cdh版本的hue安装配置部署以及集成hadoop hbase hive mysql等权威指南
hue下载地址:https://github.com/cloudera/hue
hue学习文档地址:http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/manual.html
我目前使用的是hue-3.7.0-cdh5.3.6
hue(HUE=Hadoop User Experience)
Hue是一个开源的Apache Hadoop UI系统,由Cloudera Desktop演化而来,最后Cloudera公司将其贡献给Apache基金会的Hadoop社区,它是基于Python Web框架Django实现的。
通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job,执行Hive的SQL语句,浏览HBase数据库等等。
hue特点:
能够支持各个版本的hadoop
hue默认数据库:sql lite
文件浏览器:对数据进行增删改查
hue下载src包进行一次编译,二次编译,在这用的是已经一次编译
hue部署:
1、下载依赖包:yum源安装
sudo yum -y install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi gcc gcc-c++ krb5-devel libtidy libxml2-devel libxslt-devel mvn mysql mysql-devel openldap-devel python-devel sqlite-devel openssl-devel
sudo yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel
2、解压hue tar包
tar -zxvf hue-3.7.0-cdh5.3.6.tar.gz -C /指定的目录
3、二次编译
进入hue目录:执行make apps 会出现个build目录
错误:(centos 7会有)
error: static declaration of ‘X509_REVOKED_dup’ follows non-static declaration
static X509_REVOKED * X509_REVOKED_dup(X509_REVOKED *orig) {
^
In file included from /usr/include/openssl/ssl.h:156:0,
from OpenSSL/crypto/x509.h:17,
from OpenSSL/crypto/crypto.h:30,
from OpenSSL/crypto/crl.c:3:
/usr/include/openssl/x509.h:751:15: note: previous declaration of ‘X509_REVOKED_dup’ was here
X509_REVOKED *X509_REVOKED_dup(X509_REVOKED *rev);
^
error: command 'gcc' failed with exit status 1
给下面两个删掉:/usr/include/openssl/x509.h -》751、752行
X509_REVOKED *X509_REVOKED_dup(X509_REVOKED *rev);
X509_REQ *X509_REQ_dup(X509_REQ *req);
##必须删掉,注释不行
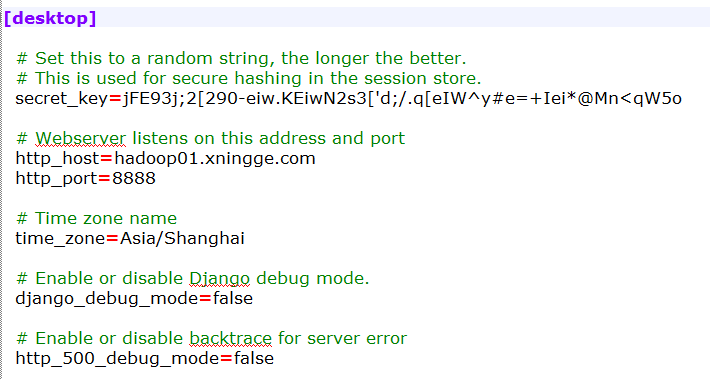
4、进入到hue-3.7.0-cdh5.3.6/desktop/conf
配置hue.ini文件:
secret_key=jFE93j;2[290-eiw.KEiwN2s3['d;/.q[eIW^y#e=+Iei*@Mn<qW5o
http_host=hadoop01.xningge.com
http_port=8888
time_zone=Asia/Shanghai
5、启动hue
两种方式
1-->cd build/env/bin---》./supervisor
2-->build/env/bin/supervisor
6、浏览器访问hue
主机名+8888
创建用户名和密码

hue和hadoop的组件配置
1、hdfs的配置
在hdfs-site.xml中配置
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
在core-site.xml中配置
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
2、重新启动hdfs进程
sbin/start-yarn.sh
3、hue配置
[[hdfs_clusters]]
# HA support by using HttpFs
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://hadoop01.xningge.com:8020
# NameNode logical name.
## logical_name=
# Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is 14000 for HttpFs.
webhdfs_url=http://hadoop01.xningge.com:50070/webhdfs/v1
# This is the home of your Hadoop HDFS installation
hadoop_hdfs_home=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6
# Use this as the HDFS Hadoop launcher script
hadoop_bin=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/bin
# Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false
# Default umask for file and directory creation, specified in an octal value.
## umask=022
# Directory of the Hadoop configuration
hadoop_conf_dir=/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/etc/hadoop
[[yarn_clusters]]
[[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=hadoop01.xningge.com
# The port where the ResourceManager IPC listens on
resourcemanager_port=8032
# Whether to submit jobs to this cluster
submit_to=True
# Resource Manager logical name (required for HA)
## logical_name=
# Change this if your YARN cluster is Kerberos-secured
## security_enabled=false
# URL of the ResourceManager API
resourcemanager_api_url=http://hadoop01.xningge.com:8088
# URL of the ProxyServer API
proxy_api_url=http://hadoop01.xningge.com:8088
# URL of the HistoryServer API
history_server_api_url=http://hadoop01.xningge.com:19888
eg:此配置都是伪分布式模式
4、启动hue服务
build/env/bin/supervisor
hue与hive配置
1、hive配置
在hive-site.xml配置
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop01.xningge.com</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>hadoop01.xningge.com:9083</value>
</property>
2、启动hive服务
bin/hiveserver2 &
bin/hive --service metastore &
3 、hue配置
修改hue.ini文件
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=hadoop01.xningge.com
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
# Hive configuration directory, where hive-site.xml is located
hive_conf_dir=/opt/modules/cdh/hive-0.13.1-cdh5.3.6/conf
# Timeout in seconds for thrift calls to Hive service
server_conn_timeout=120
# Choose whether Hue uses the GetLog() thrift call to retrieve Hive logs.
# If false, Hue will use the FetchResults() thrift call instead.
## use_get_log_api=true
# Set a LIMIT clause when browsing a partitioned table.
# A positive value will be set as the LIMIT. If 0 or negative, do not set any limit.
## browse_partitioned_table_limit=250
# A limit to the number of rows that can be downloaded from a query.
# A value of -1 means there will be no limit.
# A maximum of 65,000 is applied to XLS downloads.
## download_row_limit=1000000
# Hue will try to close the Hive query when the user leaves the editor page.
# This will free all the query resources in HiveServer2, but also make its results inaccessible.
## close_queries=false
# Thrift version to use when communicating with HiveServer2
## thrift_version=5
hue与关系型数据库配置
[librdbms]
# The RDBMS app can have any number of databases configured in the databases
# section. A database is known by its section name
# (IE sqlite, mysql, psql, and oracle in the list below).
[[databases]]
# sqlite configuration.
[[[sqlite]]] //注意这里一定要取消注释
# Name to show in the UI.
nice_name=SQLite
# For SQLite, name defines the path to the database.
name=/opt/modules/hue-3.7.0-cdh5.3.6/desktop/desktop.db
# Database backend to use.
engine=sqlite
# Database options to send to the server when connecting.
# https://docs.djangoproject.com/en/1.4/ref/databases/
## options={}
# mysql, oracle, or postgresql configuration.
##注意:这里的数据不能改动,默认是hue的数据库
[[[mysql]]] //注意这里一定要取消注释
# Name to show in the UI.
nice_name="My SQL DB"
# For MySQL and PostgreSQL, name is the name of the database.
# For Oracle, Name is instance of the Oracle server. For express edition
# this is 'xe' by default.
name=sqoop//这个name是数据库表名
# Database backend to use. This can be:
# 1. mysql
# 2. postgresql
# 3. oracle
engine=mysql
# IP or hostname of the database to connect to.
host=hadoop01.xningge.com
# Port the database server is listening to. Defaults are:
# 1. MySQL: 3306
# 2. PostgreSQL: 5432
# 3. Oracle Express Edition: 1521
port=3306
# Username to authenticate with when connecting to the database.
user=xningge
# Password matching the username to authenticate with when
# connecting to the database.
password=???
# Database options to send to the server when connecting.
# https://docs.djangoproject.com/en/1.4/ref/databases/
## options={}
hue与zookeeper配置
只需修改hue.ini文件
host_ports=hadoop01.xningge.com:2181
启动zookeeper:
hue与oozie的配置
修改:hue.ini文件
[liboozie]
oozie_url=http://hadoop01.xningge.com:11000/oozie
如果没有出来的:
修改:oozie-site.xml
<property>
<name>oozie.service.WorkflowAppService.system.libpath</name>
<value>/user/oozie/share/lib</value>
</property>
到oozie目录下重新创建sharelib库:
bin/oozie-setup.sh sharelib create -fs hdfs://hadoop01.xningge.com:8020 -locallib oozie-sharelib-4.0.0-cdh5.3.6-yarn.tar.gz
启动oozie:bin/oozied.sh start
hue与hbase的配置
修改hue.ini文件:
hbase_clusters=(Cluster|hadoop01.xningge.com:9090)
hbase_conf_dir=/opt/cdh_5.3.6/hbase-0.98.6-cdh5.3.6/conf
修改hbase-site.xml,添加以下配置:
<property>
<name>hbase.regionserver.thrift.http</name>
<value>true</value>
</property>
<property>
<name>hbase.thrift.support.proxyuser</name>
<value>true</value>
</property>
启动hbase:
bin/start-hbase.sh
bin/hbase-daemon.sh start thrift
##hbase完全分布式
hbase_clusters=(Cluster1|hostname:9090,Cluster2|hostname:9090,Cluster3|hostname:9090)
cdh版本的hue安装配置部署以及集成hadoop hbase hive mysql等权威指南的更多相关文章
- cdh版本的sqoop安装以及配置
sqoop安装需要提前安装好sqoop依赖:hadoop .hive.hbase.zookeeper hadoop安装步骤请访问:http://www.cnblogs.com/xningge/arti ...
- CDH版本的oozie安装执行bin/oozie-setup.sh prepare-war,没生成oozie.war?
不多说,直接上干货! 前期博客 Oozie安装部署 问题描述 bin/oozie-setup.sh prepare-war 解决办法 [hadoop@bigdatamaster bin]$ pwd / ...
- hbase安装配置(整合到hadoop)
hbase安装配置(整合到hadoop) 如果想详细了解hbase的安装:http://abloz.com/hbase/book.html 和官网http://hbase.apache.org/ 1. ...
- hue安装与部署
运行环境 centOS 6.6 hadoop 2.4.0 hive 1.2.0 spark 1.4.1 HUE 3.9 介绍: Hue是一个开源的Apache Hadoop UI系统,最早是由Clou ...
- hbase单机及集群安装配置,整合到hadoop
问题导读:1.配置的是谁的目录conf/hbase-site.xml,如何配置hbase.rootdir2.如何启动hbase?3.如何进入hbase shell?4.ssh如何达到互通?5.不安装N ...
- Phoenix |安装配置| 命令行操作| 与hbase的映射| spark对其读写
Phoenix Phoenix是HBase的开源SQL皮肤.可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据. 1.特点 1) 容易集成:如Spark,Hi ...
- Hue集成Hadoop和Hive
一.环境准备 1.下载Hue:https://dl.dropboxusercontent.com/u/730827/hue/releases/3.12.0/hue-3.12.0.tgz 2.安装依赖 ...
- cdh版本的zookeeper安装以及配置(伪分布式模式)
需要的软件包:zookeeper-3.4.5-cdh5.3.6.tar.gz 1.将软件包上传到Linux系统指定目录下: /opt/softwares/cdh 2.解压到指定的目录:/opt/mo ...
- hadoop cdh 4.5的安装配置
春节前用的shark,是从github下载的源码,自己编译.shark的master源码仅支持hive 0.9,支持hive 0.11的shark只是个分支,不稳定,官方没有发布release版,在使 ...
随机推荐
- Gym100971B Gym100971C Gym100971F Gym100971G Gym100971K Gym100971L(都是好写的题。。。) IX Samara Regional Intercollegiate Programming Contest Russia, Samara, March 13, 2016
昨天训练打的Gym,今天写题解. Gym100971B 这个题就是输出的时候有点小问题,其他的都很简单. 总之,emnnn,简单题. 代码: #include<iostream> #inc ...
- Legal or Not(拓扑排序判环)
http://acm.hdu.edu.cn/showproblem.php?pid=3342 Legal or Not Time Limit: 2000/1000 MS (Java/Others) ...
- [国嵌攻略][137][DM9000网卡驱动编程]
DM9000数据发送 DM9000数据发送函数是在/drivers/net/dm9000.c中的dm9000_start_xmit函数 static int dm9000_start_xmit(str ...
- input[type=file]样式更改以及图片上传预览
以前知道input[type=file]可以上传文件,但是没用过,今天初次用,总感觉默认样式怪怪的,想修改一下,于是折腾了半天,总算是小有收获. 以上是默认样式,这里我想小小的修改下: HTML代码如 ...
- eclipse配置虚拟路径后,每次启动tomcat都会虚拟路径失效的问题解决
由于,eclipse启动tomcat部署项目并不是直接把项目放到tomcat的webapps目录下的,而是从我们在eclipse配置的外部tomcat中取出二进制文件,在eclipse内部插件中作为t ...
- 查看php的配置文件Php.ini的位置
标签:php服务器 浏览器 配置文件 Linux local 近来,有不博友问php.ini存在哪个目录下?或者修改php.ini以后为何没有生效?基于以上两个问题,我觉得有必要教一下刚接触PHP的博 ...
- RSync实现文件备份同步,rsync服务器
转自:http://www.cnblogs.com/itech/archive/2009/08/10/1542945.html [rsync实现网站的备份,文件的同步,不同系统的文件的同步,如果是wi ...
- python_virtualenvwrapper安装与使用
如何创建当前python版本虚拟环境? 1. 安装virtualenv pip install -i https://pipy.doubanio.com/simple virtualenv 2. 创建 ...
- Docker for Web Developers目录
在OpenStack在私有云占主导定位之后,后起之秀Docker在PaaS平台.CI/CD.微服务领域展露锋芒.作为Web Developers,我们有必要学习和掌握这门技术. 1. 运行第一个Doc ...
- curl错误码说明
1.得到错误码 $errno=curl_errno($ch); if($errno!=0){ -- } 2.错误码说明 <?php return [ '1'=>'CURLE_UNSUPPO ...