爬虫基础——HTTP基本原理
## 学习爬虫务必从了解请求网页的工作流程和网页的组成原理开始,不然直接去学爬虫操作像是请求库等等,大概率会知其然而不知其所以然(个人体会)
URL和HTTP简介
URL(Uniform Resource Locator):统一资源定位符
下面通过百度贴吧的网址来看一下它们到底是个什么玩意儿:
https://tieba.baidu.com/index.html
这个网址其实就是所谓的URL,它的作用就是指定“资源”的访问方式。
其中包括访问协议(https)、访问路径(//tieba.baidu.com/)、资源名称(index.html)。
HTTP(Hyper Text Transfer Protocol):超文本传输协议
首先了解一下“超文本”的概念:
超文本就是利用超链接将各种不同空间的文字信息组成在一起的网状文本(百度百科定义)。它将整个Web网络连接起来。
我们在浏览器看到的网页就是超文本解析而成的,超文本在我们实际应用中体现在哪里呢?
当我们打开浏览器,从一个站点点击链接进入下一个站点,就相当于从超文本的一个空间进入另一个空间,浏览器再将其解析出来,就是我们看到的页面了。
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer):超文本传输安全协议
通俗讲HTTPS就是HTTP的安全版,通过它传输的内容都是经过SSL加密的。
爬虫抓取的页面通常都是http或https协议的。
HTTP请求过程
我们再浏览器输入一个URL,回车之后再浏览器中看到想要的页面内容。
接下来我们分析一下其具体过程:
- 浏览器向网站(你输入的URL)所在的服务器发送请求
- 网站服务器收到请求后对其进行处理和解析
- 网站服务器返回对应的响应
- 浏览器解析返回的响应
为了更加直观的说明这个过程,利用Chrome浏览器的开发者模式下的Network监听组件做下演示,它可以显示访问当前网页时发生的所有网络请求和响应。
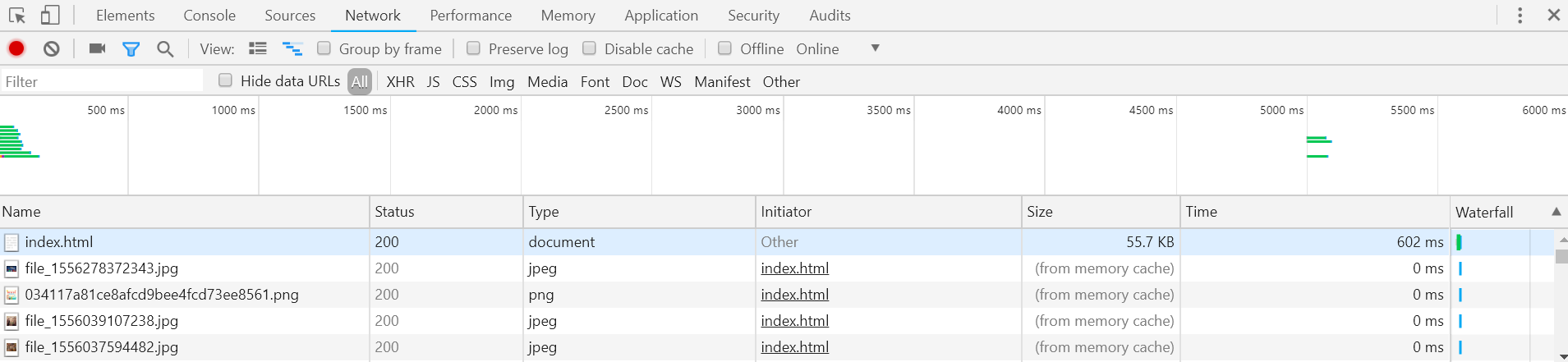
观察第一个网络请求,index.html
各列含义如下:
- Status:状态码(此处200代表成功响应)。
- Type:请求或响应的文档类型(document代表请求的是一个HTML文档)。
- Initiator:请求源。
- Size:从服务器下载的文件和请求的资源大小。如果是从缓存中获取的资源,则该列会显示from memory cache。
- 注:大家自己动手操作过程中“index.html”下面的响应的Size并不是from memory chche。这是因为这次响应是我在打开该页面后刷新得到的,此时请求的资源已经暂存在cache中了,详见下面介绍中响应头的Expires。
- Time:从发起请求到获取响应的总时间。
- Waterfall:网络请求的可视化瀑布流。
点击“index.html”可看到更详细的信息:

Remote Address:远程服务器(资源所在的服务器)的地址和端口
Referrer Policy:Referrer判别策略(没有详细了解,初入门并不常见,可以略过)
常见的请求方法有两种:
GET:百度搜索Python,链接为https://www.baidu.com/s?wd=Python,这就是一个GET请求,请求的参数(此处为wd=Python)直接包含到URL里。GET请求提交的数据最多1024kb
POST:大多在提交表单时发起,数据包含在请求体中。比如登陆表单的传输,登录时,需要输入用户名和密码,若使用GET请求,密码就会暴露在URL中。
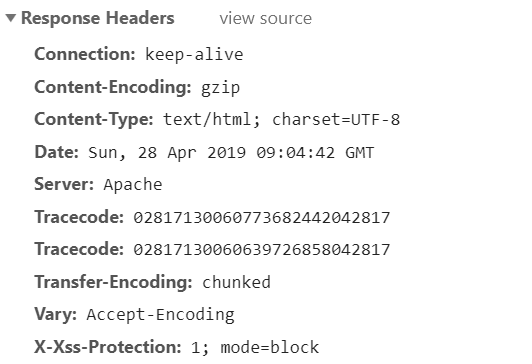
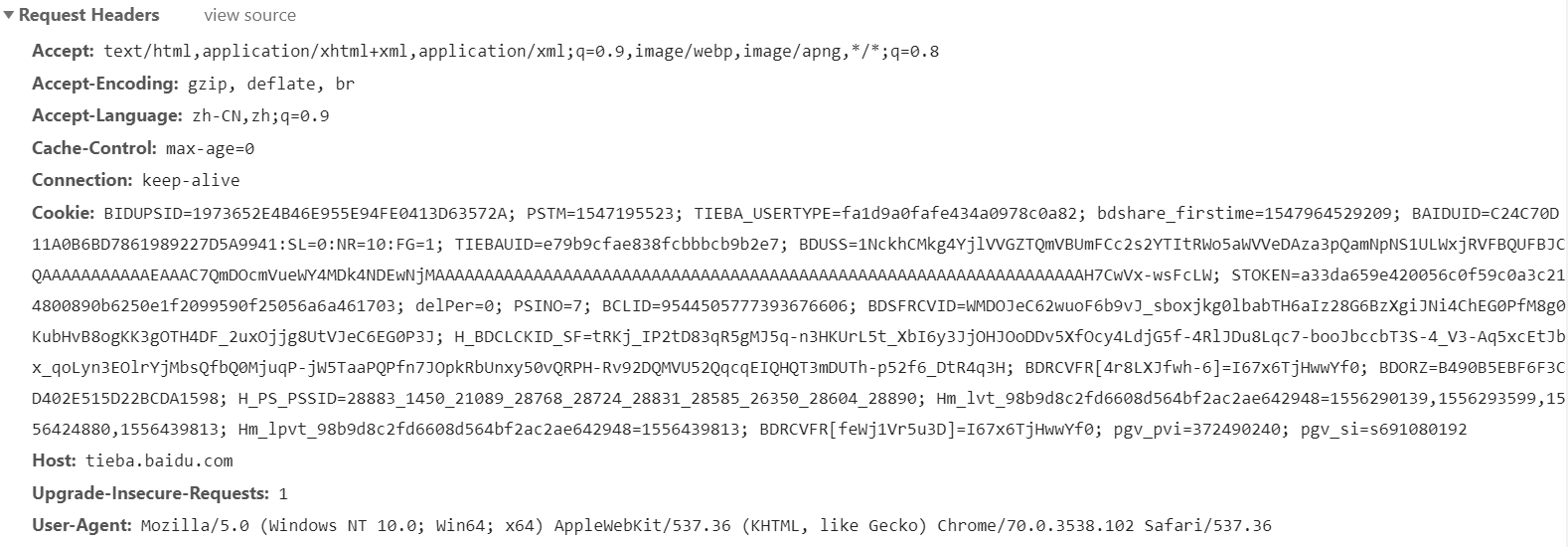
请求
请求的网址(Request URL)
请求方法(Request Method)
请求头(Request Headers)
Accept:指定客户端可接受哪些类型的信息
Accept-Language:指定客户端可接受的语言类型
Accept-Encoding:指定客户端可接受的内容编码
Host:指定请求资源的主机IP和端口号,其内容为请求URL的原始服务器或网关的位置。
Cookie(重要):网站为了辨别用户(此处断句,不然可能会绕晕了)进行会话跟踪而存储在用户本地的数据,主要功能是维持当前访问会话。当我们输入用户 名和密码登录某个网站后,本地会有一个服务器返回的Cookie,每次浏览器请求该站点的页面时(我们会发现并不用再次登录),都会在请求头中加上Cookie,服务器便可以识别该Cookie对应的会话。
User-Agent(重要):使服务器识别客户使用的操作系统及版本、浏览器及版本等信息。用Python做爬虫时,不加此信息会被识别处为爬虫。
Reffer:标识该请求从哪个页面发出。
Content-Type(重要):标识具体请求中的媒体类型信息。如text/html代表HTML文档,image/gif代表GIF图片等。
请求体(Request Body)
一般承载的是POST请求中的表单数据,对于GET请求,请求体为空。
响应
响应状态码(Response Status Code)
此处只列举几个较为常见的状态码:
200:服务器正常响应。
403:禁止访问,服务器拒绝此请求。
404:服务器找不到请求的网页。
500:服务器内部发生错误。
响应头(Response Headers)
Date:响应产生的时间。
Last-Modified:资源的最后修改时间
Cotent-Encoding:响应内容的编码方式。
Server:包含服务器的信息。
Content-Type:文档类型,指定返回的数据类型是什么。
Set-Cookie:设置Cookies。告诉浏览器需要将此内容放在Cookies中,下次请求携带Cookies请求。(前面对Cookie没理解的结合此处再回头看一下,应该会好理解一些)
Expires:响应的过期时间,可以使代理服务器或浏览器将加载的内容更新的缓存中。再次访问即可直接从缓存加载。
响应体(Response Body)
响应的正文数据都再响应体中,比如请求网页时,它的响应体就算网页的HTML代码,请求一张图片时,它的响应体就是图片的二进制数据。
我们做爬虫请求网页后,要解析的就是响应体,从而得到网页的源代码、JSON数据等,然后从中做相应内容的提取。
## 结束语:这是我的第一篇技术类博客,同时我也还在Python爬虫学习的道路上摸索,如有不足之处还请见谅,欢迎指正。
爬虫基础——HTTP基本原理的更多相关文章
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python 3.x 爬虫基础---Urllib详解
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 前言 爬虫也了解了一段时间了希望在半个月的时间内 ...
- python 3.x 爬虫基础---常用第三方库(requests,BeautifulSoup4,selenium,lxml )
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---常用第三方库 ...
- java网络爬虫基础学习(三)
尝试直接请求URL获取资源 豆瓣电影 https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort= ...
- java网络爬虫基础学习(一)
刚开始接触java爬虫,在这里是搜索网上做一些理论知识的总结 主要参考文章:gitchat 的java 网络爬虫基础入门,好像要付费,也不贵,感觉内容对新手很友好. 一.爬虫介绍 网络爬虫是一个自动提 ...
- python从爬虫基础到爬取网络小说实例
一.爬虫基础 1.1 requests类 1.1.1 request的7个方法 requests.request() 实例化一个对象,拥有以下方法 requests.get(url, *args) r ...
- 爬虫基础以及 re,BeatifulSoup,requests模块使用
爬虫基础以及BeatifulSoup模块使用 爬虫的定义:向网站发起请求,获取资源后分析并提取有用数据的程序 爬虫的流程 发送请求 ---> request 获取响应内容 ---> res ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
随机推荐
- vue+axios跨域解决方法
通过这种方法也可以解决跨域的问题. 使用http-proxy-middleware 代理解决(项目使用vue-cli脚手架搭建) 例如请求的url:“http://f.apiplus.cn/bj11x ...
- Swift中enum, struct, class的有关使用方法
import Foundation print("Hello, World!") let a = var b = var c = a + b; c = //重载:函数名相同, 函数 ...
- maven安装本地jar包到本地仓库命令
mvn install:install-file -Dfile=C:\Users\windows\.m2\repository\com\jayway\jsonpath\json-path\2.2.0\ ...
- Mabatis面试题
Mybatis面试题 1请写出Mybatis核心配置文件MyBatis-config.xml的内容? <?xml version="1.0" encoding="U ...
- .net core+Spring Cloud学习之路 一
文章开头唠叨两句. 2019年了,而自己参加工作也两年有余了,用一个词来概括这两年多的生活,就是:“碌碌无为”. 也不能说一点收获都没有,但是很少.2019来了,我立志要打破现状,改变自己,突破自我. ...
- 关于E-R图
E-R图 简介: E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型.属性和联系的方法.用来描述现实世界的概念模型.它是描述现实世界概念结构模型的有 ...
- @EnableScheduling注解
@EnableScheduling 开启对定时任务的支持 其中Scheduled注解中有以下几个参数: 1.cron是设置定时执行的表达式,如 0 0/5 * * * ?每隔五分钟执行一次 ...
- robotframework中的用evaluate关键字进行运算(随机数+转换+运算)
当我们在写rf测试用例时,可能需要随机产生一些数据,可能需要将已有的数据进行转换,做简单的运算等:此时我们可以用万能的evaluate来实现 ,后面一般均适用python表达式来进行实现. 接下来详细 ...
- c#实现识别图片上的验证码数字
这篇文章主要介绍了c#实现识别图片上的验证码数字的方法,本文给大家汇总了2种方法,有需要的小伙伴可以参考下. ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1 ...
- mysql的事务和数据库锁的关系
数据库加事务并不是数据就安全来了,事务和锁要分析清楚和配合使用 问题背景处于对高并发的秒杀环节的理解整理如下: 秒杀的时候高并发主要注意1.在秒杀的情况下,肯定不能如此高频率的去读写数据库,会严重造成 ...