Elasticsearch之优化
为什么es需要优化?
答:
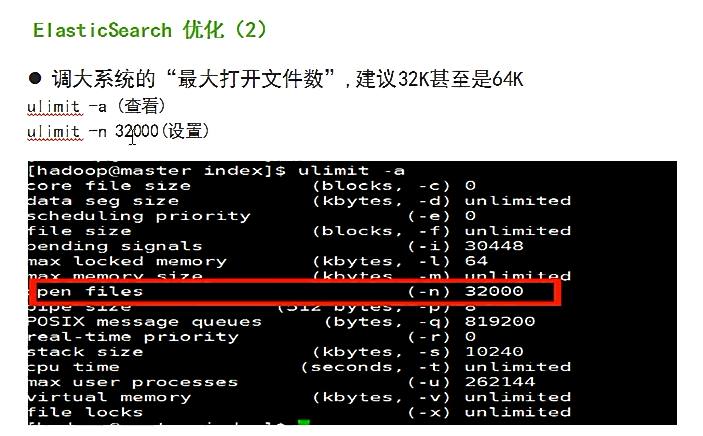


[root@master elasticsearch-2.4.0]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 6661
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240
cpu time (seconds, -t) unlimited
max user processes (-u) 6661
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[root@master elasticsearch-2.4.0]# ulimit -n 32000
[root@master elasticsearch-2.4.0]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 6661
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 32000
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240
cpu time (seconds, -t) unlimited
max user processes (-u) 6661
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[root@master elasticsearch-2.4.0]#
es集群的3节点,每个机器都要去设置。master、slave1和slave2都要去操作。
怎么来做好es的优化工作?
途径1、解决es启动的警告信息【或者es中Too many open files的问题】
max file descriptors [4096] for elasticsearch process likely too low, consider increasing to at least [65536]
vi /etc/security/limits.conf 添加下面两行
* soft nofile 65536
* hard nofile 131072
即,意思是把它们调大,重启es服务进程,就生效了。
途径2、修改配置文件调整ES的JVM内存大小
修改bin/elasticsearch.in.sh中ES_MIN_MEM和ES_MAX_MEM的大小,建议设置一样大,避免频繁的分配内存,根据服务器内存大小,一般分配60%左右(默认256M)
注意:内存最大不要超过32G【详情请看如下的截图和文字说明】
一旦你越过这个神奇的32 GB边界,指针会切换回普通对象指针.。每个指针的大小增加,使用更多的CPU内存带宽。事实上,你使用40~50G的内存和使用32G的内存效果是一样的。
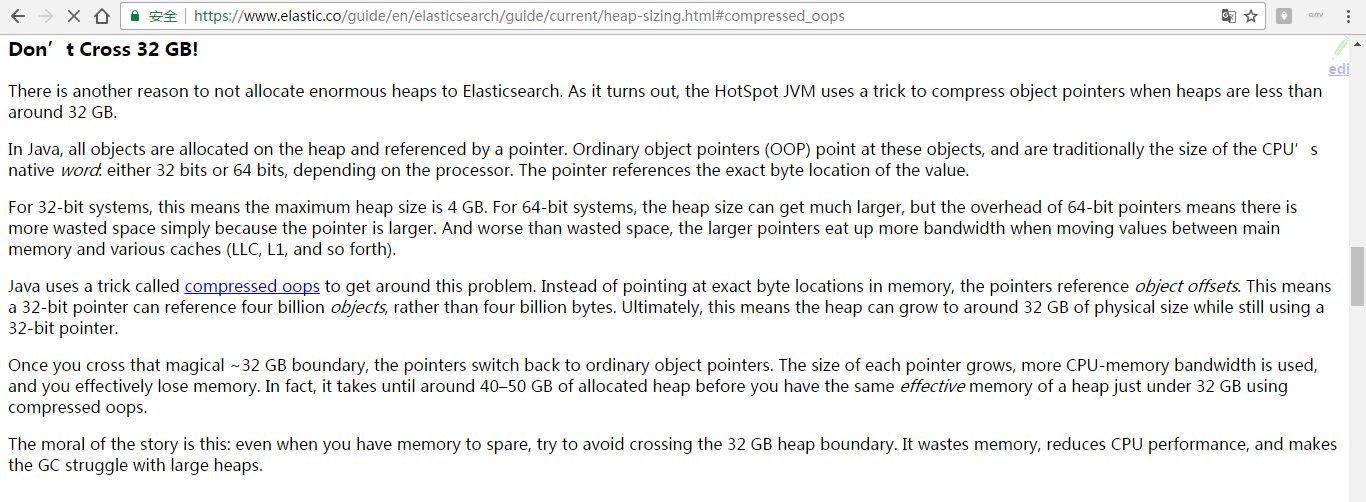
链接:https://www.elastic.co/guide/en/elasticsearch/guide/current/heap-sizing.html#compressed_oops
Don’t Cross 32 GB!
There is another reason to not allocate enormous heaps to Elasticsearch. As it turns out, the HotSpot JVM uses a trick to compress object pointers when heaps are less than around 32 GB.
In Java, all objects are allocated on the heap and referenced by a pointer. Ordinary object pointers (OOP) point at these objects, and are traditionally the size of the CPU’s native word: either 32 bits or 64 bits, depending on the processor. The pointer references the exact byte location of the value.
For 32-bit systems, this means the maximum heap size is 4 GB. For 64-bit systems, the heap size can get much larger, but the overhead of 64-bit pointers means there is more wasted space simply because the pointer is larger. And worse than wasted space, the larger pointers eat up more bandwidth when moving values between main memory and various caches (LLC, L1, and so forth).
Java uses a trick called compressed oops to get around this problem. Instead of pointing at exact byte locations in memory, the pointers reference object offsets. This means a 32-bit pointer can reference four billion objects, rather than four billion bytes. Ultimately, this means the heap can grow to around 32 GB of physical size while still using a 32-bit pointer.
Once you cross that magical ~32 GB boundary, the pointers switch back to ordinary object pointers. The size of each pointer grows, more CPU-memory bandwidth is used, and you effectively lose memory. In fact, it takes until around 40–50 GB of allocated heap before you have the same effective memory of a heap just under 32 GB using compressed oops.
The moral of the story is this: even when you have memory to spare, try to avoid crossing the 32 GB heap boundary. It wastes memory, reduces CPU performance, and makes the GC struggle with large heaps.
注意:是每个es实例不要超过32G,而不是所有的。
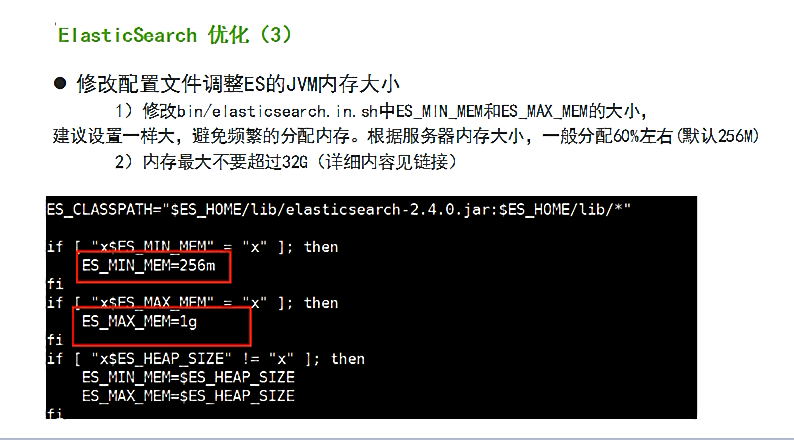
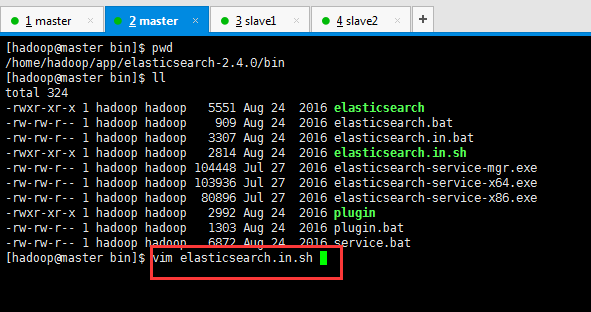
[hadoop@master bin]$ pwd
/home/hadoop/app/elasticsearch-2.4.0/bin
[hadoop@master bin]$ ll
total 324
-rwxr-xr-x 1 hadoop hadoop 5551 Aug 24 2016 elasticsearch
-rw-rw-r-- 1 hadoop hadoop 909 Aug 24 2016 elasticsearch.bat
-rw-rw-r-- 1 hadoop hadoop 3307 Aug 24 2016 elasticsearch.in.bat
-rwxr-xr-x 1 hadoop hadoop 2814 Aug 24 2016 elasticsearch.in.sh
-rw-rw-r-- 1 hadoop hadoop 104448 Jul 27 2016 elasticsearch-service-mgr.exe
-rw-rw-r-- 1 hadoop hadoop 103936 Jul 27 2016 elasticsearch-service-x64.exe
-rw-rw-r-- 1 hadoop hadoop 80896 Jul 27 2016 elasticsearch-service-x86.exe
-rwxr-xr-x 1 hadoop hadoop 2992 Aug 24 2016 plugin
-rw-rw-r-- 1 hadoop hadoop 1303 Aug 24 2016 plugin.bat
-rw-rw-r-- 1 hadoop hadoop 6872 Aug 24 2016 service.bat
[hadoop@master bin]$ vim elasticsearch.in.sh
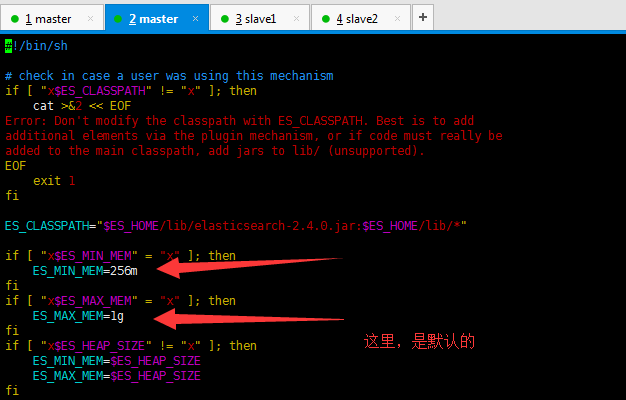
大家,自行去,根据自己机器内存实情,设置为其60%。
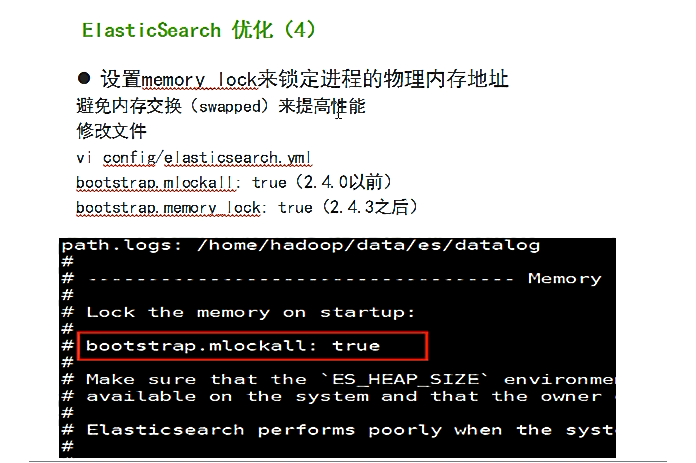
途径3、设置memory_lock来锁定进程的物理内存地址
避免交换(swapped)来提高性能
修改文件conf/elasticsearch.yml
bootstrap.memory_lock: true
这里,我就不赘述了。
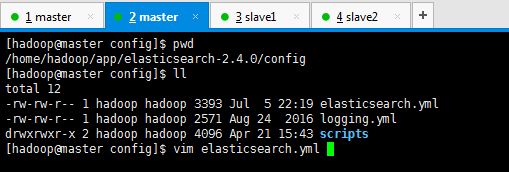
[hadoop@master config]$ pwd
/home/hadoop/app/elasticsearch-2.4.0/config
[hadoop@master config]$ ll
total 12
-rw-rw-r-- 1 hadoop hadoop 3393 Jul 5 22:19 elasticsearch.yml
-rw-rw-r-- 1 hadoop hadoop 2571 Aug 24 2016 logging.yml
drwxrwxr-x 2 hadoop hadoop 4096 Apr 21 15:43 scripts
[hadoop@master config]$ vim elasticsearch.yml
去掉注释。
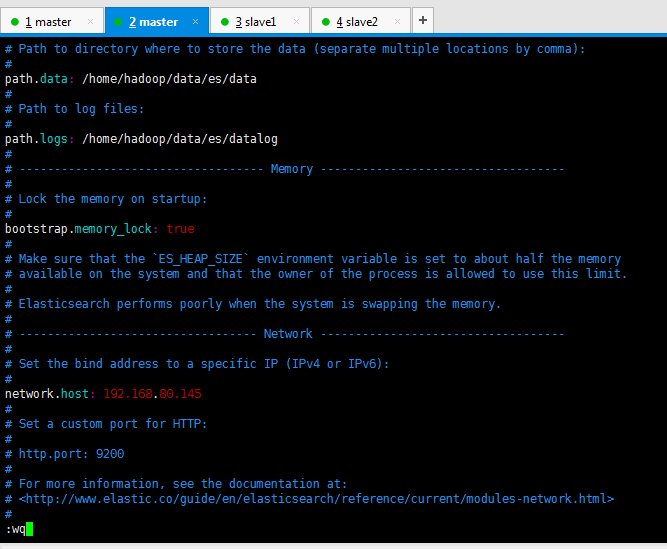
es的3节点集群,master、slave1和slave2都要去操作。
途径4、分片多的话,可以提升建立索引的能力,5-20个比较合适。
如果分片数过少或过多,都会导致检索比较慢。
分片数过多会导致检索时打开比较多的文件,另外也会导致多台服务器之间通讯。
而分片数过少会导至单个分片索引过大,所以检索速度也会慢。
建议单个分片最多存储20G左右的索引数据,所以,分片数量=数据总量/20G

途径5、副本多的话,可以提升搜索的能力,但是如果设置很多副本的话也会对服务器造成额外的压力,因为需要主分片需要给所有副本同步数据。所以建议最多设置1-2个即可。

途径6、Elastic 官方文档建议:一个 es实例中 最好不要多于三个 shards,若是 "more shards”,只能增加更多的机器 ,如果服务器性能好的话可以在一台服务器上启动多个es实例
途径7、要定时对索引进行合并优化,不然segment越多,占用的segment memory越多,查询的性能也越差
索引量不是很大的话情况下可以将segment设置为1
在es2.1.0以前调用_optimize接口,后期改为_forcemerge接口
curl -XPOST 'http://localhost:9200/zhouls/_forcemerge?max_num_segments=1'
client.admin().indices().prepareForceMerge("zhouls").setMaxNumSegments(1).get();

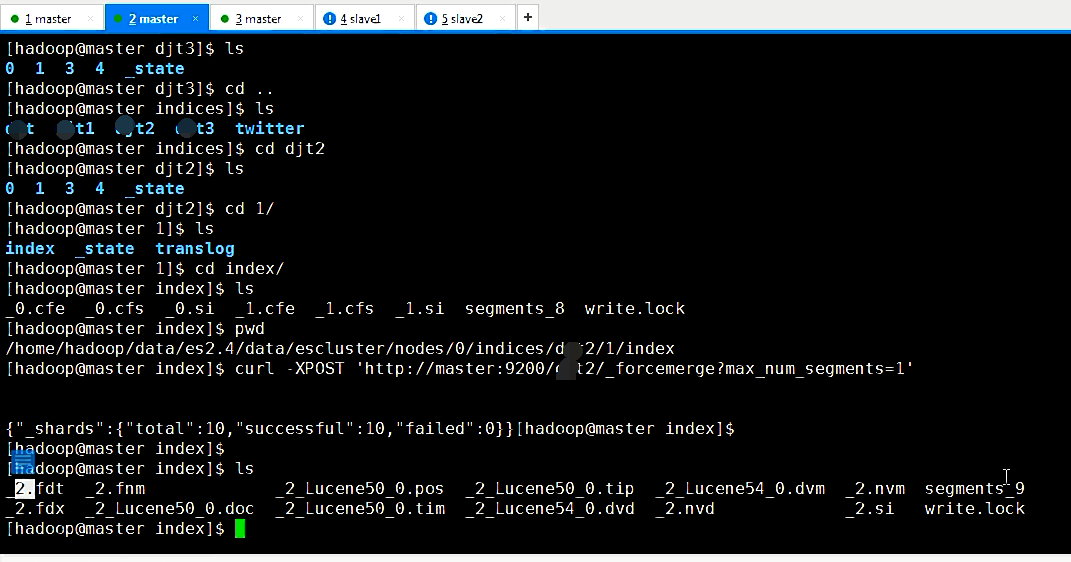
途径8、针对不使用的index,建议close,减少内存占用。因为只要索引处于open状态,索引库中的segement就会占用内存,close之后就只会占用磁盘空间了。
curl -XPOST 'localhost:9200/zhouls/_close'

途径9、删除文档:在es中删除文档,数据不会马上在硬盘上除去,而是在es索引中产生一个.del的文件,而在检索过程中这部分数据也会参与检索,es在检索过程会判断是否删除了,如果删除了在过滤掉。这样也会降低检索效率。所以可以执行清除删除文档
curl -XPOST 'http://192.168.80.10:9200/zhouls/_forcemerge?only_expunge_deletes=true'
client.admin().indices().prepareForceMerge("zhouls").setOnlyExpungeDeletes(true).get();

途径10、如果在项目开始的时候需要批量入库大量数据的话,建议将副本数设置为0
因为es在索引数据的时候,如果有副本存在,数据也会马上同步到副本中,这样会对es增加压力。可以等索引完成后将副本按需要改回来。这样可以提高索引效率。

途径11、去掉mapping中_all字段,Index中默认会有_all这个字段,默认会把所有字段的内容都拷贝到这一个字段里面,这样会给查询带来方便,但是会增加索引时间和索引尺寸。
禁用_all字段 "_all":{"enabled":false}
如果只是某个字段不希望被加到_all中,可以使用 "include_in_all":false

途径12、log输出的水平默认为trace,即查询超过500ms即为慢查询,就要打印日志,造成cpu和mem,io负载很高。把log输出水平改为info,可以减轻服务器的压力。
修改ES_HOME/conf/logging.yaml文件


途径1:可以解决es的警告信息
其实啊,若我们在ES_HOME目录下,不用后台bin/elasticsearch -d这种方式来启动的话,用前台bin/elasticsearch。则会看到,如下:
说明,我这里是因为安装了tomcat。所以,在前台直接启动,会出错。
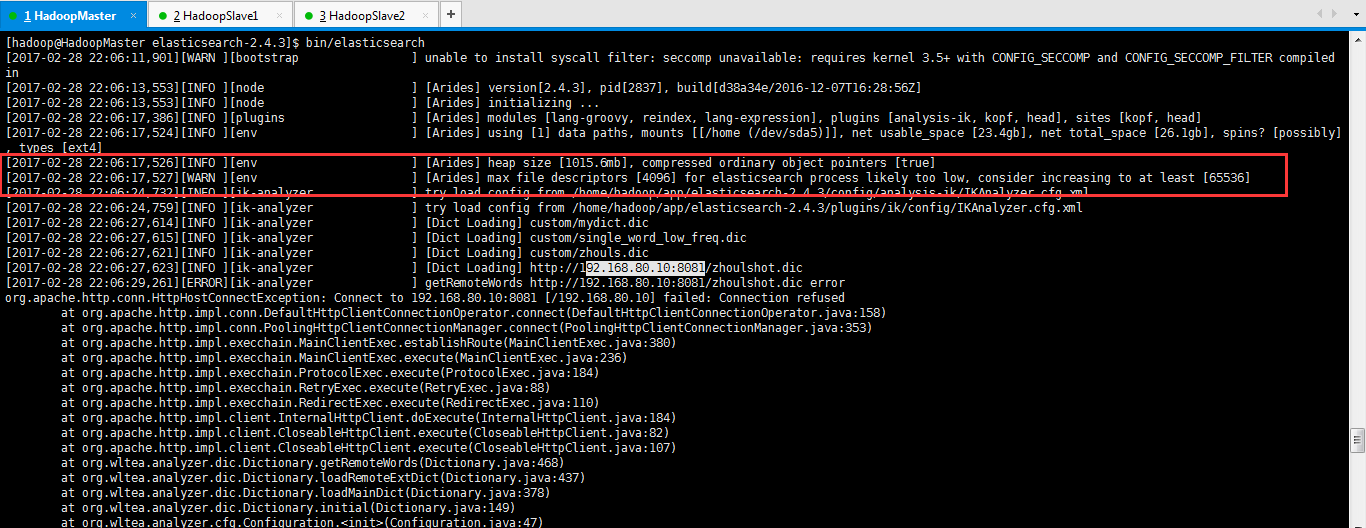
所以,
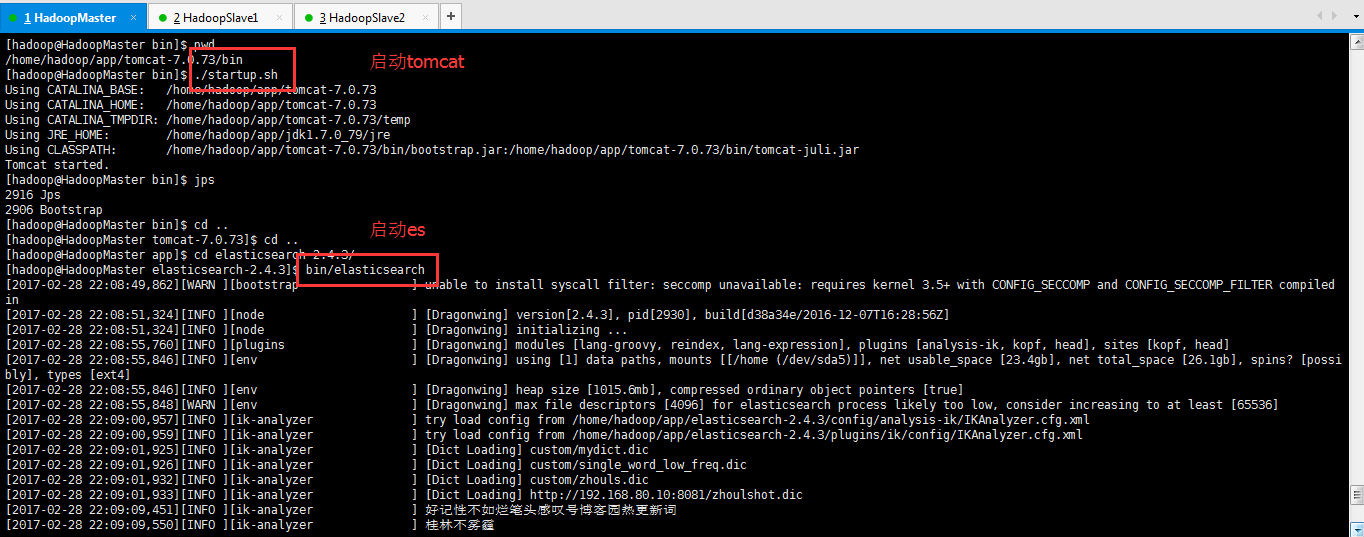
[hadoop@HadoopMaster bin]$ pwd
/home/hadoop/app/tomcat-7.0.73/bin
[hadoop@HadoopMaster bin]$ ./startup.sh
Using CATALINA_BASE: /home/hadoop/app/tomcat-7.0.73
Using CATALINA_HOME: /home/hadoop/app/tomcat-7.0.73
Using CATALINA_TMPDIR: /home/hadoop/app/tomcat-7.0.73/temp
Using JRE_HOME: /home/hadoop/app/jdk1.7.0_79/jre
Using CLASSPATH: /home/hadoop/app/tomcat-7.0.73/bin/bootstrap.jar:/home/hadoop/app/tomcat-7.0.73/bin/tomcat-juli.jar
Tomcat started.
[hadoop@HadoopMaster bin]$ jps
2916 Jps
2906 Bootstrap
[hadoop@HadoopMaster bin]$ cd ..
[hadoop@HadoopMaster tomcat-7.0.73]$ cd ..
[hadoop@HadoopMaster app]$ cd elasticsearch-2.4.3/
[hadoop@HadoopMaster elasticsearch-2.4.3]$ bin/elasticsearch
[2017-02-28 22:08:49,862][WARN ][bootstrap ] unable to install syscall filter: seccomp unavailable: requires kernel 3.5+ with CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER compiled in
[2017-02-28 22:08:51,324][INFO ][node ] [Dragonwing] version[2.4.3], pid[2930], build[d38a34e/2016-12-07T16:28:56Z]
[2017-02-28 22:08:51,324][INFO ][node ] [Dragonwing] initializing ...
[2017-02-28 22:08:55,760][INFO ][plugins ] [Dragonwing] modules [lang-groovy, reindex, lang-expression], plugins [analysis-ik, kopf, head], sites [kopf, head]
[2017-02-28 22:08:55,846][INFO ][env ] [Dragonwing] using [1] data paths, mounts [[/home (/dev/sda5)]], net usable_space [23.4gb], net total_space [26.1gb], spins? [possibly], types [ext4]
[2017-02-28 22:08:55,846][INFO ][env ] [Dragonwing] heap size [1015.6mb], compressed ordinary object pointers [true]
[2017-02-28 22:08:55,848][WARN ][env ] [Dragonwing] max file descriptors [4096] for elasticsearch process likely too low, consider increasing to at least [65536]
[2017-02-28 22:09:00,957][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/config/analysis-ik/IKAnalyzer.cfg.xml
[2017-02-28 22:09:00,959][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config/IKAnalyzer.cfg.xml
[2017-02-28 22:09:01,925][INFO ][ik-analyzer ] [Dict Loading] custom/mydict.dic
[2017-02-28 22:09:01,926][INFO ][ik-analyzer ] [Dict Loading] custom/single_word_low_freq.dic
[2017-02-28 22:09:01,932][INFO ][ik-analyzer ] [Dict Loading] custom/zhouls.dic
[2017-02-28 22:09:01,933][INFO ][ik-analyzer ] [Dict Loading] http://192.168.80.10:8081/zhoulshot.dic
[2017-02-28 22:09:09,451][INFO ][ik-analyzer ] 好记性不如烂笔头感叹号博客园热更新词
[2017-02-28 22:09:09,550][INFO ][ik-analyzer ] 桂林不雾霾
[2017-02-28 22:09:09,615][INFO ][ik-analyzer ] [Dict Loading] custom/ext_stopword.dic
[2017-02-28 22:09:13,620][INFO ][node ] [Dragonwing] initialized
[2017-02-28 22:09:13,621][INFO ][node ] [Dragonwing] starting ...
[2017-02-28 22:09:13,932][INFO ][transport ] [Dragonwing] publish_address {192.168.80.10:9300}, bound_addresses {[::]:9300}
[2017-02-28 22:09:13,960][INFO ][discovery ] [Dragonwing] elasticsearch/eKzsH0g5QoGl6pQlCG4mOQ
[2017-02-28 22:09:17,357][INFO ][cluster.service ] [Dragonwing] detected_master {Carrie Alexander}{98-Mux6mQsu1oE__EJN7yQ}{192.168.80.11}{192.168.80.11:9300}, added {{Carrie Alexander}{98-Mux6mQsu1oE__EJN7yQ}{192.168.80.11}{192.168.80.11:9300},{Shocker}{u_IYMF3ISe6_iki9KwxPCA}{192.168.80.12}{192.168.80.12:9300},}, reason: zen-disco-receive(from master [{Carrie Alexander}{98-Mux6mQsu1oE__EJN7yQ}{192.168.80.11}{192.168.80.11:9300}])
[2017-02-28 22:09:17,637][INFO ][http ] [Dragonwing] publish_address {192.168.80.10:9200}, bound_addresses {[::]:9200}
[2017-02-28 22:09:17,638][INFO ][node ] [Dragonwing] started
[2017-02-28 22:09:19,812][INFO ][ik-analyzer ] 重新加载词典...
[2017-02-28 22:09:19,816][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/config/analysis-ik/IKAnalyzer.cfg.xml
[2017-02-28 22:09:19,820][INFO ][ik-analyzer ] try load config from /home/hadoop/app/elasticsearch-2.4.3/plugins/ik/config/IKAnalyzer.cfg.xml
[2017-02-28 22:09:23,102][WARN ][monitor.jvm ] [Dragonwing] [gc][young][8][7] duration [1.6s], collections [1]/[1.9s], total [1.6s]/[5.2s], memory [121.7mb]->[79.4mb]/[1015.6mb], all_pools {[young] [59.9mb]->[457kb]/[66.5mb]}{[survivor] [8.2mb]->[8.3mb]/[8.3mb]}{[old] [53.5mb]->[70.6mb]/[940.8mb]}
[2017-02-28 22:09:23,946][INFO ][ik-analyzer ] [Dict Loading] custom/mydict.dic
[2017-02-28 22:09:23,947][INFO ][ik-analyzer ] [Dict Loading] custom/single_word_low_freq.dic
[2017-02-28 22:09:23,953][INFO ][ik-analyzer ] [Dict Loading] custom/zhouls.dic
[2017-02-28 22:09:23,955][INFO ][ik-analyzer ] [Dict Loading] http://192.168.80.10:8081/zhoulshot.dic
[2017-02-28 22:09:23,996][INFO ][ik-analyzer ] 好记性不如烂笔头感叹号博客园热更新词
[2017-02-28 22:09:23,997][INFO ][ik-analyzer ] 桂林不雾霾
[2017-02-28 22:09:24,000][INFO ][ik-analyzer ] [Dict Loading] custom/ext_stopword.dic
[2017-02-28 22:09:24,002][INFO ][ik-analyzer ] 重新加载词典完毕...
更详细,es的前台和后台启动,请移步
Elasticsearch之启动(前台和后台)
怎么做,如下:
后续更新
Elasticsearch之优化的更多相关文章
- 一次 ElasticSearch 搜索优化
一次 ElasticSearch 搜索优化 1. 环境 ES6.3.2,索引名称 user_v1,5个主分片,每个分片一个副本.分片基本都在11GB左右,GET _cat/shards/user 一共 ...
- ElasticSearch性能优化策略【转】
ElasticSearch性能优化主要分为4个方面的优化. 一.服务器部署 二.服务器配置 三.数据结构优化 四.运行期优化 一.服务器部署 1.增加1-2台服务器,用于负载均衡节点 elasticS ...
- 亿级 Elasticsearch 性能优化
前言 最近一年使用 Elasticsearch 完成亿级别日志搜索平台「ELK」,亿级别的分布式跟踪系统.在设计这些系统的过程中,底层都是采用 Elasticsearch 来做数据的存储,并且数据量都 ...
- 分布式搜索引擎Elasticsearch性能优化与配置
1.内存优化 在bin/elasticsearch.in.sh中进行配置 修改配置项为尽量大的内存: ES_MIN_MEM=8g ES_MAX_MEM=8g 两者最好改成一样的,否则容易引发长时间GC ...
- elasticsearch 性能优化
#系统默认的最大打开文件数的限制 vi /etc/security/limits.conf * - nproc 50240 * - ...
- Mac安装6.1.2版本Elasticsearch及优化配置实践
1,Mac上安装(指定java8) brew cask install java8 vim .base_profile 文件内容: JAVA_HOME=/Library/Java/JavaVirtua ...
- Elasticsearch分片优化
原文地址:https://qbox.io/blog/optimizing-elasticsearch-how-many-shards-per-index 大多数ElasticSearch用户在创建索引 ...
- ElasticSearch性能优化
一.搜索效率优化 批量提交 当有大量数据提交的时候,建议采用批量提交. 比如在做 ELK 过程中 ,Logstash indexer 提交数据到 Elasticsearch 中 ,batch size ...
- Elasticsearch聚合优化 | 聚合速度提升5倍
https://blog.csdn.net/laoyang360/article/details/79253294 1.聚合为什么慢?大多数时候对单个字段的聚合查询还是非常快的, 但是当需要同时聚合多 ...
随机推荐
- [CVE-2014-8959] phpmyadmin任意文件包含漏洞分析
0x01 漏洞描述 phpmyadmin是一款应用非常广泛的mysql数据库管理软件,基于PHP开发. 最新的CVE-2014-8959公告中,提到该程序多个版本存在任意文件包含漏洞,影响版本如下: ...
- RHEL7或CentOS7安装11.2.0.4 RAC碰到的问题
RHEL7或CentOS7安装11.2.0.4 RAC碰到的问题 随着Linux 版本的普及,但Oracle数据库主流版本仍是11gR2, 的支持不很完美,在Linux 上安装会遇到几处问题,以此记录 ...
- servlet的执行过程简介(从tomcat服务器和web应用的角度)
该链接详解htttp请求和响应 http://www.cnblogs.com/goxcheer/p/8424175.html 1.web应用工程发布到tomcat服务器 2.客户端访问某个web资源, ...
- 如何使用webpack打包项目
webpack是前端开发中比较常用的打包工具之一,另外还有gulp,grunt.之前没有涉及过打包这块,这里介绍一下使用webpack打包的流程. Grunt和Gulp的工作方式是:在一个配置文件中, ...
- Hive快捷查询:不启用Mapreduce job启用Fetch task
启用MapReduce Job是会消耗系统开销的.对于这个问题,从Hive0.10.0版本开始,对于简单的不需要聚合的类似SELECT <col> from <table> L ...
- java的list遍历
for(String str : list) {//增强for循环,其内部实质上还是调用了迭代器遍历方式,这种循环方式还有其他限制,不建议使用. System.out.println(str); } ...
- (转)日期类型的input元素设置默认值为当天
原文地址 html5的form元素对日期时间有丰富的支持 <input type="date"> <input type="time"> ...
- Robot Operating System (ROS)学习笔记2---使用smartcar进行仿真
搭建环境:XMWare Ubuntu14.04 ROS(indigo) 转载自古月居 转载连接:http://www.guyuehome.com/248 一.模型完善 文件夹urdf下,创建ga ...
- js-杂记
js可计算传值 <p>点击按钮计算 x 的值.</p> <button onclick="myFunction()">点击这里</butt ...
- IIS w3wp对应的应用程序
IIS7以前我們用IISApp查看IIS哪些服務已啟動,但在IIS7已經不適用了,新語法是appcmd.exe list wp.你可以在%windir%\system32\inetsrv\底下找到ap ...