浅析git
git是什么
简单来说,Git,它是一个快速的 分布式版本控制系统 (Distributed Version Control System,简称 DVCS) 。
同传统的 集中式版本控制系统 (Centralized Version Control Systems,简称CVCS) 不同,Git的分布式特性使得开发者间的协作变得更加灵活多样。
这时候我们会想到:
- 什么又是版本控制呢?
- 什么是分布式什么是集中式?
我们带着问题往下走。
版本控制
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
比如:有一位程序员他可能需要保存一个代码文件的所有的修订版本,这样就可以
- 将某个文件回溯到之前的状态
- 甚至将整个项目都回退到过去某个时间点的状态
- 比较文件的变化细节,查出最后是谁修改了哪个地方,从而找出导致怪异问题出现的原因
这时候采用版本控制就是一个非常明智的选择,使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改的改删的删,你也照样可以轻松恢复到原先的样子。 但额外增加的工作量却微乎其微。
版本控制的成长
儿童:人们通过复制整个项目的方式来保存不同的版本,或许还会改名加上备份时间以示区别。好处就是简单,但是特别容易犯错,一不小心会写错文件或者覆盖意想外的文件。
少年:人们为了上面的问题,很久以前就开发了许多种本地版本控制系统,大多是采用某种简单的数据库来记录文件的历次更新差异,比如其中比较流行的 RCS 。
青年:人们又遇到一个问题,如何让在不同系统上的开发者协同工作? 于是,集中化的版本控制系统( CVCS)应运而生。 这类系统,诸如 CVS 、 Subversion ,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。现在,每个人都可以在一定程度上看到项目中的其他人正在做些什么。 而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS。
事分两面,有好有坏。 这么做最显而易见的缺点是中央服务器的单方面故障。 如果关机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。 如果中心数据库所在的磁盘发生损坏,又没有做恰当备份,毫无疑问你将丢失所有数据——包括项目的整个变更历史,只剩下人们在各自机器上保留的单独快照。
壮年:于是分布式版本控制系统面世了。 在这类系统中,像 Git 、 Mercurial 等,客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
许多这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。 你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
git诞生史记
很多人都知道, Linus 在1991年创建了开源的 Linux ,从此,Linux 系统不断发展,已经成为最大的服务器系统软件了。
Linus 虽然创建了 Linux,但 Linux 的壮大是靠全世界热心的志愿者参与的,这么多人在世界各地为 Linux 编写代码,那 Linux 的代码是如何管理的呢?
事实是,在2002年以前,世界各地的志愿者把源代码文件通过 diff 的方式发给 Linus,然后由 Linus 本人通过手工方式合并代码!
你也许会想,为什么 Linus 不把 Linux 代码放到版本控制系统里呢?不是有 CVS、SVN这些免费的版本控制系统吗?因为 Linus 坚定地反对 CVS 和 SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比 CVS 、 SVN 好用,但那是付费的,和 Linux 的开源精神不符。
不过,到了2002年,Linux 系统已经发展了十年了,代码库之大让 Linus 很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是 Linus 选择了一个商业的版本控制系统 BitKeeper,BitKeeper 的东家 BitMover 公司出于人道主义精神,授权 Linux 社区免费使用这个版本控制系统。
安定团结的大好局面在2005年就被打破了,原因是 Linux 社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发 Samba 的 Andrew 试图破解 BitKeeper 的协议(这么干的其实也不只他一个),被 BitMover 公司发现了(监控工作做得不错!),于是 BitMover 公司怒了,要收回 Linux 社区的免费使用权。
Linus 可以向 BitMover 公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是这样的:
Linus 花了两周时间自己用 C 写了一个分布式版本控制系统,这就是 Git!一个月之内,Linux 系统的源码已经由 Git 管理了!牛是怎么定义的呢?大家可以体会一下。
Git 迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub 网站上线了,它为开源项目免费提供 Git 存储,无数开源项目开始迁移至 GitHub,包括 jQuery,PHP,Ruby等等。
历史就是这么偶然,如果不是当年 BitMover 公司威胁 Linux 社区,可能现在我们就没有免费而超级好用的 Git 了。
git的优点
在集中式系统中,每个开发者就像是连接在集线器上的节点,彼此的工作方式大体相像。 而在 Git 中,每个开发者同时扮演着节点和集线器的角色——也就是说,每个开发者既可以将自己的代码贡献到其他的仓库中,同时也能维护自己的公开仓库,让其他人可以在其基础上工作并贡献代码。 由此,Git 的分布式协作可以为你的项目和团队衍生出种种不同的工作流程。
速度快
简单的设计,易用
对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
完全分布式
有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
git实现原理
从根本上来讲 Git 是一个内容寻址 (content-addressable) 文件系统,并在此之上提供了一个版本控制系统的用户界面,Git 的核心部分是一个简单的键值对数据库 (key-value data store) 。 你可以向该数据库插入任意类型的内容,它会返回一个键值,通过该键值可以在任意时刻再次检索 (retrieve) 该内容。
初始化的git目录
当在一个新目录或已有目录执行 git init 时,Git 会创建一个 .git 目录。 这个目录包含了几乎所有 Git 存储和操作的对象。 如若想备份或复制一个版本库,只需把这个目录拷贝至另一处即可。
$ ls -F1
HEAD
config*
description
hooks/
info/
objects/
refs/
这是一个全新的 git init 版本库,这将是你看到的默认结构。
description文件仅供GitWeb程序使用,我们无需关心。config文件包含项目特有的配置选项。info目录包含一个全局性排除(global exclude)文件,用以放置那些不希望被记录在.gitignore文件中的忽略模式(ignored patterns)。hooks目录包含客户端或服务端的钩子脚本(hook scripts)。objects目录存储所有数据内容。refs目录存储指向数据(分支)的提交对象的指针HEAD文件指示目前被检出的分支index文件保存暂存区信息。
git对象模型
所有用来表示项目历史信息的文件,是通过一个40个字符的 (40-digit) “对象名”来索引的,对象名看起来像这样:
6ff87c4664981e4397625791c8ea3bbb5f2279a3
你会在Git里到处看到这种“40个字符”字符串。每一个“对象名”都是对“对象”内容做 SHA1 哈希计算得来的,( SHA1 是一种密码学的哈希算法)。这样就意味着两个不同内容的对象不可能有相同的“对象名”。
这样做会有几个好处:
Git只要比较对象名,就可以很快的判断两个对象是否相同。- 因为在每个仓库
(repository)的“对象名”的计算方法都完全一样,如果同样的内容存在两个不同的仓库中,就会存在相同的“对象名”下。 Git还可以通过检查对象内容的SHA1的哈希值和“对象名”是否相同,来判断对象内容是否正确。
对象
每个对象 (object) 包括三个部分:类型,大小和内容。大小就是指内容的大小,内容取决于对象的类型,有四种类型的对象:"blob" 、 "tree" 、 "commit" 和 "tag" 。
“blob”用来存储文件数据,通常是一个文件。“tree”有点像一个目录,它管理一些“tree”或是 “blob”(就像文件和子目录)。一个
“commit”只指向一个"tree",它用来标记项目某一个特定时间点的状态。它包括一些关于时间点的元数据,如时间戳、最近一次提交的作者、指向上次提交(commits)的指针等等。一个
“tag”是来标记某一个提交(commit)的方法。
几乎所有的 Git 功能都是使用这四个简单的对象类型来完成的。它就像是在你本机的文件系统之上构建一个小的文件系统。
Blob对象
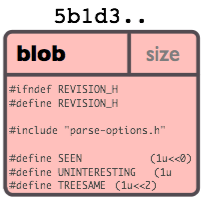
一个 blob 通常用来存储文件的内容。
Tree 对象

一个 tree 对象可以指向一个包含文件内容的 blob 对象, 也可以是其它包含某个子目录内容的其它 tree 对象,它一般用来表示内容之间的目录层次关系。 Tree 对象、blob 对象和其它所有的对象一样,都用其内容的 SHA1 哈希值来命名的;只有当两个 tree 对象的内容完全相同(包括其所指向所有子对象)时,它的名字才会一样,反之亦然。这样就能让Git 仅仅通过比较两个相关的 tree 对象的名字是否相同,来快速的判断其内容是否不同。
Commit对象
commit 对象指向一个 tree 对象,并且带有相关的描述信息。

一个提交 commit 由以下的部分组成:
一个
tree对象:tree对象的 `SHA1签名, 代表着目录在某一时间点的内容。父对象
(parent(s)): 提交(commit)的SHA1签名代表着当前提交前一步的项目历史。合并的提交(merge commits)可能会有不只一个父对象。如果一个提交没有父对象,那么我们就叫它“根提交"(root commit),它就代表着项目最初的一个版本(revision)。 每个项目必须有至少有一个“根提交"(root commit)。作者
(author):做了此次修改的人的名字,还有修改日期。提交者
(committer):实际创建提交(commit)的人的名字, 同时也带有提交日期。注释:用来描述此次提交。
注意:一个提交(commit)本身并没有包括任何信息来说明其做了哪些修改; 所有的修改(changes)都是通过与父提交(parents)的内容比较而得出的。 值得一提的是, 尽管git可以检测到文件内容不变而路径改变的情况, 但是它不会去显式(explicitly)的记录文件的更名操作(可以看一下 git diff )。
一般用 git commit 来创建一个提交 (commit), 这个提交 (commit) 的父对象一般是当前分支 (current HEAD) ,同时把存储在当前索引 (index) 的内容全部提交。
对象模型:
如果我们把它提交 (commit) 到一个 Git 仓库中, 在 Git 中它们也许看起来就如下图:
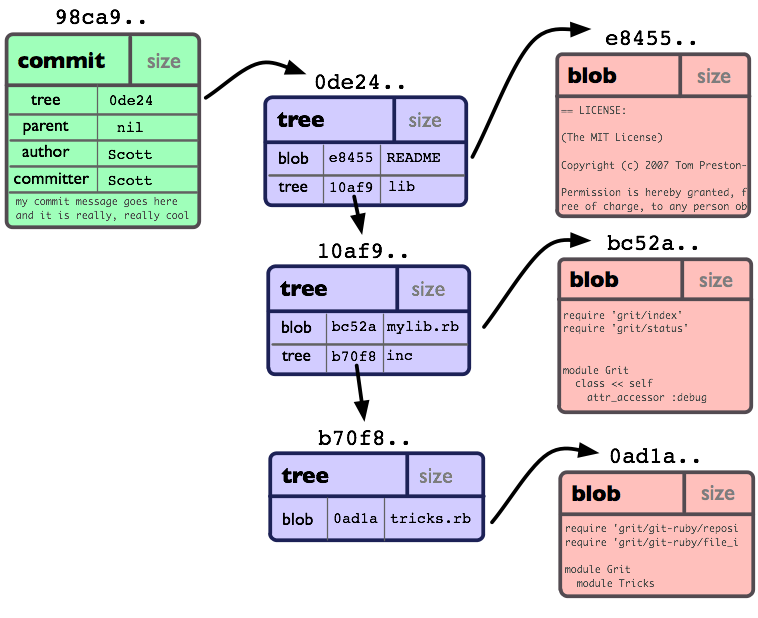
你可以看到:每个目录都创建了 tree对象 (包括根目录), 每个文件都创建了一个对应的 blob对象。最后有一个 commit 对象 来指向根 tree 对象 (root of trees) , 这样我们就可以追踪项目每一项提交内容.
标签对象:
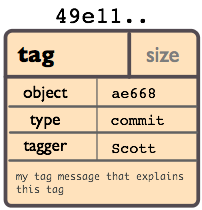
一个标签对象包括一个对象名(SHA1签名), 对象类型, 标签名, 标签创建人的名字(tagger), 还有一条可能包含有签名(signature)的消息.
回到我们的问题
强大的git分支
有人把 Git 的分支模型称为它的必杀技特性,也正因为这一特性,使得它 从众多版本控制系统中脱颖而出。
Git 保存的不是文件的变化或者差异,而是一系列不同时刻的文件快照。
在进行提交操作时,Git 会保存一个提交对象(commit object)。知道了 Git 保存数据的方式,该提交对象会包含一个指向暂存内容快照的指针。 但不仅仅是这样,该提交对象还包含了作者的姓名和邮箱、提交时输入的信息以及指向它的父对象的指针。首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象,而由多个分支合并产生的提交对象有多个父对象,
当使用 git commit 新建一个提交对象前,Git 会先计算每一个子目录的校验和(40 个字符长度 SHA-1 字串),然后在 Git 仓库中将这些目录保存为树(tree)对象。之后 Git 创建的提交对象,除了包含相关提交信息以外,还包含着指向这个树对象(项目根目录)的指针,如此它就可以在将来需要的时候,重现此次快照的内容了。
Git 中的分支,其实本质上仅仅是个指向 commit 对象的可变指针。Git 会使用 master 作为分支的默认名字。在若干次提交后,你其实已经有了一个指向最后一次提交对象的 master 分支,它在每次提交的时候都会自动向前移动。
Git 是如何知道你当前在哪个分支上工作的呢?其实答案也很简单,它保存着一个名为 HEAD 的特别指针。在 Git 中,它是一个指向你正在工作中的本地分支的指针,我们可以将 HEAD 想象为当前分支的别名。
由于 Git 中的分支实际上仅是一个包含所指对象校验和的文件,所以创建和销毁一个分支就变得非常廉价。说白了,新建一个分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,当然也就很快了。
大多数版本控制系统它们管理分支大多采取备份所有项目文件到特定目录的方式,所以根据项目文件数量和大小不同,可能花费的时间也会有相当大的差别,快则几秒,慢则数分钟。
而 Git 的实现与项目复杂度无关,它永远可以在几毫秒的时间内完成分支的创建和切换。同时,因为每次提交时都记录了祖先信息(parent 对象),将来要合并分支时,寻找恰当的合并基础(译注:即共同祖先)的工作其实已经自然而然地摆在那里了,所以实现起来非常容易。Git 鼓励开发者频繁使用分支,正是因为有着这些特性作保障。
分支的新建与合并
- 新建分支并进入
$ git checkout -b iss53
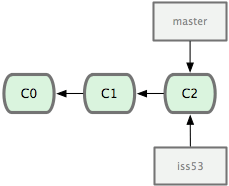
- 根据需求写代码并提交
$ git commit -a -m 'new text'
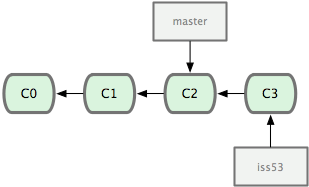
- 接到线上问题需要并且修改bug
$ git checkout master
$ git checkout -b hotfix
$ git commit -a -m 'fixed bug'
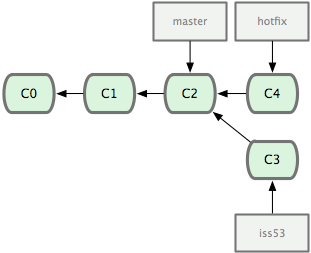
- 合并修改完bug的代码进master(暂无冲突)
$ git checkout master
$ git merge hotfix
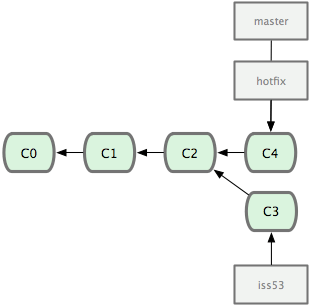
- 解决问题后删除hotfix分支并返回原来的iss53分支继续工作
$ git branch -d hotfix
$ git checkout iss53
$ git commit -a -m 'finished'
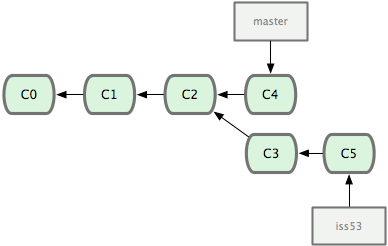
- 合并iss53分支进主分支
$ git checkout master
$ git merge iss53
请注意,这次合并操作的底层实现,并不同于之前 hotfix 的并入方式。因为这次你的开发历史是从更早的地方开始分叉的。由于当前 master 分支所指向的提交对象(C4)并不是 iss53 分支的直接祖先,Git 不得不进行一些额外处理。就此例而言,Git 会用两个分支的末端(C4 和 C5)以及它们的共同祖先(C2)进行一次简单的三方合并计算。
这次,Git 没有简单地把分支指针右移,而是对三方合并后的结果重新做一个新的快照,并自动创建一个指向它的提交对象(C6)。这个提交对象比较特殊,它有两个祖先(C4 和 C5)。
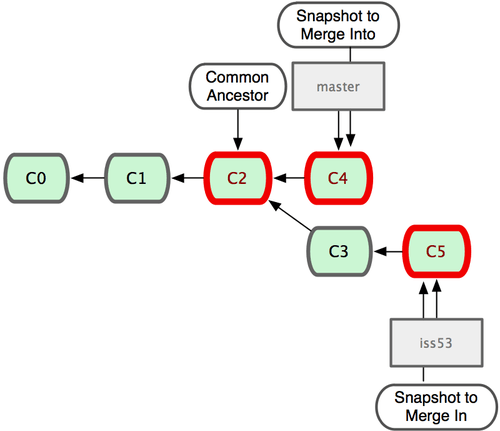
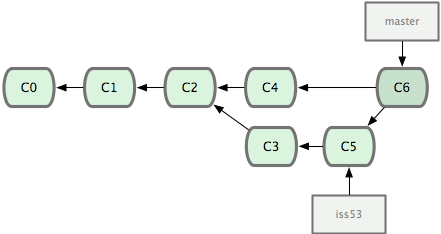
有时候合并操作并不会如此顺利。如果在不同的分支中都修改了同一个文件的同一部分,Git 就无法干净地把两者合到一起。如果你在解决问题 #53 的过程中修改了 hotfix 中修改的部分,将会出现问题。
Git 作了合并,但没有提交,它会停下来等你解决冲突。
任何包含未解决冲突的文件都会以未合并 unmerged 的状态列出。Git 会在有冲突的文件里加入标准的冲突解决标记,可以通过它们来手工定位并解决这些冲突。
rebase 变基
最容易的整合分支的方法是 merge 命令,它会把两个分支最新的快照(C3 和 C4)以及二者最新的共同祖先(C2)进行三方合并,合并的结果是产生一个新的提交对象(C5)。:
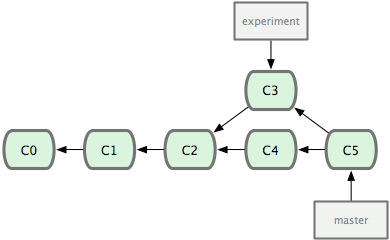
但是,如果你想让 experiment分支历史看起来像没有经过任何合并一样,还有另外一个选择:你可以把在 C3 里产生的变化补丁在 C4 的基础上重新打一遍。在 Git 里,这种操作叫做变基 (rebase)。有了 rebase 命令,就可以把在一个分支里提交的改变移到另一个分支里重放一遍。
$ git checkout experiment
$ git rebase master
它的原理是回到两个分支最近的共同祖先,根据当前分支(也就是要进行变基的分支 experiment )后续的历次提交对象(这里只有一个 C3),生成一系列文件补丁,然后以基底分支(也就是主干分支 master)最后一个提交对象(C4)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成一个新的合并提交对象(C3'),从而改写 experiment 的提交历史,使它成为 master 分支的直接下游
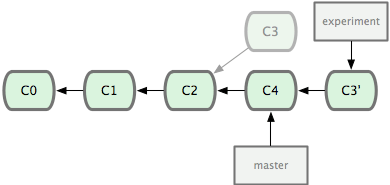
简单讲他就是把你的 experiment 分支里的每个提交 commit 取消掉,并且把它们临时 保存为补丁 patch (这些补丁放到".git/rebase"目录中),然后把 experiment 分支更新 到最新的 origin 分支,最后把保存的这些补丁应用到 experiment 分支上。
现在的 C3' 对应的快照,其实和普通的三方合并,即上个例子中的 C5 对应的快照内容一模一样了。虽然最后整合得到的结果没有任何区别,但变基能产生一个更为整洁的提交历史。如果视察一个变基过的分支的历史记录,看起来会更清楚:仿佛所有修改都是在一根线上先后进行的,尽管实际上它们原本是同时并行发生的。
在 rebase 的过程中,也许会出现冲突 conflict。在这种情况,Git 会停止 rebase 并会让你去解决 冲突;在解决完冲突后,用 git-add 命令去更新这些内容的索引 index, 然后,你无需执行 git-commit ,只要执行:
$ git rebase --continue
这样git会继续应用 apply 余下的补丁。在任何时候,你可以用 --abort 参数来终止 rebase 的行动,并且 experiment 分支会回到 rebase 开始前的状态。
$ git rebase --abort
git merge 应该只用于为了保留一个有用的,语义化的准确的历史信息,而希望将一个分支的整个变更集成到另外一个 branch 时使用 rebase。这样形成的清晰版本变更图有着重要的价值。
所有其他的情况都是以不同的方式使用 rebase 的适合场景:经典型方式,三点式,interactive 和 cherry-picking。
我们使用变基的目的:是想要得到一个能在远程分支上干净应用的补丁 — 比如某些项目你不是维护者,但想帮点忙的话,最好用变基:先在自己的一个分支里进行开发,当准备向主项目提交补丁的时候,根据最新的 origin/master 进行一次变基操作然后再提交,这样维护者就不需要做任何整合工作(实际上是把解决分支补丁同最新主干代码之间冲突的责任,化转为由提交补丁的人来解决。),只需根据你提供的仓库地址作一次快进合并,或者直接采纳你提交的补丁。
需要注意,合并结果中最后一次提交所指向的快照,无论是通过变基,还是三方合并,都会得到相同的快照内容,只不过提交历史不同罢了。变基是按照每行的修改次序重演一遍修改,而合并是把最终结果合在一起。
有趣的变基
我在不同的topic之间来回切换,这样会导致我的历史中不同topic互相交叉,逻辑上组织混乱;
我们可能需要多个连续的commit来解决一个bug;
我可能会在commit中写了错别字,后来又做修改;
甚至我们在一次提交时纯粹就是因为懒惰的原因,我可能吧很多的变更都放在一个commit中做了提交。
rebase可以合并commit
rebase可以用来修改commit信息
rebase可以用来拆分commit
git rebase -i HEAD~3
变基也可以放到其他分支进行,并不一定非得根据分化之前的分支。
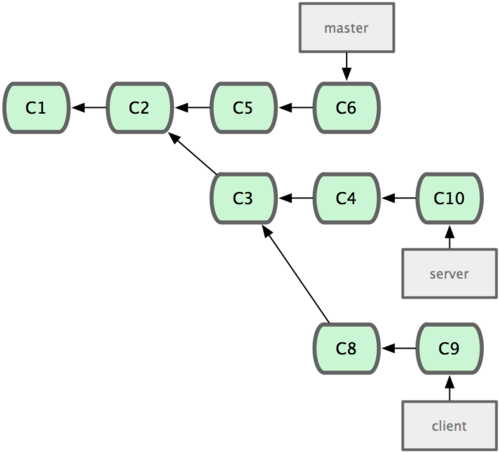
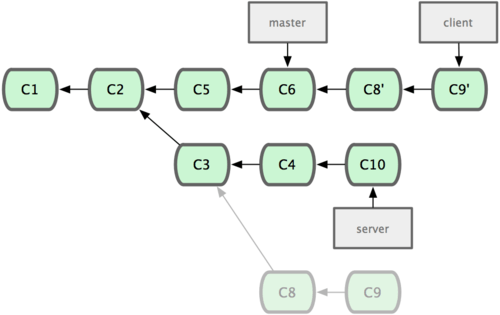
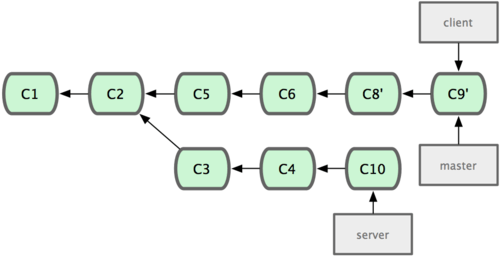
变基的风险
要用它得遵守一条准则:
不要在公共分支上使用rebase。
“No one shall rebase a shared branch” — Everyone about rebase
如果你遵循这条金科玉律,就不会出差错。
在进行变基的时候,实际上抛弃了一些现存的提交对象而创造了一些类似但不同的新的提交对象。如果你把原来分支中的提交对象发布出去,并且其他人更新下载后在其基础上开展工作,而稍后你又用 git rebase 抛弃这些提交对象,把新的重演后的提交对象发布出去的话,你的合作者就不得不重新合并他们的工作,这样当你再次从他们那里获取内容时,提交历史就会变得一团糟。
注意rebase往往会重写历史,所有已经存在的commits虽然内容没有改变,但是commit本身的hash都会改变。
结论:只要你的分支上需要rebase的所有commits历史还没有被push过(比如上例中rebase时从分叉处开始有两个commit历史会被重写),就可以安全地使用git rebase来操作。
上述结论可能还需要修正:对于不再有子分支的branch,并且因为rebase而会被重写的commits都还没有push分享过,可以比较安全地做rebase
思考下它的功能吧 git pull --rebase
浅析git的更多相关文章
- Git那些事儿
Git是目前世界上最先进的分布式版本控制系统,适合多人协作开发的大型项目.我平常也经常使用git,来管理自己的几个小项目.简单说说git的原理和git的特点!(只有知道了一个工具的运行原理,设计思路, ...
- Android源码浅析(二)——Ubuntu Root,Git,VMware Tools,安装输入法,主题美化,Dock,安装JDK和配置环境
Android源码浅析(二)--Ubuntu Root,Git,VMware Tools,安装输入法,主题美化,Dock,安装JDK和配置环境 接着上篇,上片主要是介绍了一些安装工具的小知识点Andr ...
- IDEA环境下GIT操作浅析之二-idea下分支操作相关命令
上次写到<idea下仓库初始化与文件提交涉及到的基本命令>,今天我们继续写IDEA环境下GIT操作之二--idea下分支操作相关命令以及分支创建与合并. 1.idea 下分支操作相关命令 ...
- IDEA环境下GIT操作浅析之一Idea下仓库初始化与文件提交涉及到的基本命令
目标总括 idea 下通过命令操作文件提交,删除,与更新并推送到github 开源库基本操作idea 下通过命令实现分支的创建与合并操作 idea 下通过图形化方式实现idea 项目版本控制基本操作 ...
- [转帖]Git数据存储的原理浅析
Git数据存储的原理浅析 https://segmentfault.com/a/1190000016320008 写作背景 进来在闲暇的时间里在看一些关系P2P网络的拓扑发现的内容,重点关注了Ma ...
- eclipse上的git命令使用浅析,搭建Maven项目
eclipse上的git命令使用浅析 2016-03-31 14:44 关于eclipse上git的安装和建立代码仓库的文章比较多,但作为一个初识git的人更希望了解每个命令的作用. 当项目连接到 ...
- Git浅析
Git浅析 索引 Git的常用命令 GitHub的使用 Git版本创建和回退 Git的工作区和暂存区 Git分支管理 1-Git的常用命令 01.创建一个版本库--进入相应的目录 git init 可 ...
- Mac上使用jenkins+git持续集成浅析
本文旨在让同学们明白如何让jenkis在mac笔记本上运行,并实际与一个最简单的git地址交互并执行简单的jenkins任务,如果学习本文,需要先按照https://www.cnblogs.com/x ...
- Git内部原理浅析
Git独特之处 Git是一个分布式版本控制系统,首先分布式意味着Git不仅仅在服务端有远程仓库,同时会在本地也保留一个完整的本地仓库(.git/文件夹),这种分布式让Git拥有下面几个特点: 1.直接 ...
随机推荐
- 存个emacs配置
emacs配置 (global-set-key [f9] 'compile-file) (global-set-key [f10] 'gud-gdb) (global-set-key (kbd &qu ...
- centos 配置 php 执行shell的权限
在执行特定的shell命令,如 kill,killall 等需要配置root权限 php脚本运行在apache服务器下 可以看到 httpd 是以 apache 用户执行的 看一下 该用户信息 现在 ...
- Deep Learning for Information Retrieval
最近关注了一些Deep Learning在Information Retrieval领域的应用,得益于Deep Model在对文本的表达上展现的优势(比如RNN和CNN),我相信在IR的领域引入Dee ...
- 项目构建工具Maven
- Apache和Tomcat的区别与联系
作者:郭无心链接:https://www.zhihu.com/question/37155807/answer/72706896来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- js的继承实现
1.原型链继承 1.创建父类对象2.创建子类函数对象3.将父类的实例对象赋值给子类的原型4.将子类的原型属性的构造函数设置为 子类本身 function Person(name) { this.nam ...
- keras初涉笔记【一】
安装keras依赖的库 sudo pip install numpy sudo pip install scipy sudo pip installl pyyaml sudo pipi install ...
- 机器学习策略——DeepLearning.AI课程总结
一.什么是ML策略 假设你正在训练一个分类器,你的系统已经达到了90%准确率,但是对于你的应用程序来说还不够好,此时你有很多的想法去继续改善你的系统: 收集更多训练数据 训练集的多样性不够,收集更多的 ...
- Redis持久化存储
Redis是一个支持持久化的内存数据库,也就是说redis需要经常将内存中的数据同步到磁盘来保证持久化.redis支持四种持久化方式,一是 Snapshotting(快照)也是默认方式:二是Appen ...
- Linux CentOS7下安装python3
在CentOS7下,默认安装的就是python2.7,我现在来教大家如何安装python3: 1.首先安装python3.6可能使用的依赖 # yum -y install openssl-devel ...