A*算法–A* algorithm tutorial
Author:Justin Heyes-Jones
From: http://heyes-jones.com/astar.php
Date:2014.8.16
本文地址:http://www.cnblogs.com/killerlegend/p/3917083.html Translated By KillerLegend
前言:前不久数学建模涉及到一个地图路径最优化的模型,最初采用的是Dijkstra算法以及Kruscal最小生成树等算法进行解决的,后来在网上查找时偶然遇到了A*算法,于是就看了看.期间遇到了这篇介绍A*算法的文章,并且作者已经实现了模板并且开源以供使用,作者的这种精神让我很赞,代码已经很成熟,作者给出了使用方法,代码注释的还是比较详细的,代码写的也很精彩,很棒!希望你可以仔细体会一下作者的思路.
说明:其中@Cmt-Beg和@Cmt-End是我自己的理解,[@quote]是引用的其他内容.除此之外是原文的翻译.另外有几张图片比较模糊,所以自己就按照原图又制作了几张清晰的,以方便你查看.
文章很不错,于是便翻译了一下,希望这篇优秀的文章可以让更多的人看到!如果有哪里翻译的不当或理解有误,还恳请你提出,谢谢!
以下是正文:
介绍Introduction
欢迎来到A*算法教程.A*算法经常用于视频游戏中, 在虚拟世界中给人物导航.这个教程向你介绍A*算法并描述如何实现A*算法.教程的源代码可以在GitHub上下载.
状态空间搜索(State space search)
A*是一种搜索算法.通过将世界(world)表示成初始状态,我们可以求解某些问题,对于世界中每一个要执行的动作,我们可以产生相应的状态(就像如果我们这样做,这个世界将会有什么相对的反应).如果你不断的这样做直到世界是我们所期望的状态(一个解决方案),那么从起始点到目标点的路径就是你所面对的问题的解决方案.在这个教程中,我将会使用状态空间搜索来寻找两点间的最短路径(路径发现:pathfinding),也会解决一个简单的滑块迷宫问题(8迷宫问题).首先让我们先来看一些人工智能方面的专业术语,这些术语在描述状态空间搜索时会用到:
一些专业术语(Some terminology)
一个节点就是一个状态,指代世界可能面对的问题.在路径搜索中,一个节点是将会是一个二维坐标,表示我们所在的地方.在8迷宫问题中,它是所有滑块的位置.接下来所有的节点被放在一个图中,其中,节点之间的连接代表解决一个问题的有效步骤.这些连接称之为边.在8迷宫问题中,边以蓝色的线显示,看图1.状态空间搜索这样解决问题:由起始状态开始,然后对于每一个节点,通过应用所有可能的移动步骤来展开其下所有的节点.
启发式和算法(Heuristics and Algorithms)
在此,我们引入一个重要的概念:启发式.这像一个算法,但是和算法有一个关键的区别.一个算法是一系列步骤,你可以按照这些步骤来解决问题,对于有效的输入,算法总是可以正常工作的.比如,你可以自己写一个算法来计算两个数的乘积.而启发式则不保证一定正常工作,但是它的确很有用,因为当没有算法的时候,它也可能解决一个问题.我们需要一个启发式函数来帮助我们减少巨大的搜索问题.我们需要的是在每一个节点使用启发式函数来评估我们距离目标节点还有多远.在路径搜索问题中,我们精确的知道我们距离起始点多远,因为每一步我们都知道移动的距离,因此我们也可以计算我们到目标点处的精确距离.但是,8迷宫问题是比较困难的.对于一个给定的位置,没有已知的算法能够计算出我们需要移动多少步可以到达目标点.因此,衍生出各种启发式搜索.我所知道的最好的启发式搜索是Nillson Score,在很多情况下,这个启发式搜索可以很巧妙地直接引导你到达目标状态.
花费(Cost)
对于图中的每一个节点,我们现在考虑启发式函数,启发式函数可以评估当前状态距离目标态多远.另一个需要关心的是到达我们所处的位置的花费.在路径发现问题中,我们经常赋予每个方块一个花费.所有的方块花费是一样的,因此每个方块的花费是1(这句话听起来有点令人不解,但是想一想小学的时候,我们做的应用题,比如:一项工程,甲每天做1/3,已每天做2/1,那么甲乙合作多少天做完?我记得当时通行的解法就是设工程为单位1,这里的1虽然意义不一样,当都是一个虚指,因为各个方块之间的花费没有差异嘛,所以就用1来表示,没有为什么).如果我们想要区分不同的地形,我们可以给草地以及泥地更高花费,而给新修建的道路较低的花费.对于一个节点,我们需要加上到达此处的花费,这个仅仅是对此节点以及在图中其上方所有节点的花费之和.
8迷宫(8 Puzzle)
我们仔细来看一看8迷宫问题.这是一个简单滑块迷宫问题,由3x3的网格组成,其中缺失一个滑块,你可以移动其他滑块到这个间隙,直到你使迷宫达到目标状态,见图1:
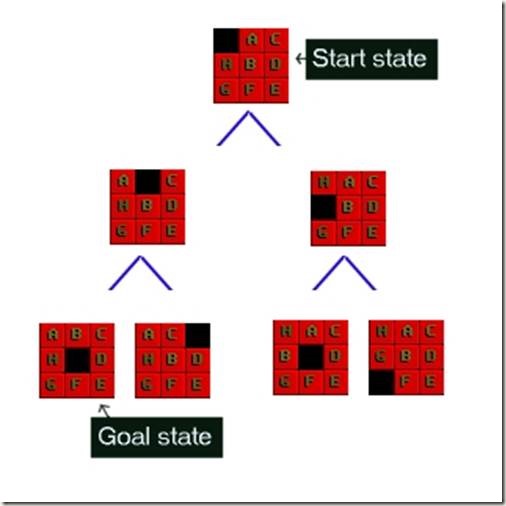
图1:一个简单的8迷宫状态空间
迷宫可能有362,880种不同的状态,为了找到一个解决方案,搜索必须通过这些状态找到一条路径.对于搜索的大部分情况,边(蓝色线)的数量是2.这意味着每一级的节点数目是2^d,其中d表示深度.如果解决一个给定状态的步骤是18,那么在解决方案的层级上就含有262,144个节点.
8迷宫游戏状态和表示含有9个方块的列表差不多.作为例子,这儿有两个状态.最后一个是目标态,达到这种状态,我们便发现了解决方案.第一个是可能的起始状态.
起始状态: SPACE, A, C, H, B, D, G, F, E
目标状态: A, B, C, H, SPACE, D, G, F, E
这是迷宫问题问题的规则:如果对于给定的滑块,其上方,下方,左方或者右方有一个间隙,你便可以移动这个滑块到此间隙.
为了解决迷宫问题,你需要找到一个路径,由起始态,穿越图,到目标态.
有一个样例代码用于解决8迷宫问题,代码放在GitHub上(链接已经失效,我就取消了链接).
路径发现
在视频游戏或者其他路径发现场景中,你想要在没有碰撞或者不走太远的情况下,找到一个状态空间以及找出如何到达你想到达的地方.A*算法将不仅找到一条路径,而且如果确实存在这样一条路径,它将会找到一条最短的路径.路径发现中的一个状态仅仅是所处世界中的一个位置.在类如吃豆人这样的的迷宫问题中,你可以使用一个二维的网格来表示所有的东西.起始态是一个2维坐标系,其中魔鬼所处的位置就是搜索的起始点.目标态是我们可以去吃掉豆形人.这是一个实现路径搜索的样例代码(链接已经失效). 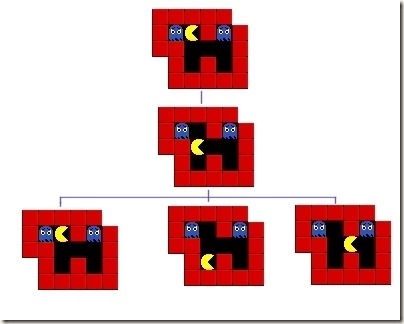
图2:路径分析状态空间的前三个步骤
A*算法的实现(Implementing A*)
我们现在开始看一看A*算法的操作.我们需要做的是从目标态开始,然后向下产生图.看一下图1中的8迷宫问题.从起始态我们可以有多少种移动的方法数?答案是2.因为我们有两个方向来移动空白块,因此我们可以展开图.如果我们仅仅是盲目的产生每一个节点的所有后续节点,我们可能在找到目标节点以前就已经耗尽了计算机的内存.很明显,我们需要记忆最好的节点,然后搜索这些节点.除此之外,我们也应该知道,我们仅需要记忆已经展开的节点,因为我们不需要重复展开相同的状态.我们首先创建一个OPEN表.在这个表中,我们记下我们没有展开的节点.当算法开始的时候,起始态被放在OPEN表中,它是唯一一个我们知道的状态并且我们还没有展开它.因此,我们将从起始态展开节点然后将这些展开的节点放在OPEN表中.现在我们已经对起始节点做了这样的工作,那么我们需要将其放入到CLOSED表中.CLOSED表中存放我们已经展开的节点列表.
f = g + h
使用OPEN和CLOSED列表让我们对于下一步搜索变得更加有选择.我们首先想要查看最好的节点.我们将会给每一个节点一个绩点,来表示我们认为它的好坏程度.这个绩点应该被考虑成从此节点到目标节点的花费加上到达我们所在节点的花费.按照惯例,这些用字母f,g和h来表示.g是到达此节点的所有花费,h是一个启发函数(评估我们到达目标节点的花费).f是这两个的和.我们为每一个节点存储这些信息. 使用f,g和h的值,A*算法将会按照我们的条件,向目标靠近,最终我们将会发现可能的最短路径.
到目前为止我们已经了解了A*算法的组成元素,接下来让我们看看这些使用这些元素实现这个算法.
A* pseudocode
Create a node containing the goal state node_goal
Create a node containing the start state node_start
Put node_start on the open list
while the OPEN list is not empty
{
Get the node off the open list with the lowest f and call it node_current
if node_current is the same state as node_goal we have found the solution; break from the while loop
Generate each state node_successor that can come after node_current
for each node_successor of node_current
{
Set the cost of node_successor to be the cost of node_current plus the cost to get to node_successor from node_current
find node_successor on the OPEN list
if node_successor is on the OPEN list but the existing one is as good or better then discard this successor and continue
if node_successor is on the CLOSED list but the existing one is as good or better then discard this successor and continue
Remove occurences of node_successor from OPEN and CLOSED
Set the parent of node_successor to node_current
Set h to be the estimated distance to node_goal (Using the heuristic function)
Add node_successor to the OPEN list
}
Add node_current to the CLOSED list
}
下面是一个对应的中文说明:
创建一个包含目标状态的节点node_goal
创建一个包含起始状态的节点node_start
将起始节点放在开放列表(OPEN)中
while OPEN 不为空
{
让含有最小f值的节点从OPEN表出列,称之为node_current
if node_current 和 node_goal 状态相同,则我们已经找到解决方案;从while循环break
取得来自node_current的每一个后继节点node_successor的状态
for node_current的每一个后继节点node_successor
{
设置node_successor的花费=node_current的花费+从node_current到node_successor的花费
在OPEN表中寻找node_successor
if node_successor已经在OPEN表中但已经存在的node_successor和其一样好甚至更好,那么丢弃这个node_successor,然后continue
if node_successor已经在CLOSED表中但是已经存在的node_successor和其一样好甚至更好,那么丢弃这个node_successor,然后continue
从OPEN以及CLOSED中移除发现的node_successor
将node_successor的父节点设置为node_current
将h设置为到目标节点node_goal的估计距离(使用启发函数)
将node_successor添加到OPEN列表中
}
将node_current添加到CLOSED表中
}
希望我们在前一段提到的思想可以在我们看A*算法伪代码的时候有所帮助.为了让这个算法的操作看起来更加的清晰,我们再来看一看图1中的8迷宫问题.下面的图3显示了每一个滑块f,g和h的绩点. 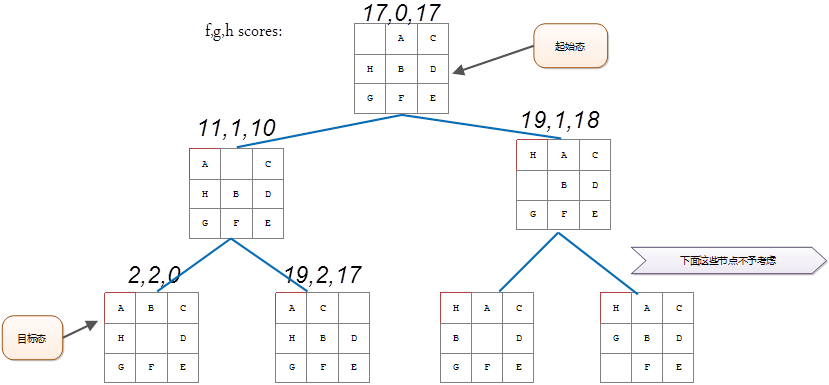
图3:显示了f,g和h绩点的8迷宫问题状态空间(替换了原图,因为原图看上去很模糊)
首先看一看每一个节点的g值.它表示的是从起始节点到当前节点的花费.因此图片中心数字就是g(注:比如17 0 7中的0就表示的是g值).正如你所看到的,这个数字每一级增加1.在某些问题中,状态发生改变,这花费也可能发生变化.比如在寻找路径的问题中,有时候某些类型的地形会比其它地形的花费要高.
@Cmt-Beg
g值表示的是该节点处所有滑块到其正确位置的曼哈顿距离之和.
@Cmt-End
接下来看最后一个数字,也就是h,即启发绩点.正如我在上面说提到的,我使用一个称之为Nilsson’s Sequence的启发函数来计算启发值.这个启发函数在很多情况下可以迅速的覆盖一个正确的解决方案.这里将告诉你对于每一个8迷宫状态如何计算这个绩点:
尼尔森序列绩点(Nilsson's sequence score)
在中心处的滑块绩点为1(它应该是空的).
对于每一个不在中心处的滑块,如果其顺时针处的滑块不应该是处于其顺时针处,那么其绩点为2.将这一系列绩点乘以3并且加上所有的滑块到其正确位置所要移动的距离.
@Cmt-Beg
原文是这样写的:
[@quote]
A tile in the center scores 1 (since it should be empty)
For each tile not in the center, if the tile clockwise to it is not the one that should be clockwise to it then score 2. Multiply this sequence by three and finally add the total distance you need to move each tile back to its correct position.
[@quote]
我表示没有看懂,这话说的到底是什么意思呢?后来我给作者发了邮件,原作者给我了个网址,他说让我看看http://heuristicswiki.wikispaces.com/Nilsson's+Sequence+Score处对此序列的介绍,这个网址是这样介绍的:
h(n) = P(n) + 3S(n)
P(n) is the Manhattan Distance of each tile from its proper position.
S(n) is the sequence score obtained by checking around the non-central squares in turn, allotting 2 for every tile not followed by its proper successor and 1 in case that the center is not empty.
也就是说:h(n) = P(n) + 3 S(n),其中:
P(n) :每一个滑块距离其正确位置的曼哈顿距离之和
S(n) : 通过轮流检查非中心滑块所获得的一个序列绩点.对于每一个其后续节点不是合适的后续节点的节点,分配绩点2,对于其他所有节点则分配绩点0,哦,不过有一个特例,中心节点分配绩点1.
似乎看起来很不错呢,但是,我发誓在我看了之后,我还是没有懂,到底怎么计算Nilsson序列!
这是我手稿纸啊,画了大半天,也没有所以然!
难道是俺英语太次,没有看懂人家的意思吗?后来在StackOverflow上看见一位来自英国的伙计说:

当时我就笑了,嗯,看起来很不错呢!当然下面有回答(英文好的朋友可以看一看: http://stackoverflow.com/questions/10584788/can-anyone-explain-nilssons-sequence-score-in-8-puzzle-more-clearly?answertab=oldest#tab-top),我也是看了这个回答,才算了解了这个让人感觉好..诡..异..的序列.下面说一说怎么算这个序列,我保证用我认为最详细的步骤给你说明白:
首先将网格按下图编号(来个绿色的网格吧,这几天盯着白花花的电脑屏幕眼睛都看得受不了了..),注意网格的编号顺序(这个网格为什么要这么写,估计是精心设计过的...):

我们约定N(x)表示x方块在上图中的编号.
那么Nilsson序列绩点有以下伪代码例程给出:
for each tile x in (A,B,C,...,H) score += distance from N(x) to the correct square for tile x if N(x)== # i.e. the tile is in the center score += * else if N(next(x))!= (N(x)+)% score += *
其中next(x)表示按照顺时针顺序(依据字母顺序:A,B,C..X,Y,Z,A),x下面的值.比如next(A)=B,next(C)=D,next(Z)=A.看上述伪代码需要注意的是,next(x)对x操作后,x还是原来的x,可能有人会认为next(x)操作x之后,x就是next(x)了..比如我,这样是不对的,希望你可以避免这个坑!这样的话,上述伪代码很清楚的告诉我们Nilsson序列是如何得到,大白话如下:
对于每一个节点(注意在这里,一个节点代表了世界所处的一种状态,而这种状态在这儿是一个3x3的表格!),计算每一个的滑块到其正确位置(目标状态时此滑块应处于的位置)所应该移动的距离(准确的说应该是曼哈顿距离),然后将所有滑块所得到的曼哈顿距离加到一块儿,这得到的是h(n)=p(n)+3*s(n)中的p(n).
然后是计算s(n).我们还是需要处理节点中的所有滑块,为了简单起见,我们按顺序来(A->B->..->H),如果这个滑块为中心滑块(也就是编号为8),那么得到一个序列绩点1,如果这个滑块为非中心滑块,那么,若其下一个滑块为恰当的滑块(比如,A的下一个滑块为B,C的下一个滑块为D,H的下一个滑块为A,那么这些滑块都是恰当的,还不懂,没事儿,一会儿我会举例子说明),则该滑块得到一个序列绩点2.当遍历完所有的滑块后,将序列绩点相加便得到了s(n).
得到s(n)和p(n)后,我们将很容易计算得到h(n).
下面举几个例子来说明:

先按照伪代码来说明:
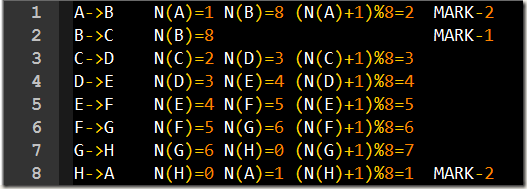
因此s(n)=2+1+2=5,而p(n)的计算是颇为简单的,因为C,D,E,F,G都在其正确的位置(我们有时也含蓄的称之为适当的位置^-^),所以需要移动的距离均为零,只需要看一看A,B,H就可以了,显然各自均要移动一个曼哈顿距离(什么是曼哈顿距离,哈!自己查查..),所以p(n)=3.so,The value of h(n) is 18 which is from 3+3*(2+1+2).
而直观一点来看的话就是..,看下图:
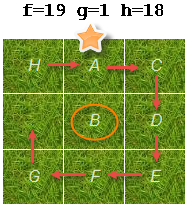
我们从A开始,A顺时针应该接的是B,可是我们遇到的却是C,所以A得到一个序列绩点2,紧接着是C,C顺时针指向的应该是D,正好符合.所以C得到0,同样的,我们可以得到D,E,F,G均得到0.在G处,G下面没有了,显然不合,所以得到序列绩点2,然后从H开始,H顺时针指向A,符合条件.因此H得到绩点为0.B为中心滑块,绩点为1. 所以S(n)=2+2+1=5.p(n)是同样的算法.我想现在你已经理解了那句话(if the tile clockwise to it is not the one that should be clockwise to it then score 2).
然后再来看一个:

依旧从A开始顺时针来计算,显然A->C使A得到序列绩点2,H->nul使H得到绩点2,B为中心滑块,所以B得到绩点1.所以s(n)=2+2+1=5.p(n)=2,很好算,我就不说了.因此h=15+2=17.到此,你肯定会说,Nilsson序列这么简单,哇..当初感觉自己都要freaking out(崩溃)啦!
@Cmt-End
读源代码或许会让这个计算方法更加清晰明了.看一看图片,你应该感到满足,因为根据这个算法,所有的h绩点都是正确的.
最后看最左边的数字,也就是f绩点.它是f和h的和,在A*算法完成其搜索的过程中,它所完成的正是通过状态空间来追踪最小的f值.
看一看教程所提供的源代码,虽然到目前为止,算法的原理可能在你头脑中已经很清晰,但是实现或许还是有些复杂的.在此处,我将使用我的源代码,源代码用C++编写,使用了标准库以及STL数据结构.
C++实现细节(C++ implementation details)
我们可以看到A*算法包含在一个头文件中,以你为它被实现为模板类.你只需要编译例子中的文件8puzzle.cpp以及findpath.cpp即可.
源文件中有一些注释,我希望这些注释是清晰的且易于理解的.接下来是关于这些文件如何工作的概要以及基本设计思想.
主类叫做AstarSearch,是一个模板类.我之所以选择模板是因为这可以让用户高效的使用AstarSearch.(...省略一堆没有的)...
你可以传入一个代表问题状态的数据类型.这个类型必须包含有数据,这些数据代表了每一种状态.另外在搜索过程中也有几个成员函数供调用.描述如下:
float GoalDistanceEstimate( PuzzleState &nodeGoal );
返回此节点到目标节点的估计花费值.
bool IsGoal( PuzzleState &nodeGoal );
如果此节点为目标节点则返回true
void GetSuccessors( AStarSearch *astarsearch );
对于此状态下的每一个后继者,调用AstarSearch的AddSuccessor方法增加一个节点到当前的搜索
float GetCost( PuzzleState *successor );
返回从此状态到后继状态的花费值.
bool IsSameState( PuzzleState &rhs );
如果所传入的状态和此状态相同则返回true.你应该可以很容易的实现一个不同的问题.你所需要做的只是创建一个类,该类表示你的问题中的一个状态.然后自己完成上面的函数.一旦你创建了一个搜索类,比如:AStarSearch astarsearch;
然后创建一个起始以及目标状态,然后将它们传到算法中以初始化搜索:
astarsearch.SetStartAndGoalStates( nodeStart, nodeEnd );
每一步(一步所完成的是获取最优节点以及展开其后续节点)你调用
SearchState = astarsearch.SearchStep();
返回一个状态,可以让你知道搜索是否成功,失败或者仍在进行.一旦搜索成功,你需要将其显示给用户,或者在你的程序中进行使用.因此我添加了几个函数:
UserState *GetSolutionStart();
UserState *GetSolutionNext()
UserState *GetSolutionEnd();
UserState *GetSolutionPrev()
你可以使用它们来在一个解决方案中移动一个内部迭代器.最典型的使用是GetSolutionStart (the start state)以及使用GetSolutionNext迭代每一个节点.对于调试以及一些需要后向迭代的问题,你可以使用后两个函数.
Debugging and Educational functions
如果你打算显示每一个步骤中的OPEN以及CLOSED表.这是一个普通的调试功能,可以让你的算法运作起来.进一步来说,对于学生而言,从这一种方式更加容易理解.在搜索例程中使用下面的函数来袭那是列表:
UserState *GetOpenListStart( float &f, float &g, float &h );
UserState *GetOpenListNext( float &f, float &g, float &h );
UserState *GetClosedListStart( float &f, float &g, float &h );
UserState *GetClosedListNext( float &f, float &g, float &h );
你可以看到这些调用是对f,g以及h的引用,因此如果你在调试或者学习过程中需要看这些变量的值的话,你可以传入浮点变量来存储这些值.这些值都是可选参数,你可以不用在意它们.
如果使用这些功能,你可以通过findpath.cpp以及8puzzle.cpp例子来了解.
我希望到此处你已经理解了关键概念,通过阅读以及亲自体验样例中的代码(在一个调试器中单步执行是非常直观的),你完全有希望领悟A*算法.为了完成这篇教程,我将简短的提一下可容忍性以及优化问题(Admissibility and Optimization issues).
Admissibility(可容忍性)
任何关于图的搜索算法,如果它总是可以返回一个优化解(也就是说,如果解决方案存在,返回的为最低花费),那么就说它是可以容忍的.然而,A*仅仅决定于你所用到的启发式函数h,当h没有过度评估到目标处的距离时,A*算法才是可容忍的.换句话说,如果你知道一个启发式函数,它总是返回到目标距离的精确值,那么如果h’是看容忍的,那么h’必须小于或者等于h.
考虑到这个因素,你应该总是确保选择的启发式函数没有过度评估到目的点的距离.实际上,有时候,这是不可能的.以8迷宫问题为例,我们上面的启发式函数可能得到到目标点的距离大于实际情况.但是它有益于你更加深刻的认识这个理论.如果你让启发式函数返回零,那么你一定不会得到一个到目标的过度估计值,这种情况下,你搜索了每一步中所产生的所有节点(深度优先搜索).
关于可容忍性最后要说的一点是:对于A*理论还有一个推理,叫做Graceful Decay of Admissibility(容忍性许可衰减?不好翻译..),这个推论告诉我们,如果你的启发式函数获得的评估距离超过真实距离(到目标点处)的大小不超过某一个值(我们称之为E),那么这个算法将基本上不会找到一个解决方案使超过最优解的花费超过E.
Optimization(优化)
对于A*算法较好的优化可以在Steve Rabin的Game Gems书中找到,另一本是AI Wisdom.这些书中聚焦于路径发现(在游戏中广泛使用).
路径发现优化本身就是一个完整的学科,我仅仅是想实现A*算法以供一般性的使用,但是很明显有很多地方你可以在你的问题中进行优化.在使用Vtune(Intel的性能分析工具)对我的样例代码进行测试后,我发现有两个主要的瓶颈,第一个是对新节点OPEN和CLOSED列表的搜索,第二个是管理新节点.一个简单但是有效的优化方案是写一个比C++ 标准的new更加简单的内存分配器.我已经为这个类提供了这样的代码,你可以在stlastar.h中使用.如果我对此有足够的兴趣的话,我可能会对其写一个教程.
由于在每一次搜索循环中你总是希望从OPEN列表中获得具有最小f绩点的节点,因此你可以使用一个叫做优先队列的数据结构(priority queue).这可以让你很好的管理你的数据,因为你可以总是让你最好的(也或者是最坏的一些,取决于你如何设置)一项有效的被移除.Steve Rabin的书中(上面提到的那本)给我展示了如何使用STL Vector以及堆操作来实现这个行为.我的源代码也使用了这个技术.如果你对优先队列感兴趣,你可以使用这个源代码.我基于优先队列使用C实现了堆以及链表.代码已经很成熟了,已经在项目FreeCell Solver中使用.
另一个优化是你应该使用一个hash表而不是搜索列表.这会防止你使用一个线性搜索.第三个优化是,你不需要在一个图搜索问题中进行回溯.比如,你可以看一下路径发现,如果你回溯到你的起始处,你绝不会距离目标点更近.因此,当你写代码来产生一个节点的后续节点时,你可以检查已经产生的节点并且评估任何和父节点一样的状态.虽然这和算法的操作没什么区别,但是它确实使回溯加快.
文章灵感来源于:http://www.gamasutra.com/features/19990212/sm_01.htm
文章基本上到此算是说完了,接下来如果有时间我会对作者的源代码进行剖析,进一步说明A*算法.
英文水平有限,如果有翻译的不当或者理解有误,还请您向我提出,或留言,或给我发邮件chinamyth1@gmail.com.谢谢!
A*算法–A* algorithm tutorial的更多相关文章
- 普林斯顿大学算法课 Algorithm Part I Week 3 排序算法复杂度 Sorting Complexity
计算复杂度(Computational complexity):用于研究解决特定问题X的算法效率的框架 计算模型(Model of computation):可允许的操作(Allowable oper ...
- c/c++ 通用的(泛型)算法 generic algorithm 总览
通用的(泛型)算法 generic algorithm 总览 特性: 1,标准库的顺序容器定义了很少的操作,比如添加,删除等. 2,问题:其实还有很多操作,比如排序,查找特定的元素,替换或删除一个特定 ...
- OpenCV 学习笔记03 凸包convexHull、道格拉斯-普克算法Douglas-Peucker algorithm、approxPloyDP 函数
凸形状内部的任意两点的连线都应该在形状里面. 1 道格拉斯-普克算法 Douglas-Peucker algorithm 这个算法在其他文章中讲述的非常详细,此处就详细撰述. 下图是引用维基百科的.ε ...
- 反向传播算法 Backpropagation Algorithm
假设我们有一个固定样本集,它包含 个样例.我们可以用批量梯度下降法来求解神经网络.具体来讲,对于单个样例(x,y),其代价函数为:这是一个(二分之一的)方差代价函数.给定一个包含 个样例的数据集,我们 ...
- 疯子的算法总结(二) STL Ⅰ 算法 ( algorithm )
写在前面: 为了能够使后续的代码具有高效简洁的特点,在这里讲一下STL,就不用自己写堆,写队列,但是做为ACMer不用学的很全面,我认为够用就好,我只写我用的比较多的. 什么是STL(STl内容): ...
- 数据结构与算法---排序算法(Sort Algorithm)
排序算法的介绍 排序也称排序算法 (Sort Algorithm),排序是将一组数据,依指定的顺序进行排列的过程. 排序的分类 1) 内部排序: 指将需要处理的所有数据都加载 到内部存储器(内存)中进 ...
- HMM——维特比算法(Viterbi algorithm)
1. 前言维特比算法针对HMM第三个问题,即解码或者预测问题,寻找最可能的隐藏状态序列: 对于一个特殊的隐马尔可夫模型(HMM)及一个相应的观察序列,找到生成此序列最可能的隐藏状态序列. 也就是说给定 ...
- 机器学习算法-K-NN的学习 /ML 算法 (K-NEAREST NEIGHBORS ALGORITHM TUTORIAL)
1为什么我们需要KNN 现在为止,我们都知道机器学习模型可以做出预测通过学习以往可以获得的数据. 因为KNN基于特征相似性,所以我们可以使用KNN分类器做分类. 2KNN是什么? KNN K-近邻,是 ...
- 数据挖掘算法-Apriori Algorithm(关联规则)
http://www.cnblogs.com/jingwhale/p/4618351.html Apriori algorithm是关联规则里一项基本算法.是由Rakesh Agrawal和Ramak ...
随机推荐
- Kosaraju算法、Tarjan算法分析及证明--强连通分量的线性算法
一.背景介绍 强连通分量是有向图中的一个子图,在该子图中,所有的节点都可以沿着某条路径访问其他节点.强连通性是一种非常重要的等价抽象,因为它满足 自反性:顶点V和它本身是强连通的 对称性:如果顶点V和 ...
- 1.0.0 Unity零基础入门——打砖块
1)设置好相应场景 2)创建脚本挂载到相应物体上并编写 2.代码 //Shoot - - 控制小球生成与射击 using System.Collections; using System.Collec ...
- 4星|《流量池》:Luckin Coffee营销操盘手经验谈
流量池:“急功近利”的流量布局.营销转化 作者是一线营销操盘手,全书是作者的经验总结,这样的作者在营销类图书中比较罕见,因此这本书非常有价值. 全书是写给巨头之外的企业营销人员看的,这样的企业的流量来 ...
- linux一切皆文件之tcp socket描述符(三)
一.知识准备 1.在linux中,一切皆为文件,所有不同种类的类型都被抽象成文件(比如:块设备,socket套接字,pipe队列) 2.操作这些不同的类型就像操作文件一样,比如增删改查等 二.环境准备 ...
- 小学生都能写智能语音助手了,我这颗转战AI的心要何去何从?
前言——我是不是老了 前天看了一个关于AI类的综艺节目我感觉整个人都不好了.这个综艺的名字叫<智造将来>上面那个小屁孩自己写了一个智能语音助手,这个小屁孩叫袁翊闳是2018年百度AI开发者 ...
- mysql select 字段别名是否可以用在 select中或者where中
select column1+10 as c1,c1+10 as c2 from table1;想实现上面的效果,结果在mysql里面报错了,提示找不到c1这个列; -- 不同的 数据库不一样 一般不 ...
- 《Linux内核设计与实现》读书笔记——第一、 二章
<Linux内核设计与实现>读书笔记--第一. 二章 标签(空格分隔): 20135321余佳源 第一章 Linux内核简介 1.Unix内核特点 十分简洁:仅提供几百个系统调用并且有明确 ...
- Daily Scrum 11.1
今天放假一天,明天又是新的一周,预计开始Alpha版本所有功能的整合和优化,争取在两天内完成各种功能的整合. Member Task on 11.1 Task on 11.2 仇栋民 放假一天 开始T ...
- vs2013的安装与使用 测试
vs2013软件我去年已经用过,可是当时只是鉴于对于c语言的编程,并没有觉得好用,况且好多的功能自并没有去深入研究,所以当时对于这个软件还是排斥的.安装的时候是别人帮我装的,所以并没有在安装的过程有问 ...
- 微信小程序对接串口摄像头
串口摄像头由树莓派控制,代码如下: # _*_ coding:utf-8 import serial import time import traceback import pycurl import ...