Hulu大规模容器调度系统Capos
Hulu是美国领先的互联网专业视频服务平台,目前在美国拥有超过2000万付费用户。Hulu总部位于美国洛杉矶,北京办公室是仅次于总部的第二大研发中心,也是从Hulu成立伊始就具有重要战略地位的分支办公室,独立负责播放器开发,搜索和推荐,广告精准投放,大规模用户数据处理,视频内容基因分析,人脸识别,视频编解码等核心项目。
在视频领域我们有大量的视频转码任务;在广告领域当我们需要验证一个投放算法的效果时,我们需要为每种新的算法运行一个模拟的广告系统来产出投放效果对比验证;在AI领域我们需要对视频提取帧,利用一些训练框架产出模型用于线上服务。这一切都需要运行在一个计算平台上,Capos是Hulu内部的一个大规模分布式任务调度和运行平台。
Capos是一个容器运行平台,包含镜像构建,任务提交管理,任务调度运行,日志收集查看,metrics收集,监控报警,垃圾清理各个组件。整个平台包含的各个模块,如下图所示:
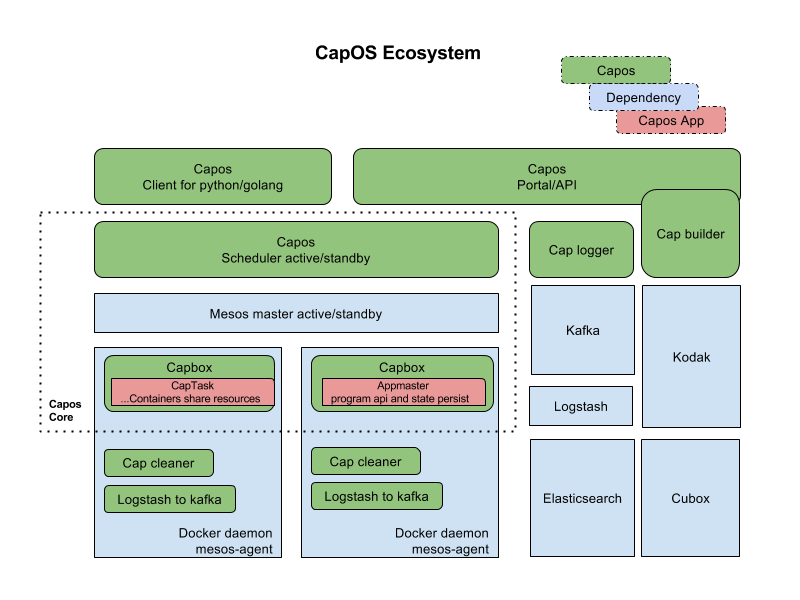
用户可以在界面上创建镜像描述符,绑定github的repo,生成镜像。之后在界面上创建作业描述符,填上镜像地址,启动参数,资源需求,选择资源池,就可以运行作业,看作业运行日志等。这些所有操作也可以通过restapi来调用,对于一些高级的需求,capos提供golang和python的sdk,可以让用户申请资源,然后启动作业,广告系统就是利用sdk,在capos上面申请多个资源,灵活的控制这些资源的生命周期,一键启动一个分布式的广告系统来做模拟测试。
Capos大部分组件都是用Golang实现的,Capos的核心组件,任务调度运行CapScheduler是今天主要和大家分享和探讨的模块。CapScheduler是一个基于mesos的scheduler,负责任务的接收,元数据的管理,任务调度。CapExecutor是mesos的一个customized executor,实现Pod-like的逻辑,以及pure container resource的功能,在设计上允许Capos用户利用capos sdk复用计算资源做自定义调度。
Capos Scheduler的架构图如下所示:
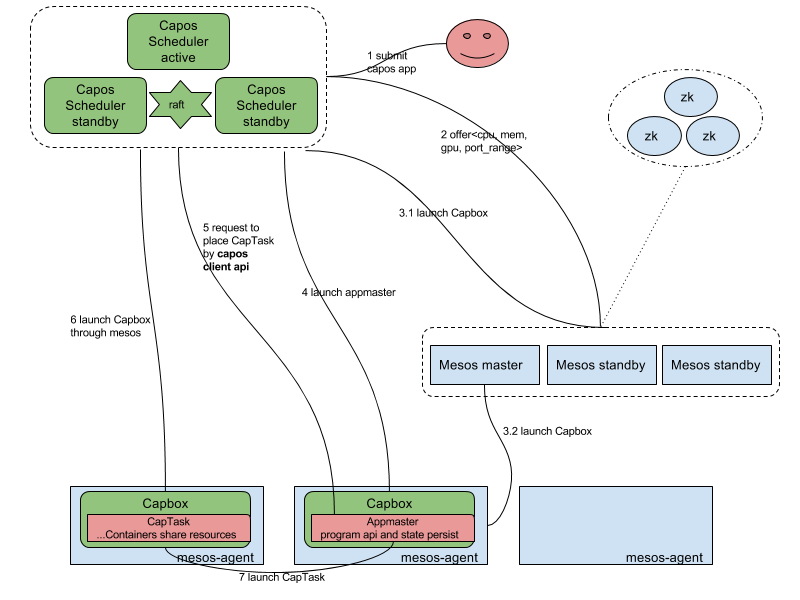
上图浅蓝色部分是mesos的组件,包括mesos master,mesos agent,mesos zookeeper。mesos作用是把所有单体的主机的资源管理起来,抽象成一个cpu,memory,port,gpu等的资源池,供之上的capos scheduler使用。
其中capos scheduler是一个active-standy的HA模型,在scheduler中我们实现了一个raft based的k-v用来存储metadata,active的scheduler注册成为mesos之上的一个framework,可以收到资源,根据调度策略来启动作业。
Capbox是一个定制实现的mesos的executor,作为mesos agent的资源的占位符,接收请求与mesos agent上的docker daemon通信启动容器。其中也实现了POD-like的功能,同时可以启动多个容器共享network,磁盘等。
Capos scheduler提供两类作业运行,一个是简单作业直接在Capbox运行,另一个是复杂带有编程语义的作业,我们称之为appmaster,其本身运行占用一个capbox,然后通过编程语义二次申请capbox运行作业。
首先说明下简单作业运行流程,这里的简单作业,提交的作业通过json描述,可以包含多个container,然后scheduler收到请求之后,命中某个offer,向mesos发送offer启动请求,在请求中同时夹带着作业json信息,把作业启动起来,scheduler根据mesos状态同步信息来控制作业的生命周期。
如果是appmaster programmatically二次调度的作业,首先需要把appmaster启动,这部分和简单作业运行是一致的,然后appmaster再申请一个到多个资源来启动capbox,运行作业。此时appmaster申请的capbox的生命周期完全由appmaster决定,所以这里appmaster可以复用capbox,或者批量申请capbox完成自己特定的调度效果。多说一句,appmaster可以支持client-mode和cluster-mode,client-mode是指appmaster运行在集群之外,这种情况适用于把appmaster嵌入在用户原先的程序之中,在某些场景更符合用户的使用习惯。
说完capos的使用方式后,我们可以聊下在capos系统中一些设计的思考:
1 Scheduler的调度job和offer match策略,如下图所示:

1.1 缓存offer。当scheduler从mesos中获取offer时候,capos scheduler会把offer放入到cache,offer在TTL后,offer会被launch或者归还给mesos,这样可以和作业和offer的置放策略解耦。
1.2 插件化的调度策略。capos scheduler会提供一系列的可插拔的过滤函数和优先级函数,这些优先级函数对offer进行打分,作用于调度策略。用户在提交作业的时候,可以组合过滤函数和优先级函数,来满足不同workload的调度需求。
1.3 延迟调度。当一个作业选定好一个offer后,这个offer不会马上被launch,scheduler会延迟调度,以期在一个offer中match更多作业后,再launch offer。获取更高的作业调度吞吐。
2 Metadata的raft-base key value store
2.1 多个scheduler之间需要有一个分布式的kv store,来存储作业的metadata以及同步作业的状态机。在scheduler downtime切换的时候,新的scheduler可以接管,做一些recovery工作后,继续工作。
2.2 基于raft实现的分布式一致性存储。Raft是目前业界最流行的分布式一致性算法之一,raft依靠leader和WAL(write ahead log)保证数据一致性,利用Snapshot防止日志无限的增长,目前raft各种语言均有开源实现,很多新兴的数据库都采用 Raft 作为其底层一致性算法。Capos利用了etcd提供的raft lib (https://github.com/coreos/etcd/tree/master/raft), 实现了分布式的一致性数据存储方案。etcd为了增强lib的通用性,仅实现了raft的核心算法,网络及磁盘io需要由使用者自行实现。Capos中利用etcd提供的rafthttp包来完成网络io,数据持久化方面利用channel并行化leader的本地数据写入以及follower log同步过程,提高了吞吐率。
2.3 Capos大部分的模块都是golang开发,所以目前的实现是基于etcd的raft lib,底层的kv存储可以用boltdb,badger和leveldb。有些经验可以分享下,在调度方面我们应该关注关键路径上的消耗,我们起初有引入stormdb来自动的做一些key-value的index,来加速某些带filter的查询。后来benchmark之后发现,index特别在大规模meta存储之后,性能下降明显,所以目前用的纯kv引擎。在追求高性能调度时候,写会比读更容器达到瓶颈,boltdb这种b+ tree的实现是对读友好的,所以调度系统中对于kv的选型应该着重考虑想leveldb这种lsm tree的实现。如果更近一步,在lsm tree基础上,考虑kv分离存储,达到更高的性能,可以考虑用badger。不过最终选型,需要综合考虑,所以我们底层存储目前实现了boltdb,badger和leveldb这三种引擎。
3 编程方式的appmaster
3.1 简单的作业可以直接把json描述通过restapi提交运行,我们这边讨论的是,比较复杂场景的SaaS,可能用户的workload是一种分布式小系统,需要多个container资源的运行和配合。这样需要capos提供一种编程方式,申请资源,按照用户需要先后在资源上运行子任务,最终完成复杂作业的运行。
3.2 我们提供的编程原语如下, Capbox.go capbox是capos中资源的描述
package client import (
"capos/types/server"
) type CapboxCallbackHandler interface {
OnCapboxesRunning(*prototypes.Capbox) error
OnCapboxesCompleted(*prototypes.Capbox) error
} type RecoveryCapboxHandler interface {
GetCallbackHandler(string) (CapboxCallbackHandler, error)
} type AMSchedulerLifeCycle interface {
Start(*prototypes.AMContext) (*prototypes.RegisterAMResponse, error)
Stop() error
} type AMSchedulerAction interface {
// container resource api
CreateCapbox(*prototypes.CapboxRequest, CapboxCallbackHandler) (*prototypes.Capbox, error)
ReleaseCapbox(string) error PreviousStateRecovery(*prototypes.RegisterAMResponse, RecoveryCapboxHandler) error
PreviousStateDrop(*prototypes.RegisterAMResponse) error GetCapAgentsSnapshot() ([]*prototypes.CapAgent, error) ListenCapboxStateChange()
StopListenCapboxStateChange()
}
appmaster可以用这些api可以申请资源,释放资源,获取资源的状态更新,在此基础上可以实现灵活的调度。
Task.go task也就是可以在capbox上运行的task, 如下图所示
package client import (
"capos/types/server"
) type TaskCallbackHandler interface {
OnTaskCompleted(*prototypes.CapTask) error
} type RecoveryTaskHandler interface {
GetCallbackHandler(capboxId string, taskId string) (TaskCallbackHandler, error)
} type AMCapboxLifeCycle interface {
Start() error
Stop() error
} type AMCapboxAction interface {
// task management api
StartTask(*prototypes.Capbox, *prototypes.CapTaskRequest, TaskCallbackHandler) (*prototypes.CapTask, error)
StopTask(*prototypes.Capbox, string) error
ListTask(*prototypes.Capbox) ([]*prototypes.CapTask, error) PreviousStateRecovery(*prototypes.RegisterAMResponse, RecoveryTaskHandler) error ListenCapTaskStateChange()
StopListenCapTaskStateChange()
}
在资源基础上,appmaster可以用api启动/停止作业,appmaster也可以复用资源不断的启动新的作业。基于以上的api,我们可以把广告模拟系统,AI框架tensorflow,xgboost等分布式系统运行在Capos之上。
4 capos对比下netflix开源的titus和kubernetes
4.1 netflix在今年开源了容器调度框架titus,Titus是一个mesos framework, titus-master是基于fenso lib的java based scheduler,meta存储在cassandra中。titus-executor是golang的mesos customized executor。因为是netflix的系统,所以和aws的一些设施是绑定的,基本上在私有云中不太适用。
4.2 Kubernetes是编排服务方面很出色,在扩展性方面有operator,multiple scheduler,cri等,把一切可以开放实现的都接口化,是众人拾柴的好思路,但是在大规模调度短作业方面还是有提升空间。
4.3 Capos是基于mesos之上的调度,主要focus在大规模集群中达到作业的高吞吐调度运行。
在分布式调度编排领域,有诸多工业界和学术界的作品,比如开源产品Mesos,Kubernetes,YARN, 调度算法Flow based的Quincy, Firmament。在long run service,short term workload以及function call需求方面有service mesh,微服务,CaaS,FaaS等解决思路,私有云和公有云的百家争鸣的解决方案和角度,整个生态还是很有意思的。绝技源于江湖、将军发于卒伍,希望这次分享可以给大家带来一些启发,最后感谢Capos的individual contributor(字母序): chenyu.zheng,fei.liu,guiyong.wu,huahui.yang,shangyan.zhou,wei.shao。
Hulu大规模容器调度系统Capos的更多相关文章
- 如何提升集群资源利用率? 阿里容器调度系统Sigma 深入解析
阿里妹导读:为了保证系统的在线交易服务顺利运转,最初几年,阿里都是在双11大促来临之前大量采购机器储备计算资源,导致了双11之后资源大量闲置点现象.是否能把计算任务与在线服务进行混合部署,在现有弹性资 ...
- 一文带你看透kubernetes 容器编排系统
本文由云+社区发表 作者:turboxu Kubernetes作为容器编排生态圈中重要一员,是Google大规模容器管理系统borg的开源版本实现,吸收借鉴了google过去十年间在生产环境上所学到的 ...
- docker,容器,编排,和基于容器的系统设计模式
目录 从容器说起 背景 docker实现原理 编排之争 基于容器的分布式系统设计之道 单节点协作模式 Sidecar pattern(边车模式) Ambassador pattern(外交官模式) A ...
- 通过重新构建Kubernetes来实现更具弹性的容器编排系统
通过重新构建Kubernetes来实现更具弹性的容器编排系统 译自:rearchitecting-kubernetes-for-the-edge 摘要 近年来,kubernetes已经发展为容器编排的 ...
- CDN边缘节点容器调度实践(下)
5月27日,OSC 源创会在上海成功举办.又拍云系统开发高级工程师黄励博在大会分享了<CDN 边缘节点容器调度的实践>.主要介绍又拍云自主开发的边缘节点容器调度方案,从 0 到 1 ,实现 ...
- CDN边缘节点容器调度实践(上)
又拍云容器云是基于 Docker 的分布式计算资源网,节点分散在全国各地及海外,提供电信.联通.移动和多线网络,融合微服务.DevOps 理念,满足精益开发.运维一体化,大幅降低分布式计算资源构建复杂 ...
- 资源管理与调度系统-YARN的基本架构与原理
资源管理与调度系统-YARN的基本架构与原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了能够对集群中的资源进行统一管理和调度,Hadoop2.0引入了数据操作系统YARN. ...
- 调度系统Airflow1.10.4调研与介绍和docker安装
Airflow1.10.4介绍与安装 现在是9102年,8月中旬.airflow当前版本是1.10.4. 随着公司调度任务增大,原有的,基于crontab和mysql的任务调度方案已经不太合适了,需要 ...
- 美团集群调度系统HULK技术演进
本文根据美团基础架构部/弹性策略团队负责人涂扬在2019 QCon(全球软件开发大会)上的演讲内容整理而成.本文涉及Kubernetes集群管理技术,美团相关的技术实践可参考此前发布的<美团点评 ...
随机推荐
- 猜数字游戏;库的使用:turtle
myNum = print('猜字游戏\n') while True: guess = int(input('请输入一个数:')) if guess > myNum: print('不对哦猜大了 ...
- ili 一例业务系统框架
ili即ilinei的简称,像名字一样,是ILINEI团队的内部项目简化而来.2017年金鸡报晓,我们为同行送来了一个简单.快速.轻量级的PHP开源系统,它的任务当然也是唯一的任务,就是提高WEB开发 ...
- 去掉"You are running Vue in development mode"提示
vue项目中报错: You are running Vue in development mode.Make sure to turn on production mode when deployin ...
- Linux 防火墙管理及操作
1.关闭firewall:systemctl stop firewalld.service #停止firewallsystemctl disable firewalld.service #禁止fire ...
- 申请的阿里云主机ubuntu系统无法显示中文
系统ubuntu 16.04,中文的文件名也无法显示,因为中文包没安装,安装如下: sudo apt-get -y install language-pack-zh-hans sudo apt-get ...
- poj 3468 A Simple Problem with Integers(线段树区间更新)
Description You have N integers, A1, A2, ... , AN. You need to deal with two kinds of operations. On ...
- scrapy的基础概念和流程
1. 什么是scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取. Scrapy 使用了Twisted['twɪstɪd]异步网 ...
- Touch365现已上架!
欢迎体验由武宇亭.诸子轩.梁国伟.张裕浩.孔维喆.邱亚威同学开发的创意照片浏览软件Touch365,现已上架Microsoft官方商城! https://www.microsoft.com/zh-cn ...
- ArcSDE
ArcSDE,即数据通路,是ArcGIS的空间数据引擎,它是在关系数据库管理系统(RDBMS)中存储和管理多用户空间数据库的通路.从空间数据管理的角度看,ArcSDE是一个连续的空间数据模型,借助这一 ...
- bower学习总结
1. 安装软件:node-v6.10.3-x64.msi 和 Git-2.13.0-64-bit.exe 在安装git时,需要选择‘Run Git from the Windows Command P ...