python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口
具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地
刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就ok了嘛~但是,网上免费接口要么限制访问频率(淘宝的),要么限制访问次数(百度及其他)
没辙了,从百度找到了几个在线查询的接口,要么不够准确(或者说她们的数据库太旧了),要么就是速度太慢了,跟限制访问似的(没办法,小规模人家的服务器的确不够好)
于是乎就想到了百度首页的ip接口,就这货:
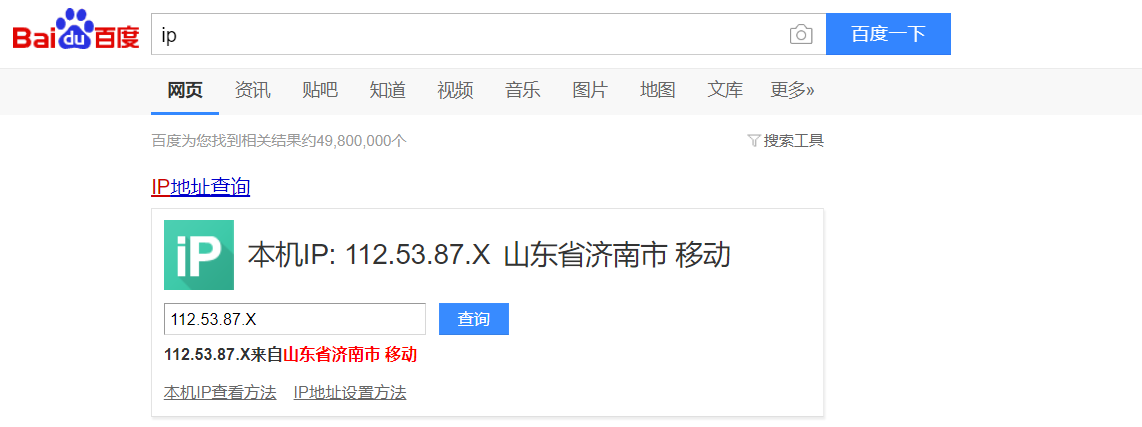
为了防止泄露隐私,其中ip地址信息已经在控制台稍作修改
随便输入一个ip,点击查询
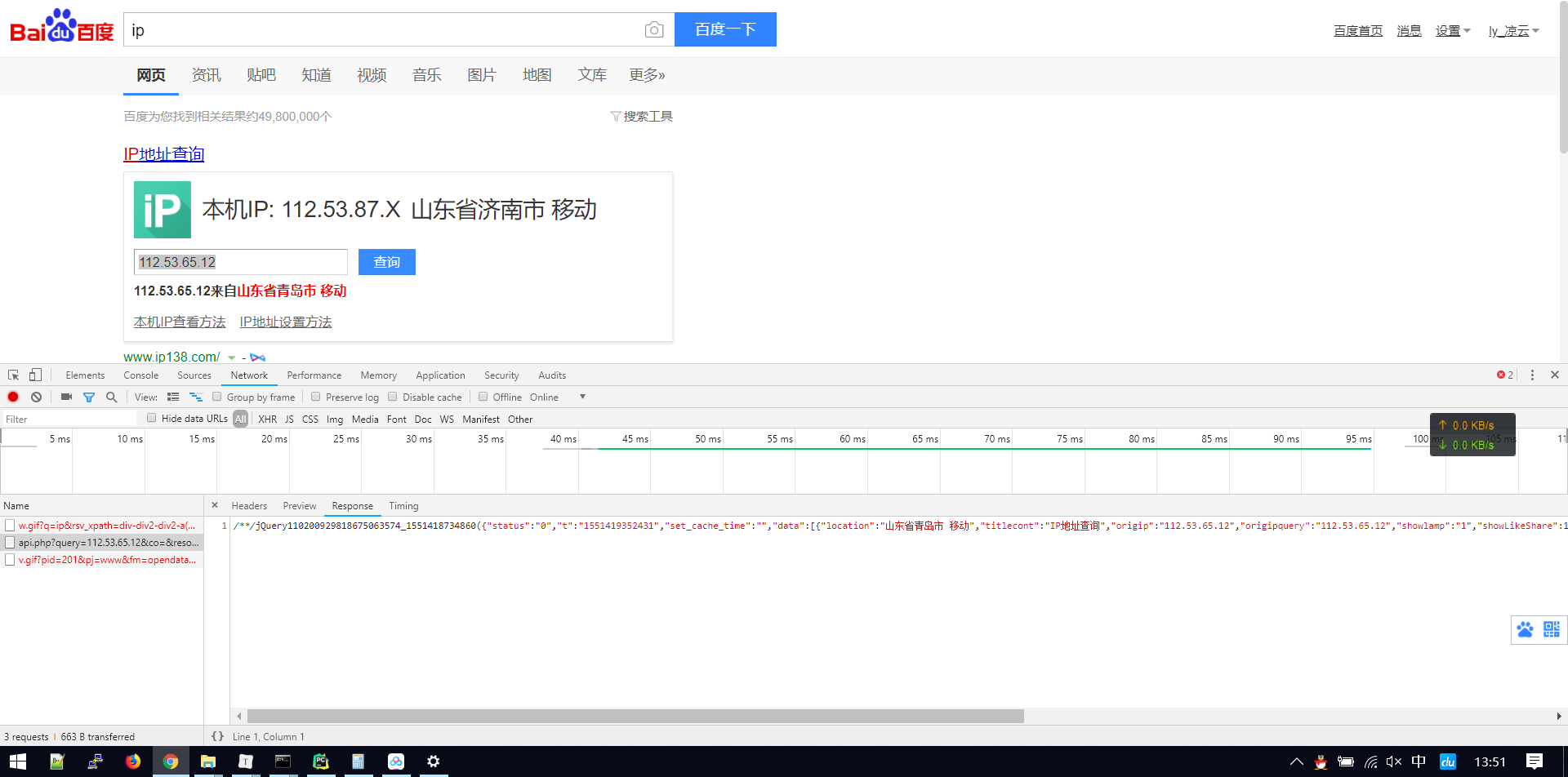
没想到,百度的接口竟然就这么暴露出来了,如此简单,试试能不能直接用
ip00.py
from pprint import pprint
import requests
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=112.53.65.12&co=&resource_id=6006&t=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb=jQuery110200929818675063574_1551418734860&_=1551418734868')
pprint(res.text)
返回结果:
('/**/jQuery110200929818675063574_1551418734860({"status":"0","t":"1551419352431","set_cache_time":"","data":[{"location":"山东省青岛市 '
'移动","titlecont":"IP地址查询","origip":"112.53.65.12","origipquery":"112.53.65.12","showlamp":"1","showLikeShare":1,"shareImage":1,"ExtendedLocation":"","OriginQuery":"112.53.65.12","tplt":"ip","resourceid":"6006","fetchkey":"112.53.65.12","appinfo":"","role_id":0,"disp_type":0}]});')
与浏览器访问返回结果一样,这个太出乎意料了,好吧,b厂还是留了点情面的,可是他们家的接口只能按年来买,大概要999RMB/年
再测试一下换个 ip 地址继续查询还能不能查到结果(防止后面的数据是加密的)
这个呢,其实最好的办法是在浏览器中进行测试,换个ip看一下控制台的url会不会有变化(主要是后面的参数),可能会存在加密数据,其实这个我测试了,会有一个参数变化 ,但是我重复提交时没发生改变一样能够请求数据,几乎就可以说明这个参数是迷惑用的(也可能是时间戳吧,我忘了具体什么参数了.时间戳的话就更好了,为了防止浏览器有缓存的)
ip01.py
from pprint import pprint
import requests
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=112.53.54.12&co=&resource_id=6006&t=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb=jQuery110200929818675063574_1551418734860&_=1551418734868')
pprint(res.text)
返回结果:
('/**/jQuery110200929818675063574_1551418734860({"status":"0","t":"1551419352431","set_cache_time":"","data":[{"location":"广东省 '
'移动","titlecont":"IP地址查询","origip":"112.53.54.12","origipquery":"112.53.54.12","showlamp":"1","showLikeShare":1,"shareImage":1,"ExtendedLocation":"","OriginQuery":"112.53.54.12","tplt":"ip","resourceid":"6006","fetchkey":"112.53.54.12","appinfo":"","role_id":0,"disp_type":0}]});')
ok,数据更换ip也是没有问题的,也不需要伪装agent
那么我们来尝试一下访问频率有没有限制:
这里先为大家介绍一个库:faker
这是一个python造假用的库,可以生成很多测试数据,姓名地址电话等等信息
这里推荐一位陌生老哥的博客:https://www.cnblogs.com/blueteer/p/10277725.html,如果不知道这个库,可以看一眼下面的 小demo:
faker_test.py
from faker import Faker
f = Faker('zh-CN')
print(f.ipv4())
返回结果:
101.208.5.200
这段代码就这点功能,就是可以生成随机ip地址
ip02.py
from pprint import pprint
import requests
from faker import Faker
f = Faker('zh-CN')
for i in range(100):
ip = f.ipv4()
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + ip +
'&co=&resource_id=6006&t'
'=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb'
'=jQuery110200929818675063574_1551418734860&_=1551418734868')
pprint(res.text)
这里稍微整理了一下url,就是换了个行而已
返回结果(太多了 ,截个图意思意思)

速度挺快,待会儿再测试一下它的耗时到底有多少
数据杂乱不好整理,直接来个简单粗暴的分割字符串吧:
稍作修改后:
ip03.py
import requests
from faker import Faker
f = Faker('zh-CN')
for i in range(100):
ip = f.ipv4()
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + ip +
'&co=&resource_id=6006&t'
'=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb'
'=jQuery110200929818675063574_1551418734860&_=1551418734868')
text = res.text
location = text.split('location":"')[1].split('","titlecont')[0]
print(location)
吓死我了,刚才断网了,我还以为百度的这条路只能走这么远了呢,毕竟我上午已经弄了不少数据了,下午就不行的话,我这一上午岂不是白瞎了
返回结果
澳大利亚
澳大利亚
广东省 电信
韩国
美国
美国
美国
比利时
美国
美国
...后面的不发了,太长了
最后,来计个时
ip04.py
from time import time
import requests
from faker import Faker
# 获取当前秒级时间戳
t1 = int(time())
f = Faker('zh-CN')
for i in range(100):
ip = f.ipv4()
res = requests.get(
'https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + ip +
'&co=&resource_id=6006&t'
'=1551419352431&ie=utf8&oe=gbk&cb=op_aladdin_callback&format=json&tn=baidu&cb'
'=jQuery110200929818675063574_1551418734860&_=1551418734868')
text = res.text
location = text.split('location":"')[1].split('","titlecont')[0]
print(location)
t2 = int(time())
print(t2 - t1)
返回结果:
...
美国
美国
美国
荷兰
美国
美国
澳大利亚
澳大利亚
19
还不错吧,100个耗时19秒,想要更快可以试试java或者多线程吧,反证我就用这一次,而且也不赶时间,估计今晚就把我那些数据搞定了
最后娱乐一下,缩减一下代码行数(计时就去掉了,反正对我也没什么实际用途)
import requests;from faker import Faker;f = Faker('zh-CN');print([requests.get('https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?query=' + f.ipv4() +'&resource_id=6006&_='+str(i)).text.split('ation":"')[1].split('","tit')[0] for i in range(10)])
这里主要是精简了一部分url,不知道修改后还好不好使了
python一行代码(251字)搞定爬取百度ip接口并实现查询数据(欢呼)
好险这字数,还好没再删东西,哈哈哈,别整这些没用的了
python爬取免费优质IP归属地查询接口的更多相关文章
- 极简代理IP爬取代码——Python爬取免费代理IP
这两日又捡起了许久不碰的爬虫知识,原因是亲友在朋友圈拉人投票,点进去一看发现不用登陆或注册,觉得并不复杂,就一时技痒搞一搞,看看自己的知识都忘到啥样了. 分析一看,其实就是个post请求,需要的信息都 ...
- 第二篇 - python爬取免费代理
代理的作用参考https://wenda.so.com/q/1361531401066511?src=140 免费代理很多,但也有很多不可用,所以我们可以用程序对其进行筛选.以能否访问百度为例. 1. ...
- golang爬取免费代理IP
golang爬取免费的代理IP,并验证代理IP是否可用 这里选择爬取西刺的免费代理Ip,并且只爬取了一页,爬取的时候不设置useAgent西刺不会给你数据,西刺也做反爬虫处理了,所以小心你的IP被封掉 ...
- 免费IP归属地查询接口汇总
目前做一个项目,需要判断是国内还是国外的IP,具体要求为接口稳定,速度快,免费,不异常,所以我整理了优质的接口供大家筛选. IP归属地查询API 一,淘宝API接口 http://ip.taobao. ...
- 简单爬虫-爬取免费代理ip
环境:python3.6 主要用到模块:requests,PyQuery 代码比较简单,不做过多解释了 #!usr/bin/python # -*- coding: utf-8 -*- import ...
- PHP简单爬虫 爬取免费代理ip 一万条
目标站:http://www.xicidaili.com/ 代码: <?php require 'lib/phpQuery.php'; require 'lib/QueryList.php'; ...
- 使用python调用淘宝的ip地址库查询接口结合zabbix判断dnspod域名解析是否正确
#encoding:utf-8 import socket import requests import json ''' 使用python结合zabbix判断dnspod域名解析是否正确 服务器分国 ...
- python爬取github数据
爬虫流程 在上周写完用scrapy爬去知乎用户信息的爬虫之后,github上star个数一下就在公司小组内部排的上名次了,我还信誓旦旦的跟上级吹牛皮说如果再写一个,都不好意思和你再提star了,怕你们 ...
- 爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码 先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制, ...
随机推荐
- 兄弟连学python---网络简介
网络简介 1.什么是网络 网络是辅助双方能够连接在一起的工具 使用网络的目的 为了联通多方然后进行通讯,能够让软件在不同的电脑上运行,相互传输数据 网络的发展 网络协议 什么是协议 约定俗成的,没有理 ...
- 一个权重的物体拷贝权重给多个(oneWeightToMany)
你是否在做项目的时候经常会遇见一个物体带权重需要拷贝给其他物体,这时候其他物体多的数不胜数 你怎么办呢? 举例:假如一头狮子 身体你已经做好了,但是模型师把半个身体都做满了垂落的实体模型毛发,你是否感 ...
- Selenium3+python几种定位元素的方法
学习小结: 这里使用ChromeV73+web driver 2.46 #几种定位方式: #Autotest.py from selenium import webdriver from seleni ...
- 学习笔记DL007:Moore-Penrose伪逆,迹运算,行列式,主成分分析PCA
Moore-Penrose伪逆(pseudoinverse). 非方矩阵,逆矩阵没有定义.矩阵A的左逆B求解线性方程Ax=y.两边左乘左逆B,x=By.可能无法设计唯一映射将A映射到B.矩阵A行数大于 ...
- vue---条件与循环语句
<!DOCTYPE html><html><head> <meta charset="utf-8"> <meta name=& ...
- css里px em rem特点(转)
1.px特点: 1.IE无法调整px作为单位的字体大小: 2.Firefox能够调整px.em和rem. px是像素,是相对长度单位,是相对于显示器屏幕分辨率而言的. 2.em特点: 1.em的值并不 ...
- 引擎设计跟踪(九.14.3) deferred shading 准备
目前做的一些准备工作 1.depth prepass for forward shading. 做depth prepass的原因是为了完善渲染流程, 虽然架构上支持多个pass, 但实际上从来没有测 ...
- 记NOIP2018
day0 中午在机房水了一波出发,坐了一下午的车,5点到了大门对面的红旗宾馆.南山中学的和我们住在一个宾馆里面,Z教练似乎同他们关系很好,见面还打招呼. 红旗宾馆附近特别偏僻,出门就是修路的工地,后面 ...
- Xshell5一打开就提示要使用该程序,请更新至最新版本
网上有两种方法 方法一:临时 修改系统时间,修改为一年前的时间即可.但是你会发现修改回当前时间后,xshell又打不开了 方法二:替换xshell文件 找到xshell安装位置,如果是快捷方式,可以右 ...
- zabbix和iptables的nat表结合使用
A 机器要去访问C机器,但是无法直接访问到A可以访问到B机器,B机器可以访问到C机器这时候就可以再B机器设置nat,让A机器访问C机器 正好工作中zabbix server要监控2个http地址,缺无 ...