[Spark Streaming_1] Spark Streaming 概述
0. 说明
Spark Streaming 介绍 && 在 IDEA 中编写 Spark Streaming 程序
1. Spark Streaming 介绍
Spark Streaming 是 Spark Core API 的扩展,针对实时数据流计算,具有可伸缩性、高吞吐量、自动容错机制的特点。
数据源可以来自于多种方式,例如 Kafka、Flume 等等。
使用类似于 RDD 的高级算子进行复杂计算,像 map 、reduce 、join 和 window 等等。
最后,处理的数据推送到数据库、文件系统或者仪表盘等。也可以对流计算应用机器学习和图计算。

在内部,Spark Streaming 接收实时数据流,然后切割成一个个批次,然后通过 Spark 引擎生成 result 的数据流。
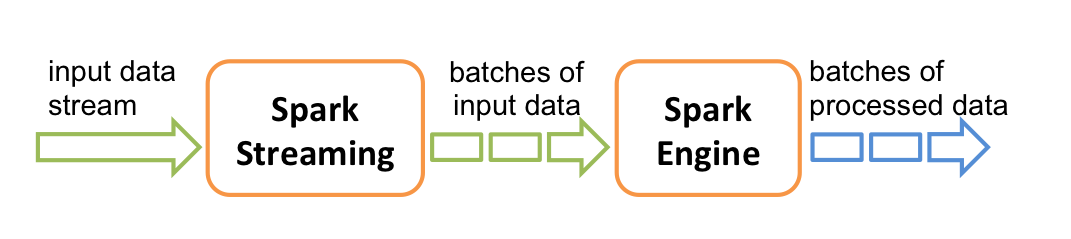
Spark Streaming 提供了称为离散流(DStream-discretized stream)的高级抽象,代表了连续的数据流。离散流通过 Kafka、 Flume 等源创建,也可以通过高级操作像 map、filter 等变换得到,类似于 RDD 的行为。内部,离散流表现为连续的 RDD。
2. 在 IDEA 中编写 Spark Streaming 程序(Scala)
【2.1 添加依赖】
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.share</groupId>
<artifactId>myspark</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<spark.version>2.1.</spark.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies> </project>
【2.2 编写代码】
package com.share.sparkstreaming.scala import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext} /**
* Spark Streaming 的 Scala 版 Word Count 程序
*/
object SparkStreamingScala1 {
def main(args: Array[String]): Unit = { val conf = new SparkConf()
conf.setAppName("Streaming")
// 至少2 以上
conf.setMaster("local[2]") // 创建 Spark Streaming Context ,间隔 1 s
val sc = new StreamingContext(conf , Seconds(1)) // 对接 socket 文本流
val lines = sc.socketTextStream("s101", 8888)
val words = lines.flatMap(_.split(" "))
val pair = words.map((_,1))
val rdd = pair.reduceByKey(_+_) // 打印结果
rdd.print() // 启动上下文
sc.start() // 等待停止
sc.awaitTermination()
}
}
【2.3 修改 Log4j 日志输出级别】

【2.4 启动服务器 s101 的 nc】
nc -lk
【2.5 运行程序并验证】
略
3. 在 IDEA 中编写 Spark Streaming 程序(Java)
package com.share.sparkstreaming.java; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator; /**
* Spark Streaming 的 Scala 版 Word Count 程序
*/
public class WordCountStreamingJava1 {
public static void main(String[] args) throws InterruptedException {
SparkConf conf = new SparkConf();
conf.setAppName("Streaming");
conf.setMaster("local[*]"); // 创建 Spark Streaming Context ,间隔 2 s
JavaStreamingContext sc = new JavaStreamingContext(conf, Durations.seconds(2));
// 对接 socket 文本流
JavaDStream<String> ds1 = sc.socketTextStream("s101", 8888); // 压扁
JavaDStream<String> ds2 = ds1.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String s) {
return Arrays.asList(s.split(" ")).iterator();
}
});
// 变换成对
JavaPairDStream<String, Integer> ds3 = ds2.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
// 聚合
JavaPairDStream<String, Integer> ds4 = ds3.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}); // 打印结果
ds4.print();
// 启动上下文
sc.start();
// 等待停止
sc.awaitTermination();
}
}
[Spark Streaming_1] Spark Streaming 概述的更多相关文章
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- Spark机器学习 Day1 机器学习概述
Spark机器学习 Day1 机器学习概述 今天主要讨论个问题:Spark机器学习的本质是什么,其内部构成到底是什么. 简单来说,机器学习是数据+算法. 数据 在Spark中做机器学习,肯定有数据来源 ...
- Real Time Credit Card Fraud Detection with Apache Spark and Event Streaming
https://mapr.com/blog/real-time-credit-card-fraud-detection-apache-spark-and-event-streaming/ Editor ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- spark教程(16)-Streaming 之 DStream 详解
DStream 其实是 RDD 的序列,它的语法与 RDD 类似,分为 transformation(转换) 和 output(输出) 两种操作: DStream 的转换操作分为 无状态转换 和 有状 ...
- WARN deploy.SparkSubmit$$anon$2: Failed to load org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount.
前言 今天运行Spark Structured Streaming官网的如下 ./bin/run-example org.apache.spark.examples.sql.streaming.Str ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
随机推荐
- JavaScrip t对象和 JSON 数据格式转换
<script> //定义一个js对象 var person = { firstName: "John", lastName: "Doe", age ...
- mysql cmd 启动服务
1.确定你的mysql 是否能正常工作登录数据库cmd--“命令提示字符”窗口录入,录入cd C:\mysql\bin 并按下回车键,将目录切换为 cd C:\mysql\bin再键入命令mysql ...
- 局域网使用visual studio配合iis调试手机app
描述:开发一款手机应用程序,服务器配置在iis,当局域网中即只有路由器无外网如何设置实时调试手机应用程序? vs配合iis调试程序的两种方式? 使用vs的debug(f5)调试网站比较常见,然而当网站 ...
- tcp/ip通信中tcp头部结构tcphdrp->check校验计算
通过raw socket修改通信数据后,可通过函数 set_tcp_checksum1(iph); 重新校验计算iph->check值 在http://www.cnblogs.com/dpf-1 ...
- [转]【mysql监控】查看mysql库大小,表大小,索引大小
本文转自:http://blog.sina.com.cn/s/blog_4c197d420101fbl9.html 查看所有库的大小 mysql> use information_schema; ...
- SQL - 先安装SQL2008 R2后安装AD导致无法正常登陆数据库(无法启动MSSQLSERVER)
分析原因:安装AD后,系统改为使用域用户登陆,原先安装SQL时设置的“本地用户”信息已经修改,当前(域)用户没有权限访问MSSQLSERVER实例文件夹或整个SQL文件夹. 解决方法: 1.打开“服务 ...
- chomd文件权限授予
drwxr -x r- x 什么意思| | | | | | | | | | 12345678910 第一位表示文件类型.d是目录文件,l是链接文件,-是普通文件,p是管道第2-4位表示这个文件的属主拥 ...
- Asp.Net里关于Session过期跳转页面的一些小技巧
这里算是自己的个人随笔吧,仅供参考使用,后续有更好的方法再做补充 之前在Aspx页面里面,在Session过期的时候我经常会使用 Server.Transfer("b.aspx") ...
- Mybatis插件开发
前面几篇文章介绍了Mybtis中四个重要的对象,其中提到它们都是在Configuration中被创建的,我们一起看一下创建四大对象的方法,代码如下所示: public ParameterHandler ...
- Windows平台如何部署scrapy
0.安装Anaconda 这个不教了,自己去Anaconda官网上下个安装包,装上就好. https://www.anaconda.com/distribution/ 1.使用Anaconda创建一个 ...