linux io的cfq代码理解
内核版本:
3.10内核。
CFQ,即Completely Fair Queueing绝对公平调度器,原理是基于时间片的角度去保证公平,其实如果一台设备既有单队列,又有多队列,既有快速的NVME,又有慢速的sas,各个磁盘都配置为CFQ的话,那么这个Completely Fair 明显无法保证,可能会演变为Completely unFair 。所以nvme的盘,一般使用的是noop策略,因为一定时间之内的io,可能会下发很多给快速设备,也可能下发很少给慢速设备,这样就无公平可言了,吞吐量也不行。
IO调度的原理:
看到io调度的时候,一定要想为什么需要io调度,调度其实就是封装一层,管理下发的io request,由于存储介质不同,需要的调度算法肯定也不一样,IO调度就是在实时性和io吞吐上的一个折中,不管采用什么的调度算法,调度的目的是明确的,就是通过io的合并或者重排,提高硬件设备的性能,不管是虚拟的硬件设备还是实际的硬件设备。
单队列和多队列
和网卡的发展一样,硬盘设备也有单队列和多队列的区别,单队列有一个明显的弱点,就是所有的io都最终汇聚到一个队列,这个面对目前多核的设备,性能很难发挥。
优先级:
每个进程都会有IO优先级,这个和进程的调度优先级类似。CFQ调度器将会将其作为考虑的因素之一,来确定该进程(或者说cggroup进程组)的请求队列何时可以获取块设备的使用权。IO优先级从高到低可以分为三大类:RT(real time),BE(best effort),IDLE(idle),其中RT和BE又可以再划分为8个子优先级。实际上,我们已经知道CFQ调度器的公平是针对于进程而言的,而只有同步请求(read或syn write)才是针对进程而存在的,他们会放入进程自身的请求队列,而所有同优先级的异步请求,无论来自于哪个进程,都会被放入公共的队列,异步请求的队列总共有8(RT)+8(BE)+1(IDLE)=17个。
调度器:
cfq是各种io调度器中的一种,其实就是实例化了调度器的类。可以和qdisc类比,就比较清晰了。
static struct elevator_type iosched_cfq = {
.ops = {
.elevator_merge_fn = cfq_merge,---------------request和bio合并的时候调用
.elevator_merged_fn = cfq_merged_request,------看到这个成员的ed没?这个merged是指已经合并了的request
.elevator_merge_req_fn = cfq_merged_requests,------这个是两个request合并的时候调用
.elevator_allow_merge_fn = cfq_allow_merge,--------request和bio能否合并的时候调用
.elevator_bio_merged_fn = cfq_bio_merged,
.elevator_dispatch_fn = cfq_dispatch_requests,---用当前的request来填充dispatch queue,一旦dispatch,调度器就不能控制这些io请求了,
.elevator_add_req_fn = cfq_insert_request,-------增加一个新请求到调度器
.elevator_activate_req_fn = cfq_activate_request,----这个相当于让block层看到这个request,
.elevator_deactivate_req_fn = cfq_deactivate_request,---这个就是block驱动再推迟这个请求
.elevator_completed_req_fn = cfq_completed_request,----req结束之后调用
.elevator_former_req_fn = elv_rb_former_request,-------查找给定请求的前一个请求
.elevator_latter_req_fn = elv_rb_latter_request,-------查找给定请求的后一个请求,在进行request合并时很有用
.elevator_init_icq_fn = cfq_init_icq,--------icq的构造函数
.elevator_exit_icq_fn = cfq_exit_icq,--------icq的析构函数
.elevator_set_req_fn = cfq_set_request,------创建请求时填充req的一些必要字段
.elevator_put_req_fn = cfq_put_request,------释放请求时填充req的一些必要字段和处理
.elevator_may_queue_fn = cfq_may_queue,----如果调度器允许在超过queue的limit情况下依然插入请求,return true
.elevator_init_fn = cfq_init_queue,----队列初始化时调用,相当于构造函数
.elevator_exit_fn = cfq_exit_queue,----队列释放时调用,相当于析构函数
},
.icq_size = sizeof(struct cfq_io_cq),
.icq_align = __alignof__(struct cfq_io_cq),
.elevator_attrs = cfq_attrs,
.elevator_name = "cfq",
.elevator_owner = THIS_MODULE,
};
这里只展示了elevator_type的部分字段,比如还有些字段是将所有的elevator_type串接起来的,elevator_attrs里面存放某个elevator的属性,设计这个
指针的原因是各种elevator的参数配置都不一样,这样各种elevator都可以统一了。
iosched_cfq = $1 = {
icq_cache = 0xffff880135ad1000,
ops = {
elevator_merge_fn = 0xffffffff81323480 <cfq_merge>,
elevator_merged_fn = 0xffffffff81324280 <cfq_merged_request>,
elevator_merge_req_fn = 0xffffffff81324a60 <cfq_merged_requests>,
elevator_allow_merge_fn = 0xffffffff81323830 <cfq_allow_merge>,
elevator_bio_merged_fn = 0xffffffff81321b60 <cfq_bio_merged>,
elevator_dispatch_fn = 0xffffffff81326960 <cfq_dispatch_requests>,
elevator_add_req_fn = 0xffffffff81329250 <cfq_insert_request>,
elevator_activate_req_fn = 0xffffffff81323b20 <cfq_activate_request>,
elevator_deactivate_req_fn = 0xffffffff81323950 <cfq_deactivate_request>,
elevator_completed_req_fn = 0xffffffff81328840 <cfq_completed_request>,
elevator_former_req_fn = 0xffffffff812fbcd0 <elv_rb_former_request>,
elevator_latter_req_fn = 0xffffffff812fbd00 <elv_rb_latter_request>,
elevator_init_icq_fn = 0xffffffff81321bb0 <cfq_init_icq>,
elevator_exit_icq_fn = 0xffffffff81326770 <cfq_exit_icq>,
elevator_set_req_fn = 0xffffffff813283e0 <cfq_set_request>,
elevator_put_req_fn = 0xffffffff813264a0 <cfq_put_request>,
elevator_may_queue_fn = 0xffffffff81322fd0 <cfq_may_queue>,
elevator_init_fn = 0xffffffff813276c0 <cfq_init_queue>,
elevator_exit_fn = 0xffffffff81327a20 <cfq_exit_queue>
},
icq_size = 120,
icq_align = 8,
elevator_attrs = 0xffffffff81ac2280 <cfq_attrs>,
elevator_name = "cfq\000\000\000\000\000\000\000\000\000\000\000\000",
elevator_owner = 0x0,
icq_cache_name = "cfq_io_cq\000\000\000\000\000\000\000\000\000\000\000",
list = {
next = 0xffffffff81abf9b0 <elv_list>,
prev = 0xffffffff81ac20a8 <iosched_deadline+232>
}
}
关键数据结构:
两大关键结构,一个是cfq_data,一个是cfq_queue,cfq_data是管理和调度cfq_queue的结构,而cfq_queue是管理io request的结构,cfq_data通过选择cfq_queue来下发对应的io request 到设备的request_queue中,达到调度的目的,在引入了io的cggroup之后,cfq_data通过选择cfq_group来先确定服务的对象,而cfq_group中的用红黑树管理的cfq_queue为二级对象,cfq_queue中红黑树管理的request为三级对象。
cfq_data是一个per block 结构,也就是每个使用cfq调度策略的块设备有一个这个结构对应,用来管理下发给这个block设备的请求。cfq_data的指针是作为一个blkio_cgroup的哈希表的key,而对应的value则是cfq_group;同时也是io_context的radix_tree的一个key,对应的value是cfq_io_context,这样cfq_data,blkio_group和cfq_io_context就一一对应起来了。通过
static void cfq_insert_request(struct request_queue *q, struct request *rq)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
这个函数可以看出,cfqd是在request_queue->elevator->elevator_data中保存。
而request和对应的cfq_queue以及cfqg关联是通过如下:
#define RQ_CFQQ(rq) (struct cfq_queue *) ((rq)->elv.priv[0])
#define RQ_CFQG(rq) (struct cfq_group *) ((rq)->elv.priv[1])
下面详细描述cfq_dtata:
/*
* Per block device queue structure
*/
struct cfq_data {
struct request_queue *queue;--------------指向块设备对应的request_queue
/* Root service tree for cfq_groups */
struct cfq_rb_root grp_service_tree;------所有待调度的cfq_group都被加入到该红黑树,管理cfq_group的rb_node成员。
struct cfq_group *root_group;---所有cggroup的根cgroup /*
* The priority currently being served
*/
enum wl_class_t serving_wl_class;---------------当前服务的BE_WORKLOAD = 0,RT_WORKLOAD = 1,IDLE_WORKLOAD = 2,CFQ_PRIO_NR=3,
enum wl_type_t serving_wl_type;-----------------当前服务的workload_type,可能的值为async_workload,sync_NOidle_workload,sync_workload
unsigned long workload_expires;
struct cfq_group *serving_group;----------------当前服务的cfq_group /*
* Each priority tree is sorted by next_request position. These
* trees are used when determining if two or more queues are
* interleaving requests (see cfq_close_cooperator).
*/
struct rb_root prio_trees[CFQ_PRIO_LISTS];----CFQ_PRIO_LISTS为8,8个优先级的红黑树,所有优先级为rt或be的进程的同步请求队列,都会根据优先级添加到对应的红黑树 unsigned int busy_queues;------------该cfqd中有多少个队列在等待调度
unsigned int busy_sync_queues;-------该cfqd中有多少个同步队列在等待调度 int rq_in_driver;---------在驱动中,也就是调度层已经下发,但还没有收到结果的request数
int rq_in_flight[];------已经下发还未收到结果的同步和异步的io个数 /*
* queue-depth detection
*/
int rq_queued;-----------------queue深度的一些成员,这个是积压的request的个数
int hw_tag;
/*
* hw_tag can be
* -1 => indeterminate, (cfq will behave as if NCQ is present, to allow better detection)
* 1 => NCQ is present (hw_tag_est_depth is the estimated max depth)
* 0 => no NCQ
*/
int hw_tag_est_depth;
unsigned int hw_tag_samples; /*
* idle window management
*/
struct timer_list idle_slice_timer;
struct work_struct unplug_work; struct cfq_queue *active_queue;--------------指向当前服务的队列,因为cfq_data是每个使用cfq调度算法的设备的数据结构,对每个时刻而言,每个cfq_data只服务一个cfq_queue
struct cfq_io_cq *active_cic;----------------当前活动的io上下文,和active_queue一样,都算是缓存 /*
* async queue for each priority case
*/
struct cfq_queue *async_cfqq[][IOPRIO_BE_NR];---对应RT和BE优先级类的各8个异步请求队列,加起来16个
struct cfq_queue *async_idle_cfqq;---------------对应优先级类别为IDLE的异步请求队列----加上前面16个就是17个 sector_t last_position; /*
* tunables, see top of file
*/
unsigned int cfq_quantum;-------------用于计算在一个队列的时间片内,最多发放多少个请求到底层的块设备, cfq_quantum = 8;
unsigned int cfq_fifo_expire[];------同步、异步请求的响应期限时间,cfq_fifo_expire[2] = { HZ / 4, HZ / 8 };
unsigned int cfq_back_penalty;------cfq_back_penalty = 2;
unsigned int cfq_back_max;-------cfq_back_max = 16 * 1024;
unsigned int cfq_slice[];------------同步、异步请求队列的时间片长度,cfq_slice_async = HZ / 25; cfq_slice_sync = HZ / 10;
unsigned int cfq_slice_async_rq;----cfq_slice_async_rq = 2;
unsigned int cfq_slice_idle;----------idle的时间片,cfq_slice_idle = HZ / 125;
unsigned int cfq_group_idle;----------cfq_group_idle = HZ / 125;
unsigned int cfq_latency;-------cfqd->cfq_latency = 1,可以设置为0
unsigned int cfq_target_latency;----cfq_target_latency = HZ * 3/10; /* 300 ms */ /*
* Fallback dummy cfqq for extreme OOM conditions
*/
struct cfq_queue oom_cfqq;------------在极端的oom的情况下,因为alloc cfq_queue失败,则使用这个queue,相当于备用的 unsigned long last_delayed_sync;
};
另外一个结构是cfq_queue,管理cfq调度器的的request请求的,每个process-group有一个这个结构,也就是跟进程组相关,会和一个cfq_io_context关联,cfq_io_context在代码中一般
简写为cic,这个cfq_queue要注意和request_queue区分。request_queue是管理某个block设备下所有下发的io request的一个队列,而cfq_queue只是cfq调度类的一个被管理对象,而它也是
管理各个io request的,主要使用了sort_list和fifo队列来管理io的request,一个io request在具体某个时刻要么在cfq_queue中,要么在request queue中。
/*
* Per process-grouping structure
*/
struct cfq_queue {
/* reference count */
int ref;
/* various state flags, see below */
unsigned int flags;
/* parent cfq_data */
struct cfq_data *cfqd;-------指向队列所属的cfq_data
/* service_tree member */
struct rb_node rb_node;------用于将该队列插入service_tree,就是红黑树的node,注意和sort_list相区别,sort_list是管理的对象是request,
/* service_tree key */
unsigned long rb_key;-------红黑树节点关键值,用于确定队列在service_tree中的位置,该值要综合jiffies,进程的io优先级等考虑
/* prio tree member */
struct rb_node p_node;-------用于将队列插入对应优先级的prio_tree
/* prio tree root we belong to, if any */
struct rb_root *p_root;------对应的prio_tree树根,就是当前cfq_q归属于cfqd中的prio_trees的节点的地址
/* sorted list of pending requests */
struct rb_root sort_list;----组织队列内的请求用的红黑树,按请求的起始扇区进行排序,便于查找某个扇区以及合并请求,
/* if fifo isn't expired, next request to serve */
struct request *next_rq;-----红黑树中下一个要处理的请求,
/* requests queued in sort_list */
int queued[];---------------目前管理的同步和异步的request的数量,数组1是同步io请求的数量
/* currently allocated requests */
int allocated[];------------读写两个方向的分配的request的数量,allocated包含dispatch+queued
/* fifo list of requests in sort_list */
struct list_head fifo;---------fifo的list,pending requests形成的fifo链表,fifo主要按时间来管理,主要防止队列内某些request饿死。
//为什么既用fifo来管理request,又用rb_tree来管理呢?其实内核中很多这样的管理方式,比如说我们的线性区也有多个管理结构,deadline io scheduler也有类似的,主要是不同维度来管理
/* time when queue got scheduled in to dispatch first request. */
unsigned long dispatch_start;---当被选中来调度时的时间
unsigned int allocated_slice;---被选中时分配的时间片
unsigned int slice_dispatch;----时间片内给对应的request queue下发的请求数,这个在一个调度周期内有效,下次选择到这个cfq_q会清零
/* time when first request from queue completed and slice started. */
unsigned long slice_start;---指定时间片什么时候开始
unsigned long slice_end;-----指明时间片何时消耗完
long slice_resid; /* pending priority requests */
int prio_pending;
/* number of requests that are on the dispatch list or inside driver */
int dispatched;---------------该cfq_q总共下发的request总数,这些是驱动待处理的请求 /* io prio of this group */
unsigned short ioprio, org_ioprio;----这组的io优先级
unsigned short ioprio_class; pid_t pid;-----该cfq_queue归属的进程的pid u32 seek_history;
sector_t last_request_pos; struct cfq_rb_root *service_tree;----指向cfq_data对应的cfq_rb_tree
struct cfq_queue *new_cfqq;
struct cfq_group *cfqg;--------------cfq_queue对应的cgroup,主要是进程信息,看组内的大家怎么分时间片,异步队列的话,这个就指向cfq_data->root_group
/* Number of sectors dispatched from queue in single dispatch round */
unsigned long nr_sectors;------------调度周期内下发的扇区总数
};
cfq代码中常见的简写:
cic是 cfq_io_context 的简写
cfqq 是cfq_queue 的简写
cfqd是cfq_data 的简写
be是 best effort 的简写
rt是 real time 的简写
其中有三种class: idle(3), best effort(2), real time(1),具体用法man ionice
real time 和 best effort 内部都有 0-7 一共8个优先级,对于real time而言,由于优先级高,有可能会饿死其他进程,对于 best effort 而言,2.6.26之后的内核如不指定io priority,那就有io priority = cpu nice
如何生成一个request:
io生成request的方法,常见的是进程上下文的时候,使用 bio_alloc 生成一个bio,bio描述的是这个io是需要访问那些扇区序列,然后调用 submit_bio 提交这个请求,blockdump的情况下,是能够打印这个进程提交的bio的具体信息的,submit_bio使用 generic_make_request 函数进入通用块层,如果 当前进程的 current->bio_list 不为NULL,那么新的bio仅仅是挂在这个bio_list末尾就返回了,为NULL的话,则根据bio所要读写的硬盘,找到对应的request_queue,然后使用 q->make_request_fn 来生成一个request,在之前关于NVME的博客描述中,曾经对这个 make_request_fn
有过解释,对于多队列的硬盘,一般是blk_mq_make_request,而对于普通单队列硬盘,则以 blk_queue_bio 居多,最终根据能否merge,调用 elv_merge 或者生成一个new request,
生成new request 之后,调用init_request_from_bio 使用bio 来初始化这个request,网上有图,这个基本都写烂了,关于扇区,bio,request这三级关系的,struct request_queue中有几个重要的成员,一个就是创建request的 make_request_fn,一个就是准备命令的成员prep_rq_fn,对于scsi协议的设备来说,就是 scsi_prep_fn,这个函数会为request_queue设置io cmd执行出错之后的回调等;一个就是执行request的 request_fn 成员,对由于scsi设备来说,就是 scsi_request_fn 来执行request 了。
对请求进行merge:
唐突地描述合并请求,其实有多个阶段,比如在submit_bio阶段,如果 current->bio_list 不为NULL,则bio请求挂在这个队列尾就返回了,算不算一种合并,从时间角度说,其实算一种合并,
因为这些bio下发的时候,是一起下发的,但是从空间的角度,每个bio所要读写的扇区是不相关的(如果是某个进程顺序读,则可能连续),传统意义上的合并request,可能在于电梯算法的
合并,而bio合入到其他的request是一种级别的合并,request与request之间又是一种级别的合并,cfq是如何合并的呢,主要就是调用 cfq_merge,一般的调用链如下:
blk_queue_bio---》elv_merge---》elevator_merge_fn--》cfq_merge----》cfq_find_rq_fmerge-----找到相邻的request
int elv_merge(struct request_queue *q, struct request **req, struct bio *bio)
{
struct elevator_queue *e = q->elevator;
struct request *__rq;
int ret; /*
* Levels of merges:
* nomerges: No merges at all attempted
* noxmerges: Only simple one-hit cache try
* merges: All merge tries attempted
*/
if (blk_queue_nomerges(q))
return ELEVATOR_NO_MERGE; /*
* First try one-hit cache.
*/
if (q->last_merge && elv_rq_merge_ok(q->last_merge, bio)) {------尝试看一下这个request_queue的最后一次合并的request能否合并,适合顺序读写的情况
ret = blk_try_merge(q->last_merge, bio);----尝试前后合并,也就是这个request的起始扇区是该bio的最后一个扇区,或者request的最后扇区是bio的第一个扇区
if (ret != ELEVATOR_NO_MERGE) {-------------可以合并,则依然记录最后合并的request
*req = q->last_merge;
return ret;
}
} if (blk_queue_noxmerges(q))--------本身这个queue就有标志确定不能合并的,则直接返回不合并
return ELEVATOR_NO_MERGE; /*
* See if our hash lookup can find a potential backmerge.
*/
__rq = elv_rqhash_find(q, bio->bi_sector);-----根据bio起始的sector,去request_queue中hash查找能合并的request,
if (__rq && elv_rq_merge_ok(__rq, bio)) {------找到了并且能合并ok,则返回这个request,
*req = __rq;
return ELEVATOR_BACK_MERGE;
} if (e->type->ops.elevator_merge_fn)
return e->type->ops.elevator_merge_fn(q, req, bio);--------这个对于cfq来说,就是调用cfq_merge return ELEVATOR_NO_MERGE;
}
上面使用的 elv_rq_merge_ok 函数,判断能否合并,比如对于cfq的实现来说,bio中必须是同步io和req中也必须是同步io,具体可见:cfq_allow_merge 实现,在此不展开。
static int cfq_merge(struct request_queue *q, struct request **req,
struct bio *bio)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct request *__rq; __rq = cfq_find_rq_fmerge(cfqd, bio);-------根据当前bio,查找可以merge的request
if (__rq && elv_rq_merge_ok(__rq, bio)) {---找到了对应的request,只是第一步,elv_rq_merge_ok才能决定是否可以merge
*req = __rq;
return ELEVATOR_FRONT_MERGE;
} return ELEVATOR_NO_MERGE;
}
static struct request *
cfq_find_rq_fmerge(struct cfq_data *cfqd, struct bio *bio)
{
struct task_struct *tsk = current;
struct cfq_io_cq *cic;
struct cfq_queue *cfqq; cic = cfq_cic_lookup(cfqd, tsk->io_context);---cic是cfq_io_context的简写,在进程的io_context中,找到进程特定于块设备的cfq_io_context,因为一个进程可能和多个设备通信
if (!cic)
return NULL; cfqq = cic_to_cfqq(cic, cfq_bio_sync(bio));----根据同步还是异步,确定cfq_queue
if (cfqq)
return elv_rb_find(&cfqq->sort_list, bio_end_sector(bio));---找到cfqq之后,按照本次bio的最后一个扇区,从cfq_queue的红黑树中查找对应的节点,也就是对应的请求
要注意的一点是,bio传入的是该bio的最后一个扇区,比较的时候,适合红黑树中的request中的第一个扇区进行比较,如果小于则找左子树,大于则找右子树,相同则返回对应的request。
return NULL;----无法merge,因为没有找到对应的cfqq
}
对cfq_cic_lookup---》ioc_lookup_icq 的流程再分析一下:
struct io_cq *ioc_lookup_icq(struct io_context *ioc, struct request_queue *q)
{
struct io_cq *icq; lockdep_assert_held(q->queue_lock); /*
* icq's are indexed from @ioc using radix tree and hint pointer,
* both of which are protected with RCU. All removals are done
* holding both q and ioc locks, and we're holding q lock - if we
* find a icq which points to us, it's guaranteed to be valid.
*/
rcu_read_lock();
icq = rcu_dereference(ioc->icq_hint);
if (icq && icq->q == q)
goto out; icq = radix_tree_lookup(&ioc->icq_tree, q->id);----从ioc中的radix树中找对应的icq,这个类似于在pogecache的address_space中找对应的page
if (icq && icq->q == q)
rcu_assign_pointer(ioc->icq_hint, icq); /* allowed to race */
else
icq = NULL;
out:
rcu_read_unlock();
return icq;
}
对无法merge的BIO,则新生成请求:
merge的结果可能返回ELEVATOR_BACK_MERGE,也有可能是ELEVATOR_FRONT_MERGE,这两种结果都是可以merge的,要注意的是,有些请求是无法merge的,比如包含barrier i/o。然后会调用
elv_merged_request 来实现merge,elevator_merged_fn---》cfq_merged_request,但是如果merge不了的请求,则会生成新的request,从bio到新的request,也是有一段路要走的,
这个要类比的话,可以参照net里面实现的skb申请的对比,当要发包的时候,如果当前的报文可以和之前的skb合并,则合并,否则申请新的skb来管理。
get_request---》cfq_may_queue,如果它的返回值是ELV_MQUEUE_NO,则报没有空间,否则根据它的返回值是 ELV_MQUEUE_MUST 还是 ELV_MQUEUE_MAY 来 判断是否拥塞
之类的,这个也可以和tcp发包时候来对比,比如我们的缓存不够了,不能填下当前的网络请求,则也会报没有空间之类的。如果存在空间,则
mempool_alloc 会返回正常的request来承载这个bio请求。申请request成功之后,elv_set_request就要被呼唤出场了,分配一个request必须进行初始化,需要调用cfq_set_request()函数。调用链如下:
blk_queue_bio-->get_request --->__get_request-->elv_set_request--->elevator_set_req_fn----->cfq_set_request:来到了构造request的方法:
static int
cfq_set_request(struct request_queue *q, struct request *rq, struct bio *bio,
gfp_t gfp_mask)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct cfq_io_cq *cic = icq_to_cic(rq->elv.icq);
const int rw = rq_data_dir(rq);
const bool is_sync = rq_is_sync(rq);
struct cfq_queue *cfqq; might_sleep_if(gfp_mask & __GFP_WAIT); spin_lock_irq(q->queue_lock); check_ioprio_changed(cic, bio);
check_blkcg_changed(cic, bio);
new_queue:
cfqq = cic_to_cfqq(cic, is_sync);---根据同异步情况,获取进程中对应的cfq_queue
if (!cfqq || cfqq == &cfqd->oom_cfqq) {----如果还没有相应的cfqq则进行分配
cfqq = cfq_get_queue(cfqd, is_sync, cic, bio, gfp_mask);---分配cfq_queue
cic_set_cfqq(cic, cfqq, is_sync);----设置cic->cfqq[is_sync] = cfqq
} else {
/*
* If the queue was seeky for too long, break it apart.-------------queue太长了,把它掰开
*/
if (cfq_cfqq_coop(cfqq) && cfq_cfqq_split_coop(cfqq)) {
cfq_log_cfqq(cfqd, cfqq, "breaking apart cfqq");
cfqq = split_cfqq(cic, cfqq);
if (!cfqq)
goto new_queue;
} /*
* Check to see if this queue is scheduled to merge with
* another, closely cooperating queue. The merging of
* queues happens here as it must be done in process context.
* The reference on new_cfqq was taken in merge_cfqqs.
*/
if (cfqq->new_cfqq)
cfqq = cfq_merge_cfqqs(cfqd, cic, cfqq);
} cfqq->allocated[rw]++; cfqq->ref++;
cfqg_get(cfqq->cfqg);
rq->elv.priv[0] = cfqq;------保留相应的cfqq信息到rq中
rq->elv.priv[1] = cfqq->cfqg;
spin_unlock_irq(q->queue_lock);
return 0;
}
如何配对request和对应的cfq_queue:
生成的新请求,如何设置其对应的cfqq呢?在 cfq_get_queue 函数中有实现:
static struct cfq_queue *
cfq_get_queue(struct cfq_data *cfqd, bool is_sync, struct cfq_io_cq *cic,
struct bio *bio, gfp_t gfp_mask)
{
const int ioprio_class = IOPRIO_PRIO_CLASS(cic->ioprio);
const int ioprio = IOPRIO_PRIO_DATA(cic->ioprio);
struct cfq_queue **async_cfqq = NULL;
struct cfq_queue *cfqq = NULL; if (!is_sync) {
async_cfqq = cfq_async_queue_prio(cfqd, ioprio_class, ioprio);-------异步的,根据io优先级使用公共队列就行
cfqq = *async_cfqq;
} if (!cfqq)
cfqq = cfq_find_alloc_queue(cfqd, is_sync, cic, bio, gfp_mask);----同步的需要费一番周折 /*
* pin the queue now that it's allocated, scheduler exit will prune it
*/
if (!is_sync && !(*async_cfqq)) {
cfqq->ref++;
*async_cfqq = cfqq;
} cfqq->ref++;
return cfqq;
}
异步的就是根据io的优先级使用cfqd中的公共队列,同步的话,task中的ioc就发挥作用了,task可能会同时和多个磁盘进行通信,为了记录这种情况,task_struct中的io_context 成员记录了这些通信的信息。
io_context 中的 icq_tree 成员其实是一颗radix 树,和我们pagecache中的radix树类似,只不过我们这颗radix树的index是request_queue的id,如果是第一次访问到这个磁盘,
则会 调用 ioc_create_icq 来创建一个cfq,并加入到对应request_queue 中的id 的slot中去。
crash> task_struct.io_context ffff881f52764500
io_context = 0xffff881fc5cb1548
crash> struct -xo io_context.icq_tree 0xffff881fc5cb1548
struct io_context {
[ffff881fc5cb1570] struct radix_tree_root icq_tree;
}
crash> tree -t radix ffff881fc5cb1570----------下面这些都是该进程通信的cfqq
ffff881fc9e4fca8
ffff8801977764b0
ffff88065fd311e0
ffff881450699a50
ffff8814489712d0
ffff8814512e80f0
ffff880d83418ca8
ffff880d83418f00
ffff8804729f9078
ffff8815769b6e10
ffff88065fd310f0
ffff88144e209d20
ffff8804a2055bb8
ffff881fc9e4f708
ffff8804a2055168
ffff880eb1f53d98
ffff880d2ec6d4b0
ffff881450699d98
ffff8804729f9618
ffff8804a2055528
ffff88065fd31168
ffff881446b20348
ffff8804a20554b0
ffff880cb47a3bb8
ffff880d2ec6d618
ffff881450699168
ffff8804a2055078
ffff880d83418078
ffff880dab6c55a0
ffff8804729f9438
ffff881448971b40
ffff880dab6c5a50
新的request 找到对应的cfq_queue之后,则建立起来了对应的request 和cfq_q之间的联系了,具体可以见本文最后的那张图。
新请求如何插入到cfqq
generic_make_request----(q->make_request_fn)对于单队列,就是 blk_queue_bio,当然对于md设备之类的,指针不一样,在此不展开。
blk_queue_bio-----blk_flush_plug_list---__elv_add_request-->cfq_insert_request----
一个request生成之后,会插入到对应的管理队列中,目前内核设计了三层的管理,一层是进程级,也就是属于这个进程的io,用plug来管理,一层是elv级,是用调度器来管理,一层是硬件的
request_queue,这个是下发给device驱动的。最后调用 scsi_dispatch_cmd 方法将请求发送到HBA。如果 scsi 层需要重新调度一个 request ,可以通过 blk_requeue_request 接口来完成。通过该接口,可以把 request 重新放回到 device request queue 中进行调度(具体可以看scsilib.c).在blk_queue_bio 函数中,如果已经创建了一个新的request的话,则需要将该请求插入到队列,如果当前进程的plug为NULL,说明不需要在进程级缓存该进程的io,则调用__blk_run_queue 来刷掉当前queue的request,进入了elv层,否则如果进程有PLUG但当前plug请求数是0,则直接缓存在该plug中,如果plug已经满了,则调用blk_flush_plug_list 来刷掉该plug缓存的io请求,刷取的方式就是遍历这个list,调用 __elv_add_request:
void __elv_add_request(struct request_queue *q, struct request *rq, int where)
{
trace_block_rq_insert(q, rq); blk_pm_add_request(q, rq); rq->q = q; if (rq->cmd_flags & REQ_SOFTBARRIER) {
/* barriers are scheduling boundary, update end_sector */
if (rq->cmd_type == REQ_TYPE_FS) {
q->end_sector = rq_end_sector(rq);
q->boundary_rq = rq;
}
} else if (!(rq->cmd_flags & REQ_ELVPRIV) &&
(where == ELEVATOR_INSERT_SORT ||
where == ELEVATOR_INSERT_SORT_MERGE))
where = ELEVATOR_INSERT_BACK; switch (where) {
case ELEVATOR_INSERT_REQUEUE:
case ELEVATOR_INSERT_FRONT:---将request加入到device request queue的队列前
rq->cmd_flags |= REQ_SOFTBARRIER;
list_add(&rq->queuelist, &q->queue_head);
break; case ELEVATOR_INSERT_BACK:--- 将request加入到device request queue的队列尾,注意此时操作的对象是request queue
rq->cmd_flags |= REQ_SOFTBARRIER;
elv_drain_elevator(q);
list_add_tail(&rq->queuelist, &q->queue_head);
/*
* We kick the queue here for the following reasons.
* - The elevator might have returned NULL previously
* to delay requests and returned them now. As the
* queue wasn't empty before this request, ll_rw_blk
* won't run the queue on return, resulting in hang.
* - Usually, back inserted requests won't be merged
* with anything. There's no point in delaying queue
* processing.
*/
__blk_run_queue(q);----如注释,添加队列尾的,已经无法合并,刷掉该队列中的请求
break; case ELEVATOR_INSERT_SORT_MERGE:
/*
* If we succeed in merging this request with one in the
* queue already, we are done - rq has now been freed,
* so no need to do anything further.
*/
if (elv_attempt_insert_merge(q, rq))---尝试对request进行合并操作,如果无法合并将request加入到elevator request queue中
break;
case ELEVATOR_INSERT_SORT:---需要重排,则将request加入到elevator request queue中,进入elv层
BUG_ON(rq->cmd_type != REQ_TYPE_FS);
rq->cmd_flags |= REQ_SORTED;
q->nr_sorted++;
if (rq_mergeable(rq)) {
elv_rqhash_add(q, rq);
if (!q->last_merge)
q->last_merge = rq;
} /*
* Some ioscheds (cfq) run q->request_fn directly, so
* rq cannot be accessed after calling
* elevator_add_req_fn.
*/
q->elevator->type->ops.elevator_add_req_fn(q, rq);----对于cfq来说,就是 cfq_insert_request,对于deadline来说,就是deadline_add_request
break; case ELEVATOR_INSERT_FLUSH:
rq->cmd_flags |= REQ_SOFTBARRIER;
blk_insert_flush(rq);
break;
default:
printk(KERN_ERR "%s: bad insertion point %d\n",
__func__, where);
BUG();
}
}
其实插入到cfqq还是比较简单的,记住两个主要的结构,一个是红黑树,按扇区大小管理,一个是fifo队列,按照request到来时间先后来管理:
static void cfq_insert_request(struct request_queue *q, struct request *rq)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct cfq_queue *cfqq = RQ_CFQQ(rq); cfq_log_cfqq(cfqd, cfqq, "insert_request");
cfq_init_prio_data(cfqq, RQ_CIC(rq)); rq->fifo_time = jiffies + cfqd->cfq_fifo_expire[rq_is_sync(rq)];
list_add_tail(&rq->queuelist, &cfqq->fifo);----两个主要数据结构,一个是将request加入到cfqq的fifo队列,一个是将request根据扇区加到对应的红黑树
cfq_add_rq_rb(rq);
cfqg_stats_update_io_add(RQ_CFQG(rq), cfqd->serving_group,
rq->cmd_flags);
cfq_rq_enqueued(cfqd, cfqq, rq);
}
如何从调度队列cfqq中下发一个request到设备的request queue:
CFQ调度器在发送request到底层块设备时的流程大致如下:
1.选择一个cfq_queue
2.从cfq_queue中选择一个request进行发送
选择cfq_queue的思路如下:
1.如果当前的cfq_queue的时间片还没用完,则继续当前的cfq_queue
2.如果当前的cfq_queue的时间片消耗完了,则优先在对应的prio_tree中选择一个cfq_queue,该cfq_queue的第一个访问扇区与整个调度器最后处理的扇区之间的差值必须小于一个阈值,如果OK的话就选择这个cfq_queue
3.如果找不到这样的cfq_queue,再从service_tree中调度其他的cfq_queue
调用链:cfq_dispatch_requests----cfq_select_queue
-----cfq_dispatch_request
调用链可以简单分为两部分,一部分是选择queue,另一部分是根据选择的queue,取其中request下发给request queue,就是从cfqq中取请求到request_queue
/*
* Find the cfqq that we need to service and move a request from that to the
* dispatch list
*/
static int cfq_dispatch_requests(struct request_queue *q, int force)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct cfq_queue *cfqq; if (!cfqd->busy_queues)
return ; if (unlikely(force))
return cfq_forced_dispatch(cfqd); cfqq = cfq_select_queue(cfqd);-------------选择一个队列,它会优先选择active_queue,如果没有则选择新的queue,并将新的queue设置为active
if (!cfqq)
return ; /*
* Dispatch a request from this cfqq, if it is allowed
*/
if (!cfq_dispatch_request(cfqd, cfqq))-------从选择的队列中选择request进行派发,这个放在后面描述,因为cfq_select_queue就已经较复杂了,选择好queue之后来轮到它。
return ; cfqq->slice_dispatch++;
cfq_clear_cfqq_must_dispatch(cfqq); /*
* expire an async queue immediately if it has used up its slice. idle
* queue always expire after 1 dispatch round.
*/
if (cfqd->busy_queues > && ((!cfq_cfqq_sync(cfqq) &&
cfqq->slice_dispatch >= cfq_prio_to_maxrq(cfqd, cfqq)) ||
cfq_class_idle(cfqq))) {
cfqq->slice_end = jiffies + ;
cfq_slice_expired(cfqd, );
}
//异步队列发送的请求数超过了时间片内的最大请求数,且有其他队列等待调度,则将队列挂起,如果是idle队列,则直接挂起
cfq_log_cfqq(cfqd, cfqq, "dispatched a request");
return ;
}
如何选择一个cfq调度队列:
那么具体怎么选择队列来进行request的派发呢?选择队列其实也是有讲究的,
cfq_select_queue的调用链:cfq_select_queue----cfq_close_cooperator
cfq_select_queue的实现如下:
/*
* Select a queue for service. If we have a current active queue,
* check whether to continue servicing it, or retrieve and set a new one.
*/
static struct cfq_queue *cfq_select_queue(struct cfq_data *cfqd)
{
struct cfq_queue *cfqq, *new_cfqq = NULL; cfqq = cfqd->active_queue;
if (!cfqq)-----------------没有指定active_queue则跳转到new_queue去选择新的队列
goto new_queue; if (!cfqd->rq_queued)--------当前cfqd没有积压的request了,则返回,因为queue里面肯定也没有request了
return NULL; /*
* We were waiting for group to get backlogged. Expire the queue
*/
if (cfq_cfqq_wait_busy(cfqq) && !RB_EMPTY_ROOT(&cfqq->sort_list))
goto expire; /*
* The active queue has run out of time, expire it and select new.
*/
if (cfq_slice_used(cfqq) && !cfq_cfqq_must_dispatch(cfqq)) {----active_queue,这里检查该队列的时间片是否已经过去
/*
* If slice had not expired at the completion of last request
* we might not have turned on wait_busy flag. Don't expire
* the queue yet. Allow the group to get backlogged.
*
* The very fact that we have used the slice, that means we
* have been idling all along on this queue and it should be
* ok to wait for this request to complete.
*/
if (cfqq->cfqg->nr_cfqq == && RB_EMPTY_ROOT(&cfqq->sort_list)
&& cfqq->dispatched && cfq_should_idle(cfqd, cfqq)) {
cfqq = NULL;
goto keep_queue;
} else
goto check_group_idle;
} /*
* The active queue has requests and isn't expired, allow it to
* dispatch.
*/
if (!RB_EMPTY_ROOT(&cfqq->sort_list))-------表示时间片尚在,这里检查cfq_queue的sort_list是否为空
goto keep_queue; /*
* If another queue has a request waiting within our mean seek
* distance, let it run. The expire code will check for close
* cooperators and put the close queue at the front of the service
* tree. If possible, merge the expiring queue with the new cfqq.
*/
new_cfqq = cfq_close_cooperator(cfqd, cfqq);-----走到这里说明active_queue内已经没有请求了,因此要找一个最适合的cfq_queue,怎么查找下面描述
if (new_cfqq) {-----------找到了对应的比较靠近当前请求的cfqq
if (!cfqq->new_cfqq)
cfq_setup_merge(cfqq, new_cfqq);---------尝试merge两个queue
goto expire;
} /*
* No requests pending. If the active queue still has requests in
* flight or is idling for a new request, allow either of these
* conditions to happen (or time out) before selecting a new queue.
*/
if (timer_pending(&cfqd->idle_slice_timer)) {
cfqq = NULL;
goto keep_queue;
} /*
* This is a deep seek queue, but the device is much faster than
* the queue can deliver, don't idle
**/
if (CFQQ_SEEKY(cfqq) && cfq_cfqq_idle_window(cfqq) &&
(cfq_cfqq_slice_new(cfqq) ||
(cfqq->slice_end - jiffies > jiffies - cfqq->slice_start))) {
cfq_clear_cfqq_deep(cfqq);
cfq_clear_cfqq_idle_window(cfqq);
} if (cfqq->dispatched && cfq_should_idle(cfqd, cfqq)) {
cfqq = NULL;
goto keep_queue;
} /*
* If group idle is enabled and there are requests dispatched from
* this group, wait for requests to complete.
*/
check_group_idle:
if (cfqd->cfq_group_idle && cfqq->cfqg->nr_cfqq == &&
cfqq->cfqg->dispatched &&
!cfq_io_thinktime_big(cfqd, &cfqq->cfqg->ttime, true)) {
cfqq = NULL;
goto keep_queue;
} expire:
cfq_slice_expired(cfqd, );--------将时间片消耗完的active_queue重新插入service_tree,体现公平的含义
new_queue:
/*
* Current queue expired. Check if we have to switch to a new
* service tree
*/
if (!new_cfqq)
cfq_choose_cfqg(cfqd);-------------选择新的service tree cfqq = cfq_set_active_queue(cfqd, new_cfqq);----------设置new_cfqq为新的active_tree,开始接收时间片
keep_queue:
return cfqq;
}
如果当前queue因为没有request,cfq_close_cooperator会选择一个新的queue来调度,,其实选择好了之后光派发request还是比较简单的。这个函数实现如下:
static struct cfq_queue *cfq_close_cooperator(struct cfq_data *cfqd,
struct cfq_queue *cur_cfqq)
{
struct cfq_queue *cfqq; if (cfq_class_idle(cur_cfqq))
return NULL;
if (!cfq_cfqq_sync(cur_cfqq))----------------只考虑sync的类型,其他类型返回NULL
return NULL;
if (CFQQ_SEEKY(cur_cfqq))
return NULL; /*
* Don't search priority tree if it's the only queue in the group.
*/
if (cur_cfqq->cfqg->nr_cfqq == )
return NULL; /*
* We should notice if some of the queues are cooperating, eg
* working closely on the same area of the disk. In that case,
* we can group them together and don't waste time idling.
*/
cfqq = cfqq_close(cfqd, cur_cfqq);----找一个比较近的扇区,靠近cfqd->last_position 的,优先找紧靠的,然后两者相差一定阈值的,下面详细描述
if (!cfqq)
return NULL;----没找到,则返回 /* If new queue belongs to different cfq_group, don't choose it */
if (cur_cfqq->cfqg != cfqq->cfqg)----就算找到了对应的cfqq,但如果它的group不一样,还是不行
return NULL; /*
* It only makes sense to merge sync queues.
*/
if (!cfq_cfqq_sync(cfqq))--------非同步请求的队列,不能合并
return NULL;
if (CFQQ_SEEKY(cfqq))
return NULL; /*
* Do not merge queues of different priority classes
*/
if (cfq_class_rt(cfqq) != cfq_class_rt(cur_cfqq))-------不同优先级class也不能合并
return NULL; return cfqq;
}
cfqq_close的选择很讲究:
static struct cfq_queue *cfqq_close(struct cfq_data *cfqd,
struct cfq_queue *cur_cfqq)
{
struct rb_root *root = &cfqd->prio_trees[cur_cfqq->org_ioprio];
struct rb_node *parent, *node;
struct cfq_queue *__cfqq;
sector_t sector = cfqd->last_position; if (RB_EMPTY_ROOT(root))
return NULL; /*
* First, if we find a request starting at the end of the last
* request, choose it.
*/
__cfqq = cfq_prio_tree_lookup(cfqd, root, sector, &parent, NULL);-------如果有个请求他的start的扇区是上一个请求的最后位置,当然选它了,说明连续啊
if (__cfqq)
return __cfqq; /*
* If the exact sector wasn't found, the parent of the NULL leaf
* will contain the closest sector.
*/
__cfqq = rb_entry(parent, struct cfq_queue, p_node);----parent保存了最接近的节点的父节点,如果没找到相邻的cfq_queue,获取父节点对应的cfq_queue
if (cfq_rq_close(cfqd, cur_cfqq, __cfqq->next_rq))--间隙满足要求
return __cfqq; if (blk_rq_pos(__cfqq->next_rq) < sector)---下一个请求的位置小于之前的扇区,则往next找
node = rb_next(&__cfqq->p_node);
else
node = rb_prev(&__cfqq->p_node);------否则往前找,
if (!node)
return NULL; __cfqq = rb_entry(node, struct cfq_queue, p_node);---找到node后还是取对应的cfqq
if (cfq_rq_close(cfqd, cur_cfqq, __cfqq->next_rq))---再次判断这个cfqq能不能用,还是按照间隙来
return __cfqq; return NULL;
}
如何根据选择的调度队列下发request到 request queue:
如果找到了这样的队列,就要把这个队列设置为active队列,即调用 cfq_set_active_queue 来设置这个queue为active,然后即调用 cfq_dispatch_request 进行request的派发了。
cfq_dispatch_request 的实现如下,如果你到这个地方已经迷糊了,请回到调用链部分就行。
调用链:cfq_dispatch_request-----cfq_may_dispatch
-----cfq_check_fifo----------先看有没有快饿死的request,也就是等待过长时间的request
-----cfq_dispatch_insert
下面分别描述这几个函数实现:
/*
* Dispatch a request from cfqq, moving them to the request queue
* dispatch list.
*/
static bool cfq_dispatch_request(struct cfq_data *cfqd, struct cfq_queue *cfqq)
{
struct request *rq; BUG_ON(RB_EMPTY_ROOT(&cfqq->sort_list)); if (!cfq_may_dispatch(cfqd, cfqq))------下面描述,主要是判断是否继续发放cfqq中的请求
return false; /*
* follow expired path, else get first next available
*/
rq = cfq_check_fifo(cfqq);-------------如果fifo为空,或者fifo中第一个请求的期限还没到,则返回NULL,
if (!rq)
rq = cfqq->next_rq;----------------既然时间上不紧急,那么就从磁盘连续性考虑下一个请求 /*
* insert request into driver dispatch list
*/
cfq_dispatch_insert(cfqd->queue, rq);----取到请求了,放到设备的request queue if (!cfqd->active_cic) {
struct cfq_io_cq *cic = RQ_CIC(rq); atomic_long_inc(&cic->icq.ioc->refcount);
cfqd->active_cic = cic;
} return true;
}
cfq_may_dispatch:
static bool cfq_may_dispatch(struct cfq_data *cfqd, struct cfq_queue *cfqq)
{
unsigned int max_dispatch; /*
* Drain async requests before we start sync IO
*/
if (cfq_should_idle(cfqd, cfqq) && cfqd->rq_in_flight[BLK_RW_ASYNC])---如果cfqq可以被idle并且设备有异步请求处理,则不进行新的同步请求的发放
return false; /*
* If this is an async queue and we have sync IO in flight, let it wait
*/
if (cfqd->rq_in_flight[BLK_RW_SYNC] && !cfq_cfqq_sync(cfqq))---如果发放的是异步请求并且request_queue中还有同步请求在等待提交,则不下发
return false; max_dispatch = max_t(unsigned int, cfqd->cfq_quantum / , );-----------cfq_quantum是可以配置的,详见:/sys/block/sdb/queue/iosched/quantum
if (cfq_class_idle(cfqq))
max_dispatch = ;------cfqq的优先级类为idle类的话,最多一个请求,idle类好可怜, /*
* Does this cfqq already have too much IO in flight?
*/
if (cfqq->dispatched >= max_dispatch) {----超阈值
bool promote_sync = false;
/*
* idle queue must always only have a single IO in flight
*/
if (cfq_class_idle(cfqq))------idle类,歇着吧你,你就是天朝的屁民,优先级最低
return false; /*
* If there is only one sync queue
* we can ignore async queue here and give the sync
* queue no dispatch limit. The reason is a sync queue can
* preempt async queue, limiting the sync queue doesn't make
* sense. This is useful for aiostress test.
*/
if (cfq_cfqq_sync(cfqq) && cfqd->busy_sync_queues == )
promote_sync = true; /*
* We have other queues, don't allow more IO from this one
*/
if (cfqd->busy_queues > && cfq_slice_used_soon(cfqd, cfqq) &&
!promote_sync)
return false;----cfqd的其他队列在等待发放请求 /*
* Sole queue user, no limit
*/
if (cfqd->busy_queues == || promote_sync)----只有自己在发放请求
max_dispatch = -;
else
/*
* Normally we start throttling cfqq when cfq_quantum/2
* requests have been dispatched. But we can drive
* deeper queue depths at the beginning of slice
* subjected to upper limit of cfq_quantum.
* */
max_dispatch = cfqd->cfq_quantum;
} /*
* Async queues must wait a bit before being allowed dispatch.
* We also ramp up the dispatch depth gradually for async IO,
* based on the last sync IO we serviced
*/
if (!cfq_cfqq_sync(cfqq) && cfqd->cfq_latency) {
unsigned long last_sync = jiffies - cfqd->last_delayed_sync;
unsigned int depth; depth = last_sync / cfqd->cfq_slice[];
if (!depth && !cfqq->dispatched)
depth = ;
if (depth < max_dispatch)
max_dispatch = depth;
}---根据最后一次发送的同步请求和现在的时间间隔以及同步请求时间片的值,计算出depth,根据depth重置max_dispatch
/*
* If we're below the current max, allow a dispatch
*/
return cfqq->dispatched < max_dispatch;
}
cfq_check_fifo 只是比较一下时间,比较简单,略过不描述。通过选择之后,选择到期的request来下发。
cfq_dispatch_insert的实现如下:
static void cfq_dispatch_insert(struct request_queue *q, struct request *rq)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct cfq_queue *cfqq = RQ_CFQQ(rq); cfq_log_cfqq(cfqd, cfqq, "dispatch_insert");---记录log cfqq->next_rq = cfq_find_next_rq(cfqd, cfqq, rq);---取下一个请求,保存好
cfq_remove_request(rq);---从cfqq中sortlist和fifo队列中移除,要知道,此前的request的queuelist成员还是指向fifo中的请求,之后就指向request queue了
cfqq->dispatched++;
(RQ_CFQG(rq))->dispatched++;
elv_dispatch_sort(q, rq);----此时rq是自由的了,进入block device的request_queue,离开电梯调度层 cfqd->rq_in_flight[cfq_cfqq_sync(cfqq)]++;---这个request就像tcp发包一样,已经属于inflight了,不属于具体的cfq_queue了,不过还要在设备的request_queue呆一会排队
cfqq->nr_sectors += blk_rq_sectors(rq);
cfqg_stats_update_dispatch(cfqq->cfqg, blk_rq_bytes(rq), rq->cmd_flags);
}
进入request queue,需要进行排队, elv_dispatch_sort就负责干这个
/*
* Insert rq into dispatch queue of q. Queue lock must be held on
* entry. rq is sort instead into the dispatch queue. To be used by
* specific elevators.
*/
void elv_dispatch_sort(struct request_queue *q, struct request *rq)
{
sector_t boundary;
struct list_head *entry;
int stop_flags; if (q->last_merge == rq)----------这个变量之前也看到过,就是记录最后merge的request
q->last_merge = NULL; elv_rqhash_del(q, rq); q->nr_sorted--; boundary = q->end_sector;
stop_flags = REQ_SOFTBARRIER | REQ_STARTED;
list_for_each_prev(entry, &q->queue_head) {
struct request *pos = list_entry_rq(entry); if ((rq->cmd_flags & REQ_DISCARD) !=
(pos->cmd_flags & REQ_DISCARD))
break;
if (rq_data_dir(rq) != rq_data_dir(pos))
break;
if (pos->cmd_flags & stop_flags)
break;
if (blk_rq_pos(rq) >= boundary) {
if (blk_rq_pos(pos) < boundary)
continue;
} else {
if (blk_rq_pos(pos) >= boundary)
break;
}
if (blk_rq_pos(rq) >= blk_rq_pos(pos))
break;
} list_add(&rq->queuelist, entry);--------rq的queuelist成员嵌入到request_queue的queue_head管理的双向链表
}
如何执行一个request:
已经下发到request_queue中的request是如何被执行的呢?
主要的调用入口为:__blk_run_queue,
块IO命令的下发最终都是调用__blk_run_queue函数实现。__blk_run_queue调用块设备注册的request_fn方法下发块IO请求。
inline void __blk_run_queue_uncond(struct request_queue *q)
{
if (unlikely(blk_queue_dead(q)))
return; /*
* Some request_fn implementations, e.g. scsi_request_fn(), unlock
* the queue lock internally. As a result multiple threads may be
* running such a request function concurrently. Keep track of the
* number of active request_fn invocations such that blk_drain_queue()
* can wait until all these request_fn calls have finished.
*/
q->request_fn_active++;
q->request_fn(q);--------------还记得这个么?比如对于scsi设备来说,执行request的就是scsi_request_fn 了
q->request_fn_active--;
}
以 scsi_request_fn 为例,这个函数是调度层进入scsi层的入口,不过所谓层次概念,在目前的linux内核实现中,blk都是通过过程调用方式,就像linux net代码中的层次概念一样,不是windows的那种消息驱动方式。比如说我们fs层通过bio的方式申请request 来触发io,它的cmd_type 是REQ_TYPE_FS,在人们使用SG_IO发送命令的时候,scsi层也可以从request_list 中申请request,只不过它的类型是 REQ_TYPE_BLOCK_PC 而已,这个request中的bio指针则为NULL,sg内核驱动的存在使我们可以不使用文件系统,直接在用户空间调用scsi命令。
如果能一步步看到这里,说明你定力不错,给自己加个鸡腿吧,cfq里面还有timer那部分没有描述,留着下次补充。
附一张网上看到的图,挺佩服那些画图的兄弟,一图胜千言。
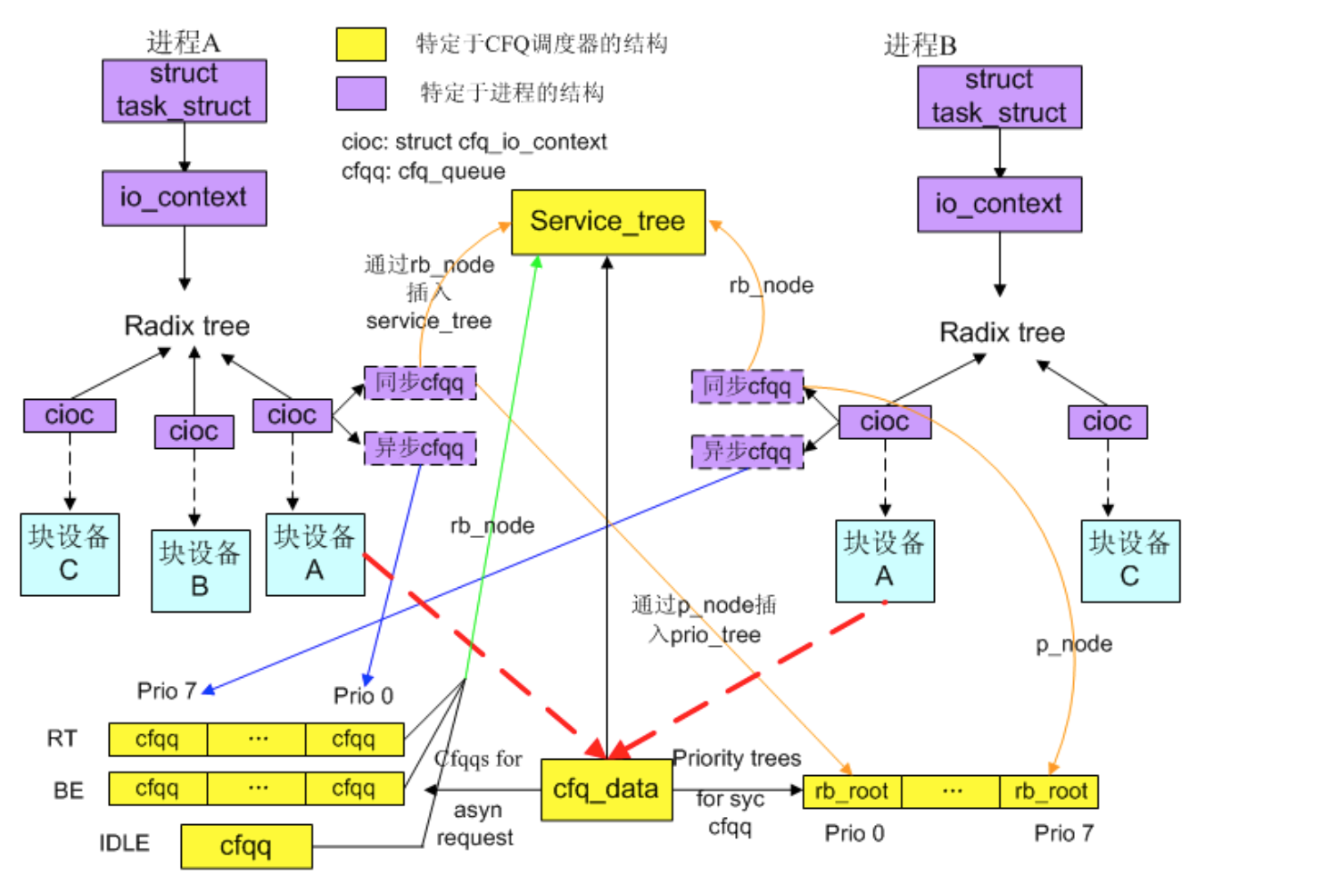
由于已经不知道原图的出处,无法给出链接,再次对图作者表示感谢。由于本文过长,计划下一篇学习记录《linux io 的cfq代码理解二》,描述时间片的计算,对cfqg的选择,组内的选择等。
参考资料:
https://www.kernel.org/doc/Documentation/block/cfq-iosched.txt
linux io的cfq代码理解的更多相关文章
- 【知乎网】Linux IO 多路复用 是什么意思?
提问一: Linux IO多路复用有 epoll, poll, select,知道epoll性能比其他几者要好.也在网上查了一下这几者的区别,表示没有弄明白. IO多路复用是什么意思,在实际的应用中是 ...
- linux IO调度
I/O 调度算法再各个进程竞争磁盘I/O的时候担当了裁判的角色.他要求请求的次序和时机做最优化的处理,以求得尽可能最好的整体I/O性能.在linux下面列出4种调度算法CFQ (Completely ...
- Linux IO 调度器
Linux IO Scheduler(Linux IO 调度器) 每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交 ...
- java基础之IO流及递归理解
一.IO流(简单理解是input/output流,数据流内存到磁盘或者从磁盘到内存等) 二.File类(就是操作文件和文件夹的) 1.FIleFile类构造方法 注意:通过构造方法创建的file对象是 ...
- Linux IO Scheduler(Linux IO 调度器)【转】
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request.I/O调度器的基本目的是将请求按照它们对应在块设 ...
- Linux IO性能分析blktrace/blk跟踪器
关键词:blktrace.blk tracer.blkparse.block traceevents.BIO. 本章只做一个记录,关于优化Block层IO性能方法工具. 对Block层没有详细分析,对 ...
- Linux IO系统分析(scsi篇)
一.概述 Linux内核中SCSI子系统由SCSI上层,中间层,底层驱动模块三部分组成,负责管理SCSI资源和处理其他子系统,如文件系统,提交到SCSI子系统中的IO请求. 因此,理解SCSI子系统的 ...
- Linux IO Scheduler
一直都对linux的io调度算法不理解,这段时间一直都在看这方面的内容,下面是总结和整理的网络上面的内容.生产上如何建议自己压一下.以实际为准. 每个块设备或者块设备的分区,都对应有自身的请求队列(r ...
- Linux IO 监控与深入分析
https://jaminzhang.github.io/os/Linux-IO-Monitoring-and-Deep-Analysis/ Linux IO 监控与深入分析 引言 接昨天电话面试,面 ...
随机推荐
- Beginning Math and Physics For Game Programmers (Wendy Stahler 著)
Chapter 1. Points and Lines (已看) Chapter 2. Geometry Snippets (已看) Chapter 3. Trigonometry Snippets ...
- servlet_4
过滤器入门 过滤器的概念及执行基本流程 过滤器的使用场景 过滤器的实现及基本配置 过滤器链 过滤器链的配置 使用注解的方式无法保证过滤器链的执行顺序,所以只能使用web.xml的配置 按照出现在web ...
- dubbo 中文官网
根大家分享一下:dubbo的中文官网迁移到了githup上地址:https://dubbo.gitbooks.io/dubbo-user-book/content/preface/background ...
- MQTT研究之EMQ:【SSL双向验证】
EMQ是当前MQTT中,用于物联网领域中比较出色的一个broker,今天我这里要记录和分享的是关于SSL安全通信的配置和注意细节. 环境: 1. 单台Linux CentOS7.2系统,安装一个EMQ ...
- Redis入门的简单使用
Redis是什么? redis是一个开源的,面向键/值对的NOSQL的分布式数据库系统 NOSQL指的是非关系型的数据,简单直白地讲就是在非关系型的数据库中不存在表的概念,而是以键值对的方式, 即一个 ...
- 【PLM】【PDM】60页PPT终于说清了PDM和PLM的区别;智造时代,PLM系统10大应用趋势!
https://blog.csdn.net/np4rhi455vg29y2/article/details/79266738
- 解决Table不继承父节点的属性的方法
解决Table不继承父节点的属性的方法 发现table不继承父节点的属性. 解决方法:给html文件加上<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML ...
- Cleanmymac X好不好用?
Cleanmymac X是一款Mac清理软件,能够帮助我们快速实现快速实现磁盘清理,是mac用户的智能助手.那么为什么大家会认定它并坚定不移呢?小编带你感受感受. 1. 简洁大气的外观. 用户正版官方 ...
- Xilinx FPGA开发随笔
1.UCF文件 1.1.UCF作用 UCF文件主要是完成管脚的约束,时钟的约束, 以及组的约束. 1.2.UCF语法 普通IO口只需约束引脚号和电压: NET "端口名称" LOC ...
- Ubuntu 16.04.3 LTS 安装 MongoDB
1.安装Ubuntu16.04 运行sudo apt-get install mongodb安装Mongodb 如果没有MongoDB库,则运行sudo apt-get update更新库. 2.运行 ...