Python 项目实践二(生成数据)第二篇
接着上节继续学习,在本节中,我们将使用Python来生成随机漫步数据,再使用matplotlib以引人瞩目的方式将这些数据呈现出来。随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向,结果是由一系列随机决策决定的。你可以这样认为,随机漫步就是蚂蚁在晕头转向的情况下,每次都沿随机的方向前行所经过的路径。
一 随机漫步
1 创建RandomWalk()类
为模拟随机漫步,我们将创建一个名为RandomWalk的类,它随机地选择前进方向。这个类需要三个属性,其中一个是存储随机漫步次数的变量,其他两个是列表,分别存储随机漫步经过的每个点的x和y坐标。代码如下:
from random import choice class RandomWalk() :
'''一个生成随机漫步数的类'''
def __init__(self,num_points=50000):
'''初始化随机漫步的属性'''
self.num_points = num_points #所有随机漫步都始于(0,0)
self.x_values = [0]
self.y_values =[0]
2 选择方向
我们将使用fill_walk()来生成漫步包含的点,并决定每次漫步的方向,如下所示。请将这个方法添加到random_walk.py中:
def fill_walk(self):
#计算随机漫步包含的所有点 #不断漫步,直到列表达到指定的长度
while len(self.x_values) < self.num_points : #决定前进方向以及沿着个方向前进的距离
x_direction = choice([1,-1])
x_distance = choice([0,1,2,3,4])
x_step = x_direction*x_distance y_direction = choice([1,-1])
y_distance = choice([0,1,2,3,4])
y_step = y_direction*y_distance #拒绝原地踏步
if x_step == 0 and y_step ==0 :
continue #计算下一个点的x和y值
next_x= self.x_values[-1] + x_step
next_y= self.y_values[-1] + y_step self.x_values.append(next_x)
self.y_values.append(next_y)
代码注释的很清楚了,我再强调几点:
(1)我们建立了一个循环,这个循环不断运行,直到漫步包含所需数量的点。
(2)如何模拟四种漫步决定:向右走还是向左走?沿指定的方向走多远?向上走还是向下走?沿选定的方向走多远?
3 绘制随机漫步的图像
import matplotlib.pyplot as plt from random_walk import RandomWalk while True :
random_walk = RandomWalk()
random_walk.fill_walk()
plt.figure(figsize=(10,6))
point_numbers = list(range(random_walk.num_points))
plt.scatter(random_walk.x_values,random_walk.y_values,c=point_numbers,cmap=plt.cm.Blues,edgecolor="none",s=1) # 突出起点和终点
plt.scatter(0, 0, c='green', edgecolors='none', s=100)
plt.scatter(random_walk.x_values[-1], random_walk.y_values[-1], c='red', edgecolors='none',
s=100) #隐藏坐标轴
plt.axes().get_xaxis().set_visible(False)
plt.axes().get_yaxis().set_visible(False)
plt.show() input_flag = input("是否结束?(Y/N)") if input_flag == "Y" :
break
运行效果图如下:

注意几点:
(1)模拟多次随机漫步:每次随机漫步都不同,因此探索可能生成的各种模式很有趣。要在不多次运行程序的情况下使用前面的代码模拟多次随机漫步,一种办法是将这些代码放在一个while循环中。
(2)给点着色:我们将使用颜色映射来指出漫步中各点的先后顺序,并删除每个点的黑色轮廓,让它们的颜色更明显。为根据漫步中各点的先后顺序进行着色。
(3)重新绘制起点和终点:,可在绘制随机漫步图后重新绘制起点和终点。我们让起点和终点变得更大,并显示为不同的颜色,以突出它们。
(4)隐藏坐标轴:为修改坐标轴,使用了函数plt.axes()来将每条坐标轴的可见性都设置为False。随着你越来越多地进行数据可视化,经常会看到这种串接方法的方式。
(5)增加点数:增大num_points的值,并在绘图时调整每个点的大小。
(6)调整尺寸以适合屏幕:函数figure()用于指定图表的宽度、高度、分辨率和背景色。你需要给形参figsize指定一个元组,向matplotlib指出绘图窗口的尺寸,单位为英寸。
二 使用Pygal模拟掷骰子
在本节中,我们将使用Python可视化包Pygal来生成可缩放的矢量图形文件。对于需要在尺寸不同的屏幕上显示的图表,这很有用,因为它们将自动缩放,以适合观看者的屏幕。如果你打算以在线方式使用图表,请考虑使用Pygal来生成它们,这样它们在任何设备上显示时都会很美观。
在这个项目中,我们将对掷骰子的结果进行分析。掷6面的常规骰子时,可能出现的结果为1~6点,且出现每种结果的可能性相同。然而,如果同时掷两个骰子,某些点数出现的可能性将比其他点数大。为确定哪些点数出现的可能性最大,我们将生成一个表示掷骰子结果的数据集,并根据结果绘制出一个图形。
1 安装Pygal
python -m pip install --user pygal
2 创建Die类
from random import randint class Die():
'''表示一个骰子的类''' def __init__(self,num_sides=6):
'''骰子默认6个面'''
self.num_sides=num_sides def roll(self):
#返回一个1-面数之间的随机值
return randint(1,self.num_sides)
3 掷筛子
使用这个类来创建图表前,先来掷D6骰子,将结果打印出来,并检查结果是否合理:
from die import Die die=Die() results=[] for roll_num in range(100) :
result=die.roll()
results.append(result) print(results)
结果如下:
4 分析结果
为分析掷一个D6骰子的结果,我们计算每个点数出现的次数:
from die import Die die=Die() results=[] for roll_num in range(1000) :
result=die.roll()
results.append(result) #分析结果
frequencies=[]
for value in range(1,die.num_sides+1) :
frequency=results.count(value)
frequencies.append(frequency) print(frequencies)
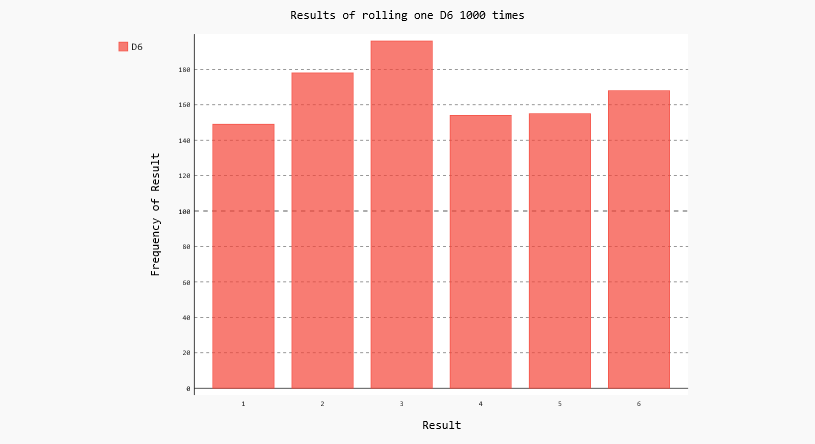
结果如下:[156, 171, 151, 173, 181, 168]
结果看起来是合理的:我们看到了6个值——掷D6骰子时可能出现的每个点数对应一个;我们还发现,没有任何点数出现的频率比其他点数高很多。下面来可视化这些结果。
5 绘制立方图
from die import Die
import pygal die=Die() results=[] for roll_num in range(1000) :
result=die.roll()
results.append(result) #分析结果
frequencies=[]
for value in range(1,die.num_sides+1) :
frequency=results.count(value)
frequencies.append(frequency) #print(frequencies) #对结果进行可视化
hist = pygal.Bar() hist.title= "Results of rolling one D6 1000 times."
hist.x_labels=['1','2','3','4','5','6']
hist.x_title = "Result"
hist.y_title = "Frequency of Result" hist.add("D6",frequencies)
hist.render_to_file("die_visual.svg")
为创建条形图,我们创建了一个pygal.Bar()实例,并将其存储在hist中,我们设置hist的属性title(用于标示直方图的字符串),将掷D6骰子的可能结果用作x轴的标签,并给每个轴都添加了标题,我们使用add()将一系列值添加到图表中(向它传递要给添加的值指定的标签,还有一个列表,其中包含将出现在图表中的值)。最后,我们将这个图表渲染为一个SVG文件,这种文件的扩展名必须为.svg。
要查看生成的直方图,最简单的方式是使用Web浏览器。如下图:
6 同时掷两个骰子
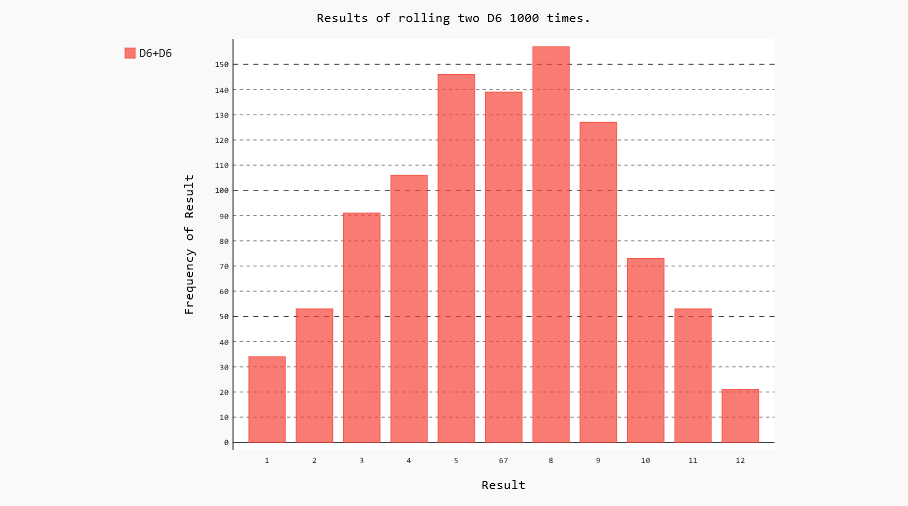
每次掷两个骰子时,我们都将两个骰子的点数相加,并将结果存储在results中。请复制die_visual.py并将其保存为dice_visual.py,再做如下修改:
from die import Die
import pygal die_1=Die()
die_2=Die() results=[] for roll_num in range(1000) :
result=die_1.roll() + die_2.roll()
results.append(result) #分析结果
frequencies=[]
max_result = die_1.num_sides + die_2.num_sides for value in range(2,max_result+1) :
frequency=results.count(value)
frequencies.append(frequency) #print(frequencies) #对结果进行可视化
hist = pygal.Bar() hist.title= "Results of rolling two D6 1000 times."
hist.x_labels=['1','2','3','4','5','6''7','8','9','10','11','12']
hist.x_title = "Result"
hist.y_title = "Frequency of Result" hist.add("D6+D6",frequencies)
hist.render_to_file("die_visual.svg")
结果如下:
也可以掷不同的骰子,就不在详解了!未完待续!
Python 项目实践二(生成数据)第二篇的更多相关文章
- Python 项目实践二(生成数据)第一篇
上面那个小游戏教程写不下去了,以后再写吧,今天学点新东西,了解的越多,发现python越强大啊! 数据可视化指的是通过可视化表示来探索数据,它与数据挖掘紧密相关,而数据挖掘指的是使用代码来探索数据集的 ...
- Python 项目实践二(生成数据)第二篇之随机漫步
接着上节继续学习,在本节中,我们将使用Python来生成随机漫步数据,再使用matplotlib以引人瞩目的方式将这些数据呈现出来.随机漫步是这样行走得到的路径:每次行走都完全是随机的,没有明确的方向 ...
- Python 项目实践二(下载数据)第三篇
接着上节继续学习,在本章中,你将从网上下载数据,并对这些数据进行可视化.网上的数据多得难以置信,且大多未经过仔细检查.如果能够对这些数据进行分析,你就能发现别人没有发现的规律和关联.我们将访问并可视化 ...
- Python 项目实践二(下载数据)第四篇
接着上节继续学习,在本节中,你将下载JSON格式的人口数据,并使用json模块来处理它们.Pygal提供了一个适合初学者使用的地图创建工具,你将使用它来对人口数据进行可视化,以探索全球人口的分布情况. ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - Guava Cache
文章目录 1. Guava Cache 集成 2. 个性化配置 3. 源代码 本文,讲解 Spring Boot 如何集成 Guava Cache,实现缓存. 在阅读「Spring Boot 揭秘与实 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - 快速入门
文章目录 1. 声明式缓存 2. Spring Boot默认集成CacheManager 3. 默认的 ConcurrenMapCacheManager 4. 实战演练5. 扩展阅读 4.1. Mav ...
- Spring Boot 揭秘与实战(二) 数据存储篇 - 数据访问与多数据源配置
文章目录 1. 环境依赖 2. 数据源 3. 单元测试 4. 源代码 在某些场景下,我们可能会在一个应用中需要依赖和访问多个数据源,例如针对于 MySQL 的分库场景.因此,我们需要配置多个数据源. ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - Redis Cache
文章目录 1. Redis Cache 集成 2. 源代码 本文,讲解 Spring Boot 如何集成 Redis Cache,实现缓存. 在阅读「Spring Boot 揭秘与实战(二) 数据缓存 ...
- Spring Boot 揭秘与实战(二) 数据缓存篇 - EhCache
文章目录 1. EhCache 集成 2. 源代码 本文,讲解 Spring Boot 如何集成 EhCache,实现缓存. 在阅读「Spring Boot 揭秘与实战(二) 数据缓存篇 - 快速入门 ...
随机推荐
- Codeforces 468C/469E 易错点
#include <stdio.h> #include <stdlib.h> typedef long long ll; int main() { ll x=1e17; ll ...
- SqlServer在视图上创建索引
在视图上创建索引需要三个条件: 一.视图必须绑定到架构. 要做到这点,在 CREATE VIEW 语句中,必须加上 WITH SCHEMABINDING,如果是使用企业管理器,则在设计界面的空白处点击 ...
- python实现windows Service服务程序
python实现windows Service服务程序 win32serviceutil.ServiceFramework是封装得很好的Windows服务框架,本文通过继承它来实现. 通过SvcDoR ...
- SQL记录-PLSQL-DBMS输出
PL/SQL DBMS输出 DBMS_OUTPUT是一个内置的软件包,能够显示输出显示调试信息,并从PL/ SQL块,子程序,包和触发器发送消息.我们已经使用这个包在我们所有的教程中. 让我们来看 ...
- spring中set注入的一些小细节错误
这是小白偶尔一直null指针的错误,调试了好久,原来是自己对spring注入的不够了解 我相信有很多跟我差不多的初学者会遇上,所以特地写出来,防止有人跟我一样.哈哈,也写上去,以防自己下次还犯这样的错 ...
- 用matplotlib绘制每次交易的盈亏三角形
用matplotlib绘制每次交易的盈亏三角形 结果: 代码: python def plot_trade_triangle(self): # plot each trade as a trade-t ...
- 20155220 2016-2017-2 《Java程序设计》第六周学习总结
20155220 2016-2017-2 <Java程序设计>第六周学习总结 教材学习内容总结 第十章 输入输出 10.1 InputStream OutputStream 数据有来源与目 ...
- Git Pull Failed: cannot lock ref 'refs/remotes/origin/xxxxxxxx': unable to resolve ref
1.xxxxxxxx代表目录名称,我要pull的目录是supman_creditmall_v5: 2.从代码库中pull代码时报这个错误,代码pull失败: 3.解决办法,看下图,删除文件后再pull ...
- java学习第05天(数组常见操作、数组中的数组)
(4)数组常见操作 a.遍历取值 class ArrayDemo3 { public static void main(String[] args) { //System.out.println(&q ...
- Anaconda+django写出第一个web app(七)
今天来实现如何在页面弹出一些信息,比如注册成功后弹出注册成功的信息.这一点可以通过materialize里的Toasts来实现. django自带的messages可以告诉我们是否注册成功,以及注册失 ...