Hadoop记录-fair公平调度队列管理
<?xml version="1.0"?>
<allocations>
<queue name="root">
<queue name="default">
<minResources>2048 mb,4 vcores</minResources>
<maxResources>2000000 mb,660 vcores</maxResources>
<maxRunningApps>80</maxRunningApps>
<aclSubmitApps>*</aclSubmitApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode> </queue>
<queue name="queue_a">
<minResources>2048 mb,4 vcores</minResources>
<maxResources>102400 mb,148 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<aclSubmitApps>*</aclSubmitApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode>
</queue>
<queue name="queue_b">
<minResources>2048 mb,4 vcores</minResources>
<maxResources>102400 mb,148 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<aclSubmitApps>*</aclSubmitApps>
<weight>2.0</weight>
<schedulingMode>fair</schedulingMode>
</queue>
</queue>
</allocations>
beeline -u " jdbc:hive2://10.202.77.201:10000" -n hive -p hive
set hive.execution.engine=tez;
nohup hive --service hiveserver2 &
nohup hive --service metastore &
hive -S -e "select * from xxx" --S静音模式不打印MR2的进度信息 e加载hql查询语句
hive -f test.hql --加载一个hql文件
source test.hql
for f in 'rpm -qa | grep xxx';do rpm -e --nodeps ${f} done;
磁盘空间满了,kill超时太长的job
cd hive/yarn/local1/usercache/hive/appcache
su yarn
yarn application -kill job名
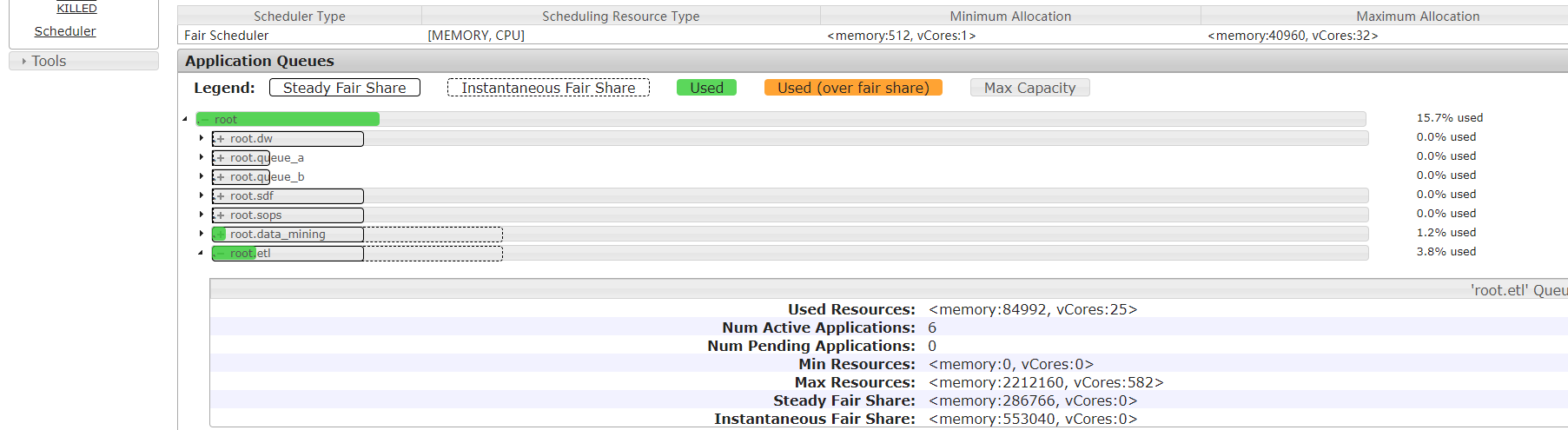
Hadoop记录-fair公平调度队列管理的更多相关文章
- Hadoop记录-MRv2(Yarn)运行机制
1.MRv2结构—Yarn模式运行机制 Client---客户端提交任务 ResourceManager---资源管理 ---Scheduler调度器-资源分配Containers ----在Yarn ...
- hadoop记录-Hadoop参数汇总
Hadoop参数汇总 linux参数 以下参数最好优化一下: 文件描述符ulimit -n 用户最大进程 nproc (hbase需要 hbse book) 关闭swap分区 设置合理的预读取缓冲区 ...
- hadoop学习笔记肆--元数据管理机制
1.首先,认识几个名词 (1).NameNode中读.写.以及DataNode映射等信息叫做“元数据” ,NameNode元数据存放位置有.内存.fsimage.edits log三个位置. (2). ...
- Hadoop记录-hdfs转载
Hadoop 存档 每个文件均按块存储,每个块的元数据存储在namenode的内存中,因此hadoop存储小文件会非常低效.因为大量的小文件会耗尽namenode中的大部分内存.但注意,存储小文件所需 ...
- Hadoop记录-hadoop介绍
1.hadoop是什么? Hadoop 是Apache基金会下一个开源的大数据分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心,为用户提供了系统底层细节透明的分布式基础架构. ...
- spark的task调度器(FAIR公平调度算法)
FAIR 调度策略的树结构如下图所示: FAIR 调度策略内存结构 FAIR 模式中有一个 rootPool 和多个子 Pool, 各个子 Pool 中存储着所有待分配的 TaskSetMagage ...
- hadoop记录-hive常见设置
分区表 set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict;create tabl ...
- Hadoop记录-JMX参数
Yarn metrics参数说明 获取Yarn jmx信息:curl -i http://xxx:8088/jmx Hadoop:service=ResourceManager,name=FSOpDu ...
- Hadoop记录-日常运维操作
1.Active NameNode hang死,未自动切换 #登录当前hang死 Active namenode主机,停止Namenode,触发自动切换.hadoop-daemon.sh stop n ...
随机推荐
- P1403 [AHOI2005]约数研究
原题链接 https://www.luogu.org/problemnew/show/P1403 这个好难啊,求约数和一般的套路就是求1--n所有的约数再一一求和,求约数又要用for循环来判断.... ...
- CH0805 防线(算竞进阶习题)
二分 一道藏的很深的二分题... 题目保证只有一个点有奇数个防具,这个是突破口. 因为 奇数+偶数=偶数,我们假设某个点x,如果有奇数点的防具在x的左边,那么x的左边的防具总数一定是奇数,右边就是偶数 ...
- 【BZOJ2127】happiness 网络流
题目描述 有\(n\times m\)个人,排成一个\(n\times m\)的矩阵.每个同学和前后左右相邻的同学互相成为了好朋友.这学期要分文理科了,每个同学对于选择文科与理科有着自己的喜悦值,而一 ...
- haar的简单应用(2)
上次对图片进行了人脸识别,这次对摄像头捕获的内容进行识别 直接写注释来解释 import cv2 def CatchUsbVideo(window_name, camera_idx): #定义一个函数 ...
- Dockerfile基础
Dockerfile基础Dockerfile分四部分组成: 基础镜像.维护者信息.镜像操作指令.启动时命令ps: 我的本地镜像已经有centos,若没有请使用docker pull centos 入门 ...
- Swarm stack
什么是 stack ?例如:首先创建 secret. 然后创建 MySQL service,这是 WordPress 依赖的服务. 最后创建 WordPress service. 也就是说,这个应用包 ...
- LOJ#6280. 数列分块入门 4
另外开一个数组维护每一个块内的总和. 给区间加值是,残余的块一个一个点更新,整个的块一次性更新 查询的时候也是,残余的块一个一个点加,整个的块一次性加 #include<map> #inc ...
- webRequest封装
from requests.models import Response import requests import random import time class WebRequest(obje ...
- layer 弹出层
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- BZOJ2244 拦截导弹
此题最早看到是在我还什么都不会的去年的暑期集训,是V8讲的DP专题,我当时还跑去问这概率怎么做.这道题要求的是二维最长不上升子序列,加上位置一维就成了三维偏序问题,也就是套用CDQ分治,对位置排序,然 ...