir("C:\\python37\\2019pythonshel37\\diedai")的更多相关文章
- python数据读取路径为啥要用双反斜杠?
Window下python读取数据路径可以有三种表示方式: (1)'c:\\a.txt' ——>转义的方式.表示这里\\是一个普通\字符,不容易出错(2)r'c:\a.txt' ——>声明 ...
- C/C++中相对路径与绝对路径以及斜杠与反斜杠的区别
1 绝对路径与相对路径 绝对路径表示相对容易得多,依次将文件所在盘符文件夹逐级展开就是绝对路径: ofstream infile("E:\\MyDoc\\file.txt", io ...
- 【本地资源路径&&网络资源路径&&正反斜杠在Java中的用法】
一.概念和用法 左正右反 先来看看转义字符的概念:通过 \ ,?来转变后面字母或符号的含义.意思就是改变字母本身的含义. 以"\"符号为例,JAVA中有很多操作,例如文件操作等,需 ...
- 带双反斜杠的Json数据至单反斜杠的Json数据处理
假如你光看标题,你只能哦呵呵了!我也看不懂.还是先描述下问题吧.这里是使用微信接口返回了一些数据.因为该串数据包含html标签所以TX是对该串数据进行了编码的.所有的数据是通过Unicode编码的,然 ...
- replace和replaceAll(路径反斜杠问题)
转载自:http://www.cnblogs.com/zhenmingliu/archive/2012/01/13/2321560.html 1)replace的参数是char和CharSequenc ...
- 拒绝让Eclipse帮倒忙,解决其复制粘贴时把反斜杠变成双反斜杠的问题
比如,你粘贴到字符串的文本是“C:\Users\horn1\Desktop”,结果变成了“C:\\Users\\horn1\\Desktop\\”,这还好,不会带来麻烦. 但是,比如你输入的是正则表达 ...
- python如何实现像shell中的case功能
我们知道在shell脚本里是支持case语句,当位置参数为空时,会提示我们怎么使用脚本 那么在python怎么实现呢?也使用case吗? python里不支持case语句,但是也有实现case的方法. ...
- [转载]Python正则表达式匹配反斜杠'\'问题
转载自csdnblog:Python正则表达式匹配反斜杠'\'问题 在学习Python正则式的过程中,有一个问题一直困扰我,如何去匹配一个反斜杠(即“\”)? 一.引入 在学习了Python特殊字符和 ...
- (转载)MySQL中执行sql语句反斜杠需要进行转义否则会被吃掉
(转载)http://www.phpcode8.com/lamp/mysql-lamp/mysql-escape-slash.html 最近在执行一个sql备份的还原后,发现系统的部分路径找不到,于是 ...
随机推荐
- oracle_hc.sql
select event,count(1) from gv$session group by event order by 2;exec dbms_workload_repository.create ...
- webservice之jax-rs实现方式
1.什么叫restful风格 restful是一组架构约束条件和原则,满足这些约束条件和原则的应用程序即是restful风格. 2.jax-rs实现步骤 1.创建一个简单应用(略) 2.添加依赖jar ...
- Windows 10 +VS2019 编译OpenCV 4.1.0
准备环境 安装cmake 官网 获取代码 github 下载拓展库opencv_contrib github 生成Sln cmake安装完后桌面会有一个快捷方式,可打开cmakeGUI,打开它. 第一 ...
- VS2017离线版的SSDT安装包(包括SSIS)
VS2017离线版的SSDT安装包(包括SSIS) 装好SQL2016和VS2017后发现没有创建SSIS项目的接口,原来VS2017里是没有包含SSDT的安装包的. 下面是我整理好的包含中英文的VS ...
- JAVA递归实现全排列
全排列(permutation) 排列组合概念 排列,就是指从给定n个数的元素中取出指定m个数的元素,进行排序 组合,则是指从给定n个数的元素中仅仅取出指定m个数的元素,不考虑排序 全排列 以数字为例 ...
- Mac git 上传到 github
上传本地项目到github 1.初始化本地项目 进入到你的项目,根目录下git init,会在你的项目的根目录下多出一个.git的文件夹,也许你的mac隐藏了,但是用命令行或者vscode等工具是可以 ...
- Oracle中文排序问题
默认感觉中文是按拼音排序,如果没实现效果,请加上其它排序,例如日期 表名为 dept ,其中name字段是中文,下面分别实现按照单位名称的笔划.部首和拼音排序.1: //按照笔划排序2: select ...
- chmod 755 是李鬼(转)
(1) 使用ls –l查看文件,前面显示的-rwxrwxr-x是什么意思? (2) chmod 755 xxx.sh又是什么意思? 1分钟简单说下,这两个和权限相关的问题. 先说下文件类型,访问方式, ...
- 快速获取IP地址的各种方法
调用百度的IP定位API(首先需要去百度开放平台注册申请key值http://lbsyun.baidu.com/apiconsole/key) http://api.map.baidu.com/loc ...
- js实现选中div内容并复制到剪切板
function copyUrl () { var div = document.getElementById('xxxx'); if (document.body.createTextRange) ...