ConcurrentHashMap、CopyOnWriteArrayList、LinkedHashMap
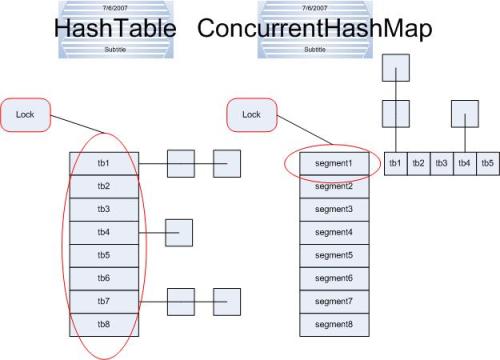
HashMap中未进行同步考虑,而Hashtable在每个方法上加上了synchronized,锁住了整个Hash表,一个时刻只能有一个线程操作,其他的线程则只能等待,在并发的环境下,这样的操作导致Hashtable的效率低下。
Collections的静态方法synchronizedMap(HashMap hm)返回的是一个SynchronizedMap对象,SynchronizedMap也是对原HashMap中的方法加上synchronized,锁的粒度应该减小。
ConcurrentHashMap的get读操作中基本没有用到锁,可以看下面的代码:
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
当读到的value是null时,处理是return readValueUnderLock(e);,因为整个的操作未加锁,上面的if (v != null)为false时,可能同时有其他线程修改了value的值,这里有进行一次同步的取值,如下:
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
size读操作为了确保读的数据是准确的也进行了部分的加锁操作。
写后读或者读后写都会造成数据的不一致,即使用线程安全类,应该做好对象的加锁。
ConcurrentHashMap的写操作锁住了Segment
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
下面是针对Segment的写操作:
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
CopyOnWriteArrayList应用于读多写少的场景,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
CopyOnWriteArrayList应用于读多写少的场景,在有较多写操作的情况下,CopyOnWriteArrayList性能不佳,而且如果容器容量较大的话容易造成溢出,应该使用Vector。使用ReadWriteLock是另外一种思路。
下面是的CopyOnWriteArrayList的set操作:
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
Arrays.copyOf创建一个新的数组,在新数组上做了修改后将新数组的引用赋给原对象。
private transient volatile Object[] array;
final void setArray(Object[] a) {
array = a;
}
set方法中的
else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
元素都没有发生变化,为什么还要重新做一次赋值操作呢。
为了保持“volatile”的语义,任何一个读操作都应该是一个写操作的结果,也就是说线程的读操作看到的数据一定是某个线程写操作的结果。这里即使不设置也没有问题,仅仅是为了一个语义上的补充。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
LinkedHashMap中的Entry是这样的,维护了before Entry和after Entry。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
ConcurrentHashMap、CopyOnWriteArrayList、LinkedHashMap的更多相关文章
- Collections.synchronizedList 、CopyOnWriteArrayList、Vector介绍、源码浅析与性能对比
## ArrayList线程安全问题 众所周知,`ArrayList`不是线程安全的,在并发场景使用`ArrayList`可能会导致add内容为null,迭代时并发修改list内容抛`Concurre ...
- 【Java】Map杂谈,hashcode()、equals()、HashMap、TreeMap、LinkedHashMap、ConcurrentHashMap
参考的优秀文章: <Java编程思想>第四版 <Effective Java>第二版 Map接口是映射表的结构,维护键对象与值对象的对应关系,称键值对. > hashco ...
- HashMap、LinkedHashMap、ConcurrentHashMap、ArrayList、LinkedList 底层实现
HashMap相关问题 1.你用过HashMap吗?什么是HashMap?你为什么用到它? 用过,HashMap是基于哈希表的Map接口的非同步实现,它允许null键和null值,且HashMap依托 ...
- 牛客网Java刷题知识点之Map的两种取值方式keySet和entrySet、HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 003-jdk-数据结构-HashMap、HashTable、ConcurrentHashMap、TreeMap、LinkedHashMap、Set
一.Map概述 Map:“键值”对映射的抽象接口.该映射不包括重复的键,一个键对应一个值. 1.1.HashTable[不常用] 基于“拉链法”实现的散列表. 底层数组+链表实现,无论key还是val ...
- java面试记录三:hashmap、hashtable、concurrentHashmap、ArrayList、linkedList、linkedHashmap、Object类的12个成员方法、消息队列MQ的种类
口述题 1.HashMap的原理?(数组+单向链表.put.get.size方法) 非线程安全:(1)hash冲突:多线程某一时刻同时操作hashmap并执行put操作时,可能会产两个key的hash ...
- hashMap、ConcurrentHashMap、hashTable、TreeMap、LinkedHashMap用法区别详解
Java集合中设计了一个接口Java.util.Map,它实现类中hashMap.hashTable.TreeMap.ConcurrentHashMap.LinkedHashMap. Map类型的集合 ...
- Hashtable、synchronizedMap、ConcurrentHashMap 比较
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcytp18 Hashtable.synchronizedMap.Concurren ...
- HashMap、Hashtable、 LinkedHashMap、TreeMap四者之分。
java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HasMap.Hashtable.LinkedHasmap和TreeMap. (1)HashMa ...
随机推荐
- [bzoj1500 维修数列](NOI2005) (splay)
真的是太弱了TAT...光是把代码码出来就花了3h..还调了快1h才弄完T_T 号称考你会不会splay(当然通过条件是1h内AC..吓傻)... 黄学长的题解:http://hzwer.com/28 ...
- 换行符 '\n' 和 回车符 '\r' 的区别?
顾名思义: 换行符就是另起一新行,光标在新行的开头: 回车符就是光标回到一旧行的开头:(即光标目前所在的行为旧行) ------------------------------------------ ...
- 如何使用padlepadle 进行意图识别-开篇
前言 意图识别是通过分类的办法将句子或者我们常说的query分到相应的意图种类.举一个简单的例子,我想听周杰伦的歌,这个query的意图便是属于音乐意图,我想听郭德纲的相声便是属于电台意图.做好了意图 ...
- Linux怎么查看软件安装路径 查看mysql安装在哪
https://jingyan.baidu.com/article/86112f1378bf282737978730.html Linux系统一般都是命令行界面,对于安装的软件也是通过命令安装的.对于 ...
- WOW.js – 让页面滚动更有趣
演示1 演示2-仿oppo首页 下载 简介 有的页面在向下滚动的时候,有些元素会产生细小的动画效果.虽然动画比较小,但却能吸引你的注意.比如刚刚发布的 iPhone 6 的页面(查看).如果你希望你的 ...
- FileZilla出现Failed to convert command to 8 bit charset
FileZilla这款FTP客户端软件,自从华哥使用以来,采用其默认的设置,一直用得很顺畅,没有出现过什么问题.但是今天碰到了一个问题.如图. 错误信息为:Failed to convert comm ...
- 【开发技术】java中代码检查checkStyle结果分析
编写Javadoc代码在Java代码的类.函数.数据成员前中输入/**回车,Eclipse能够自动生成相应的Javadoc代码.可以在后面添加相关的文字说明. Type is missing a ja ...
- servlet入门学习之生命周期
一. 什么是Servlet Servlet是用Java语言编写的服务器端小程序,驻留在web服务器中,并在其中运行,扩展了web服务器的动态处理功能. 用java语言编写的java类 在web容器中运 ...
- Activity内切换fragment实现底部菜单切换遇到的坑
1.一般说来,app底部导航都会设计为5个菜单,可以使用textView,也可使用radioButton,这里我选择用radioButton,给radioButton直接设置selector就可以实现 ...
- scrapy_全站爬取
如何查询scrapy有哪些模版? scrapy genspider –list 如何创建crawl模版? scrapy genspider -t crawl 域名 scrapy genspider - ...