SpringBoot+kafka+ELK分布式日志收集
一、背景
随着业务复杂度的提升以及微服务的兴起,传统单一项目会被按照业务规则进行垂直拆分,另外为了防止单点故障我们也会将重要的服务模块进行集群部署,通过负载均衡进行服务的调用。那么随着节点的增多,各个服务的日志也会散落在各个服务器上。这对于我们进行日志分析带来了巨大的挑战,总不能一台一台的登录去下载日志吧。那么我们需要一种收集日志的工具将散落在各个服务器节点上的日志收集起来,进行统一的查询及管理统计。那么ELK就可以做到这一点。
ELK是ElasticSearch+Logstash+Kibana的简称,在这里我分别对如上几个组件做个简单的介绍:
1.1、ElasticSearch(简称ES)
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎。它允许您快速、实时地存储、搜索和分析大量数据。它通常用作底层引擎/技术,为具有复杂搜索特性和需求的应用程序提供动力。我们可以借助如ElasticSearch完成诸如搜索,日志收集,反向搜索,智能分析等功能。ES设计的目标:
- 快速实时搜索
Elasticsearch是一个实时搜索平台。这意味着,从索引文档到可搜索文档,存在轻微的延迟(通常为一秒)。
- 集群
集群是一个或多个节点(服务器)的集合,这些节点(服务器)一起保存整个数据,并提供跨所有节点的联合索引和搜索功能。集群由一个惟一的名称来标识,默认情况下该名称为“elasticsearch”。这个名称很重要,因为节点只能是集群的一部分,如果节点被设置为通过其名称加入集群的话。确保不要在不同的环境中重用相同的集群名称,否则可能会导致节点加入错误的集群。例如,您可以使用logging-dev、logging-test和logging-prod开发、测试和生产集群。
- 节点
节点是单个服务器,它是集群的一部分,它用来存储数据,并参与集群的索引和搜索功能。与集群一样,节点的名称默认为在启动时分配给节点的随机惟一标识符(UUID)。如果不需要默认值,可以定义任何节点名称。这个名称对于管理非常重要,因为您想要确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
- 索引
索引是具有类似特征的文档的集合。例如,您可以有一个客户数据索引、另一个产品目录索引和另一个订单数据索引。索引由一个名称标识(必须是小写的),该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。在单个集群中,可以定义任意数量的索引。
- 文档
文档是可以建立索引的基本信息单元。例如,可以为单个客户提供一个文档,为单个产品提供一个文档,为单个订单提供另一个文档。这个文档用JSON (JavaScript对象符号)表示。在索引中,可以存储任意数量的文档。请注意,尽管文档在物理上驻留在索引中,但实际上文档必须被索引/分配到索引中的类型中。
1.2、Logstash
Logstash是一个开源数据收集引擎,具有实时流水线功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据规范化后(通过Filter过滤)传输到您选择的目标。
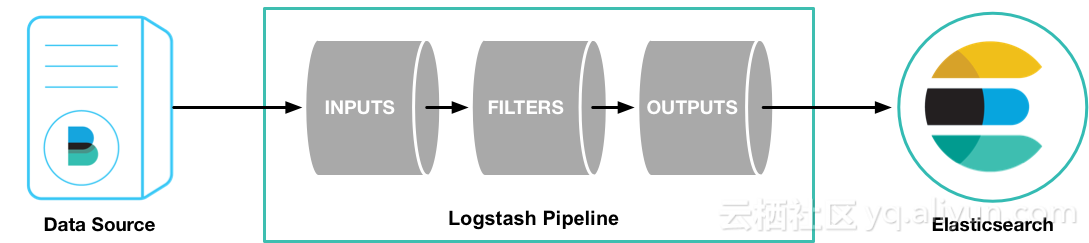
在这里inputs代表数据的输入通道,大家可以简单理解为来源。常见的可以从kafka,FileBeat, DB等获取日志数据,这些数据经过fliter过滤后(比如说:日志过滤,json格式解析等)通过outputs传输到指定的位置进行存储(Elasticsearch,Mogodb,Redis等)
简单的实例:
cd logstash-6.4.1
bin/logstash -e 'input { stdin { } } output { stdout {} }'
1.3、Kibana
kibana是用于Elasticsearch检索数据的开源分析和可视化平台。我们可以使用Kibana搜索、查看或者与存储在Elasticsearch索引中的数据交互。同时也可以轻松地执行高级数据分析并在各种图表、表和映射中可视化数据。基于浏览器的Kibana界面使您能够快速创建和共享动态仪表板,实时显示对Elasticsearch查询的更改。
1.4、处理方案
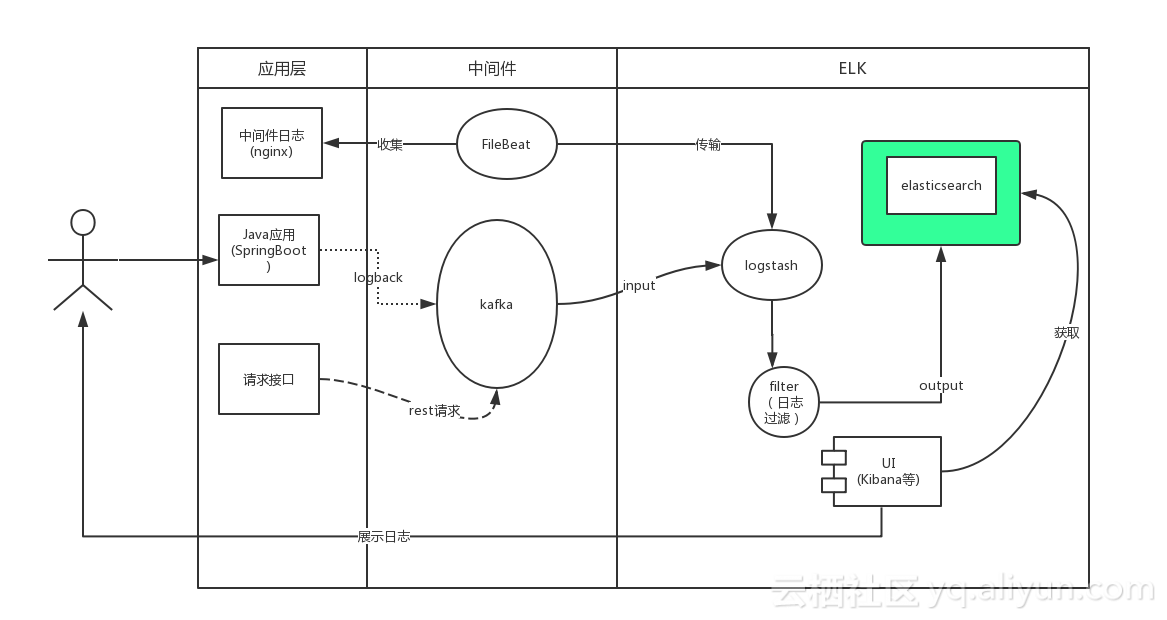
用户通过java应用程序的Slf4j写入日志,SpringBoot默认使用的是logback。我们通过实现自定义的Appender将日志写入kafka,同时logstash通过input插件操作kafka订阅其对应的主题。当有日志输出后被kafka的客户端logstash所收集,经过相关过滤操作后将日志写入Elasticsearch,此时用户可以通过kibana获取elasticsearch中的日志信息
二、SpringBoot中的配置
在SpringBoot当中,我们可以通过logback-srping.xml来扩展logback的配置。不过我们在此之前应当先添加logback对kafka的依赖,代码如下:
compile group: 'com.github.danielwegener', name: 'logback-kafka-appender', version: '0.2.0-RC1'
添加好依赖之后我们需要在类路径下创建logback-spring.xml的配置文件并做如下配置(添加kafka的Appender):
<configuration>
<!-- springProfile用于指定当前激活的环境,如果spring.profile.active的值是哪个,就会激活对应节点下的配置 -->
<springProfile name="default">
<!-- configuration to be enabled when the "staging" profile is active -->
<springProperty scope="context" name="module" source="spring.application.name"
defaultValue="undefinded"/>
<!-- 该节点会读取Environment中配置的值,在这里我们读取application.yml中的值 -->
<springProperty scope="context" name="bootstrapServers" source="spring.kafka.bootstrap-servers"
defaultValue="localhost:9092"/>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder by default -->
<encoder>
<pattern>%boldYellow(${module}) | %d | %highlight(%-5level)| %cyan(%logger{15}) - %msg %n</pattern>
</encoder>
</appender>
<!-- kafka的appender配置 -->
<appender name="kafka" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder>
<pattern>${module} | %d | %-5level| %logger{15} - %msg</pattern>
</encoder>
<topic>logger-channel</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy"/>
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy"/>
<!-- Optional parameter to use a fixed partition -->
<!-- <partition>0</partition> -->
<!-- Optional parameter to include log timestamps into the kafka message -->
<!-- <appendTimestamp>true</appendTimestamp> -->
<!-- each <producerConfig> translates to regular kafka-client config (format: key=value) -->
<!-- producer configs are documented here: https://kafka.apache.org/documentation.html#newproducerconfigs -->
<!-- bootstrap.servers is the only mandatory producerConfig -->
<producerConfig>bootstrap.servers=${bootstrapServers}</producerConfig>
<!-- 如果kafka不可用则输出到控制台 -->
<appender-ref ref="STDOUT"/>
</appender>
<!-- 指定项目中的logger -->
<logger name="org.springframework.test" level="INFO" >
<appender-ref ref="kafka" />
</logger>
<root level="info">
<appender-ref ref="STDOUT" />
</root>
</springProfile>
</configuration>
在这里面我们主要注意以下几点:
- 日志输出的格式是为模块名 | 时间 | 日志级别 | 类的全名 | 日志内容
- SpringProfile节点用于指定当前激活的环境,如果spring.profile.active的值是哪个,就会激活对应节点下的配置
- springProperty可以读取Environment中的值
三、ELK搭建过程
3.1、检查环境
ElasticSearch需要jdk8,官方建议我们使用JDK的版本为1.8.0_131,原文如下:
Elasticsearch requires at least Java 8. Specifically as of this writing, it is recommended that you use the Oracle JDK version 1.8.0_131
检查完毕后,我们可以分别在官网下载对应的组件
3.2、启动zookeeper
首先进入启动zookeeper的根目录下,将conf目录下的zoo_sample.cfg文件拷贝一份重新命名为zoo.cfg
mv zoo_sample.cfg zoo.cfg
配置文件如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=../zookeeper-data
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
紧接着我们进入bin目录启动zookeeper:
./zkServer.sh start
3.3、启动kafka
在kafka根目录下运行如下命令启动kafka:
./bin/kafka-server-start.sh config/server.properties
启动完毕后我们需要创建一个logger-channel主题:
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic logger-channel
3.4、配置并启动logstash
进入logstash跟目录下的config目录,我们将logstash-sample.conf的配置文件拷贝到根目录下重新命名为core.conf,然后我们打开配置文件进行编辑:
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
kafka {
id => "my_plugin_id"
bootstrap_servers => "localhost:9092"
topics => ["logger-channel"]
auto_offset_reset => "latest"
}
}
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{WORD:module} \| %{LOGBACKTIME:timestamp} \| %{LOGLEVEL:level} \| %{JAVACLASS:class} - %{JAVALOGMESSAGE:logmessage}" }
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts =>["localhost:9200"]
}
}
```
我们分别配置logstash的input,filter和output(懂ruby的童鞋们肯定对语法结构不陌生吧):
- 在input当中我们指定日志来源为kafka,具体含义可以参考官网:[kafka-input-plugin](https://www.elastic.co/guide/en/logstash/current/plugins-inputs-kafka.html)
- 在filter中我们配置grok插件,该插件可以利用正则分析日志内容,其中patterns_dir属性用于指定自定义的分析规则,我们可以在该文件下建立文件配置验证的正则规则。举例子说明:55.3.244.1 GET /index.html 15824 0.043的 日志内容经过如下配置解析:
```ruby
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
解析过后会变成:
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043
这些属性都会在elasticsearch中存为对应的属性字段。更详细的介绍请参考官网:grok ,当然该插件已经帮我们定义好了好多种核心规则,我们可以在这里查看所有的规则。
- 在output当中我们将过滤过后的日志内容打印到控制台并传输到elasticsearch中,我们可以参考官网上关于该插件的属性说明:[地址]((https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html)
- 另外我们在patterns文件夹中创建好自定义的规则文件logback,内容如下:
# yyyy-MM-dd HH:mm:ss,SSS ZZZ eg: 2014-01-09 17:32:25,527
LOGBACKTIME 20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND})
```
编辑好配置后我们运行如下命令启动logstash:
```bash
bin/logstash -f first-pipeline.conf --config.reload.automatic
该命令会实时更新配置文件而不需启动
3.5、启动ElasticSearch
启动ElasticSearch很简单,我们可以运行如下命令:
./bin/elasticsearch
我们可以发送get请求来判断启动成功:
GET http://localhost:9200
我们可以得到类似于如下的结果:
{
"name" : "Cp8oag6",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "AT69_T_DTp-1qgIJlatQqA",
"version" : {
"number" : "6.4.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "f27399d",
"build_date" : "2016-03-30T09:51:41.449Z",
"build_snapshot" : false,
"lucene_version" : "7.4.0",
"minimum_wire_compatibility_version" : "1.2.3",
"minimum_index_compatibility_version" : "1.2.3"
},
"tagline" : "You Know, for Search"
}
3.5.1 配置IK分词器(可选)
我们可以在github上下载elasticsearch的IK分词器,地址如下:ik分词器,然后把它解压至your-es-root/plugins/ik的目录下,我们可以在{conf}/analysis-ik/config/IKAnalyzer.cfg.xmlor {plugins}/elasticsearch-analysis-ik-*/config/IKAnalyzer.cfg.xml 里配置自定义分词器:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
首先我们添加索引:
curl -XPUT http://localhost:9200/my_index
我们可以把通过put请求来添加索引映射:
PUT my_index
{
"mappings": {
"doc": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}
其中doc是映射名 my_index是索引名称
3.5.2 logstash与ElasticSearch
logstash默认情况下会在ES中建立logstash-*的索引,*代表了yyyy-MM-dd的时间格式,根据上述logstash配置filter的示例,其会在ES中建立module ,logmessage,class,level等索引。(具体我们可以根据grok插件进行配置)
3.6 启动Kibana
在kibana的bin目录下运行./kibana即可启动。启动之后我们可以通过浏览器访问http://localhost:5601 来访问kibanaUI。我们可以看到如下界面:
SpringBoot+kafka+ELK分布式日志收集的更多相关文章
- ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK全框架 SpringBootSecurity1.传统系统日志收集的问题2.Logstash操作工作原理3.分布式日志收集ELK原理4.Elasticsearch+Log ...
- 传统ELK分布式日志收集的缺点?
传统ELK图示: 单纯使用ElK实现分布式日志收集缺点? 1.logstash太多了,扩展不好. 如上图这种形式就是一个 tomcat 对应一个 logstash,新增一个节点就得同样的拥有 logs ...
- 分布式日志收集框架Flume
分布式日志收集框架Flume 1.业务现状分析 WebServer/ApplicationServer分散在各个机器上 想在大数据平台Hadoop进行统计分析 日志如何收集到Hadoop平台上 解决方 ...
- .NetCore快速搭建ELK分布式日志中心
懒人必备:.NetCore快速搭建ELK分布式日志中心 该篇内容由个人博客点击跳转同步更新!转载请注明出处! 前言 ELK是什么 它是一个分布式日志解决方案,是Logstash.Elastaics ...
- 分布式日志收集系统Apache Flume的设计详细介绍
问题导读: 1.Flume传输的数据的基本单位是是什么? 2.Event是什么,流向是怎么样的? 3.Source:完成对日志数据的收集,分成什么打入Channel中? 4.Channel的作用是什么 ...
- 分布式日志收集收集系统:Flume(转)
Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力.Fl ...
- ELK 分布式日志实战
一. ELK 分布式日志实战介绍 此实战方案以 Elk 5.5.2 版本为准,分布式日志将以下图分布进行安装部署以及配置. 当Elk需监控应用日志时,需在应用部署所在的服务器中,安装Filebeat ...
- 分布式日志收集之Logstash 笔记(一)
(一)logstash是什么? logstash是一种分布式日志收集框架,开发语言是JRuby,当然是为了与Java平台对接,不过与Ruby语法兼容良好,非常简洁强大,经常与ElasticSearch ...
- .NetCore 分布式日志收集Exceptionless 在Windows下本地安装部署及应用实例
自己安装时候遇到很多问题,接下来把这些问题写出来希望对大家有所帮助 搭建环境: 1.下载安装 java 8 SDK (不要安装最新的10.0) 并配置好环境变量(环境变量的配置就不做介绍了) 2.下载 ...
随机推荐
- Python之旅Day12 HTML与CSS
前端CSS与HTML部分 <a href="http://www.baidu.com" target="_Blank">百度</a>_B ...
- Virtual Networking
How the virtual networks used by guests work Networking using libvirt is generally fairly simple, an ...
- Docker应用:Kubernetes(容器集群)
阅读目录: Docker应用:Hello World Docker应用:Docker-compose(容器编排) Docker应用:Kubernetes(容器集群) 前言: 终于出第三篇了,上个月就已 ...
- 使用Python多渠道打包apk
使用Python生成多渠道包 往apk包中追加到一个空文件到META-INF目录以标识渠道,Android中获取此文件即可获得App的下载渠道 首先在info文件夹新建一个qdb.txt的空文本文件 ...
- 新鲜出炉的一套Java面试题
作者:孤独烟 由于近期是互联网寒冬,然而烟哥的好友还是顶着重重压力出去面试,最终斩获无数offer.在烟哥的沟通下,终于套得其中一套题目,故在此分享! 公司:国内三巨头其中的一家!面试时间约在1月份左 ...
- C/C++ 多线程机制
一.C/C++多线程操作说明 C/C++多线程基本操作如下: 1. 线程的建立结束 2. 线程的互斥和同步 3. 使用信号量控制线程 4. 线程的基本属性配置 在C/C++代码编写时,使用多线程机制, ...
- python 77种常用的基础函数
Python: 1. print()函数:打印字符串 2. raw_input()函数:从用户键盘捕获字符 3. len()函数:计算字符长度 4. format(12.3654,’ ...
- 性能瓶颈之Source
数据源的瓶颈通常发生从数据库读取数据的时候,原因通常如下: 1) 脚本的查询效率低下 2) 数据库网络包太小 如何判定源瓶颈 通过在session log中读取thread statistics判定源 ...
- 序列化与反序列化之JSON
在不同编程语言之间传递对象,须把对象序列化为标准格式,比如XML 但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可被所有语言读取,也可方便地存储到磁盘或者通过网络传输 JSON不 ...
- [原创]IIS提权工具-VBS提权脚本免杀生成器
[原创]添加系统用户 VBS提权脚本随机加密生成器[K.8] 2011-05-05 02:42:53| 分类: 原创工具 VBS提权脚本随机加密生成器[K.8] Author: QQ吻 QQ:39 ...