ConcurrentHashMap为了高并发而设计,相比于HashTable和HashMap有更多优势。HashTable是同步的,在多线程环境下,能保证程序执行的正确性,每次同步执行的时候都要锁住整个结构。HashMap不是同步的,在单线程情况下效率高。
ConcurrentHashMap锁方式是稍微细粒度的,内部采用分离锁的设计。它默认将Hash表分为16个分段,get,put,remove等常用操作只锁当前需要用到的分段。对于每个Segment,采用final和volatile关键字。
concurrenthashmap采用了二次hash的方式,第一次hash将key映射到对应的segment,而第二次hash则是映射到segment的不同桶中。
原来只能一个线程进入,现在却能同时16个写线程进入,写线程需要锁定,读线程几乎不受限制,并发性是显而易见的。只有size等操作才需要锁定整个表。
定义
ConcurrentHashMap继承AbstractMap,实现了ConcurrentMap,Serializable接口。ConcurrentMap继承了Map,添加了一些原子性方法,如putIfAbsent,remove,replace等。
数据结构
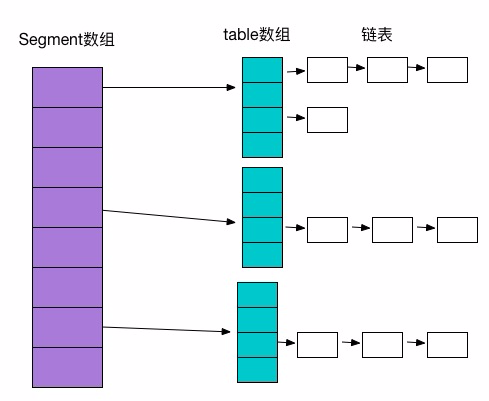
ConcurrentHashMap是由Segment数组结构,HashEntry数组结构和链表组成。Segment是可重入锁ReentrantLock,扮演锁角色。每个Segment的结构和HashMap类似,数组加链表存储结构。
HashEntry的key,hash采用final,可以避免并发修改问题,HashEntry链的尾部是不能修改的,而next和value采用volatile,可以避免使用同步造成的并发性能灾难。
Segment
Segment是ConcurrentHashMap的内部类,继承ReentrantLock,实现了Serializable接口。操作基本上都在Segment上,Segment中的table是一个HashEntry数组,数据就存放到这个数组中。看到这里对比下HashMap的存储结构,就大概能明白。具体方法在接下来的ConcurrentHashMap的具体方法中讲解。
初始化
ConcurrentHashMap初始化是通过initialCapacity,loadFactor,concurrencyLevel等参数来初始化Segment数组,段偏移量segmentShift,段掩码segmentMask和每个segment里的HashEntry数组。
1
public ConcurrentHashMap(int initialCapacity,
segments数组的长度ssize通过concurrencyLevel计算得出。为了能通过按位与的哈希算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。假如concurrencyLevel等于14,15或16,ssize都会等于16,即容器里锁的个数也是16。注意concurrencyLevel的最大大小是65535,意味着segments数组的长度最大为65536,对应的二进制是16位。
初始化segmentShift和segmentMask。
初始化每个Segment。输入参数initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个segment。
变量cap就是segment里HashEntry数组的长度,它等于initialCapacity除以ssize的倍数c,如果c大于1,就会取大于等于c的2的N次方值,所以cap不是1,就是2的N次方。segment的容量threshold=(int)cap*loadFactor,默认情况下initialCapacity等于16,loadfactor等于0.75,通过运算cap等于1,threshold等于零。
put(key,value)方法
1
public V put(K key, V value) {
Segment内部类中的put方法:
1
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
put操作开始,首先定位到Segment,为了线程安全,锁定当前Segment;然后在Segment里进行插入操作,首先判断是否需要扩容,然后在定位添加元素的位置放在HashEntry数组里。
扩容:在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
get(key)方法
1
public V get(Object key) {
size()方法
我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,我们是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是拿到之后可能累加前使用的count发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计size的时候把所有Segment的put,remove和clean方法全部锁住,但是这种做法显然非常低效。
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
迭代
ConcurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,我们称为弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出 ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数 据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变,更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。
源码分析
jdk1.7.0_71
1
//默认容量
Holder 静态内部类,存放一些在虚拟机启动后才能初始化的值
容量阈值,初始化hashSeed的时候会用到该值
1
static final int ALTERNATIVE_HASHING;
static静态块
1
获取系统变量jdk.map.althashing.threshold
ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) 构造
传入的参数有initialCapacity,loadFactor,concurrencyLevel这三个。
initialCapacity表示新创建的这个ConcurrentHashMap的初始容量,也就是上面的结构图中的Entry数量。默认值为static final int DEFAULT_INITIAL_CAPACITY = 16;
loadFactor表示负载因子,就是当ConcurrentHashMap中的元素个数大于loadFactor * 最大容量时就需要rehash,扩容。默认值为static final float DEFAULT_LOAD_FACTOR = 0.75f;
concurrencyLevel表示并发级别,这个值用来确定Segment的个数,Segment的个数是大于等于concurrencyLevel的第一个2的n次方的数。比如,如果concurrencyLevel为12,13,14,15,16这些数,则Segment的数目为16(2的4次方)。默认值为static final int DEFAULT_CONCURRENCY_LEVEL = 16;。理想情况下ConcurrentHashMap的真正的并发访问量能够达到concurrencyLevel,因为有concurrencyLevel个Segment,假如有concurrencyLevel个线程需要访问Map,并且需要访问的数据都恰好分别落在不同的Segment中,则这些线程能够无竞争地自由访问(因为他们不需要竞争同一把锁),达到同时访问的效果。这也是为什么这个参数起名为“并发级别”的原因。 初始化的一些动作:
验证参数的合法性,如果不合法,直接抛出异常。
concurrencyLevel也就是Segment的个数不能超过规定的最大Segment的个数,默认值为static final int MAX_SEGMENTS = 1 << 16;,如果超过这个值,设置为这个值。
然后使用循环找到大于等于concurrencyLevel的第一个2的n次方的数ssize,这个数就是Segment数组的大小,并记录一共向左按位移动的次数sshift,并令segmentShift = 32 - sshift,并且segmentMask的值等于ssize - 1,segmentMask的各个二进制位都为1,目的是之后可以通过key的hash值与这个值做&运算确定Segment的索引。
检查给的容量值是否大于允许的最大容量值,如果大于该值,设置为该值。最大容量值为static final int MAXIMUM_CAPACITY = 1 << 30;。
然后计算每个Segment平均应该放置多少个元素,这个值c是向上取整的值。比如初始容量为15,Segment个数为4,则每个Segment平均需要放置4个元素。
最后创建一个Segment实例,将其当做Segment数组的第一个元素。
1
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
ConcurrentHashMap(int initialCapacity, float loadFactor) 指定初始容量和负载因子
1
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
ConcurrentHashMap(int initialCapacity) 指定初始容量
1
public ConcurrentHashMap(int initialCapacity) {
ConcurrentHashMap(int initialCapacity) 空构造
1
public ConcurrentHashMap() {
1
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {}
isEmpty() 是否为空
1
//为了避免错误统计,会把每个segment的modCount都加起来进行判断
size() 返回大小
get(Object key) 根据key获取value
1
public V get(Object key) {}
containsKey(Object key) 是否包含key
1
public boolean containsKey(Object key) {}
containsValue(Object value) 是否包含value
1
//思路和size()相同
put(K key, V value)
1
public V put(K key, V value) {}
putIfAbsent(K key, V value) 如果不存在对应的key,就放进去
1
public V putIfAbsent(K key, V value) {}
1
public void putAll(Map<? extends K, ? extends V> m){}
remove(Object key) 删除
1
public V remove(Object key){}
remove(Object key, Object value)删除
1
public boolean remove(Object key, Object value){}
replace(K key, V oldValue, V newValue) 替换
1
public boolean replace(K key, V oldValue, V newValue) {}
replace(K key, V value) 替换
1
public V replace(K key, V value){}
clear() 清空
Segment (–重要–)
1
//最大的尝试加锁的次数
put(K key, int hash, V value, boolean onlyIfAbsent)
1
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
参考
http://my.oschina.net/indestiny/blog/209458
http://qifuguang.me/2015/09/10/[Java%E5%B9%B6%E5%8F%91%E5%8C%85%E5%AD%A6%E4%B9%A0%E5%85%AB]%E6%B7%B1%E5%BA%A6%E5%89%96%E6%9E%90ConcurrentHashMap/
http://www.importnew.com/20952.html
http://www.importnew.com/16147.html
javascript中的in运算符
in运算符希望它的左操作数是一个字符串或可以转换为字符串,希望他的又操作数是一个对象:如果右侧对象拥有一个名为左操作数值的属性名,那么表达式返回true: var point = {x:1,y:1}; ...
Python 3.7 将引入 dataclass 装饰器
简评:Python 3.7 将于今年夏天发布,Python 3.7 中将会有许多新东西,最激动人心的新功能之一是 dataclass 装饰器. 什么是 Data Class 大多数 Python 开发 ...
《转》iOS 平台 Cocos2d-x 项目接入新浪微博 SDK 的坑
最近在做一个 iOS 的 cocos2d-x 项目接入新浪微博 SDK 的时候被“坑”了,最后终于顺利的解决了.发现网上也有不少人遇到一样的问题,但是能找到的数量有限的解决办法写得都不详细,很难让人理 ...
快递单号查询免费api接口(PHP示例)
快递单号查询API,可以对接顺丰快递查询,邮政快递查询,中通快递查询等.这些快递物流企业,提供了快递单号自动识别接口,快递单号查询接口等快递物流服务.对于电商企业,ERP服务企业,集成此接口到自己的软 ...
search a 2D matrix(在二维数组中搜索一个元素)
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the follo ...
JSP指令与动作
Jsp基本指令和动作 (2011-08-18 16:25:13) 转载▼ 标签: 杂谈 分类: java JSP基本指令 jsp命令指令用来设置与整个jsp页面相关的属性,它并不直接产生任何可见的输出 ...
Hadoop的Python框架指南
http://www.oschina.NET/translate/a-guide-to-Python-frameworks-for-Hadoop 最近,我加入了Cloudera,在这之前,我在计算生物 ...
SOFA 源码分析— 自定义路由寻址
前言 SOFA-RPC 中对服务地址的选择也抽象为了一条处理链,由每一个 Router 进行处理.同 Filter 一样, SOFA-RPC 对 Router 提供了同样的扩展能力. 那么就看看 SO ...
Python黑客泰斗利用aircrack-ng破解 wifi 密码,超详细教程!
开始前,先连上无线网卡,因为虚拟机中的kali系统不用调用笔记本自带的无线网卡,所以需要一个外接无线网卡,然后接入kali系统. 输入 ifconfig -a 查看网卡,多了个 wlan0,说明网卡已 ...
「SQL归纳」树形结构表的存储与查询功能的实现——通过路径方法(非递归)
一.树形结构例子分析: 以360问答页面为例:http://wenda.so.com/c/ 我们通过观察URL,可以明确该页面的数据以树形结构存储,下面三块模块分别为: ①根节点 ②根节点的第一层子节 ...