吴裕雄 python深度学习与实践(5)
import numpy as np data = np.mat([[1,200,105,3,False],
[2,165,80,2,False],
[3,184.5,120,2,False],
[4,116,70.8,1,False],
[5,270,150,4,True]])
row = 0
for line in data:
row += 1
print(row)
print(data.size)

import numpy as np data = np.mat([[1,200,105,3,False],
[2,165,80,2,False],
[3,184.5,120,2,False],
[4,116,70.8,1,False],
[5,270,150,4,True]])
print(data[0,3])
print(data[0,4])
import numpy as np data = np.mat([[1,200,105,3,False],
[2,165,80,2,False],
[3,184.5,120,2,False],
[4,116,70.8,1,False],
[5,270,150,4,True]])
print(data)
col1 = []
for row in data:
print(row)
col1.append(row[0,1]) print(col1)
print(np.sum(col1))
print(np.mean(col1))
print(np.std(col1))
print(np.var(col1))

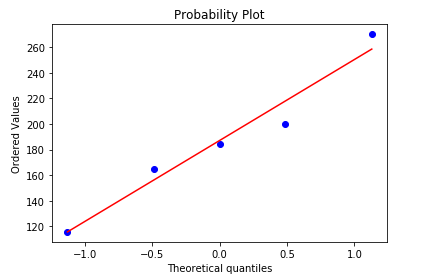
import pylab
import numpy as np
import scipy.stats as stats data = np.mat([[1,200,105,3,False],
[2,165,80,2,False],
[3,184.5,120,2,False],
[4,116,70.8,1,False],
[5,270,150,4,True]]) col1 = []
for row in data:
col1.append(row[0,1]) stats.probplot(col1,plot=pylab)
pylab.show()
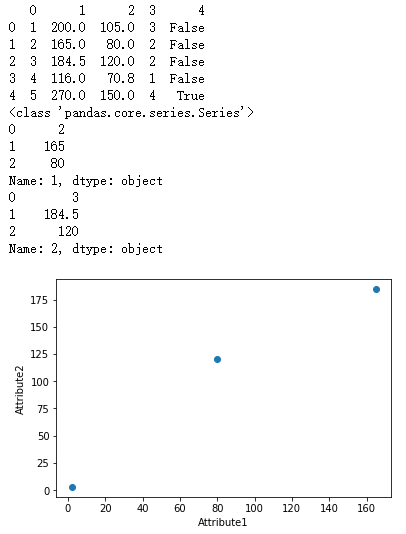
import pandas as pd
import matplotlib.pyplot as plot rocksVMines = pd.DataFrame([[1,200,105,3,False],
[2,165,80,2,False],
[3,184.5,120,2,False],
[4,116,70.8,1,False],
[5,270,150,4,True]])
print(rocksVMines)
dataRow1 = rocksVMines.iloc[1,0:3]
dataRow2 = rocksVMines.iloc[2,0:3]
print(type(dataRow1))
print(dataRow1)
print(dataRow2)
plot.scatter(dataRow1, dataRow2)
plot.xlabel("Attribute1")
plot.ylabel("Attribute2")
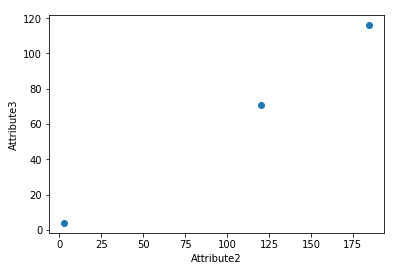
plot.show() dataRow3 = rocksVMines.iloc[3,0:3]
plot.scatter(dataRow2, dataRow3)
plot.xlabel("Attribute2")
plot.ylabel("Attribute3")
plot.show()
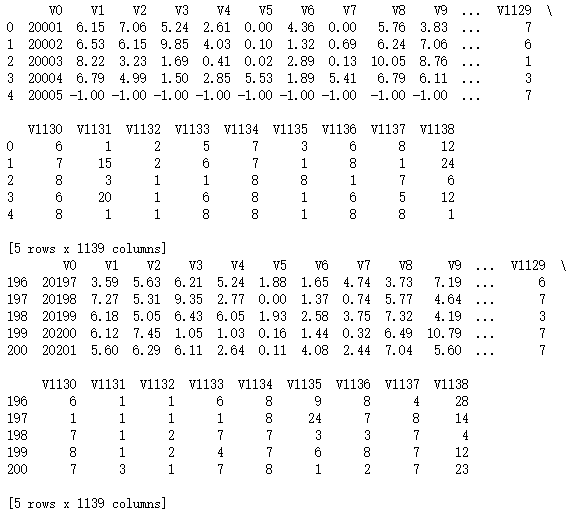
import numpy as np
import pandas as pd
import matplotlib.pyplot as plot filePath = ("G:\\MyLearning\\TensorFlow_deep_learn\\data\\dataTest.csv")
dataFile = pd.read_csv(filePath,header=None, prefix="V")
print(np.shape(dataFile))
dataRow1 = dataFile.iloc[100,1:300]
dataRow2 = dataFile.iloc[101,1:300]
plot.scatter(dataRow1, dataRow2)
plot.xlabel("Attribute1")
plot.ylabel("Attribute2")
plot.show()
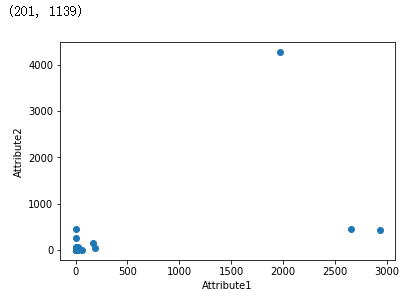
import pandas as pd
import matplotlib.pyplot as plot filePath = ("G:\\MyLearning\\TensorFlow_deep_learn\\data\\dataTest.csv")
dataFile = pd.read_csv(filePath,header=None, prefix="V") target = []
for i in range(200):
if dataFile.iat[i,10] >= 7:
target.append(1.0)
else:
target.append(0.0) dataRow = dataFile.iloc[0:200,10]
plot.scatter(dataRow, target)
plot.xlabel("Attribute")
plot.ylabel("Target")
plot.show()
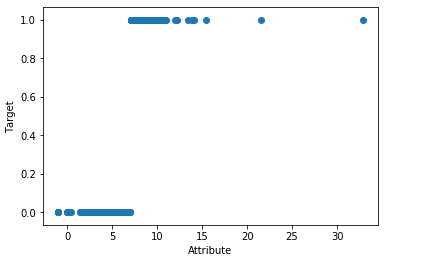
import random as rd
import pandas as pd
import matplotlib.pyplot as plot filePath = ("G:\\MyLearning\\TensorFlow_deep_learn\\data\\dataTest.csv")
dataFile = pd.read_csv(filePath,header=None, prefix="V") target = []
for i in range(200):
if dataFile.iat[i,10] >= 7:
target.append(1.0 + rd.uniform(-0.3, 0.3))
else:
target.append(0.0 + rd.uniform(-0.3, 0.3))
dataRow = dataFile.iloc[0:200,10]
plot.scatter(dataRow, target, alpha=0.5, s=100)
plot.xlabel("Attribute")
plot.ylabel("Target")
plot.show()
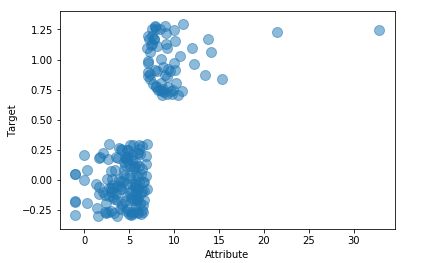
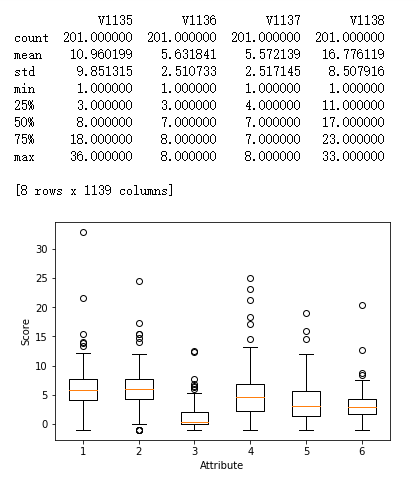
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot filePath = ("G:\\MyLearning\\TensorFlow_deep_learn\\data\\dataTest.csv")
dataFile = pd.read_csv(filePath,header=None, prefix="V") print(dataFile.head())
print(dataFile.tail()) summary = dataFile.describe()
print(summary) array = dataFile.iloc[:,10:16].values
boxplot(array)
plot.xlabel("Attribute")
plot.ylabel("Score")
show()

吴裕雄 python深度学习与实践(5)的更多相关文章
- 吴裕雄 python深度学习与实践(18)
# coding: utf-8 import time import numpy as np import tensorflow as tf import _pickle as pickle impo ...
- 吴裕雄 python深度学习与实践(17)
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import time # 声明输 ...
- 吴裕雄 python深度学习与实践(16)
import struct import numpy as np import matplotlib.pyplot as plt dateMat = np.ones((7,7)) kernel = n ...
- 吴裕雄 python深度学习与实践(15)
import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data mnist = ...
- 吴裕雄 python深度学习与实践(14)
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt threshold = 1.0e-2 x1_dat ...
- 吴裕雄 python深度学习与实践(13)
import numpy as np import matplotlib.pyplot as plt x_data = np.random.randn(10) print(x_data) y_data ...
- 吴裕雄 python深度学习与实践(12)
import tensorflow as tf q = tf.FIFOQueue(,"float32") counter = tf.Variable(0.0) add_op = t ...
- 吴裕雄 python深度学习与实践(11)
import numpy as np from matplotlib import pyplot as plt A = np.array([[5],[4]]) C = np.array([[4],[6 ...
- 吴裕雄 python深度学习与实践(10)
import tensorflow as tf input1 = tf.constant(1) print(input1) input2 = tf.Variable(2,tf.int32) print ...
- 吴裕雄 python深度学习与实践(9)
import numpy as np import tensorflow as tf inputX = np.random.rand(100) inputY = np.multiply(3,input ...
随机推荐
- django-request获取数据
request 如果说 urls.py 是 Django 中前端页面和后台程序桥梁,那么 request 就是桥上负责运输的小汽车 可以说后端接收到的来至前端的信息几乎全部来自于requests中. ...
- 「NOI2018」屠龙勇士(CRT)
/* 首先杀每条龙用到的刀是能够确定的, 然后我们便得到了许多形如 ai - x * atki | pi的方程 而且限制了x的最小值 那么exgcd解出来就好了 之后就是扩展crt合并了 因为全T调了 ...
- SVN上拖下来的项目,缺少build path怎么办?
在eclipse里用subeclipe从svn上拖下来的项目,看不见java build path怎么办? 原因那是因为你的两个配置文件:.project .classpath没有内容或者缺失. 重新 ...
- Shell 格式化输出数字、字符串(printf)
1.语法 printf打印格式字符串,解释'%'指令和'\'转义. 1.1.转义 printf使用时需要指定输出格式,输出后不换行. printf FORMAT [ARGUMENT] printf O ...
- uva-10132-排序
题意: 有很多文件,碎成了俩片,问,原来的文件是什么,如果有多个答案,任意一个答案就行,输入2N个字符串,拼接成N个文件. 直接排序,正确的答案一定是某个长度最短的和某个最长的连在一起. #inclu ...
- Python学习笔记_week3_函数
一.介绍 1.面向对象(华山派)--->类(独门秘籍)--->class(定义的关键字) 2.面向过程(少林派)--->过程--->def 3.函数式编程(逍遥派)---> ...
- <转载> MySQL 性能优化的最佳20多条经验分享 http://www.jb51.net/article/24392.htm
当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能.这里,我们不会讲过多的SQL语句的优化,而只是针对MySQL这一Web应用最多的数据库.希望下面的这 ...
- linux驱动开发第二步 驱动模块传参(module_param函数使用)
在驱动的模块中声明一下你要传递的参数名称,类型和权限 module_param(变量的名称,类型,权限); 先上例子 #include <linux/init.h> #include &l ...
- Tomcat的相关配置问题
Tomcat的目录结构bin --- 存放启动和关闭tomcat的脚本文件 conf --- 存放tomcat的各种配置文件 (主要有server.xml,context.xml,web.xml) ...
- day44-pymysql模块的使用
pymysql模块的使用 本节重点: pymysql的下载和使用 execute()之sql注入 增.删.改:conn.commit() 查:fetchone.fetchmany.fetchall 一 ...