day15模块内容
1.生成器表达式
先说三元表达式如下
res = [i for i in range(10) if 1 > 5]
这样res就是一个列表6,7,8,9]
只要在这个基础上稍加调整,如下
方括号改成圆括号
res = (i for i in range(10) if 1 > 5)
这样res就是一个生成器了
print(res)
使用next(g)就可以输出这个生成器的下一个值
到最后没有值了,就会爆出异常,StopIteraiton
接下来尝试做一件事,计算一个文件拥有的所有字符数
with open(a.txt,encoding = 'utf8') as f:
print(len(f.read())) # 这会有一个问题,就是一次把文件都读进内存了,如果文件内容很大的话,内存会不够用,系统会卡
所以就有了另一种方法:一行一行的读取进内存中,计算字符数,再将每行的字符相加
for line in f:
g = len(line) for line in f
res = sum(g)
写成一行就是如下
res = sum(len(line) for line in f)
print(res)
2.模块
2.1什么是模块
模块就是一堆功能的集合体
模块分为四个通用的类别:
1.使用python编写的.py文件(*****)
2.已被编译为共享库或DLL的C或C++扩展
3.把一系列模块组织到一起的文件夹(注意:文件夹下有一个__init__.py文件,该文件夹称之为包)(*****)
4.使用c编写并链接到python解释器的内置模块
三种来源
1.内置模块
2.第三方模块
3.自定义模块
2.2为什么用模块
1.使用内置的或者第三方的模块的好处是:拿来主义,极大提升开发效率
2.使用自定义的模块的好处是:将程序各部分组件共用的功能提取取出放到一个模块里,其他组件通过导入的方式使用该模块,该模块即自定义的模块,好处是可以减少代码冗余
3.如何用模块
3.1 import的用法
spam.py文件内容如下:
money=1000
l=[] def read1():
print('spam模块:',money) def read2():
print('spam模块')
read1() def read3():
l.append('xxxxxxxxx') def change():
global money
money=0
run.py文件内容如下:
money = 10
import spam
首次导入模块会发生三件事
1.会产生一个模块的名称空间
2.执行spam.py文件的内容,将产生的名字丢到模块的名称空间里
3.在当前执行文件中拿到一个名字spam,该名字指向模块的名称空间
之后的导入直接引用首次导入的成果
import spam
import spam
import spam
import spam # 后续再导入,不会再执行,而是直接调用内存中已经读取的模块内容
print(money) #打印run.py文件中定义的money,为10
print(spam.money) # 10
print(spam.money) # 1000
print(spam.read1())
print(spam.read2())
print(spam.change) # 上面三行都是spam中定义的函数
spam.read1()
def read1():
print('from run1.py read1')
spam.read2() # read2(中)调用的read1()还是spam中的函数,不是在run中定义的read1()
也就是说模块的名称空间和函数的名称空间一样,是按照定义时的来的
spam.change() # 函数改的是spam中的money,不是run中的money
print(money) # 所以直接打印money,还是10未改动
补充:
import可以用别名,如果要调用的模块吗太长,后续使用不方便,可以在导入阶段用as,起一个别名,后续用这个别名来调用其中的功能,也是一样的
import spam as sm
print(sm.money)
另外可以一行导入多个模块,不过最好不要这么用,还是一行导一个
import os,sys,spam
3.2 from ... import
from spam import money,read1,read2,change
首次导入模块会发生三件事
1.会产生一个模块的名称空间
2.执行spam.py文件的内容,将产生的名字丢到模块的名称空间里
3.在当前执行文件中拿到名字read1,该名字指向模块的名称空间中的read1
money = 10
print(money)
因为money被修改了,所以直接变了
print(read1) # spam中的函数read1
print(read2)
print(read3) # 都是spam中的函数
def read1():
print('from read1')
money = 11111
read1() # 调用时函数向上查找,找的是最近的一次定义,也就是在run中的定义,而不是去调用spam里的
read2() # 读取的spam中的money,没有改变
change()
print(money) #打印run中的money,被改变了
import总结
优点:指名道姓地问某一个名称空间要名字,不会与当前执行文件名称空间中的名字冲突
缺点:引用模块中的名字必须加前缀(模块名.),使用不够简洁
from import 总结
优点:引用模块中的名字不用加前缀(模块名.),使用更为简洁
缺点:容易与当前执行文件名称空间中的名字冲突
from spam import money as m 一样可以用别名
print(m)
from spam import * # 可以用星号把模块中所有名称加载进内存,但是会不知道到底加载了多少模块,会有什么地方冲突,除非调用的功能很多,不然不建议这样用
print(read1)
print(money)
另外获取一个模块,如果模块中有可变类型的数据,那么可能在运行文件中改完数据,调用文件中的数据值也变了,比如列表
3.查找模块路径的优先级
1.内存
2.内置模块
3.sys.path
import sys
print(sys.path) # 包含当前执行文件所在的根目录
这里可以做个测试
import spam
print(spam.money)
import time
time.sleep(15) # 在程序睡眠时间内把spam文件删了,下面依然能找到spam中的内容
import spam
print(spam.money)
sys.path中的当前目录,总是按执行文件的路径去找根目录的
4.如何区分python文件的两种用途
mmm.py
def f1():
print('f1') def f2():
print('f2') if __name__ == '__main__':
f1()
f2()
当文件被当作执行文件时,__name__的值,为__main__
当文件被当做模块导入__name__的值为模块名mmm
5. 软件开发目录规范
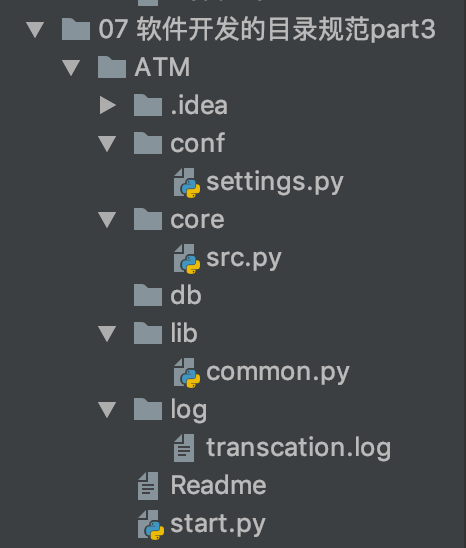
conf文件夹放配置文件settings.py,里面是用户可以设置的一些参数,比如日志地址,安装地址之类的
# 1. 应该把项目的根目录加到环境变量里
# 2. 应该把项目根目录所在绝对路径拿到,然后加到环境变量里
core文件夹放核心逻辑的源代码
db文件夹放数据库文件
lib文件夹中放一些其他不属于业务逻辑的通用的功能,比如记录日志的功能
log文件夹存放日志文件
每个项目应该有Readme文件,存放一些对项目的说明,告知用户程序如何使用
start.py,项目执行文件,主程序的入口,放在根目录下,这样项目的sys.path就是根目录,不存在import找不到模块的情况,会比较方便
day15模块内容的更多相关文章
- iOS开发之聊天模块--内容保存逻辑实现
需求详解: 在实际开发中,有可能是在后期优化的时候,会有这么需要优化的需求:聊天输入框保存之前输入的文本,提高用户的良好体验. 在聊天模块中,用户可能会在输入框输入若干字符,但是没有点击发送就点击退出 ...
- Day15模块(导入,使用)
Day15模块 什么是模块: 一系列功能的集合体 一个py文件就是一个模块 aaa.py就是aaa模块 模块四种形式: 内置的模块 py文件 第三方的 包 模块三种来源:内置的,第三方,自定义 为什么 ...
- 基于SqlSugar的开发框架循序渐进介绍(12)-- 拆分页面模块内容为组件,实现分而治之的处理
在早期的随笔就介绍过,把常规页面的内容拆分为几个不同的组件,如普通的页面,包括列表查询.详细资料查看.新增资料.编辑资料.导入资料等页面场景,这些内容相对比较独立,而有一定的代码量,本篇随笔介绍基于V ...
- Perl包和模块(内容来自beginning perl)
单文件版的perl程序只能用于构建较小的脚本程序.当代码规模较大时,应该遵循下面两条规则来构建程序.这样能将程序的各个部分按功能一个一个地细化,便于维护,也便于后续开发. 能复用的代码放进函数 能复用 ...
- python学习day15 模块(重点)
模块(重点) python2,与py3的区别 py2:range() 在内存中立即把所有的值都创建,xrange() 不会再内存中立即创建,而是在循环时边环边创建. py3:range() 不会再内存 ...
- DAY15 模块
一.模块 1.1 模块的定义:模块就是一系列功能的集合体 1.2 模块的四种存在方式: 1.使用python编写的.py文件(任一py文件都可以作为模块) 2.包:一堆py文件的集合体 3.使用C编写 ...
- day15(模块引用笔记)
import spam文件名是spam.py,模块名则是spam# 首次导入模块发生?件事# 1. 会产生一个模块的名称空间# 2. 执行文件spam.py,将执行过程中产生的名字都放到模块的名称空间 ...
- httprunner3源码解读(1)简单介绍源码模块内容
前言 最近想着搭建一个API测试平台,基础的注册登录功能已经完成,就差测试框架的选型,最后还是选择了httprunner,github上已经有很多开源的httprunner测试平台,但是看了下都是基于 ...
- Day15 Javascipt内容补充
JavaScript函数: 函数: function 函数名(a,b,c){ 执行代码 } 1,如何去找到标签 Dom直接选择器: 1,找到标签 #获取单个元素 document.getElement ...
随机推荐
- 0基础学习MySQL 之常用数据类型
原文地址 =========================================== 数据类型是定义列中可以存储什么数据以及该数据实际怎么存储的基本规则. Mysql的常用数据类型主要有: ...
- 学习笔记: js插件 —— SuperSlide 2 (轮播图插件,PC用)
SuperSlide 2 轮播图插件,较老.但还好用. 适用于PC,是绑定到jquery上的方法: $.slide(); 如果在实际中找不到.slide方法,请检查jquery等.js文件的引入次序 ...
- hdfs fsimage namenode 应该设置多少堆内存合适
线上的fsimage 有1.8G左右了,设置了6G heap 不够用了 新生代:老年代=1:2=2G: 4G NameNode的内存主要由NameSpace和BlocksMap占用,其中NameSpa ...
- asp:Repeater控件使用
Repeater控件和DataList控件,可以用来一次显示一组数据项.比如,可以用它们显示一个数据表中的所有行. Repeater控件完全由模板驱动,提供了最大的灵活性,可以任意设置它的输出格式.D ...
- JS 事件 Event
注册事件 target.addEventListener(type, listener, options); 或者 target.addEventListener(type, listener, us ...
- H5视频推流方案
导语 随着直播平台爆发式增长,直播平台从 PC 端转战移动端,紧跟着直播的潮流,自己学习实现了一套简单的 H5 视频推流的解决方案,下面就给小伙伴们分享一下自己学习过程中的经验. 环境部署 1. 配置 ...
- Mysql中select的正确姿势
引言 大家在开发中,还有很多童鞋在写查询语句的时候,习惯写下面这种不规范sql select * from table 而不写成下面的这种规范方式 select col1,col2,...,coln ...
- mac 关于默认python2下的pip,和python3下pip 的坑
pip是常用的python包管理工具,类似于java的maven.用python的同学,都离不开pip. 1.在Python2.7的安装包中,easy_install.py是默认安装的,而pip需要手 ...
- node.js 爬虫中文乱码 处理
爬虫中文乱码可做如下处理 import request from 'superagent'; import cheerio from 'cheerio';//类似jquery写法 const Icon ...
- unrecognized import path "golang.org/x/net/html"
go run的时候报:unrecognized import path "golang.org/x/net/html" 应该是被墙掉了,自己去github上下载包即可 git cl ...