[DeeplearningAI笔记]ML strategy_1_3可避免误差与改善模型方法
机器学习策略 ML strategy
觉得有用的话,欢迎一起讨论相互学习~Follow Me
1.8 为什么是人的表现
今天,机器学习算法可以与人类水平的表现性能竞争,因为它们在很多应用程序中更有生产力和更可行。并且设计和构建机器学习系统的工作流程都比以往更加高效.此外,人类所做的一些任务接近于“完美”,这就是机器学习试图模仿人类水平表现的原因。
图中所示的是经过一段时间后人和机器的表现.
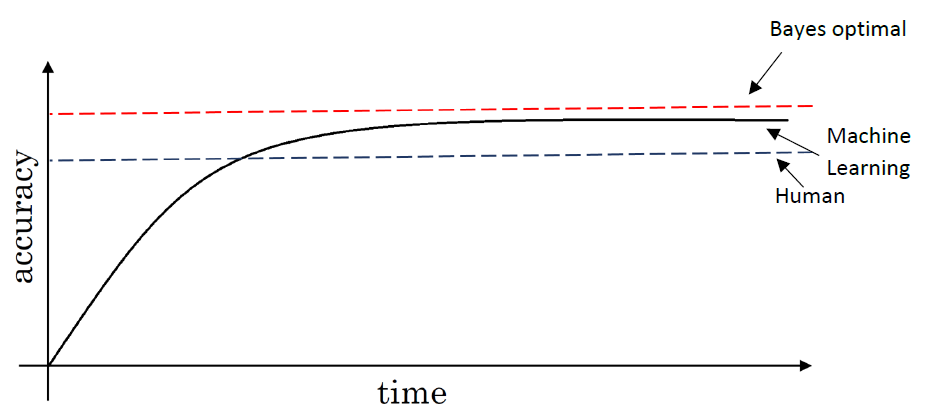
- 当算法逐渐逼近人类表现时,算法的准确率快速提高.但是当这个算法表现比人类更好时,进展和精确度的提升就变得很缓慢了.最终逼近但是无法超过贝叶斯最优误差(Bayes optimal error).Bayes optimal error是被称为是理论上的最优误差.就是说没有办法设计一个函数让它能够超过一定的准确度.
- 对于机器学习算法在精确度低于人类之前进展迅速,但是超越人类后进展缓慢的解释:
- 人类水平在求解很多问题时离贝叶斯最优误差已经不远了,特别是处理自然数据,如视觉辨认和音频处理.即使你超过人类,也没有很大的空间可以进行提升.
- 当机器算法的准确度在人类以下时,可以使用某些工具来提高性能.一旦你超过了人类,这些工具就显得不是那么好用了.
- 给算法更多人工标记的数据
- 人工分析算法弱点
- 分析数据偏差和方差
- 这些工具在机器学习准确度比人低的时候可以较好的使用,但是一旦算法的准确度比人高,这些方法就不能给算法带来优势的改变了.
1.9 可避免误差(Avoidable bias)
- 当你要区分一个算法表现得好坏的时候,了解人类级别的表现十分重要.
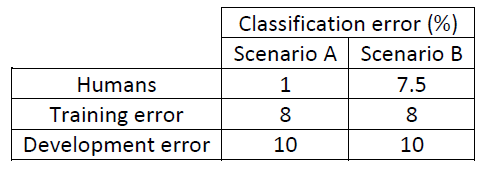
- 我们使用猫分类器做例子,在处理自然数据方面,人类有十分完美的准确度,我们假设人类水平的错误是1%,我们假设其已经十分接近贝叶斯最优误差假设此时你的算法有8%的训练误差和10%的开发误差,显然你的训练误差和人类水平错误的差距有7%,而和开发误差仅有2%的差距.所以从减少偏差和方差的角度来考虑,我们应该把重点放在减少偏差上.此时我们应当训练更大的神经网络或者跑久一点梯度下降.
- 在使用的场景和不同的训练集后,假设人类水平错误实际上是7.5%. 也许你的训练集中图片十分模糊,即使是人类也无法区分图片中是否有猫. 此时我们训练集上的误差已经和人类水平的误差差距很小 ,我们现在专注的是减少训练集和开发集上的误差,也就是需要专注减少学习算法的方差.也许应该使用正则化使你的开发误差更加接近你的训练误差.
- 相比于原先对于训练集和开发集的讨论,我们原先假设贝叶斯/最优误差为0,但现在对于处理自然数据的问题,鉴于人类视觉识别物体的能力很强,离贝叶斯误差很小,我们使用人类平均水平代替贝叶斯误差
可避免误差
- 将贝叶斯误差和训练集上的误差差值称为可避免误差,我们可以一步步接近贝叶斯误差,但是我们不能超过它.因为理论上是不可能超过贝叶斯误差的,除非过拟合.
- 而训练误差和开发误差之间的差值大概说明你的算法在方差上还有许多改善空间.

1.10 理解人的表现
通过人类平均水平误差估计贝叶斯误差
医学图像分类例子
- 假设你要观察这样的放射科图像,然后做出分类诊断.
- 假设普通人分类产生3%的误差.
- 假设普通的放射科医生达到1%的误差.
- 假设经验丰富的医生误差水平为0.7%.
- 假设经验丰富的医生团队讨论后达到共识的诊断误差水平为0.5%.
- 此时如何界定人类平均误差水平?...是3%,1%,0.7%,0.5%?...思考这个问题最简化的方式应该是将其作为贝叶斯误差的替代或估计.
- 则最优误差必定在0.5%以下,所以如果你是要代替或估计贝叶斯误差,人类水平误差应该取最小值即0.5%的状况
- 但是为了发表论文或者产品精度不需要足够高,我们可以设置人类水平误差为普通放射科医生的错误率即1%的值,意味着系统在一些情况下已经有部署价值了
- 本视频的要点是在定义人类水平误差时,要弄清楚你的目标所在如果要表明你可以超越单个人类,那么就有理由在某些场合部署你的系统,这个定义在某些场合也是合适的.
误差分析
- 仍然是医学图像分类的,我们加上模型在训练集和开发集上的误差率的对比数据:
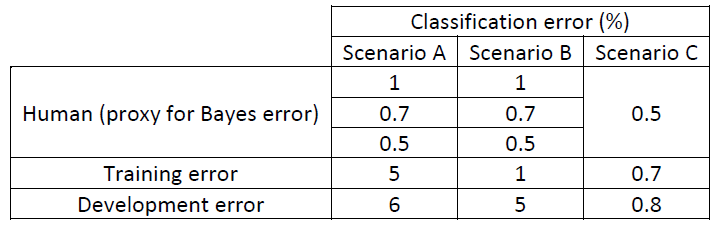
- 场景一:
- 这种情况下,人类水平的表现的标准选取几乎没有没有影响.可避免误差在4%-4.5%之间,方差为1%.因此,重点应该放在偏差上.
- 场景二:
- 这种情况下,人类水平的表现的标准选取几乎没有没有影响.可避免误差在0%-0.5%之间,方差为4%.因此,重点应该放在方差上.
- 场景三:
- 这种情况下,贝叶斯误差应该是0.5%,因为最优误差不能低于人类水平,否则训练集上的误差就过拟合.此外可避免误差为0.2%,方差为0.1%,重点应该放在调整偏差上.
Summary
利用人类水平误差调整偏差和方差
- 你可以使用人类水平误差来估计贝叶斯误差.
- 人类水平误差和训练集误差的差异可以用来表示偏差,训练集误差和开发集误差之间的差异可以用来表示方差.
- 如果人类水平误差和训练集之间的差异大于训练集误差与开发集误差之间的差异,重点应该放在减少偏差的技术上;反之重点应该是减少方差的技术.
1.11 超过人的表现
Surpassing human-level performance

- 场景一:
- 这种情况下,贝叶斯误差选取最低误差即0.5%,因此偏差是0.6%-0.5%=0.1%而方差是0.8%-0.6%=0.2%
- 场景二:
- 在这种情况下,即使贝叶斯误差选取人类水平最低误差即0.5%,但是机器预测误差比人类水平误差还低,但是此误差绝对不会比贝叶斯误差还低,证明机器的预测分类水平已经超过了人类的表现
- 在这种情况下,没有足够的信息来判断是否需要在算法上进行偏差减少或方差的减少。这并不意味着模型不能改进,它意味着传统的方法来了解偏差减少或方差减少在这种情况下是行不通的。
- 在这种情况下,机器的表现已经超过了人类水平的表现,要进一步优化你的机器学习问题,就没有明确的选项和前进的方向了,这并不意味着你不能取得进展,你仍可以取得进展,但现有的帮助你指明方向的工具就没有那么好用了.
机器学习超过人类的领域
- 现在机器学习在很多领域的表现已经大大超过了人类.
- 网络广告-估计某个用户点击广告的可能性,算法的水平已经超过了任何人类.
- 提出产品建议-向你推荐电影或者书籍之类的任务.
- 物流预测-从A到B开车需要多久
- 贷款审批-判断是否批准此人的贷款
- 这四个例子都是从结构化数据中总结得来的,从数据库或者用户记录中搜集信息,进行预测,都不是自然感知的问题
1.12 改善你的模型的表现
Improving your model performance
监督学习的两个基本条件
机器学习算法对训练集拟合的很好,这意味着低的可避免偏差
具有低或者可接受的方差,这意味着训练集的性能可以很好的扩展到开发集和测试集.
1.通过比较训练集上的误差和人类水平的误差我们可以知道可避免误差有多大.
2.通过比较开发误差和训练误差的距离我们可以知道你的方差问题有多大,即你需要做多少努力才能使你的算法表现从训练集推广到开发集.
如果可避免误差距离比方差距离大.
- 训练更大的模型(更深层次的神经网络,更多的隐藏单元)
- 训练更长时间,更好的优化算法
- 更先进的神经网络架构(RNN,CNN),超参数搜索.
如果方差距离比可避免误差距离大
- 使用更多的数据(搜集更多的数据)
- 正则化(L2,Dropout,数据增强)
- 更先进的神经网络架构(RNN,CNN),超参数搜索
[DeeplearningAI笔记]ML strategy_1_3可避免误差与改善模型方法的更多相关文章
- [DeeplearningAI笔记]ML strategy_1_2开发测试集评价指标
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 满足和优化指标 Stisficing and optimizing metrics 有时候把你要考 ...
- [DeeplearningAI笔记]ML strategy_1_1正交化/单一数字评估指标
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 什么是ML策略 机器学习策略简介 情景模拟 假设你正在训练一个分类器,你的系统已经达到了90%准确 ...
- [DeeplearningAI笔记]ML strategy_2_2训练和开发/测试数据集不匹配问题
机器学习策略-不匹配的训练和开发/测试数据 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.4在不同分布上训练和测试数据 在深度学习时代,越来越多的团队使用和开发集/测试集不同分布的数据来 ...
- [DeeplearningAI笔记]ML strategy_2_1误差分析
机器学习策略-误差分析 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.1 误差分析 训练出来的模型往往没有达到人类水平的效果,为了得到人类水平的结果,我们对原因进行分析,这个过程称为误差 ...
- [DeeplearningAI笔记]ML strategy_2_3迁移学习/多任务学习
机器学习策略-多任务学习 Learninig from multiple tasks 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 迁移学习 Transfer Learninig 神 ...
- [DeeplearningAI笔记]ML strategy_2_4端到端学习
机器学习策略-端到端学习 End-to-end deeplearning 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.9 什么是端到端学习-What is End-to-end dee ...
- [DeeplearningAI笔记]神经网络与深度学习2.11_2.16神经网络基础(向量化)
觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.11向量化 向量化是消除代码中显示for循环语句的艺术,在训练大数据集时,深度学习算法才变得高效,所以代码运行的非常快十分重要.所以在深度学 ...
- 【Unity Shaders】学习笔记——SurfaceShader(四)用纹理改善漫反射
[Unity Shaders]学习笔记——SurfaceShader(四)用纹理改善漫反射 转载请注明出处:http://www.cnblogs.com/-867259206/p/5603368.ht ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
随机推荐
- .net整理
CLR via C# 1 关于CLI,CTS,CLS,CIL,.Net Framework,CLR,FCL图 CLI:Common Language Infrastructure,是公共语言架构: C ...
- cs231n spring 2017 lecture2 Image Classification 听课笔记
1. 相比于传统的人工提取特征(边.角等),深度学习是一种Data-Driven Approach.深度学习有统一的框架,喂不同的数据集,可以训练识别不同的物体.而人工提取特征的方式很脆弱,换一个物体 ...
- linux下,文件的权限和数字对应关系详解
命令 chmod ABC file 其中A.B.C各为一个数字,分别表示User.Group.及Other的权限. A.B.C这三个数字如果各自转换成由"0"."1&qu ...
- 51Nod 1003 阶乘后面0的数量(数学,思维题)
1003 阶乘后面0的数量 基准时间限制:1 秒 空间限制:131072 KB 分值: 5 难度:1级算法题 n的阶乘后面有多少个0? 6的阶乘 = 1*2*3*4*5*6 = 720 ...
- oracle erp 表结构
BOM模块常用表结构 表名: bom.bom_bill_of_materials 说明: BOM清单父项目 BILL_SEQUENCE_ID NUMBER 清单序号(关键字)ASSEMBLY_ITEM ...
- c与c++d的typedef
一.基本概念剖析 int* (*a[5])(int, char*); //#1 void (*b[10]) (void (*)()); //#2 double(*)() (*pa)[9]; ...
- 久未更 ~ 一之 —— 关于ToolBar
很久没更博客了,索性开一个久未更 系列 > > > > > 久未更 系列一:关于ToolBar的使用(后续补充) //让 ToolBar 单独使用深色主题 使得 tool ...
- HTTP协议简介
一.简介 HTTP(HyperText Transfer Protocol, 超文本传输协议) 是访问互联网使用的核心通信协议,也是所有web应用程序使用的通信协议.消息模型:客户端发送请求消息,服务 ...
- 如何节省 1TB 图片带宽?解密极致图像压缩
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 作者:Gophery 本文由 腾讯技术工程官方号 发布在云+社区 图像已经发展成人类沟通的视觉语言.无论传统互联网还是移动互联网,图像一直占据着 ...
- spring问题:java.lang.NoClassDefFoundError: org/aspectj/weaver/tools/PointcutPrimitive
问题描述: spring的:java.lang.NoClassDefFoundError: org/aspectj/weaver/tools/PointcutPrimitive 解决方案: 缺少jar ...