scrapy入门二(分页抓取文章入库)
分页抓取博客园新闻,先从列表里分析下一页按钮
相关代码:
# -*- coding: utf-8 -*-
import scrapy from cnblogs.items import ArticleItem class BlogsSpider(scrapy.Spider):
name = 'blogs'
allowed_domains = ['news.cnblogs.com']
start_urls = ['https://news.cnblogs.com/'] def parse(self, response):
articleList=response.css('.content') for item in articleList:
# 由于详情页里浏览次数是js动态加载的,无法获取,这里需要传递过去
viewcount = item.css('.view::text').extract_first()[:-3].strip()
detailurl = item.css('.news_entry a::attr(href)').extract_first()
detailurl = response.urljoin(detailurl)
yield scrapy.Request(url=detailurl, callback=self.parse_detail, meta={"viewcount": viewcount})
#获取下一页标签
text=response.css('#sideleft > div.pager > a:last-child::text').extract_first().strip()
if text=='Next >':
next = response.css('#sideleft > div.pager > a:last-child::attr(href)').extract_first()
url=response.urljoin(next) yield scrapy.Request(url=url,callback=self.parse) ##解析详情页内容
def parse_detail(self, response):
article=ArticleItem()
article['linkurl']=response.url
article['title']=response.css('#news_title a::text').extract_first()
article['img'] = response.css('#news_content img::attr(src)').extract_first("default.png")
article['source'] = response.css('.news_poster ::text').extract_first().strip()
article['releasetime'] = response.css('.time::text').extract_first()[3:].strip()
article['viewcount']= response.meta["viewcount"]
article['content']=response.css('#news_body').extract_first("") yield article
写入数据库,先在setting.py页面配置mongo连接数据信息
ROBOTSTXT_OBEY = True
MONGODB_HOST='localhost'
MONGO_PORT=27017
MONGO_DBNAME='cnblogs'
MONGO_DOCNAME='article'
修改pipelines.py页面,相关代码
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.conf import settings
from cnblogs.items import ArticleItem
class CnblogsPipeline(object):
#初始化信息
def __init__(self): host = settings['MONGODB_HOST']
port = settings['MONGO_PORT']
db_name = settings['MONGO_DBNAME']
client = pymongo.MongoClient(host=host, port=port)
db = client[db_name]
self.post=db[settings['MONGO_DOCNAME']] ##获取值进行入库
def process_item(self, item, spider): article=dict(item)
self.post.insert(article) return item
__init__函数里,获取配置文件里的mongo连接信息,连接mongo库
process_item函数里获取blogs.py里parse里yield返回的每一行,然后将数据入库 最后需要在setting取消注释pipelines.py页面运行的注释,不修改(pipelines.py页面代码可能无法正常调用)
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
最后在Terminal终端运行命令:scrapy crawl blogs
启用后便会开始进行抓取,结束后打开mongo客户端工具:库和表名创建的都是setting.py里配置的

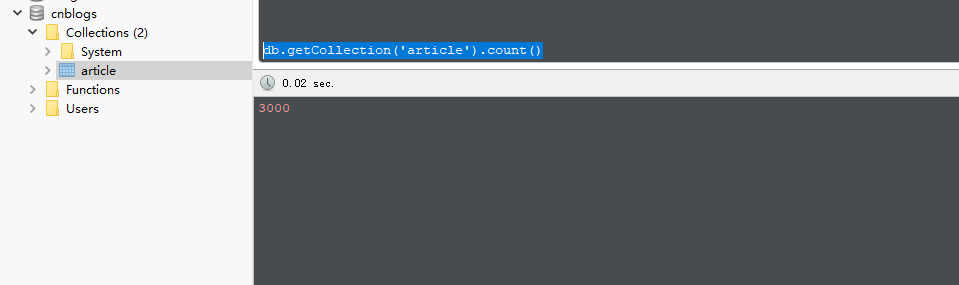
到此,3000条文章资讯数据一条不差的下载下来了
scrapy入门二(分页抓取文章入库)的更多相关文章
- Heritrix源码分析(九) Heritrix的二次抓取以及如何让Heritrix抓取你不想抓取的URL
本博客属原创文章,欢迎转载!转载请务必注明出处:http://guoyunsky.iteye.com/blog/644396 本博客已迁移到本人独立博客: http://www.yun5u ...
- Node.js 爬虫,自动化抓取文章标题和正文
持续进行中... 目标: 动态User-Agent模拟浏览器 √ 支持Proxy设置,避免被服务器端拒绝 √ 支持多核模式,发挥多核CPU性能 √ 支持核内并发模式 √ 自动解码非英文站点,避免乱码出 ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- 爬虫 - 动态分页抓取 游民星空 的资讯 - bs4
# coding=utf-8 # !/usr/bin/env python ''' author: dangxusheng desc : 动态分页抓取 游民星空 的资讯 date : 2018-08- ...
- python实现一个栏目的分页抓取列表页抓取
python实现一个栏目的分页抓取列表页抓取 #!/usr/bin/env python # coding=utf-8 import requests from bs4 import Beautifu ...
- Scrapy 使用CrawlSpider整站抓取文章内容实现
刚接触Scrapy框架,不是很熟悉,之前用webdriver+selenium实现过头条的抓取,但是感觉对于整站抓取,之前的这种用无GUI的浏览器方式,效率不够高,所以尝试用CrawlSpider来实 ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- 基于scrapy的分布式爬虫抓取新浪微博个人信息和微博内容存入MySQL
为了学习机器学习深度学习和文本挖掘方面的知识,需要获取一定的数据,新浪微博的大量数据可以作为此次研究历程的对象 一.环境准备 python 2.7 scrapy框架的部署(可以查看上一篇博客的简 ...
- [转]使用Scrapy建立一个网站抓取器
英文原文:Build a Website Crawler based upon Scrapy 标签: Scrapy Python 209人收藏此文章, 我要收藏renwofei423 推荐于 11个月 ...
随机推荐
- laravel 处理自定错误页面,如404,500,501,502,503,504等等
laravel 5.0 版本下,修改pp/Exceptions/Handler.phppublic function render($request, Exception $e) { if ($e i ...
- MT【76】直线系
解答 :答案是3,4.
- 【BZOJ1293】[SCOI2009]生日礼物(单调队列)
[BZOJ1293][SCOI2009]生日礼物(单调队列) 题面 BZOJ 洛谷 题解 离散之后随便拿单调队列维护一下就好了. #include<iostream> #include&l ...
- LANMP环境编译参数查看方法
nginx编译参数查看:/usr/local/nginx/sbin/nginx -V apache编译参数查看:cat /usr/local/apache2/build/config.nice mys ...
- SpringBoot中的定时任务与Quartz的整合
SpringBoot集成Quartz 定时任务Quartz : 就是在指定的时间执行一次或者循环执行,在项目的开发中有时候会需要的, 还是很有用的. SpringBoot内置的定时 添加依赖 < ...
- jQuery EasyUI API 中文文档 - 消息框(Messager)
http://www.cnblogs.com/Philoo/archive/2011/11/15/jeasyui_api_messager.html Messager 消息框 博客园 风流涕淌 (p ...
- 各种蕴含算法思想的DP - 3
内容中包含 base64string 图片造成字符过多,拒绝显示
- ubuntu下sublime Text3配置C++编译环境
今天在Ubuntu下用sublime Text3编译C++代码,环境配的不太顺利,下边展示一个实例. 1.主函数main.cpp #include <iostream> #include ...
- k8s pod的4种网络模式最佳实战(externalIPs )
[k8s]k8s pod的4种网络模式最佳实战(externalIPs ) hostPort相当于docker run -p 8081:8080,不用创建svc,因此端口只在容器运行的vm ...
- spectrogram函数做短时傅里叶分析
整理自:http://blog.sina.com.cn/s/blog_6163bdeb0102dwfw.html 今天偶人发现原来matlab自带了短时傅里叶变换的分析函数,老版本的matlab是sp ...