复仇者联盟3热映,我用python爬取影评告诉你它都在讲什么
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象、直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句。
Python支持命令式程序设计、面向对象程序设计、函数式编程、面向切面编程、泛型编程多种编程范式。与Scheme、Ruby、Perl、Tcl等动态语言一样,Python具备垃圾回收功能,能够自动管理存储器使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller之类的工具可以将Python源代码转换成可以脱离Python解释器运行的程序。

《复仇者联盟3:无限战争》于 2018 年 5 月 11 日在中国大陆上映。截止 5 月 16 日,它累计票房达到 15.25 亿。这票房纪录已经超过了漫威系列单部电影的票房纪录。不得不说,漫威电影已经成为一种文化潮流。
先贴海报欣赏下:

图片来自时光网
复联 3 作为漫威 10 年一剑的收官之作。漫威确认下了很多功夫, 给我们奉献一部精彩绝伦的电影。自己也利用周末时间去电影院观看。看完之后,个人觉得无论在打斗特效方面还是故事情节,都是给人愉悦的享受。同时,电影还保持以往幽默搞笑的风格,经常能把观众逗得捧腹大笑。如果还没有去观看的朋友,可以去电影院看看,确实值得一看。
本文通过 Python 制作网络爬虫,爬取豆瓣电影评论,并分析然后制作豆瓣影评的云图。
1 分析
先通过影评网页确定爬取的内容。我要爬取的是用户名,是否看过,五星评论值,评论时间,有用数以及评论内容。
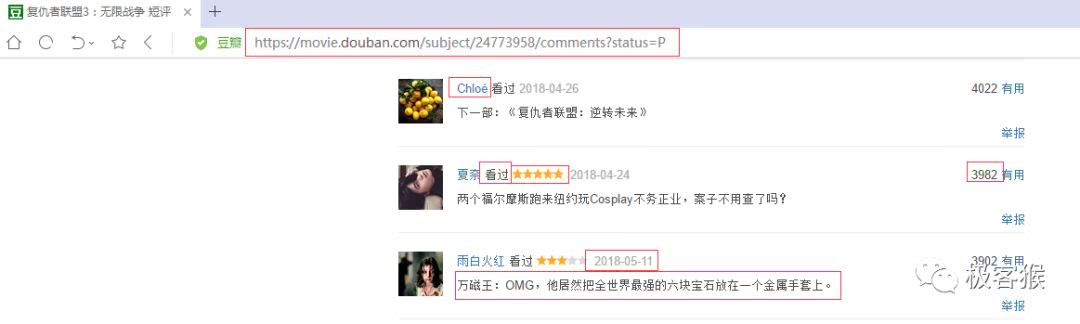
点击查看大图
然后确定每页评论的 url 结构。
第二页 url 地址:
点击查看大图第三页 url 地址:

点击查看大图
最后发现其中的规律:除了首页,后面的每页 url 地址中只有 start= 的值逐页递增,其他都是不变的。
2 数据爬取
本文爬取数据,采用的主要是 requests 库和 lxml 库中 Xpath。豆瓣网站虽然对网络爬虫算是很友好,但是还是有反爬虫机制。如果你没有设置延迟,一下子发起大量请求,会被封 IP 的。另外,如果没有登录豆瓣,只能访问前 10 页的影片。因此,发起爬取数据的 HTTP 请求要带上自己账号的 cookie。搞到 cookie 也不是难事,可以通过浏览器登录豆瓣,然后在开发者模式中获取。
python学习路线分三大阶段:基础-进阶-框架-项目实战
基础第一阶段:基础Python的理解。基础第二阶段面对对象编程(注重编程能力)
基础第三阶段面向对象“设计思想”-封装-继承。基础第四阶段python高级专题。
进阶班第一阶段:linux基础。第二:python web工具。第三python部署工具。
第四关系型数据库。第五Python web框架基础原理。
框架阶段.python web开发第一阶段web.py。基础第二Django基础。
第三flask基础。第四tornado基础,
项目实战:个人博客系统-微信开发-企业OA系统=网盘系统。
我想从影评首页开始爬取,爬取入口,然后依次获取页面中下一页的 url 地址以及需要爬取的内容,接着继续访问下一个页面的地址。
import jieba
import requests
import pandas as pd
import time
import random
from lxml import etree
def start_spider():
base_url = 'https://movie.douban.com/subject/24773958/comments'
start_url = base_url + '?start=0'
number = 1
html = request_get(start_url)
while html.status_code == 200:
# 获取下一页的 url
selector = etree.HTML(html.text)
nextpage = selector.xpath("//div[@id='paginator']/a[@class='next']/@href")
nextpage = nextpage[0]
next_url = base_url + nextpage
# 获取评论
comments = selector.xpath("//div[@class='comment']")
marvelthree = []
for each in comments:
marvelthree.append(get_comments(each))
data = pd.DataFrame(marvelthree)
# 写入csv文件,'a+'是追加模式
try:
if number == 1:
csv_headers = ['用户', '是否看过', '五星评分', '评论时间', '有用数', '评论内容']
data.to_csv('./Marvel3_yingpping.csv', header=csv_headers, index=False, mode='a+', encoding='utf-8')
else:
data.to_csv('./Marvel3_yingpping.csv', header=False, index=False, mode='a+', encoding='utf-8')
except UnicodeEncodeError:
print("编码错误, 该数据无法写到文件中, 直接忽略该数据")
data = []
html = request_get(next_url)

我在请求头中增加随机变化的 User-agent, 增加 cookie。最后增加请求的随机等待时间,防止请求过猛被封 IP。
def request_get(url):
'''
使用 Session 能够跨请求保持某些参数。
它也会在同一个 Session 实例发出的所有请求之间保持 cookie
'''
timeout = 3
UserAgent_List = [
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2226.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.4; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.93 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.2309.372 Safari/537.36",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.2117.157 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1866.237 Safari/537.36",
]
header = {
'User-agent': random.choice(UserAgent_List),
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/subject/24773958/?from=showing',
}
session = requests.Session()
cookie = {
'cookie': "你的 cookie 值",
}
time.sleep(random.randint(5, 15))
response = requests.get(url, headers=header, cookies=cookie_nologin, timeout = 3)
if response.status_code != 200:
print(response.status_code)
return response
最后一步就是数据获取:
def get_comments(eachComment):
commentlist = []
user = eachComment.xpath("./h3/span[@class='comment-info']/a/text()")[0] # 用户
watched = eachComment.xpath("./h3/span[@class='comment-info']/span[1]/text()")[0] # 是否看过
rating = eachComment.xpath("./h3/span[@class='comment-info']/span[2]/@title") # 五星评分
if len(rating) > 0:
rating = rating[0]
comment_time = eachComment.xpath("./h3/span[@class='comment-info']/span[3]/@title") # 评论时间
if len(comment_time) > 0:
comment_time = comment_time[0]
else:
# 有些评论是没有五星评分, 需赋空值
comment_time = rating
rating = ''
votes = eachComment.xpath("./h3/span[@class='comment-vote']/span/text()")[0] # "有用"数
content = eachComment.xpath("./p/text()")[0] # 评论内容
commentlist.append(user)
commentlist.append(watched)
commentlist.append(rating)
commentlist.append(comment_time)
commentlist.append(votes)
commentlist.append(content.strip())
# print(list)
return commentlist
3 制作云图
因为爬取出来评论数据都是一大串字符串,所以需要对每个句子进行分词,然后统计每个词语出现的评论。我采用jieba库来进行分词,制作云图,我则是将分词后的数据丢给网站worditout处理。
def split_word():
with codecs.open('Marvel3_yingpping.csv', 'r', 'utf-8') as csvfile:
reader = csv.reader(csvfile)
content_list = []
for row in reader:
try:
content_list.append(row[5])
except IndexError:
pass
content = ''.join(content_list)
seg_list = jieba.cut(content, cut_all=False)
result = ' '.join(seg_list)
print(result)
最后制作出来的云图效果是:

点击查看大图
"灭霸"词语出现频率最高,其实这一点不意外。因为复联 3 整部电影的故事情节大概是,灭霸在宇宙各个星球上收集 6 颗无限宝石,然后每个超级英雄为了防止灭霸毁灭整个宇宙,组队来阻止灭霸。

Python可以做什么?
web开发和 爬虫是比较适合 零基础的
自动化运维 运维开发 和 自动化测试 是适合 已经在做运维和测试的人员
大数据 数据分析 这方面 是很需要专业的 专业性相对而言比较强
科学计算 一般都是科研人员 在用
机器学习 和 人工智能 首先 学历 要求高 其次 高数要求高 难度很大
我有一个微信公众号,经常会分享一些python技术相关的干货;如果你喜欢我的分享,可以用微信搜索“python语言学习”关注
欢迎大家加入千人交流答疑群:588+090+942
复仇者联盟3热映,我用python爬取影评告诉你它都在讲什么的更多相关文章
- 用python爬取之后发现果然如此,都说知乎的小姐姐漂亮
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
随机推荐
- android传值
需求 OneActivity向TwoActivity传值name=hzs,然后TwoActivity向OneActivity传值sex=Y 第一步:OneActivity向TwoActivity传值n ...
- C#中的var和dynamic
在理解var和dynamic关键字之前,让我们先了解一下编程语言的类别. C#中有两类编程语言: 静态类型语言类别 动态语言类别 静态类型语言 静态类型语言也被称为强类型语言.所谓强类型语言,通俗的讲 ...
- JavaScript对象添加、删除、修改对象的属性
https://www.cnblogs.com/goweb/p/5357640.html 利用动态特性 function Person(){}; var person = new Person(); ...
- Day4_闭包含数
闭包函数: 闭包函数是在作用域的前提下 闭包含数:定义在函数内部的函数,包含对外部作用域名字的引用,而不是对全局作用域名字的引用,那么该内部函数就称为闭包含数. eg: x=1 def f1(): x ...
- svn path already exists的解决办法
这种问题的一般原因是这个path所指的目录在服务器端是一个空目录,对客户端不可见,客户端如果新建了这个目录,而且向服务器端commit的时候就会报错,服务器端此目录已存在,这个时候就会存在一个问题:就 ...
- Android设计开发笔记
1.因为Android的开发是基于框架的开发:往对方指定的位置加代码:其运行的Message\Handler机制也决定了其单步跟踪也不方便,所以建立新代码时要多Log,这样不但便于调试,而且帮助你加深 ...
- dp,px,pt,sp 的区别 以及dp 和 px 互转
dp = dip : device independent pixels(设备独立像素). 不同设备有不同的显示效果,这个和设备硬件有关,一般我们为了支持WVGA.HVGA和QVGA 推荐使用这个,不 ...
- Scala编程入门---数组操作之数组转换
使用yield和函数式编程转换数组 //对Array进行转换,获取的还是Aarry val a = Array(1,2,3,4,5) val a2 = for(ele <- a) yield e ...
- DevOps之四 Jenkins的安装与配置
CentOS 上 Jenkins 安装 一.添加yum repos,然后安装 sudo wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins ...
- mybatis源码解读(五)——sql语句的执行流程
还是以第一篇博客中给出的例子,根据代码实例来入手分析. static { InputStream inputStream = MybatisTest.class.getClassLoader().ge ...