python学习笔记-(十五)RabbitMQ队列
rabbitMQ是消息队列;想想之前的我们学过队列queue:threading queue(线程queue,多个线程之间进行数据交互)、进程queue(父进程与子进程进行交互或者同属于同一父进程下的多个子进程进行交互);如果两个独立的程序,那么之间是不能通过queue进行交互的,这时候我们就需要一个中间代理即rabbitMQ
消息队列:
- RabbitMQ
- ZeroMQ
- ActiveMQ
- ...........
一. 安装
1. ubuntu下安装rabbitMQ:
1.1 安装: sudo apt-get install rabbitmq-server
1.2 启动rabbitmq web服务:
sudo invoke-rc.d rabbitmq-server stop
sudo invoke-rc.d rabbitmq-server start
启动web管理:sudo rabbitmq-plugins enable rabbitmq_management
1.3 远程访问rabbitmq,自己增加一个用户,步骤如下:
- 创建一个admin用户:sudo rabbitmqctl add_user admin 123123
- 设置该用户为administrator角色:sudo rabbitmqctl set_user_tags admin administrator
- 设置权限:sudo rabbitmqctl set_permissions -p '/' admin '.' '.' '.'
- 重启rabbitmq服务:sudo service rabbitmq-server restart
之后就能用admin用户远程连接rabbitmq server了。
2. 安装python rabbitMQ modul:
- 管理员打开cmd,切换到python的安装路径,进入到Scripts目录下(如:C:\Users\Administrator\AppData\Local\Programs\Python\Python35\Scripts);
- 执行以下命令:pip install pika
- 校验是否安装成功:进入到python命令行模式,输入import pika,无报错代表成功;
二. 代码实现
1. 实现最简单的队列通信

发送端:
import pika
credentials = pika.PlainCredentials('admin', '123123')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
#声明queue
channel.queue_declare(queue='hello')
#n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
接收端:
import pika
credentials = pika.PlainCredentials('admin', '123123')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
2. RabbitMQ消息分发轮询
先启动消息生产者,然后再分别启动3个消费者,通过生产者多发送几条消息,你会发现,这几条消息会被依次分配到各个消费者身上
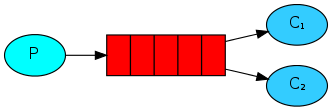
在这种模式下,RabbitMQ会默认把p发的消息公平的依次分发给各个消费者(c),跟负载均衡差不多
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc') #声明queue队列
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!'
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc')
def callback(ch,method,properties,body):
print(ch,method,properties)
#ch:<pika.adapters.blocking_connection.BlockingChannel object at 0x002E6C90> 管道内存对象地址
#methon:<Basic.Deliver(['consumer_tag=ctag1.03d155a851b146f19cee393ff1a7ae38', #具体信息
# 'delivery_tag=1', 'exchange=', 'redelivered=False', 'routing_key=lzl'])>
#properties:<BasicProperties>
print("Received %r"%body)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
consume.py
通过执行pubulish.py和consume.py可以实现上面的消息公平分发,那假如c1收到消息之后宕机了,会出现什么情况呢?rabbitMQ是如何处理的?现在我们模拟一下:
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc') #声明queue队列
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!'
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
import pika,time
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc')
def callback(ch,method,properties,body):
print("->>",ch,method,properties)
time.sleep(15) # 模拟处理时间
print("Received %r"%body)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
consume.py
在consume.py的callback函数里增加了time.sleep模拟函数处理,通过上面程序进行模拟发现,c1接收到消息后没有处理完突然宕机,消息就从队列上消失了,rabbitMQ把消息删除掉了;如果程序要求消息必须要处理完才能从队列里删除,那我们就需要对程序进行处理一下:
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc') #声明queue队列
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!'
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
import pika,time
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc')
def callback(ch,method,properties,body):
print("->>",ch,method,properties)
#time.sleep(15) # 模拟处理时间
print("Received %r"%body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
consume.py
通过把consume.py接收端里的no_ack=True去掉之后并在callback函数里面添加ch.basic_ack(delivery_tag = method.delivery_tag,就可以实现消息不被处理完不能在队列里清除。
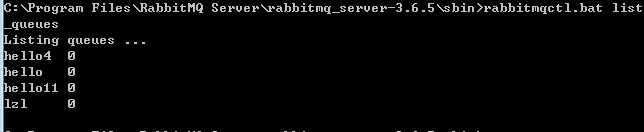
查看消息队列数:
3. 消息持久化
如果消息在传输过程中rabbitMQ服务器宕机了,会发现之前的消息队列就不存在了,这时我们就要用到消息持久化,消息持久化会让队列不随着服务器宕机而消失,会永久的保存下去
发送端:
import pika
credentials = pika.PlainCredentials('admin', '123123')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc',durable=True) #队列持久化
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode = 2 #消息持久化
)
)
print("Sent 'Hello,World!'")
connection.close() #关闭
接收端:
import pika,time
credentials = pika.PlainCredentials('admin', '123123')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc',durable=True)
def callback(ch,method,properties,body):
print("->>",ch,method,properties)
time.sleep(15) # 模拟处理时间
print("Received %r"%body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
4. 消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
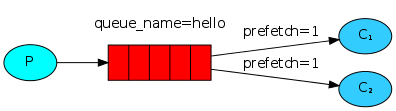
channel.basic_qos(prefetch_count=1)
带消息持久化+公平分发:
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel() #声明一个管道(管道内发消息)
channel.queue_declare(queue='cc',durable=True) #队列持久化
channel.basic_publish(exchange='',
routing_key='cc', #routing_key 就是queue名
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode = 2 #消息持久化
)
)
print("Sent 'Hello,World!'")
connection.close() #关闭
publish.py
import pika,time
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.queue_declare(queue='cc',durable=True)
def callback(ch,method,properties,body):
print("->>",ch,method,properties)
time.sleep(15) # 模拟处理时间
print("Received %r"%body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback, #如果收到消息,就调用callback函数处理消息
queue="cc",
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() #开始收消息
consume.py
5. Publish\Subscribe(消息发布\订阅)
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了,
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息:
- fanout: 所有bind到此exchange的queue都可以接收消息
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
- topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
- headers: 通过headers 来决定把消息发给哪些queue
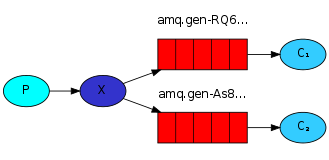
5.1 fanout接收所有广播:
import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='logs',
type='fanout') message = "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='', #广播不用声明queue
body=message)
print(" [x] Sent %r" % message)
connection.close()
publish.py
import pika
credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
result = channel.queue_declare(exclusive=True) # 不指定queue名字,rabbit会随机分配一个名字,
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs', # 绑定转发器,收转发器上面的数据
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
consume.py
5.2 有选择的接收消息 direct:
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列
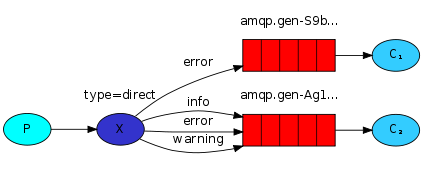
import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
publish.py
import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1) for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming() consume.py
consume.py
5.3 更细致的消息过滤 topic:

import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close() publish.py
publish.py
import pika
import sys credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1) for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
consume.py
5.4 RPC(Remote procedure call )双向通信:
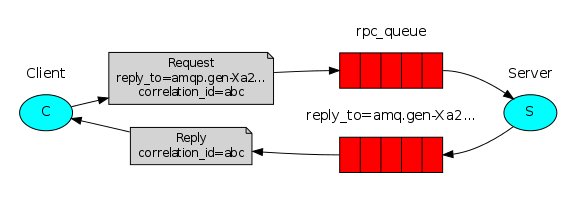
import pika
import time credentials = pika.PlainCredentials('admin', '')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2) def on_request(ch, method, props, body):
n = int(body) print(" [.] fib(%s)" % n)
response = fib(n) ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests")
channel.start_consuming()
rpc server
import pika
import uuid class FibonacciRpcClient(object):
def __init__(self):
credentials = pika.PlainCredentials('admin', '')
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
'192.168.16.82', 5672, '/', credentials)) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue) def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response) fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
rpc client
python学习笔记-(十五)RabbitMQ队列的更多相关文章
- python 学习笔记十五 web框架
python Web程序 众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端. Python的WEB框架分为两类: 自己写socket,自 ...
- python 学习笔记十五 django基础
Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了ORM.模型绑定.模板引擎.缓存.Session等诸多功能. ...
- python学习笔记(十五)-unittest单元测试的一个框架
unittest 单元测试的一个框架什么框架 一堆工具的集合. TestCase TestSuite 测试套件,多个用例在一起 TestLoader是用来加载TestCase到TestSuite中的 ...
- python学习笔记十五:日期时间处理笔记
#-*- coding: utf-8 -*- import datetime #给定日期向后N天的日期 def dateadd_day(days): d1 = datetime.datetime.no ...
- python学习笔记(十五)-异常处理
money = input('输入多少钱:') months = input('还几个月:') try: res = calc(int(money),int(months)) except ZeroD ...
- python3.4学习笔记(十五) 字符串操作(string替换、删除、截取、复制、连接、比较、查找、包含、大小写转换、分割等)
python3.4学习笔记(十五) 字符串操作(string替换.删除.截取.复制.连接.比较.查找.包含.大小写转换.分割等) python print 不换行(在后面加上,end=''),prin ...
- python学习笔记(五岁以下儿童)深深浅浅的副本复印件,文件和文件夹
python学习笔记(五岁以下儿童) 深拷贝-浅拷贝 浅拷贝就是对引用的拷贝(仅仅拷贝父对象) 深拷贝就是对对象的资源拷贝 普通的复制,仅仅是添加了一个指向同一个地址空间的"标签" ...
- Python学习笔记(五)
Python学习笔记(五): 文件操作 另一种文件打开方式-with 作业-三级菜单高大上版 1. 知识点 能调用方法的一定是对象 涉及文件的三个过程:打开-操作-关闭 python3中一个汉字就是一 ...
- Python学习笔记(十二)—Python3中pip包管理工具的安装【转】
本文转载自:https://blog.csdn.net/sinat_14849739/article/details/79101529 版权声明:本文为博主原创文章,未经博主允许不得转载. https ...
- (转载)西门子PLC学习笔记十五-(数据块及数据访问方式)
一.数据块 数据块是在S7 CPU的存储器中定义的,用户可以定义多了数据块,但是CPU对数据块数量及数据总量是有限制的. 数据块与临时数据不同,当逻辑块执行结束或数据块关闭,数据块中的数据是会保留住的 ...
随机推荐
- 在CentOS中安装NodeJS
1. 更改软件源 备份默认的软件源文件“CentOS-Base.repo” mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-B ...
- 不同版本SQL SERVER备份还原时造成索引被禁用
以下测试例子以SQL 2008备份,在SQL2014还原,造成索引被禁用. --备份环境(SQL Server 2008 R2) /* MicrosoftSQL Server 2008 R2 (RTM ...
- WordPress目录文件结构详细说明
根目录 |-wp-admin | |-css | |-images | |-includes | |-js | |-maint | |-network | |-user |-wp-content | ...
- 解决虚拟机VMware安装CentOS7.0识别不到网卡
由于Vmware虚拟网卡和linux兼容问题导致驱动无法正常安装,默认的网卡类型不兼容. 解决方法 找到我们的Vmware虚拟机文件夹,将VMware 虚拟机配置 (.vmx),追加一条设置我们网卡类 ...
- 【Windows编程】系列第二篇:Windows SDK创建基本控件
在Win32 SDK环境下,怎么来创建常用的那些基本控件呢?我们知道如果用MFC,简单的拖放即可完成大多数控件的创建,但是我们既然是用Windows SDK API编程,当然是从根上解决这个问题,实际 ...
- [django]django+post+ajax+highcharts使用方法
直接代码展示: view.py文件代码 from django.http import JsonResponse #django ajax部分 def ajax_kchart(request): ti ...
- TJ2016 CTF Write up
No zuo no die. Use markdown to write writeup in the future......
- 【CSS】使用盒模型
盒子是CSS中的基础概念,我们需要使用它来配置元素的外观以及文档的整体布局. 1. 为元素应用内边距 应用内边距会在元素内容和边距之间添加空白.我们可以为内容盒的每个边界单独设置内边距,或者使用 pa ...
- Hibernate批量处理数据
01.批量插入数据 步骤一.创建实体类,Dept和Emp /** * 员工类 * @author Administrator * */ public class Emp { private Integ ...
- NOIP模拟赛20161114
幸运串 题意:长度为n,字符集大小为m的字符串中有多少不同的不含回文的串 n,m<10^9 我靠这不就是萌数的DP部分吗 有规律 f[2][j][k]=1 f[i][j][k]=sigma{f[ ...