显卡、显卡驱动、CUDA、cuDNN之间的关系
作者:冬瓜哥
链接:https://www.zhihu.com/question/59184480/answer/166167659
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
显卡/GPU是具体干活的芯片,其从host端拿命令和数据。显卡驱动,分内核态和用户态两部分。内核态驱动只管将用户态驱动发过来的命令和数据准备好,通知GPU来拿,利用环形fifo来下发命令和数据指针,并追踪命令的完成状态。用户态部分,负责对shader程序的编译,编译成GPU的二进制代码指令。OS提供的D3D,OpenGL等函数库,屏蔽底层不同显卡的差异。上层程序比如游戏,在准备好对应的模型、贴图纹理、着色器程序等数据之后,调用统一的D3D/OpenGL接口发起绘制请求,D3D则调用显卡用户态驱动提供的回调函数将对应的数据传递给后者,后者进行运行时编译生成底层代码,然后传递给内核态驱动,内核态驱动将命令和数据发送给GPU。至于GPU怎么算的,那就是完全另外一回事了。
那么,GUDA又是什么呢。CUDA就是通用计算,游戏让GPU算的是一堆像素的颜色,而GPU完全可以算其他任何运算,比如大数据量矩阵乘法等。同样,程序准备好对应的数组,以及让GPU如何算这些数组的描述结构(比如让GPU内部开多少个线程来算,怎么算,之类),这些数据和描述,都要调用CUDA库提供的函数来传递给CUDA,CUDA再调用显卡用户态驱动对CUDA程序进行编译,后者再调用内核态驱动将命令以及编译好的程序数据传送给GPU,算。CUDA,就是相当于一个专门与通用程序而不是图形程序对接的库,那么它的角色和地位与D3D/OpenGL在系统架构层次中是齐平的。
cudnn,是针对深度卷积神经网络的加速库
资料一:https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#thread-hierarchy
先来讲讲CPU和GPU的关系和差别吧。截图来自资料1(CUDA的官方文档):
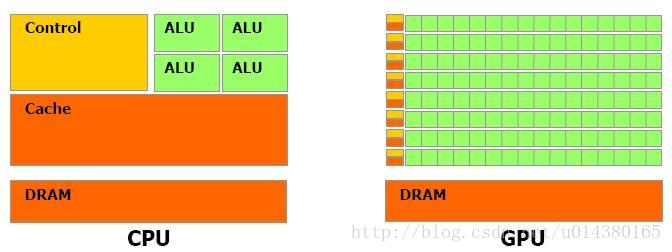
从上图可以看出GPU(图像处理器,Graphics Processing Unit)和CPU(中央处理器,Central Processing Unit)在设计上的主要差异在于GPU有更多的运算单元(如图中绿色的ALU),而Control和Cache单元不如CPU多,这是因为GPU在进行并行计算的时候每个运算单元都是执行相同的程序,而不需要太多的控制。Cache单元是用来做数据缓存的,CPU可以通过Cache来减少存取主内存的次数,也就是减少内存延迟(memory latency)。GPU中Cache很小或者没有,因为GPU可以通过并行计算的方式来减少内存延迟。因此CPU的Cahce设计主要是实现低延迟,Control主要是通用性,复杂的逻辑控制单元可以保证CPU高效分发任务和指令。所以CPU擅长逻辑控制,是串行计算,而GPU擅长高强度计算,是并行计算。打个比方,GPU就像成千上万的苦力,每个人干的都是类似的苦力活,相互之间没有依赖,都是独立的,简单的人多力量大;CPU就像包工头,虽然也能干苦力的活,但是人少,所以一般负责任务分配,人员调度等工作。
可以看出GPU加速是通过大量线程并行实现的,因此对于不能高度并行化的工作而言,GPU就没什么效果了。而CPU则是串行操作,需要很强的通用性,主要起到统管和分配任务的作用。
————————————————————————-华丽的分割线——————————————————————-
CUDA的官方文档(参考资料1)是这么介绍CUDA的:a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU.
换句话说CUDA是NVIDIA推出的用于自家GPU的并行计算框架,也就是说CUDA只能在NVIDIA的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥CUDA的作用。
接下来这段话摘抄自资料2。在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
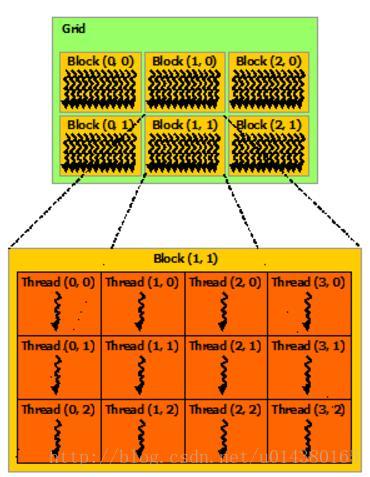
接下来这段话摘抄自资料2。在 CUDA 架构下,显示芯片执行时的最小单位是thread。数个 thread 可以组成一个block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成grid。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
————————————————————————-华丽的分割线——————————————————————-
cuDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
---------------------
作者:AI之路
来源:CSDN
原文:https://blog.csdn.net/u014380165/article/details/77340765
版权声明:本文为博主原创文章,转载请附上博文链接!
显卡、显卡驱动、CUDA、cuDNN之间的关系的更多相关文章
- # Ubuntu16.04安装nvidia驱动+CUDA+cuDNN
Ubuntu16.04安装nvidia驱动+CUDA+cuDNN 准备工作 1.查看GPU是否支持CUDA lspci | grep -i nvidia 2.查看Linux版本 uname -m &a ...
- Ubuntu系统---“NVIDIA 驱动+CUDA+cuDNN ”之后 OpenCV安装
Ubuntu系统---“NVIDIA 驱动+CUDA+cuDNN ”之后 OpenCV安装 目录: 一.OpenCV安装包下载 二.cmake安装 三.OpenCV安装 正文 一.OpenCV安装包下 ...
- ubuntu18.40 rtx2080ti安装显卡驱动/cuda/cudnn/tensorflow-gpu
电脑环境 ubuntu 18.40 gpu rtx2080ti 一.安装显卡驱动 刚开始尝试用手动安装方式安装驱动 下载了驱动程序但是因为没有gcc所以放弃这种方法 后尝试最简单的方式 在 菜单-- ...
- Ubuntu 下安装Anaconda + 显卡驱动 + CUDA + CUDNN + 离线安装环境
写来给自己备忘,并不是什么教程- .- 下载安装包 Anaconda:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 显卡驱动:https ...
- CPU、OpenGL/DirectorX、显卡驱动和GPU之间的关系
- 容器内安装nvidia,cuda,cudnn
/var/lib/docker/overlay2 占用很大,清理Docker占用的磁盘空间,迁移 /var/lib/docker 目录 du -hs /var/lib/docker/ 命令查看磁盘使用 ...
- ubuntu 16.04安装nVidia显卡驱动和cuda/cudnn踩坑过程
安装深度学习框架需要使用cuda/cudnn(GPU)来加速计算,而安装cuda/cudnn,首先需要安装nvidia的显卡驱动. 我在安装的整个过程中碰到了驱动冲突,循环登录两个问题,以至于最后不得 ...
- ubuntu显卡(NVIDIA)驱动以及对应版本cuda&cudnn安装
(已禁用集显,禁用方法可自行百度) 驱动在线安装方式进入tty文本模式ctrl+alt+F1关闭显示服务sudo service lightdm stop卸载原有驱动sudo apt-get remo ...
- 艰辛五天:Ubuntu14.04+显卡驱动+cuda+Theano环境安装过程
题记:从一开始不知道显卡就是GPU(虽然是学计算机的,但是我真的不知道…脑残如我也是醉了),到搞好所有这些环境前后弄了5天时间,前面的买显卡.装显卡和装双系统见另一篇博客装显卡.双系统,这篇主要记录我 ...
随机推荐
- 【AtCoder】ARC084
C - Snuke Festival 对于每个B二分求出几个A比它小记为sum 然后对于每个C就是比它小的B的sum的和 #include <bits/stdc++.h> #define ...
- Linux常用包的安装
下面列出的这些包都有很强大的功能,也是非常实用常用的工具 gcc yum -y install gcc GNU编译器套件(GNU Compiler Collection) gcc-c++ yum -y ...
- 循序渐进学.Net Core Web Api开发系列【1】:开发环境
系列目录 循序渐进学.Net Core Web Api开发系列目录 本系列涉及到的源码下载地址:https://github.com/seabluescn/Blog_WebApi 一.本篇概述 本篇不 ...
- 火狐浏览器接口测试工具Poster
- 【HDU 3590】 PP and QQ (博弈-Anti-SG游戏,SJ定理,树上删边游戏)
PP and QQ Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- codevs 2821 天使之城
题目描述 Description 天使城有一个火车站,每辆火车都从A方向驶入车站,再从B方向驶出车站. 为了调度火车,火车站设有停放轨道,可存放5辆火车.已知从A进入车站顺序为1.2.3…….现在给你 ...
- MySQL Replication(Master与Slave基本原理及配置)
MySQL Replication(Master与Slave基本原理及配置) 1. 主从mysql server的工作原理:(如图及其过程分析) 过程: Mysql的复制(replication ...
- LPC43xx SGPIO Slice 示意图
SGPIO inverted clock qualifier Hi, With bits 6:5 of SGPIO_MUX_CFG the QUALIFIER_MODE is selected (0x ...
- STM32 System and Timer Clock Configurations
STM32 System and Timer Clock Configurations I've started writing some software to drive a series of ...
- ThinkPHP 模型方法 getField() 和 select() 使用技巧
getField() 使用技巧 getField() 方法是 ThinkPHP 中用来获取字段值的方法,区别于 select() 和 find() 方法,通常仅用于获取个别字段的值.但是事实上并没有那 ...