Flume分布式日志收集系统
1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去。
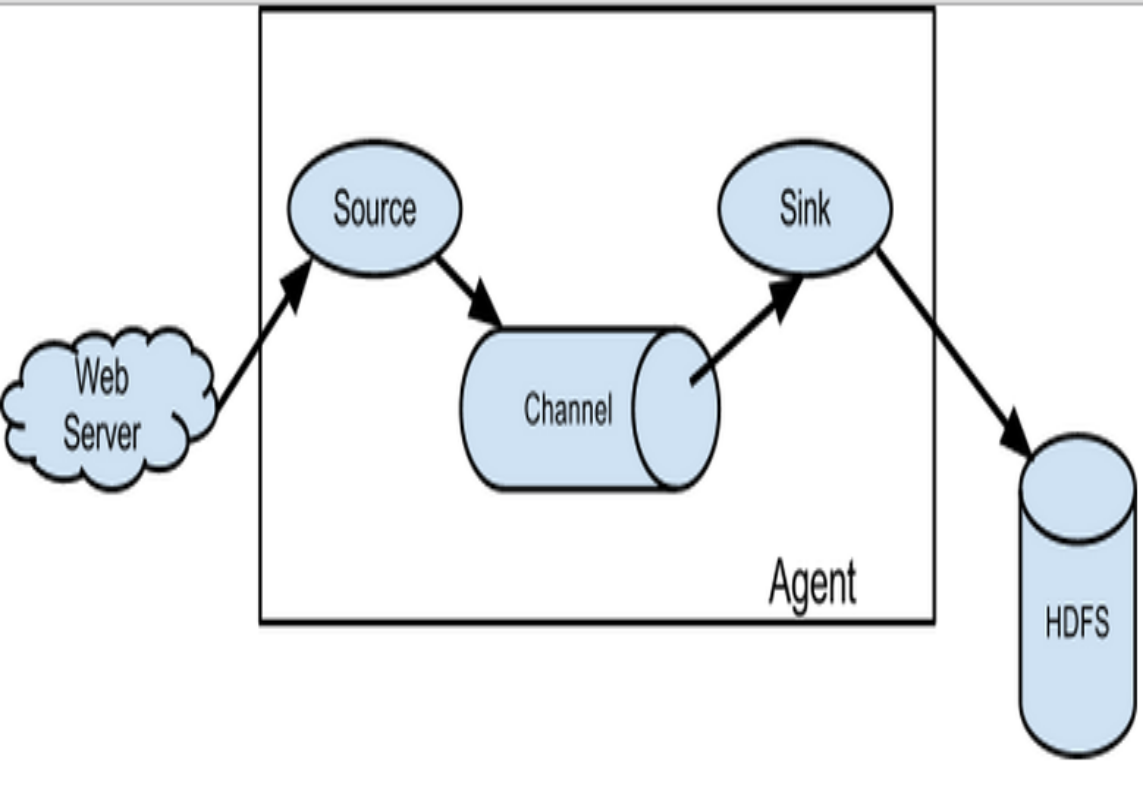
2.flume里面有个核心概念,叫做agent。agent是一个java进程,运行在日志收集节点。通过agent接收日志,然后暂存起来,再发送到目的地。
3.agent里面包含3个核心组件:source、channel、sink。
3.1 source组件是专用于收集日志的,可以处理各种类型各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
source组件把数据收集来以后,临时存放在channel中。
3.2 channel组件是在agent中专用于临时存储数据的,可以存放在memory、jdbc、file、自定义。
channel中的数据只有在sink发送成功之后才会被删除。
3.3 sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
4.在整个数据传输过程中,流动的是event。事务保证是在event级别。
5.flume可以支持多级flume的agent,支持扇入(fan-in)、扇出(fan-out)。
6、安装Flume:
1、先将flume的bin.jar和src.jar复制到/usr/local下,然后解压,将src目录下的文件复制到bin目录下:cp -ri apache-flume-1.4.0-src/* apache-flume-1.4.0-bin/
2、删除/usr/lcoal下的解压好的src文件,再将bin重命名:mv apache-flume-1.4.0-bin flume
3、flume/bin/ #flume-ng 可以看到命令的相关用法
4、核心是写配置文件
7.书写配置文件example
在flume/conf/下创建配置文件example:
vi example 或者直接在winSCP中创建
- #agent1表示代理名称
- agent1.sources=source1
- agent1.sinks=sink1
- agent1.channels=channel1
- #Spooling Directory是监控指定文件夹中新文件的变化,一旦新文件出现,就解析该文件内容,然后写入到channle。写入完成后,标记该文件已完成或者删除该文件。
- #配置source1 interceptor可以在数据传递过程中改变其属性信息
- agent1.sources.source1.type=spooldir
- agent1.sources.source1.spoolDir=/root/hmbbs
- agent1.sources.source1.channels=channel1
- agent1.sources.source1.fileHeader = false
- agent1.sources.source1.interceptors = i1
- agent1.sources.source1.interceptors.i1.type = timestamp
- #配置sink1
- agent1.sinks.sink1.type=hdfs
- agent1.sinks.sink1.hdfs.path=hdfs://hadoop0:9000/hmbbs
- agent1.sinks.sink1.hdfs.fileType=DataStream
- agent1.sinks.sink1.hdfs.writeFormat=TEXT
- agent1.sinks.sink1.hdfs.rollInterval=1
- agent1.sinks.sink1.channel=channel1
- agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
- #配置channel1
- agent1.channels.channel1.type=file
- agent1.channels.channel1.checkpointDir=/root/hmbbs_tmp/123
- agent1.channels.channel1.dataDirs=/root/hmbbs_tmp/
在/root下创建文件夹hmbbs:mkdir hmbbs
在HDFS中创建文件夹:hadoop fs -mkdir /hmbbs
8.执行命令bin/flume-ng agent -n agent1 -c conf -f conf/example -Dflume.root.logger=DEBUG,console
执行完了,flume就会监控/root/hmbbs中数据的变化
在/root/hmbbs下:
vi hello
hello you
hello me
cp hello hmbbs
现在数据就发生了变化!flume就会监控到变化,并把数据文件上传到hdfs中
可在hadoop0:50070中观察到日志文件

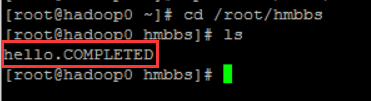
也可在hadoop0/root/hmbbs下,观察到有个hello.COMPLETED,之前的hello变成了hello.COMPLETED(因为这里使用的是Spooling Directory导致的。对hello从不删除,上传完成只会重命名)
在/root/hmbbs_tmp目录下,这个目录是channel使用的目录。在/root/hmbbs_tmp123目录下,表示的是备份数据。
Flume分布式日志收集系统的更多相关文章
- flume分布式日志收集系统操作
1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去. 2.flume里面有个核心概念,叫做agent.agent是一个java进程,运行在日志收集节点. 3.agent里面包含3个核心 ...
- 分布式日志收集系统Apache Flume的设计详细介绍
问题导读: 1.Flume传输的数据的基本单位是是什么? 2.Event是什么,流向是怎么样的? 3.Source:完成对日志数据的收集,分成什么打入Channel中? 4.Channel的作用是什么 ...
- 基于Flume的日志收集系统方案参考
前言 本文将简单介绍两种基于Flume的日志收集系统可能的架构方案,可根据不同的实际场景参考使用. 方案一 示例图如下: 说明: 每个日志源(http上报.日志文件等)对应一个Agent-c用于收集对 ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- 分布式日志收集系统- Cloudera Flume 介绍
Flume是Cloudera提供的日志收集系统,具有分布式.高可靠.高可用性等特点,对海量日志采集.聚合和传输, Flume支持在日志系统中定制各类数据发送方, 同时,Flume提供对数据进行 ...
- 分布式日志收集系统:Flume
Flume知识点: Event 是一行一行的数据 1.flume是分布式的日志收集系统,把收集来的数据传送到目的地去. 2.flume里面有个核心概念,叫做agent.agent是一个java进程,运 ...
- 分布式日志收集系统 —— Flume
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- 分布式日志收集系统--Chukwa
1. 安装部署 1.1 环境要求 1.使用的JDK的版本必须是1.6或者更高版本,本实例中使用的是JDK1.6 2.使用的hadoop的版本必须是Hadoop0.20.205.1及以上版本,本实例中使 ...
- 分布式日志收集收集系统:Flume(转)
Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力.Fl ...
随机推荐
- 【BZOJ1965】[AHOI2005]洗牌(数论)
[BZOJ1965][AHOI2005]洗牌(数论) 题面 BZOJ 洛谷 题解 考虑反过来做这个洗牌的操作,假定当前牌是第\(l\)张. 因为之前洗的时候考虑了前一半和后一半,所以根据\(l\)的奇 ...
- bzoj1018/luogu4246 堵塞的交通 (线段树)
对于一个区间四个角的点,可以用线段树记下来它们两两的联通情况 区间[l,r]通过两个子区间[l,m],[m+1,r]来更新,相当于合并[l,m],[m+1,r],用(m,m+1)这条边来合并 查询a, ...
- 使用Rider写一个C#的Hello World程序
1. 安装Rider 首先到Jetbrains官网下载Rider:https://www.jetbrains.com/rider/ 然后到IntelliJ IDEA 注册码获得注册码. 2. 安装do ...
- gulpfile.js不断更新中...
Gulp压缩合并js/css文件,压缩图片,以及热更新教程 var gulp = require('gulp');var concat = require('gulp-concat');//- 多个文 ...
- 使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- arcgis计算邻接矩阵
求邻接矩阵 教程链接 http://m.blog.csdn.net/wan_yanyan528/article/details/49175673 (1) 将目标shp文件导出一份副本备用(以省级为 ...
- SpringBoot Logback日志配置
Logback的配置介绍: 1.Logger.appender及layout Logger作为日志的记录器,把它关联到应用的对应的context上后,主要用于存放日志对象,也可以定义日志类型.级别. ...
- JavaScript继承详解(二)
这一章我们将会重点介绍JavaScript中几个重要的属性(this.constructor.prototype), 这些属性对于我们理解如何实现JavaScript中的类和继承起着至关重要的作用. ...
- Myeclipse 工具优化 [内存一直增加, jsp,javascript 编辑很卡]
首先看这篇随笔 地址: Myeclipse/STS 首次在本地部署配置一个Spring MVC 项目 (十二) [http://www.cnblogs.com/editor/p/3915239.htm ...
- CSS-3 文字阴影—text-shadow 的使用
text-shadow还没有出现的时候,大家在网页中的阴影就是用ps一张图片作为背景.那么现在有了CSS3的这个属性,日后我们的工作会更简洁些. text-shadow之前出现过,不过不久就被Pass ...